文章目录
- 管道命令(pipe)
- 选取命令:cut、grep
- cut
- 使用案例
- cut的优点缺点
- grep
- 使用案例
- 排序命令:sort、wc、uniq
- sort
- 使用案例
- uniq
- 使用案例
- wc
- 使用案例
- 双向重定向:tee
- 使用案例
- 字符转换命令:tr、col、join、paste、expand
- tr
- 使用案例
- col
- 使用案例
- join
- 使用案例
- paste
- 使用案例
- expand
- 使用案例
- 划分命令:split
- 使用案例
- 参数代码:xargs
- 使用案例
- 关于减号【-】的用途
管道命令(pipe)
有时候我在bash命令执行输出数据的时候,有时候数据必须要经过好几个命令处理后才能得到我们想要的结果。这时候我们就可以时候管道命令,管道命令使用的是【|】这个符号shift + \即可输出。我们来利用管道命令简单的举个例子
假设我们想要知道/etc/下面有多少文件,那么可以利用【 ls /etc】 来查看,不过,因为/etc 下面文件太多了,导致输出以后屏幕很多内容,此时我们可以通过 less命令的协助
[root@localhost ~]# ls /etc/ | less
如此一来,使用ls命令输出后的内容,就能够被less读取,并且利用less功能,我们就可以前后翻动或者/file 查找文件,非常方便。其实这个管道命令【|】仅能处理前一个命令传来的正确信息,也就是标准输出信息,对于标准错误信息并没有直接处理能力。如果对标准输入,标准输出没有了解的人可以查看一下这篇博客: https://blog.csdn.net/qq_52089863/article/details/130366493?spm=1001.2014.3001.5501
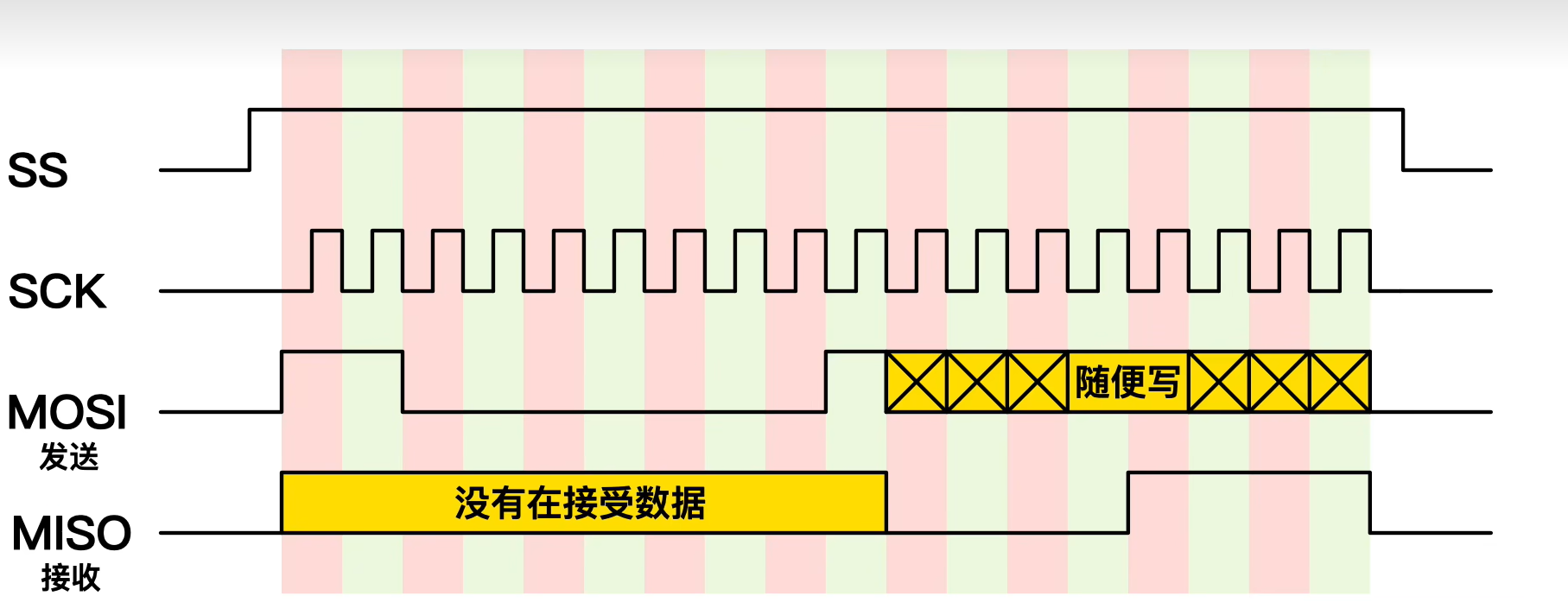
管道命令处理流程图如下所示
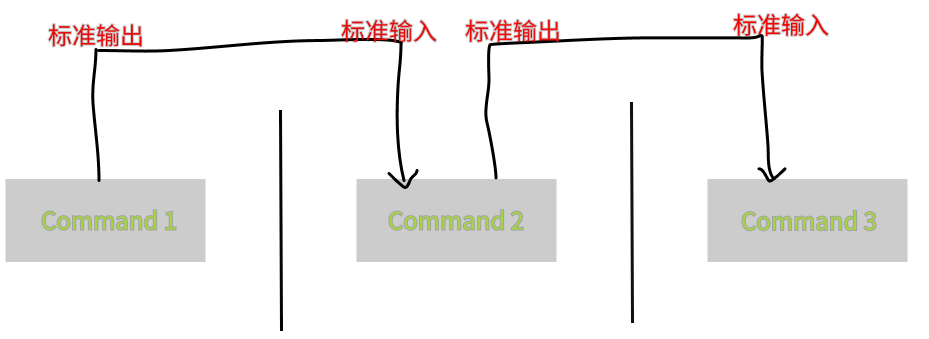
如上图所示,每个管道后面接的第一个数据必定是【命令】,而且这个命令必须能够接受标准输入的数据才行,这样的命令才可为管道命令,如less、more、head、tail 等都是可以接受标准输入的管道命令至于例如 ls、cp、mv等就不是管道命令。因为ls、cp、mv并不会接受来自stdin的数据,也就是说,管道命令主要有两个比较特殊的地方:
管道命令仅会处理标准输出,对于标准错误输出会给予忽略管道命令必须要能够接受来自前一个命令的数据成为标准输入继续处理才行。
如果你硬是要让标准错误可以被管道命令所使用的话,可以这么做。可以使用数据流重定向,让2>&1加入命令中,就可以让2> 变成1>。如果不了解数据流重定向可以参考:https://blog.csdn.net/qq_52089863/article/details/130366493?spm=1001.2014.3001.5501
选取命令:cut、grep
什么是选取命令?就是将一段数据经过分析后,取出我们所想要的,或是经由分析关键词,取得我们所想要的那一行。不过,要注意的是,一般来说,选取信息通常是针对【一行一行】来分析的,并不是整篇信息分析,下面介绍两个很常用的信息选取命令
cut
cut翻译成英格利希的意思就是【切】,这个命令可以将一段信息的某一段给他【切】出来,处理的信息就是以【行】为单位
cut -d '分隔字符' -f 字段
cut -c 字符区间
选项:
-d:后面接分隔字符,与-f一起使用
-f:根据-d分隔字符将一段信息划分成为数段,用-f取出第几段的意思
-c:以字符的单位取出固定字符的区间
使用案例
- 将PATH变量取出,我要找出第五个路径
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
1 2 3 4 5
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 5
/root/bin
# 如同上面数字显示,我们是以【:】作为分隔,因此会出现/root/bin
如果想要列出第3和第5,可以这样
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 3,5
/usr/sbin:/root/bin
- 将export输出的信息,取得第12字符以后的所有字符
[root@localhost ~]# export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="localhost.localdomain"
declare -x LANG="zh_CN.UTF-8"
declare -x LESSOPEN="||/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="root"
.....
.......
...
# 注意看,每个数据都是整齐的输出,如果我们不想要【declare -x 】时,就得这样做
[root@localhost ~]# export | cut -c 12-
HISTCONTROL="ignoredups"
HISTSIZE="1000"
HOME="/root"
HOSTNAME="localhost.localdomain"
LANG="zh_CN.UTF-8"
LESSOPEN="||/usr/bin/lesspipe.sh %s"
LOGNAME="root"
...........
......
...
用last将显示的登录者的信息中,仅留下使用者的大名
[root@localhost ~]# last
root pts/1 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/0 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/1 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
root pts/0 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 15:51 - 09:37 (17:45)
.....
.......
...
# last 可以输出【账号/终端/来源/日期时间】的数据,并且是排列整齐的。
[root@localhost ~]# last | cut -d ' ' -f 1
root
root
root
root
reboot
root
root
.....
.......
...
# 由输出的结果我们可以发现第一个空白分隔的栏位代表账号,所以使用如上命令
# 但是因为root pts/1 之间空格有好几个,并非仅有一个,所以,如果要找出
# pts1/1 其实不能以 cut -d ' ' -f 1,2 输出结果会不是我们想要的
cut的优点缺点
优点:
-
可以在不改变原始文件的情况下,从一个文件中提取部分内容,具有较高的安全性和可靠性。
-
可以将文件内容按照指定的规则进行切割,实现定制化的处理需求。
-
可以将切割后的文件内容输出到指定的位置,方便后续处理和使用。
-
可以处理大文件,并且速度较快。
缺点:
-
不支持对文件内容进行修改,只能对文件内容进行切割和提取,限制了其功能的扩展性。
-
对于复杂的文件处理需求,需要使用其他工具进行辅助处理。
-
对于非常规的文件格式,可能无法正确处理文件内容。
-
操作命令较为繁琐,需要熟悉命令语法和参数。
grep
刚刚的cut是将一行信息当中,取出某部分我们想要的,而grep则是分析一行信息,若当中有我们所需要的信息,则将该行拿出来,简单的语法是这样的。
grep [-acinv] [--color=auto] '查找字符' filename
选项:
-a:将二进制以文本文件的方式查找数据
-c:计算找到'查找字符'的次数
-i:忽略大小写的不同,所以大小写视为相同
-n:顺便输出行号
-v:反向选择,就是显示出没有'查找字符'内容的那一行
--color=auto:可以将找到的关键字的那一行加上颜色显示
使用案例
last当中,又出现root的那一行就显示出来
[root@localhost ~]# last | grep 'root'
root pts/1 192.168.100.1 Wed Apr 26 09:42 still logged in
root pts/0 192.168.100.1 Wed Apr 26 09:42 still logged in
root pts/1 192.168.100.1 Wed Apr 26 09:42 - 09:42 (00:00)
root pts/0 192.168.100.1 Wed Apr 26 09:42 - 09:42 (00:00)
root pts/1 192.168.100.1 Wed Apr 26 08:42 - down (00:59)
....
......
与上述案例相反,只要没有root就取出
[root@localhost ~]# last |grep -v 'root'
reboot system boot 3.10.0-1160.el7. Wed Apr 26 09:42 - 14:05 (04:22)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 15:51 - 09:42 (17:50)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 09:07 - 09:42 (1+00:34)
reboot system boot 3.10.0-1160.el7. Mon Apr 24 20:40 - 09:42 (1+13:01)
....
...
在last的输出信息中,只要有root就取出,并且仅取第一栏
[root@localhost ~]# last |grep 'root'|cut -d ' ' -f 1
root
root
root
root
root
.......
