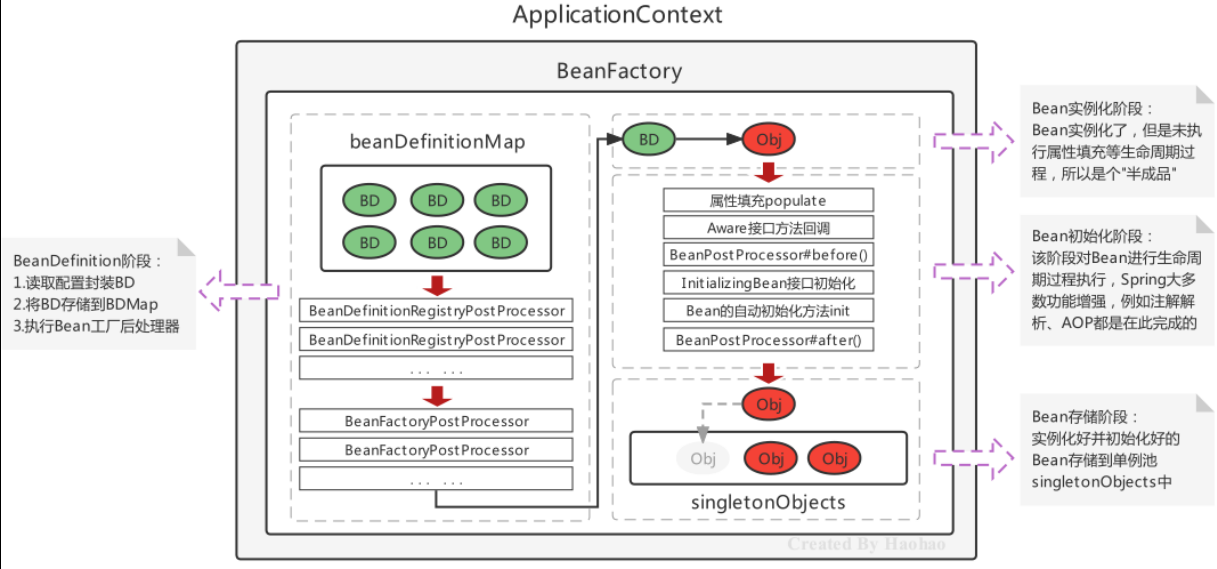
在对文本进行几乎任何自然语言处理之前,都必须对文本进行规范化。至少有三个任务通常作为任何规范化过程的一部分:
1. 分词
2. 规范化词格式
3. 句子分段
让我们从一个简单的(如果有点幼稚的话)单词标记化和非malization(以及频率计算)版本开始,它可以在一个UNIX命令行中单独完成英语,灵感来自Church(1994)。我们将使用一些Unix命令:tr,用于系统地更改输入中的特定字符;Sort,按字母顺序对输入行进行排序;uniq,它折叠并计算相邻的相同线。
例如,让我们从一个文本文件sh.txt中的莎士比亚的“完整单词”开始。我们可以使用tr通过将每个非字母字符序列更改为换行符来对单词进行标记(' a- za -z '表示字母,-c选项com-补充为非字母,-s选项将所有序列压缩为单个字符):
tr -sc ' A-Za-z ' ' \n ' < sh.txt
输出如下:
THE
SONNETS
by
William
Shakespeare
From
fairest
creatures
We

因此,标记化的标准方法是使用基于正则表达式的确定性算法,将正则表达式编译成非常高效的有限状态自动机。
例如,在汉语中,单词是由汉字组成的(在汉语中称为汉字)。每个字符通常代表一个单一的意义单位(称为语素),并且可以作为一个音节发音。单词平均有2.4个字符长。但在汉语中,如何定义一个词是很复杂的。例如,考虑下面的句子:

事实上,对于大多数中文NLP任务来说,采用字符而不是单词作为输入效果更好,因为对于大多数应用程序来说,字符处于合理的语义水平,而且大多数单词标准都会导致包含大量非常罕见的单词的庞大词汇表。 然而,对于日文和泰文,字符是一个太小的单位,因此需要分词算法。在需要单词边界而不是字符边界的罕见情况下,这对中文也很有用。这些语言的标准分割算法使用在手工分割训练集上通过监督机器学习训练的神经序列模型。
使用子词标记很有帮助的一个原因是处理未知单词。
未知单词与机器学习系统特别相关。正如我们将在下一章中看到的,机器学习系统通常会在一个语料库(训练语料库)中学习一些关于单词的事实,然后使用这些事实来对单独的测试语料库及其单词做出决定。因此,如果我们的训练语料库包含,说low,和lowest,但不是lower,但然后这个词lower出现在我们的测试语料库中,我们的系统将不知道如何处理它。这个地方其实意思就是如果训练集里面的词是low和lowest,如果测试集合里面出现了lower,那么模型就不知道如何处理了。
这个问题的解决方案是使用一种标记化,其中大多数标记是单词,但有些标记是频繁的语素或其他子词,如-er,这样就可以通过组合部分来表示未见过的单词。
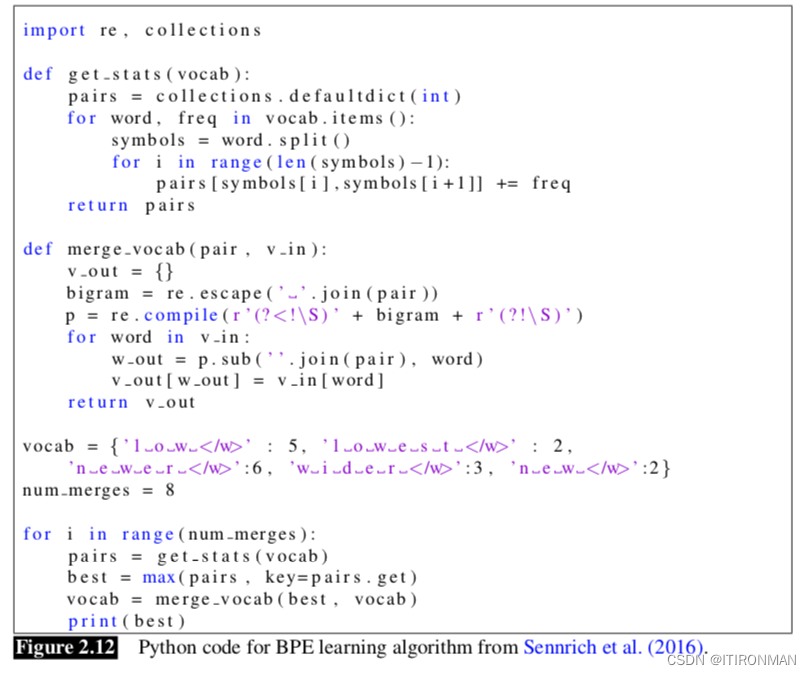
最简单的算法是字节对编码,或BPE (Sennrich et al., 2016)。字节对编码基于一种文本压缩方法(Gage, 1994),但这里我们将其用于标记化。该算法的直觉是迭代地合并频繁的字符对。
该算法从一组等于一组字符的符号开始。每个单词都表示为一个字符序列加上一个特殊的单词结束符号。在算法的每一步,我们计算符号对的数量,找到最频繁的符号对(' A ', ' B '),并用新合并的符号(' AB ')替换它。我们继续计数和合并,创建新的越来越长的字符串,直到我们完成k次合并;K是算法的一个参数。



如下是BEP算法的代码: