目录
前言:
总结下上述的内容:
1. 进程间通信目的
2. 进程间通信的分类
1. 匿名管道
2. 匿名管道的使用
1. 匿名管道的创建
2. 使用匿名管道进行父子间通信
Linux🌷

前言:
进程具有独立性,拥有独立的数据、代码及其他资源,为什么要让相互独立的进程间进行通信呢?
如何让相互独立的进程进行通信?
先说为什么?:
首先在此提一下协同的概念:
协同:本质就是多人合作完成同一件事情。
用一个APP的上市来说吧!
首先由产品经理了解用户的需求—>程序员对APP进行开发—>测试人员对APP进行测试—>发布!
大致流程就如上述所示!
这便是协同工作的场景,多个部门人员进行沟通协作完成了一款APP。
如果让一个部门人员完成上述工作,那势必耗时又耗力,专门的事还是应该交给专业的人做。
进程间在一定场景下也会发生协同工作,完成某种事情,这便是为什么的原因。
如下给出一个例子以便更好地理解:

第一条命令行解释:我们可以使用 ll 命令查看当前目录下的文件信息;
第二条命令行解释:我们将 ll 命令展示的信息 利用管道传递给 grep 命令 最后在grep命令的协助下完成了只筛选出包含5的信息;
这便是两条命令间的共同协作。
如何进行进程间通信呢?
进程间相互协同工作,一个进程把自己的数据交付给另一个进程,让其进行处理,这便是进程间通
信,操作系统便要设计进程间的通信方式。因为进程间是具有独立性的,如果交互数据,成本一定
很高,这是因为一个进程是看不到另一个进程的资源的。那么OS便要设计必须得让两个进程先看
到一份公共的资源,这里的资源其实是由OS提供得一段内存!
只不过这段内存可能以文件的方式提供(管道)、可能以队列的方式提供(消息队列)、也可能就
是原始的内存块(共享内存),由此可见进程间通信方式是有多种的。
终于开始我们正文了!🤦♀️
总结下上述的内容:
1. 进程间通信目的
- 数据传输:一个进程要把自己的数据交给另一个进程,让其继续进行处理;
- 资源共享:多个进程之间共享同样的资源;
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程);
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变;
2. 进程间通信的分类
- 管道
- 匿名管道pipe
- 命名管道pipe
- System V标准 进程间通信
- System V 消息队列
- System V 共享内存
- System V 信号量
- POSIX标准 进程间通信(多线程详谈)
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
在今天这篇博客中谈的是:管道中的匿名管道通信方式。
管道:
管道是Unix中最古老的进程间通信的方式;
我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”;
1. 匿名管道
管道是用于进程间通信的,匿名管道主要用于“具有亲缘关系”的进程间通信的,一般用于父子进程。
父进程创建子进程,子进程以父进程为模板创建自己的和进程相关的数据结构,和父进程共同分享一份代码,如果不发生写时拷贝,数据也是共同分享一份的。
今天主要探讨的是 file_struct:
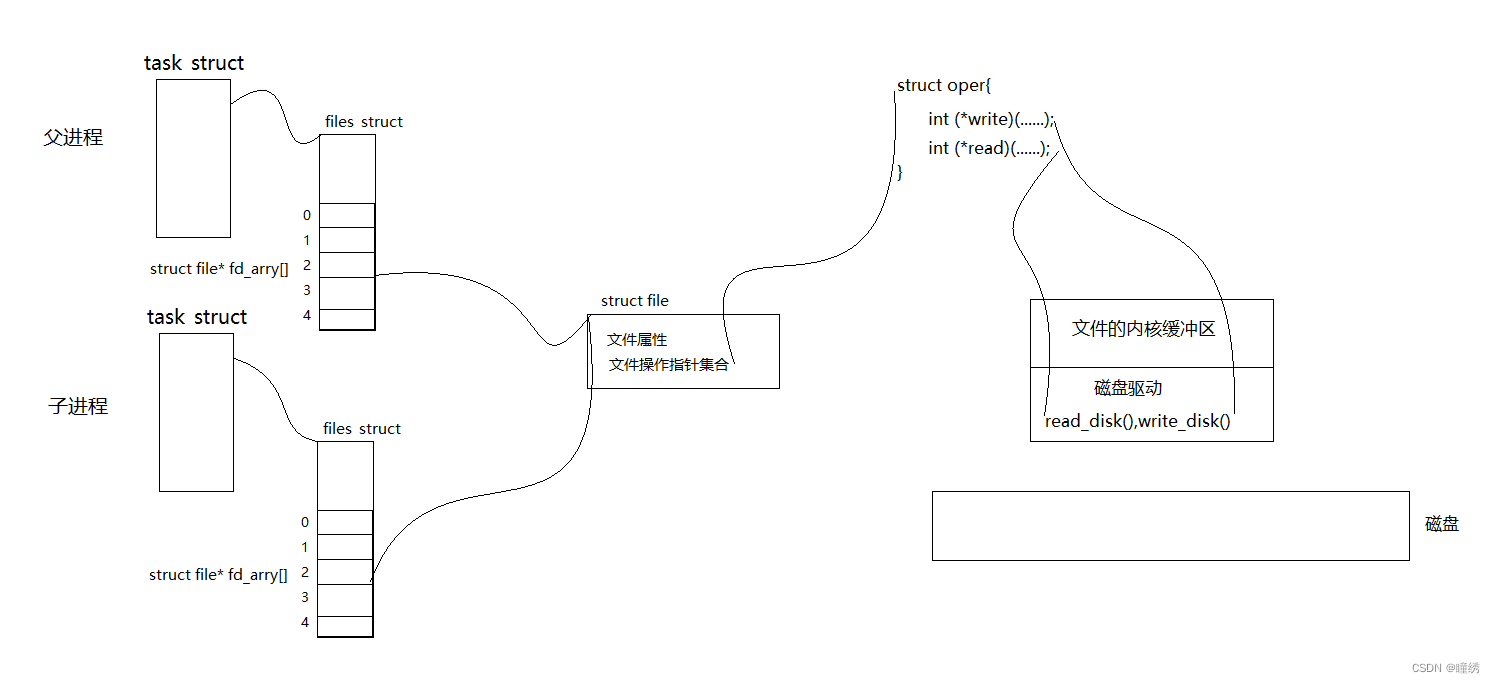
我们平常使用write系统调用,最开始的理解是:直接将数据写至内核缓冲区。
今天我们要对它进行更深一步的理解,write系统调用实际上干了两件事:
1. 拷贝数据到内核缓冲区;
2. 触发底层的写入函数在合适的时机刷新到外设,如write_disk()到磁盘;
如果只是将数据拷贝至内核缓冲区,而不进行刷新,另一个进程从缓冲区读,那么这个缓冲区便相当于管道(一份临界资源)(公共资源)。
这种基于文件的通信方式叫做管道。
2. 匿名管道的使用
1. 匿名管道的创建
#include <unistd.h>
int pipe(int pipefd[2]);参数pipefd:是输出型参数,通过这个参数拿到两个未被分配的文件标识符fd;
如果没有文件打开则 pipefd[0] = 3 ,pipefd[1] = 4,因为0、1、2 已经被占用;
其中pipefd[0]是读端,pipefd[1]是写端;
0很像嘴巴,嘴巴是用来读的,1像一支笔,笔是用来写的,这样是不是很好区分了😁
返回值:创建成功返回0,失败返回-1;


经过证实确实如此!
2. 使用匿名管道进行父子间通信
1. 总体流程:

上述是一个子进程来写,父进程来读的大致图示;
其实父子进程本没有谁应该读、谁应该写之分,上述分配只是为了帮助我们更好验证一些东西;
2. 读阻塞:
子进程写的慢,父进程读的快,会发生什么情况呢?
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
const char* msg = "hello pipe";
while(1)
{
write(pipedf[1],msg,strlen(msg));
sleep(3);
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[64]={0};
while(1)
{
read(pipedf[0],buffer,sizeof(buffer));
printf("child say # %s\n",buffer);
}
close(pipedf[0]);
return 0;
}
上述代码:
创建了一个管道,让子进程每隔3秒往管道里写数据,父进程一直从管道中读取数据并输出;

经过实验我们可以看到,大概每隔3秒显示器便会输出数据;
由此可以说明: 在写的慢读的快的情况下,读端会等写端;
3. 写阻塞
子进程写的快,父进程读的慢,会发生什么情况呢?