....
# 在last输出信息中,利用cut命令的处理,就能够仅取第一栏
取出/etc/man_db.conf 内含MANPATH的那几行
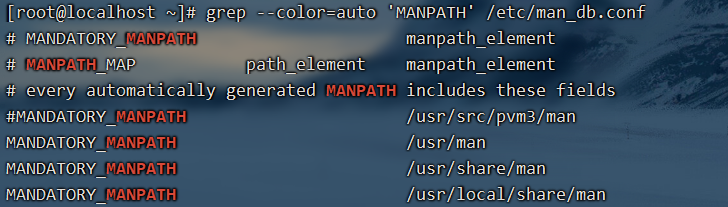
加上–color=auto 的选项,找到的关键字部分会用特殊颜色显示,但是不加也会显示,因为centos7系统中,默认已经将–color=auto 选项加入到了alias中了。
想要详细了解grep 可以参考这篇博客:https://blog.csdn.net/qq_52089863/article/details/129581762
排序命令:sort、wc、uniq
很多时候,我们都会区计算一次数据里面的相同形式的数据总数,举例来说,使用last可以查得系统上面有登录主机者的身份。那么我可以针对每个用户查出它们的总登录次数吗?此时就要排序与计算之类的命令来辅助,下面介绍一下几个好用的排序与统计的命令。
sort
sort它可以帮我们进行排序,而且可以根据不同的数据形式来排序,例如数字与文字的排序就不一样。此外,排序的字符与语系的编码有关,因此,如果你需要排序时,建议使用LANG=C让语系统一,数据排序比较好一点
sort [-fbMnrtuk] [file 或 stdin]
选项:
-f:忽略大小写的差异,例如A与a视为编码相同
-b:忽略最前面的空格字符部分
-M:以月份的名字来排序,例如JAN、DEC等排序方法
-n:使用【纯数字】进行排序(默认是以文字形式来排序的)
-r:反向排序
-u:就是uniq,相同的数据中,仅出现一行代表。
-t:分隔符号,默认是使用[TAB]键来分隔
-k:以哪个区间来进行排序的意思。
使用案例
个人账号都记录在/etc/passwd下,请将账号进行排序
[root@localhost ~]# cat /etc/passwd | sort
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
csq:x:1000:1000::/home/csq:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....
...
# 直接输入sort 默认是以【文字】形式来排序的,所以由a开始排序到最后
/etc/passwd内容是以【:】分隔的,我想以第三栏来排序,该如何?
[root@localhost ~]# cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
csq:x:1000:1000::/home/csq:/bin/bash
zhw:x:1001:1001::/home/zhw:/bin/bash
zzh:x:1002:1002::/home/zzh:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
....
......
..
# 发现了吗sort默认是以文字形式来排序的,如果想要数字排序
# cat /etc/passwd | sort -t ':' -k 3 -n 这样才行 加上-n来告知sort是以数字来排序
利用last,将输出的数据仅显示账号,并加以排序
[root@localhost ~]# last | cut -d ' ' -f 1 | sort
sort是很常用的命令,例如上面的第二个例子,假设你有很多账号,而且你想要知道最大的用户ID目前到哪一个了。使用sort就可以知道答案。
uniq
如果我完成了排序,我想要将重复的数据仅列出一个显示,可以怎么做呢?
uniq [-ic]
选项:
-i:忽略大小写字符的不同
-c:进行计数
使用案例
使用last将账号列出,仅取出账号栏,进行排序后,仅取出一位
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq
reboot
root
wtmp
如果我还想要知道每个人登录的总次数呢?
