目录
MoreKey案例
测试数据
如何向redis数据库中一次性的插入100W条数据
如何将 100W条数据一次性写入redis数据库中
遍历百万、千万级别数据能否使用keys *?
生产上如何限制keys *、flushdb、flushall等危险命令?
不使用keys *使用什么遍历?
使用scan命令——用于迭代数据库中的数据库键
BigKey案例
多大算Big?
如何发现BigKey?
--Bigkeys命令
memory usage
如何删除BigKey?
BigKey生产调优
MoreKey案例
测试数据
如何向redis数据库中一次性的插入100W条数据
生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;
如何将 100W条数据一次性写入redis数据库中
利用redis提供的管道命令 -pipe插入100W条数据
cat /tmp/redisTest.txt | redis-cli -h 本地主机 -p 端口号 -a 密码 --pipe
遍历百万、千万级别数据能否使用keys *?
key * 这个指令有致命的弊端,在实际环境中最好不要使用
keys*这个指令相当于一次性吐出所有key,由于redis是单线程的,所有的操作都是原子性的,keys算法属于遍历算法,时间复杂度是O(n),在实际生产环境中如果执行该指令,可能会导致redis服务卡顿,更严重的可能会导致redis缓存雪崩或者数据库宕机宕机
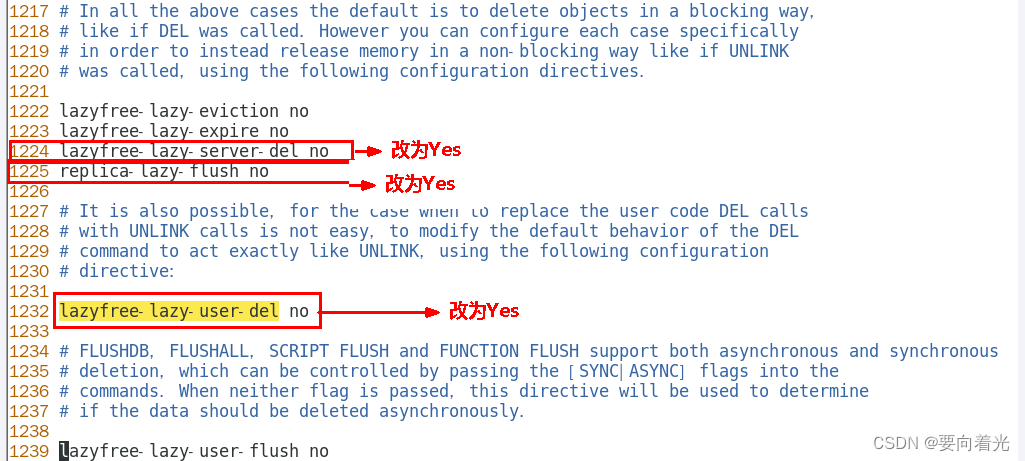
生产上如何限制keys *、flushdb、flushall等危险命令?
通过修改redis.conf配置文件
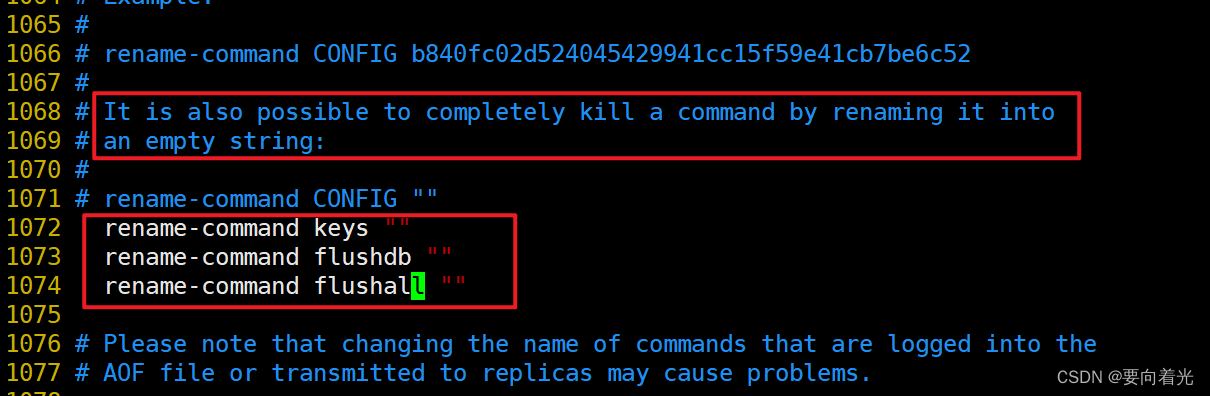
(ps:记得重启redis)
(pps:如果aof及rdb文件中包含了禁用掉的命令,redis会启动失败,需要删除对应aof及rdb文件)
不使用keys *使用什么遍历?
使用scan命令——用于迭代数据库中的数据库键
 语法:
语法:
SCAN cursor [MATCH pattern] [COUNT count]
-cursor:游标
-pattern:匹配的模式
-count:指定从数据集中返回多少元素,默认为10
BigKey案例
大key问题本质上是key对应的value大
多大算Big?
--String是value,最大512M但是超过10kb就是BigKey
--list、set、hash、zset个数超过5000就算是BigKey
如何发现BigKey?
--Bigkeys命令
redis-cli -h 本地主机名 -p 端口号 -a 密码 --bigkeys
给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小,但不能查询到大于10kb的所有key
memory usage

memory usage key
如何删除BigKey?
参考《阿里云Redis开发规范》

BigKey生产调优
redis.conf优化配置