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
const char* msg = "hello pipe";
while(1)
{
write(pipedf[1],msg,strlen(msg));
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[64]={0};
while(1)
{
read(pipedf[0],buffer,sizeof(buffer));
printf("child say # %s\n",buffer);
sleep(3);
}
close(pipedf[0]);
return 0;
}
上述代码:
创建了一个管道,让子进程一直往管道里写数据,父进程每隔3秒从管道中读取数据并输出;

经过实验我们可以看到,显示器上输出了一大批数据;
这是因为管道文件在写入的时候:只要有缓冲区(空闲的)就写入;在读的时候:只要有内容就会读取;
管道是面向字节流的,没有明确的界限划分,是以字节为单位进行读取的,我们可以通过制定协议的方法来达到父子进程正常的一个通信,在学习网络的时候再详谈;
4.验证管道的大小
管道也有自身的大小,利用如下代码我们可以验证管道缓冲区的大小为 64KB;
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
char* msg ="a";
int count=0;
while(1)
{
write(pipedf[1],msg,1);
count++;
printf("count:%d\n",count);
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
while(1)
{
}
close(pipedf[0]);
return 0;
}
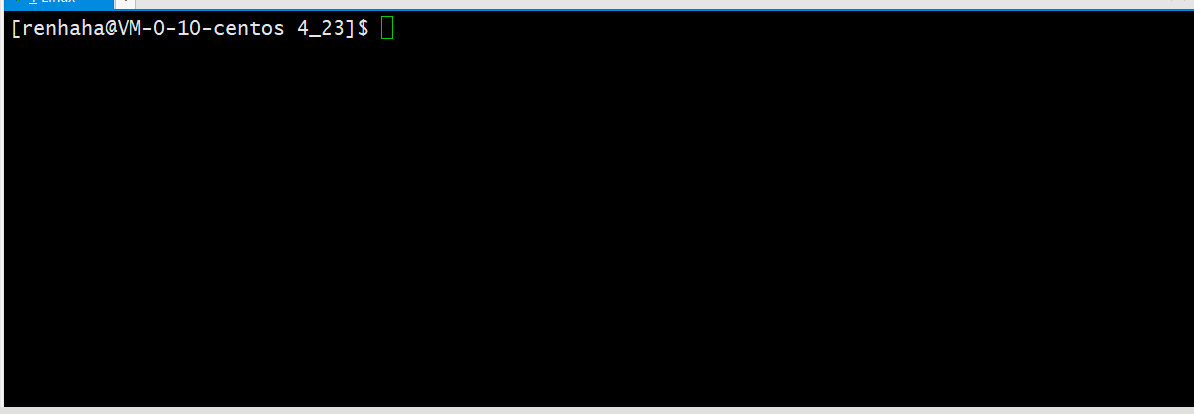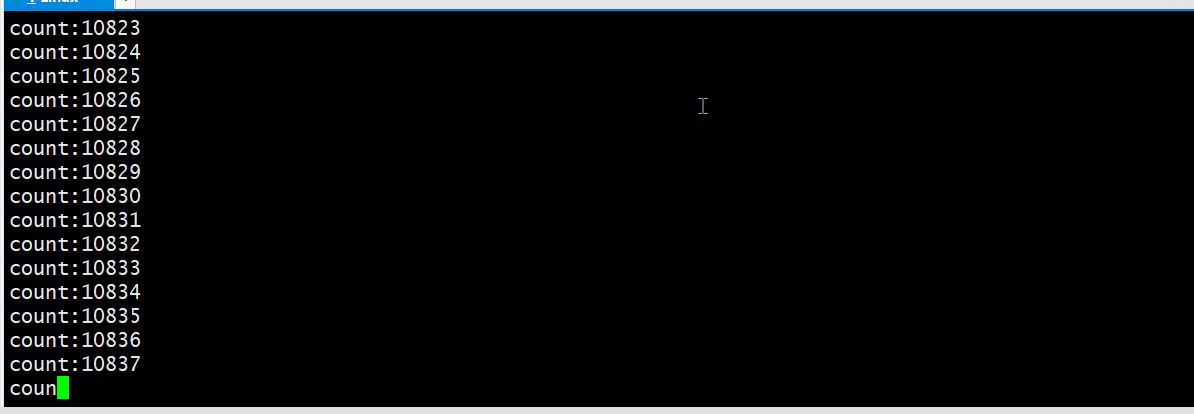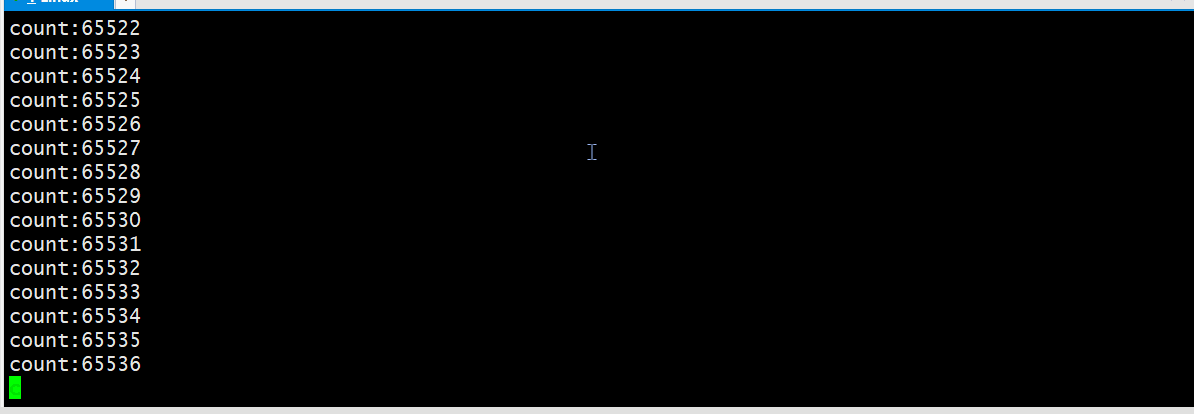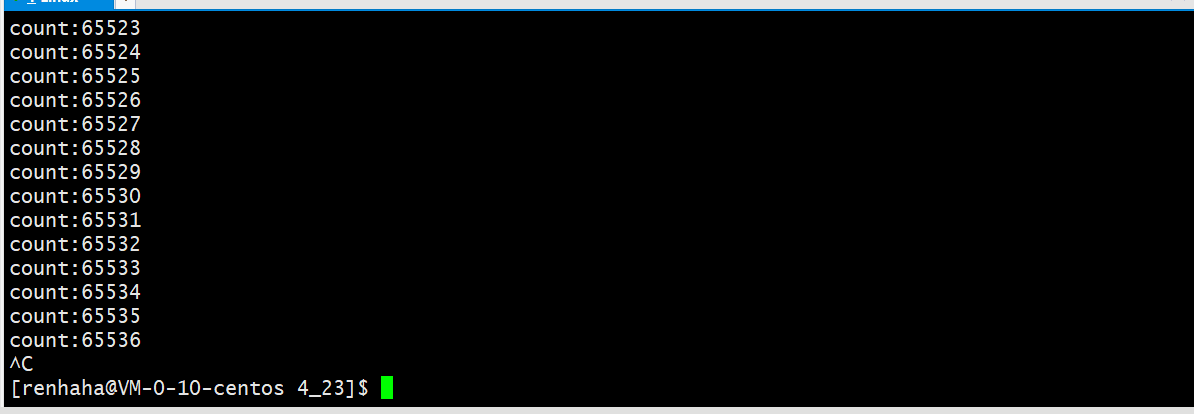
经过证实我使用的云服务器上管道容量是64KB
在这里我们还有一个疑惑:在管道写满的时候,我们难道不能覆盖前面的内容然后继续写吗?
我们是不能覆盖之前的内容重新写入的,因为我们写数据就是为了让读端来读,如果覆盖掉之前的数据,那不相当于之前写的工作就白费了,违背了进程通信的初衷。
事实上,管道是自带同步机制的,父子进程在读写时会相互等待,这种机制很好的保证了数据安全。
5. 写数据的时机
对于读进程来说,只要管道中有数据,读进程便可以从管道中读取到数据;
但对于写进程来说,必须有4KB大小的空闲缓冲区时,写进程才可以写入数据。
下面我们来验证下:
#include <stdio.h>
#include <unistd.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
char* msg = "a";
int count = 0;
while(1)
{
//往管道中以字节为单位进行写入计数
write(pipedf[1],msg,1);
printf("count:%d\n",count);
count++;
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[64]={0};
while(1)
{
//每秒读取64字节数据
ssize_t s = read(pipedf[0],buffer,sizeof(buffer));
sleep(1);
if(s==0)
{
printf("写端关闭\n");
break;
}
else if(s>0)
{
printf("child say # %s\n",buffer);
}
else
{
perror("read fail");
return 1;
}
}
close(pipedf[0]);
return 0;
}
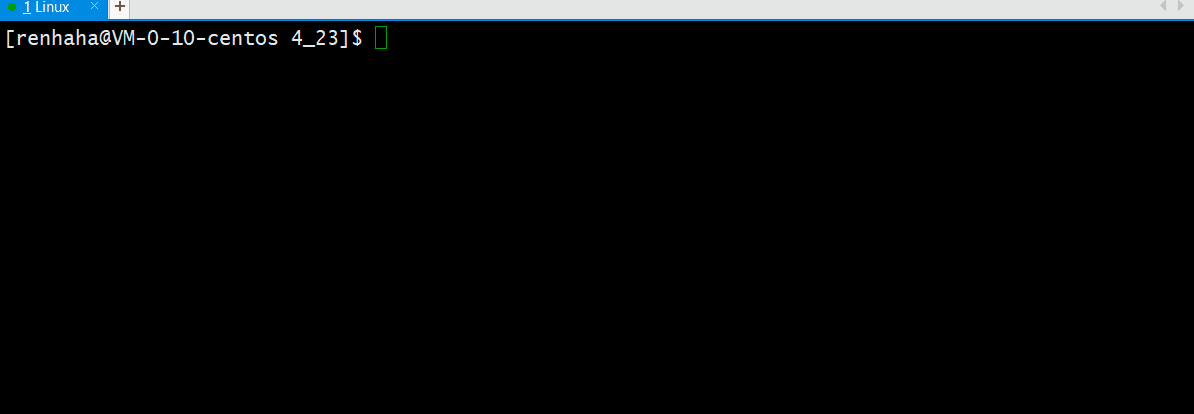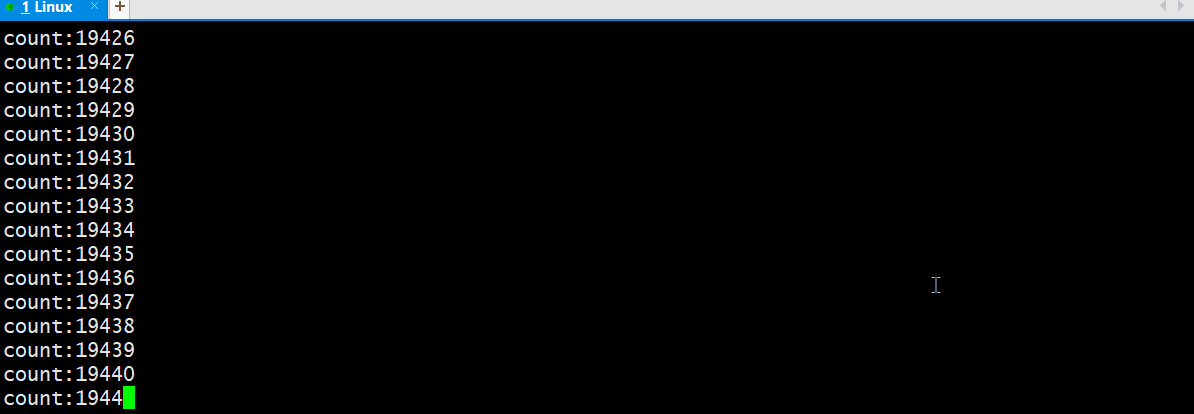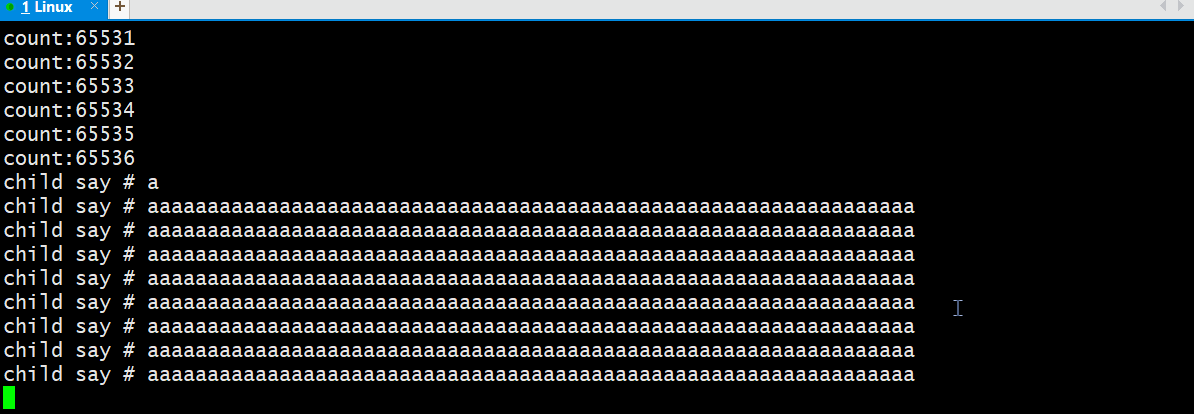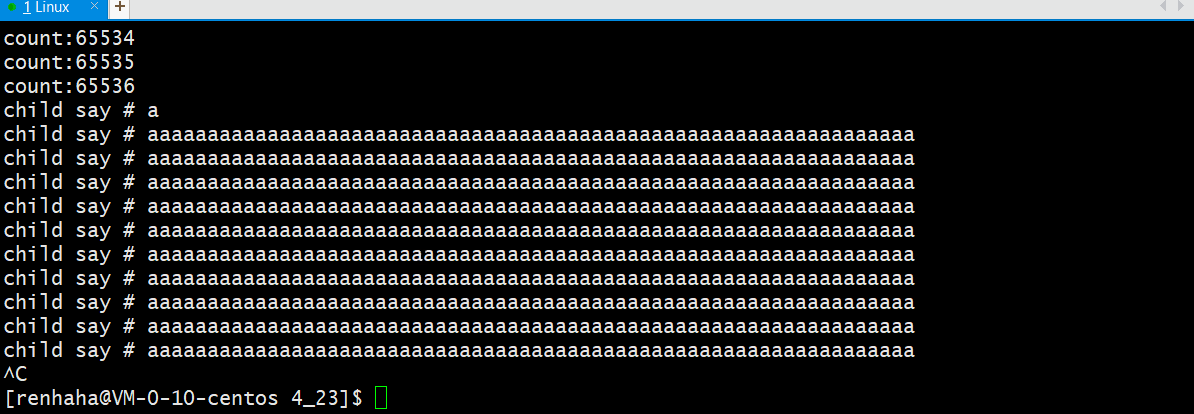
上述代码:一直往管道中写入数据,每秒中读取64字节数据;
经过实验我们看到读取了一定的数据后,我们还没有看到写进程写入数据;
由此:并不只是有空闲缓冲区写进程就会写入数据的,而是有一定的时机;
我们试着每次读取2KB的数据在进行如下实验:
#include <stdio.h>
#include <unistd.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
char* msg = "a";
int count = 0;
while(1)
{
//往管道中以字节为单位进行写入计数
write(pipedf[1],msg,1);
printf("count:%d\n",count);
count++;
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[1024*2+1]={0};
while(1)
{
//每秒读取2KB数据
ssize_t s = read(pipedf[0],buffer,sizeof(buffer));
sleep(1);
if(s==0)
{
printf("写端关闭\n");
break;
}
else if(s>0)
{
printf("child say # %c\n",buffer[0]);
}
else
{
perror("read fail");
return 1;
}
}
close(pipedf[0]);
return 0;
}
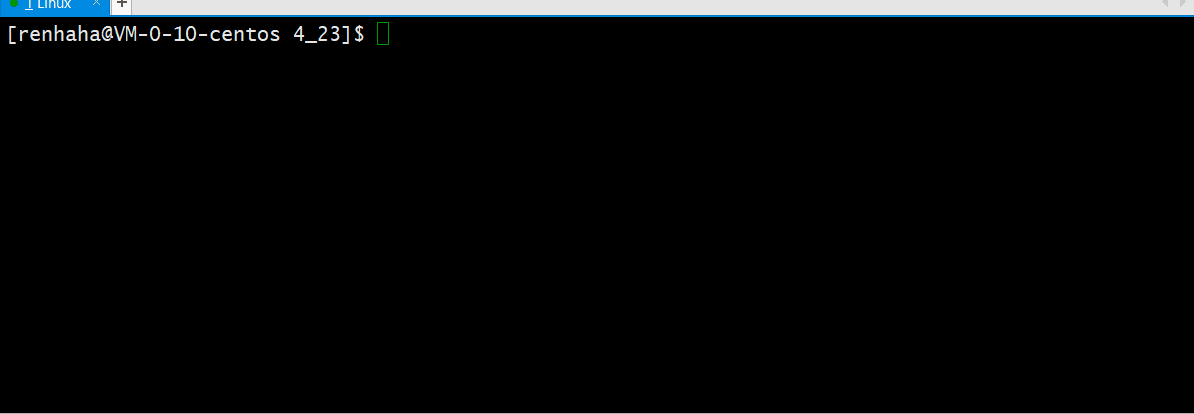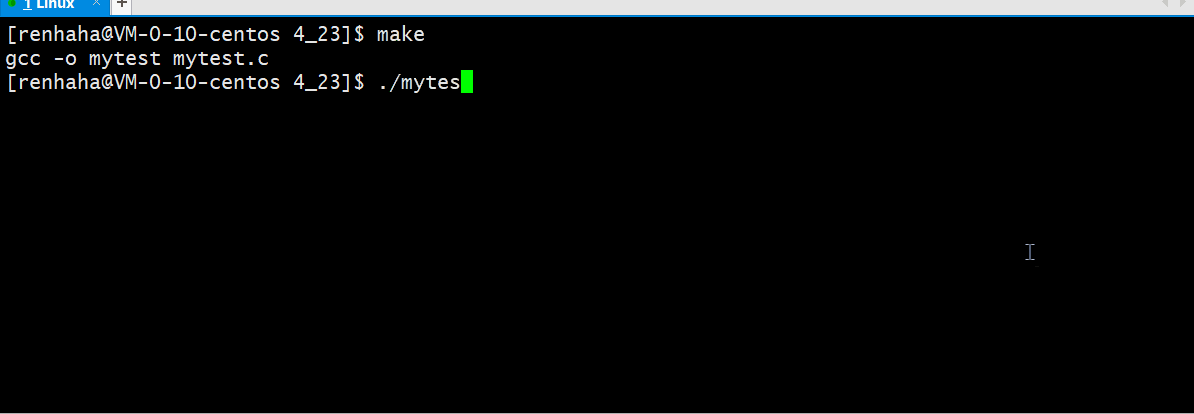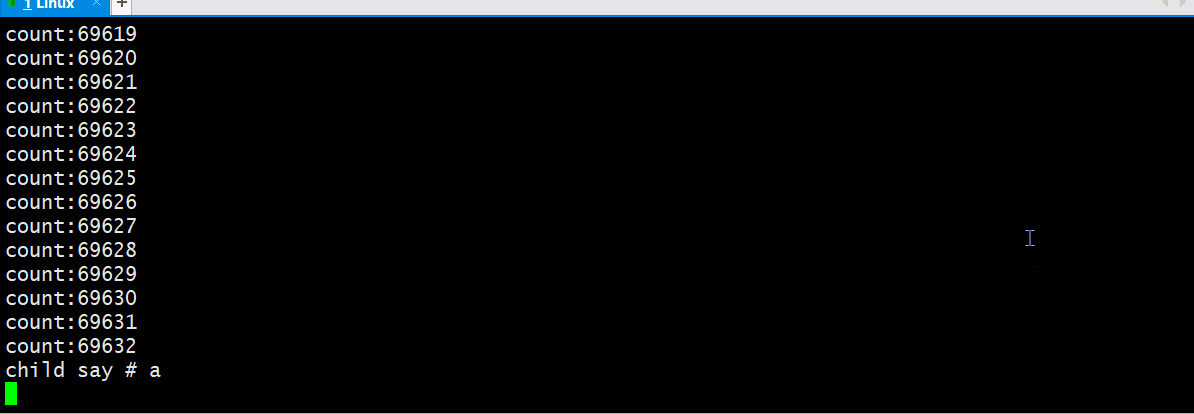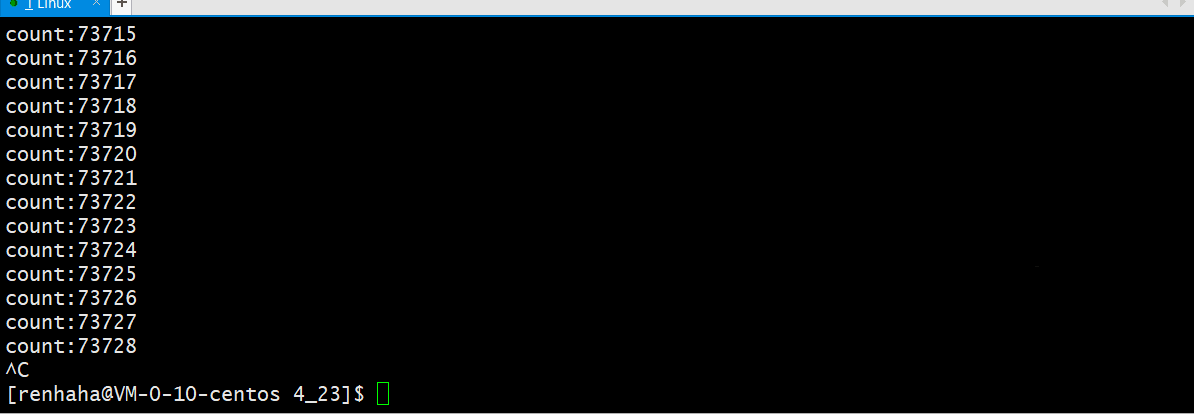
如上:我们可以看到在经过两次2KB的读数据后,写进程才会写入数据。
这样做是为了保证写入的一个原子性;

6. 写端关闭
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
const char* msg = "hello 管道";
int count = 3;
while(count)
{
//往管道中以字节为单位进行写入计数
write(pipedf[1],msg,strlen(msg));
count--;
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[64]={0};
while(1)
{
//每秒读取64字节数据
ssize_t s = read(pipedf[0],buffer,sizeof(buffer));
sleep(1);
if(s==0)
{
printf("写端关闭\n");
break;
}
else if(s>0)
{
printf("child say # %s\n",buffer);
}
else
{
perror("read fail");
return 1;
}
}
close(pipedf[0]);
printf("读取完毕\n");
return 0;
}

上述代码:写端写入3次数据,读端每隔1秒读取64字节数据;
在此我们可以看到:读端读取完写端写入的数据后,继续执行进程中的后续代码;
7. 读端关闭
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//创建管道
int pipedf[2]={0};
if(pipe(pipedf)!=0)
{
perror("pipe fail");
return 1;
}
//创建子进程
if(fork()==0)
{
//child
close(pipedf[0]);
const char* msg = "hello 管道";
while(1)
{
//往管道中以字节为单位进行写入计数
write(pipedf[1],msg,strlen(msg));
}
close(pipedf[1]);
return 0;
}
//parent
close(pipedf[1]);
char buffer[64]={0};
int count = 3;
while(count)
{
ssize_t s = read(pipedf[0],buffer,sizeof(buffer));
if(s==0)
{
printf("写端关闭\n");
break;
}
else if(s>0)
{
printf("child say # %s\n",buffer);
count--;
}
else
{
perror("read fail");
return 1;
}
}
close(pipedf[0]);
printf("读取完毕\n");
return 0;
}
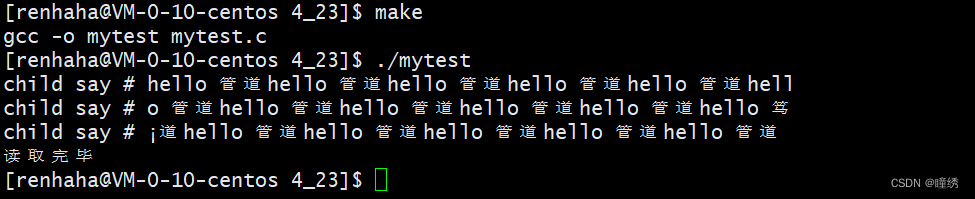
子进程一直写入,父进程读取三次后关闭管道,我们可以看出父子进程都退出了;
这是因为:当我们读端关闭,写端还在写时,此时对于OS来说,是对资源的一种浪费;
因此OS便会在读进程关闭读端口时,向写进程发送 13)SIGPIPE 信号杀死该进程;
在上述代码后添加如下代码便可验证:
//使用waitpid时要包含这两个头文件
#include <stdlib.h>
#include <sys/wait.h>
int status=0;
waitpid(-1,&status,0);
printf("exit code:%d\n",(status>>8)&0xff);
printf("signal:%d\n",status&0x7f);

总结一下整篇博客的内容:
管道有4种情况:
a. 读端不读或者读的慢,写端要等待读端;
b. 写端不写或写的慢,读端要等写端;
c. 读端关闭,写端收到SIGPIPE信号直接终止;
d. 写端关闭,读端读完pipe内部的数据然后再读,会读到0,表示读到文件结尾;
匿名管道的5个特点:
1. 管道是一个只能单向通信的通信信道;
2. 管道是面向字节流的;
3. 仅限于具有血缘关系的进程进行进程间通信,通常用于父子进程通信;
4. 管道是自带同步机制的,且原子性写入;
5. 管道的生命周期是随进程的:管道是文件,如果一个文件只被一些进程打开,相关进程都退出了,那么被打开的文件会被OS自动关闭;
坚持打卡!😀







![[测试猿课堂]小白怎么学测试?史上最全《软件测试》学习路线](https://img-blog.csdnimg.cn/img_convert/c59142a63c9c3d2442bb59f85d863f8c.jpeg)
