分享一位读者面试美团 java 岗位的面经。主要在考察 java+mysql
算法题目
最长回文串
根据前序中序恢复二叉树
说一说 MySQL 的索引
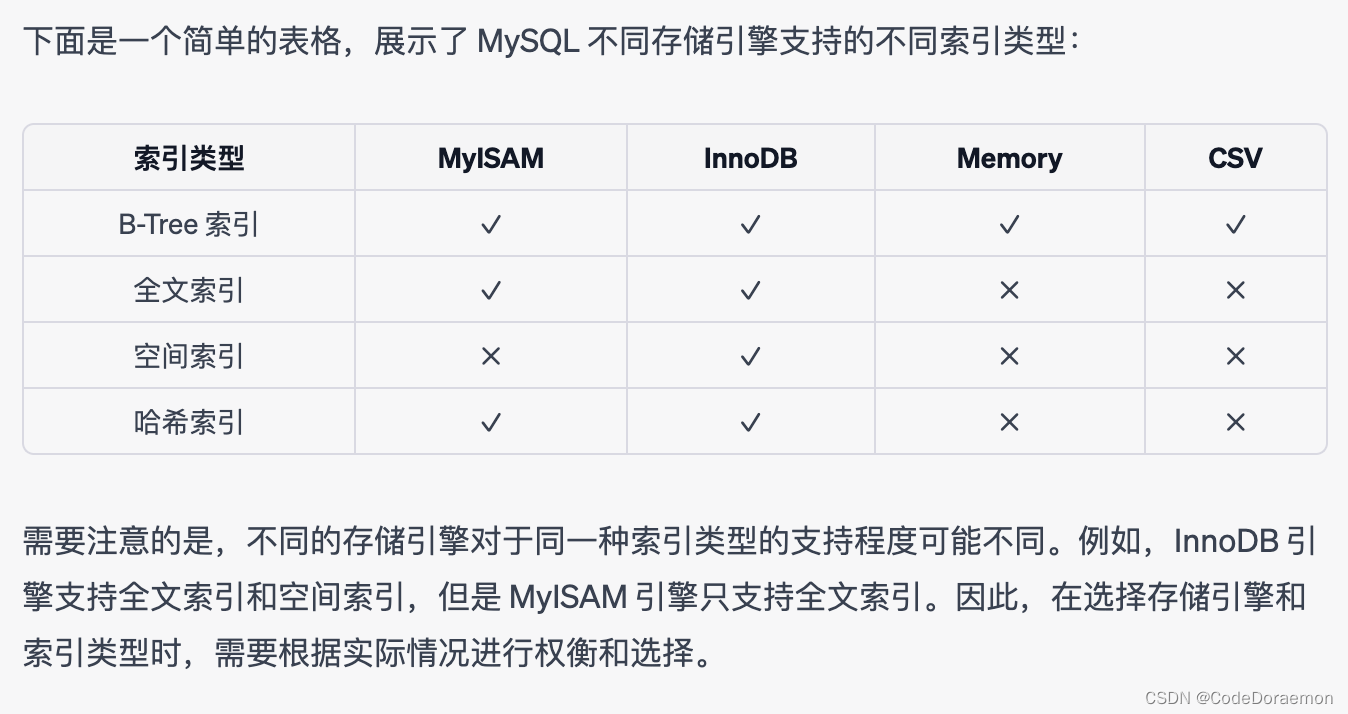
MySQL 的索引是一种存储数据结构,
按照数据结构划分,MySQL 可以分为 B+ 树索引、Hash 索引、全文索引
按照 B+ 树的叶子节点中是否存储了真实的行数据将索引分为聚簇索引和非聚簇缩影。
说说 ACID
这个是 MySQL 事务的特性,MySQL 服务器部署在服务器上,为多个客户端提供服务,为了保证每个客户端访问的数据是线程安全的,MySQL 提供了事务操作。而事务的 ACID 保证了事务之间执行是安全的。
原子性:一组操作要么全部成功,要么全部失败 - undo log
undo log 记录了事务操作之间的状态,事务执行不成功,回滚即可,保存原来的数据,有个可以撤销的设定。
一致性:逻辑一致性,账户取钱的例子
隔离性:事物之间的执行是相互不影响的 - MVCC
基于乐观锁的事务对同一个数据的修改机制,可以通过设置版本号完成
持久性:对于数据的修改是会持久化到磁盘中的 - redo log
MySQL 中的数据被操作之后,记录了所有的 MySQL 数据库修改操作,即使服务器崩溃了,也能使用这个 redo log 文件进行数据的恢复,一种数据安全的保证机制
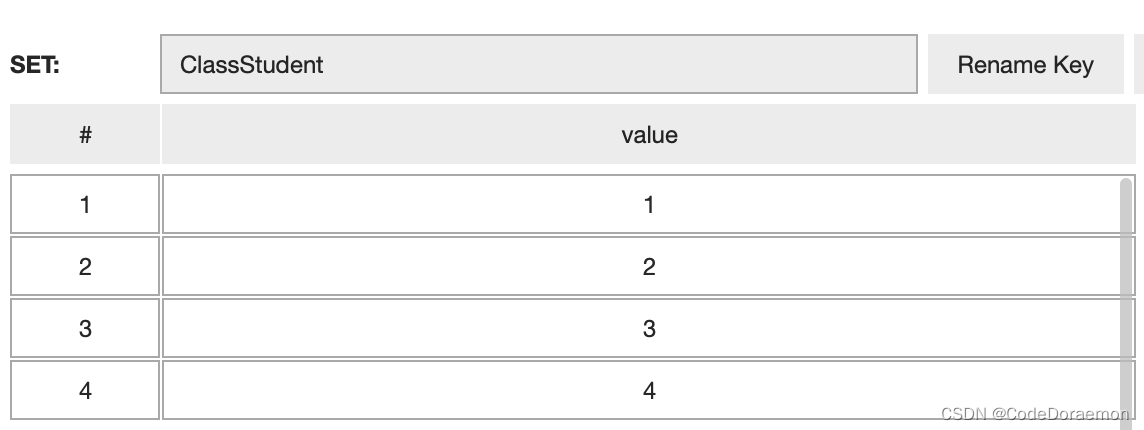
Redis 的数据类型以及底层的数据结构
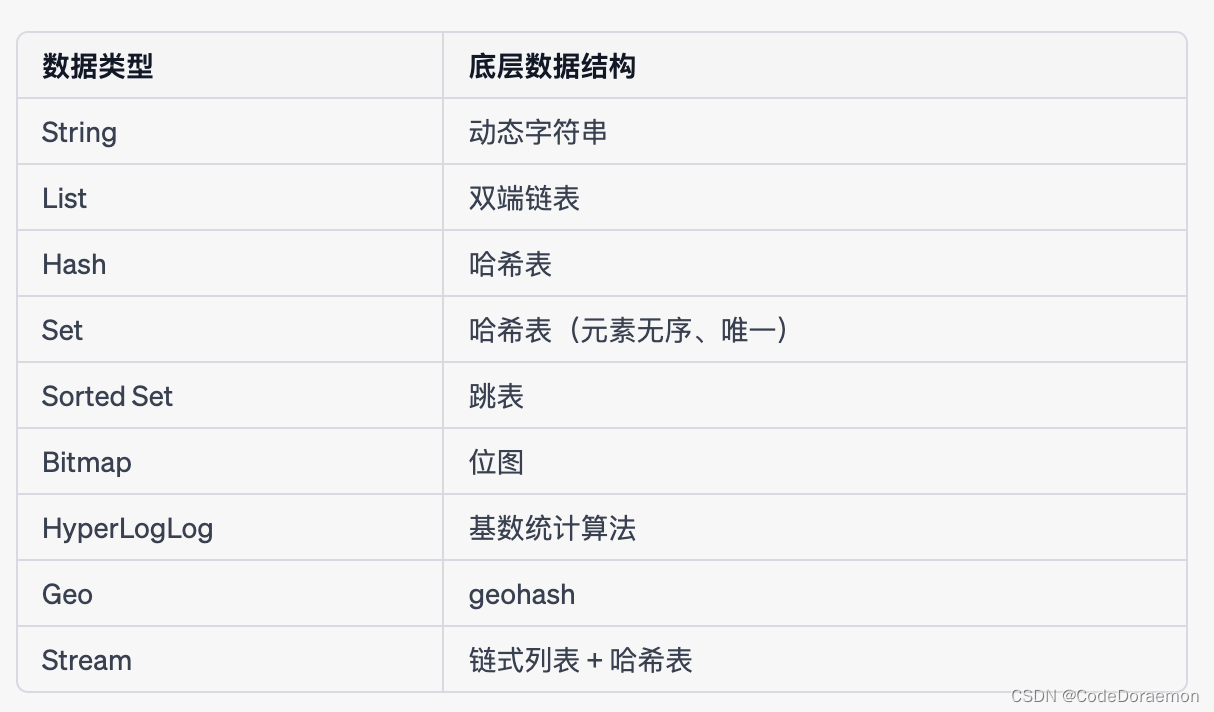
常见的 Redis 数据类型有:String 、List 、Set 、ZSet
String : 基于动态字符串实现
List : 基于双端链表实现
Set : 使用哈希表,存储的数据是无序的
ZSet : 使用跳表和哈希表来实现,因为跳表式多级链表,有序的,所以尽
管底层是哈希表,但仍然是有序的。ZSet 本身也是有序的。

hash:
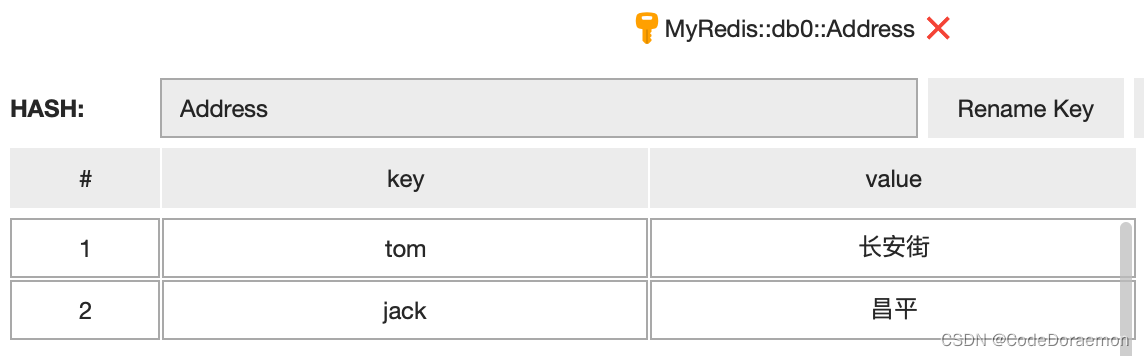
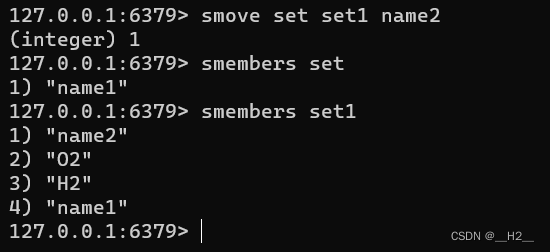
set 和 hash 之间的区别
set 中是不允许存储相同元素的, set 中 key 表示 redis 键,value 就是哈希表的键
hash 中 key 是 redis 键, value 是哈希表中的键值对
比如:
# key - value 形式,key 是 redis 键,value 是哈希表键
SADD myset menber
#key - value 形式,key 是 redis 键,value 是哈希表的键值对: field "hello"
HSET myhash field "hello"
Spring Bean 以及其生命周期
Spring Bean 就是 Spring 管理的 Java 对象,交给 Spring 容器管理。
bean 注入的方式有:构造器注入,set 方法注入,字段注入,在字段上面使用 @autowired 进行 Bean 的注入。
Spring 怎么解决循环依赖问题
Spring 创建的 Bean是存在三级缓存的,实例化但是没有注入属性的 bean 放在了第三级缓存中,注入了属性的 bean 放到了第二级缓存中,完整的可以直接使用的 bean 放在第一级缓存中。