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq -c
1
7 reboot
34 root
1 wtmp
# 1.先将所有的数据列出来 2.再将人名独立出来 3.经过排序 4.只显示一个
# 从上述案例得知可以发现reboot出现了7次,root登录则有34次,大部分都是root在登录
# wtmp与第一行的空白都是last的默认字符,两个可以忽略
这个命令用来将重复的行删除掉只显示一个,举例来说,你要知道这个月登录你主机的用户有谁,而不在乎它的登录次数,那么就可以使用上面的案例。
wc
如果我想知道/etc/man_db.conf 这个文件里面有多少文字?多少行?多少字符?,可以利用wc这个命令来完成,它可以帮我们计算出信息的整体数据
wc [-lwm]
选项:
-l:仅列出行
-w:仅列出多少字
-m:多少字符
使用案例
man_db.conf里面到底有多少行、字数、字符数呢?
[root@localhost ~]# cat /etc/man_db.conf | wc
131 723 5171
# 输出的三个数字中,分别代表:【行、字数、字符数】
使用last可以输出登录者,但是last最后两行并非账号内容,那么请问,我该如何以一行命令串取得登录系统的总人次呢?
[root@localhost ~]# last |grep [a-zA-z] |grep -v 'wtmp' | grep -v 'reboot' | wc -l
34
# 由于last会输出空白行,wtmp、reboot等无关账号登录的信息,因此,利用grep 取出非空白行,以及取出上述关键字的那几行,在计算行数,就好了。
双向重定向:tee
前面我们了解过数据流重定向知道【>】会将数据流整个传送给文件或设备,因此我们除非去读取该文件或设备,否则就无法继续利用整个数据流。那如果我想要将整个数据流处理过程中将某段信息存下来,应该怎么做呢?利用tee就行
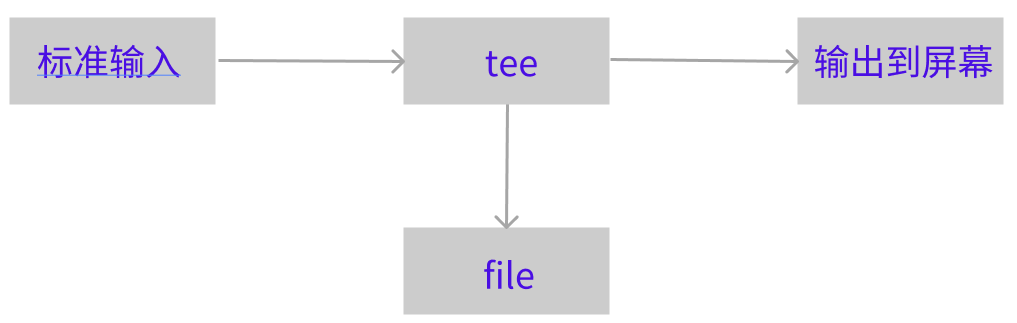
tee会同时将数据流分送到文件与屏幕,而输出到屏幕,其实是stdout,那就可以让下个命令继续处理
tee [-a] file
选项:
-a:以累加的方式,将数据加入file当中
使用案例
将last输出存一份到last.list文件中
[root@localhost ~]# last | tee last.list | cut -d " " -f 1
root
root
root
root
......
...
将ls -l /home 的数据存一份到~/homefile,同时屏幕也有输出信息
[root@localhost ~]# ls -l /home | tee ~/homefile
total 0
drwx------. 2 csq csq 162 Apr 25 14:48 csq
drwx------. 2 zhw zhw 62 Apr 25 09:52 zhw
drwx------. 2 zzh zzh 62 Apr 25 09:52 zzh
# 如果信息很多的话在后面可以加一个【 | less】
再ls -l /etc的数据累加到~/homefile中,同时屏幕也要输出信息
[root@localhost ~]# ls -l /etc/ | tee ~/homefile | less
# 是否累加成功可以自行查看
字符转换命令:tr、col、join、paste、expand
tr
可以用来删除一段信息当中的文件,或是进行文字信息的替换
tr [-ds] SET1 ....