比如两个 bean ,A 依赖于 B ,B 依赖 A。
创建 A 的时候,发现需要依赖 B ,
然后去创建 B ,此时 B 可以完全创建出来,虽然只有一个 A 的空壳,但是 B 能创建出来;
B 创建出来之后,A 就能创建出来了,解决了循环依赖问题,使得两个 Bean 都被成功的创建了。
Java 中线程的状态
创建:创建一个新的线程、但是还没有被分配到资源
就绪:除了 CPU 时间片,其他的运行资源已经获取到了
运行:拿到 CPU 时间片,线程开始运行
等待:运行期间可能遇到 IO 操作,此时线程进入等待状态,之后继续运行
销毁:线程的使命结束,将线程销毁
创建,创建了分配了除了 CPU 时间,分配了 CPU 时间,因为 IO 等待,继续执行最终销毁。
JVM 内存结构
所谓的 JVM 内存结构就是 JVM 运行时数据区的各项内容
在 JVM 内存结构中存在:堆、虚拟机栈、本地方法栈、程序计数器;
在 JDK 1.8 的时候讲原来的方法去移除了,变成了元空间,元空间独立与堆的,直接保存操作系统管理的直接内存中。元空间中保存了描述类的元信息比如类的名称、类的父类名称,类实现了什么接口等信息。
以前方法去的常量池是存放到了堆中。
以前方法区由于加载的 class 的数量大小是没有办法控制的,所以可能造成 OOM 的问题产生。替换成元空间之后,其大小可以动态变化,使得 OOM 问题得到了一定的解决。
syncronized是怎么实现的
在 Java 中每个对象都有一个监视器锁。
使用 synchornized 的时候,会在括号中传递进去一个对象。
线程访问 synchornized 代码块的时候,首先拿到对象的监视器锁。
当使用结束后会释放锁。
拿到的、释放的本质上是对象的监视器锁,而不是拿到了对象
多个线程同时访问 synchornized 的时候,会有一个锁升级的过程,也就是排队同步的操作。
第一个线程访问的时候,拿到的是偏向锁,(线程想要拿到锁 JVM 判断对象头的 id 和线程 id 是够一样即可)
第多个线程访问的时候,偏向锁升级成为轻量级锁(CAS 操作尝试获取JVM锁),
竞争继续加强,轻量级锁会升级成为重量级锁。
偏向锁和轻量级别所是对 synchornized 的一种优化,
volatile实现什么能力,怎么实现的
volatile 用于修饰变量,表示这个变量在一定程度上面是线程安全的,因为 volatile 只能保证可见性、有序性,原子性是没有灿发保证的。
可见性:一个线程修改了一个数据强制马上同步到主内存中。
有序性:禁止对于对代码优化的指令重拍。内存屏障。
比如说执行下面的代码:
volatile int count = 0
在一个方法中对 count 进行修改,可能优于不满足原子性从而导致线程安全的问题出现。
count++ 本身有三个操作:
1、获取到 count 数值
2、count 数值 + 1
3、返回增加后的数据
这个时候只是单纯的使用 colatile 是不能解决问题的。





![[测试猿课堂]小白怎么学测试?史上最全《软件测试》学习路线](https://img-blog.csdnimg.cn/img_convert/c59142a63c9c3d2442bb59f85d863f8c.jpeg)