选项:
-d:删除信息当中的SET1字符
-s:替换掉重复的字符
使用案例
将last输出的信息中,所有的小写变成大写字符
[root@localhost ~]# last | tr '[a-z]' '[A-Z]'
ROOT PTS/1 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
ROOT PTS/0 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
.....
...
将/etc/passwd 输出信息中,将冒号【:】删除
[root@localhost ~]# cat /etc/passwd | tr -d ':'
rootx00root/root/bin/bash
binx11bin/bin/sbin/nologin
daemonx22daemon/sbin/sbin/nologin
admx34adm/var/adm/sbin/nologin
.....
...
将/etc/passwd转成dos换行到/root/passwd中,再将^M符号删除
如果不知道dos换行可以参考:https://blog.csdn.net/qq_52089863/article/details/130276325?spm=1001.2014.3001.5501
[root@localhost ~]# cp -rf /etc/passwd ~/passwd && unix2dos ~/passwd
unix2dos: converting file /root/passwd to DOS format ...
[root@localhost ~]# file ~/passwd
/root/passwd: ASCII text, with CRLF line terminators # 这就是DOS换行
[root@localhost ~]# cat ~/passwd | tr -d '\r' > ~/passwd.Linux
[root@localhost ~]# ll /etc/passwd ~/passwd*
-rw-r--r--. 1 root root 957 Apr 25 09:52 /etc/passwd
-rw-r--r--. 1 root root 979 Apr 26 15:12 /root/passwd
-rw-r--r--. 1 root root 957 Apr 26 15:12 /root/passwd.Linux
# 处理过后,发现文件大小与原本的/etc/passwd就一致了
上述案例,为什么可以使用\r替换?
回车符(Carriage Return)或者 \r 是一个控制字符,它在DOS/Windows系统中作为换行符的一部分存在,表示将光标移动到行首。在Linux和Unix系统中,换行符只有一个,是一个叫做 Line Feed 的字符,也就是 \n。
因此,当我们在Linux系统中使用cat命令查看一个DOS/Windows系统中的文本文件时,会看到很多 ^M 字符,这是因为 ^M 是 \r 的可见表示。而在Linux系统中,这个字符并不是换行符的一部分,因此需要将它替换掉。
tr命令可以用来替换文本中的字符,其中 -d 选项表示删除指定的字符,因此 tr -d ‘\r’ 表示删除文本中的 \r 字符。所以,使用 tr -d ‘\r’ 命令可以将 DOS/Windows 格式的文本文件转换为 Linux 格式。
col
col [-xb]
选项:
-x:将tab键转换成对的空格键
使用案例
利用cat -A 显示出所有的特殊按键,最后以col 将[TAB]转成空白
[root@localhost ~]# cat -A /etc/man_db.conf
# 执行完这个命令你就看到很多^I的符号,那就是tab
[root@localhost ~]# cat /etc/man_db.conf | col -x | cat -A |less
# 执行完命令就可以看到所有的[TAB]按键会被替换成为空格键
col的用途就是简单的处理[tab]按键替换成空格键。
join
join翻译成英格利希的意思就是(参加/加入),它是在处理两个文件之前的数据,而且,主要是在处理【两个文件当中,有相同数据的那一行,才将它加在一起的意思。
join [-ti12] file1 file2
选项:
-t:join默认以空格字符分隔数据,并且比对【第一个栏位】的数据
如果两个文件相同,则将两条数据连成一行,且第一个栏位放在第一个
-i:忽略大小写的差异
-1:这个是数字的1,代表【第一个文件要用哪个栏位来分析】的意思
-2:代表【第二个文件要用哪个栏位来分析】的意思
使用案例
用root身份,将/etc/passwd与/etc/shadow相关数据整合成一栏
[root@localhost ~]# head -n 3 /etc/passwd /etc/shadow
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/shadow <==
root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:*:18353:0:99999:7:::
daemon:*:18353:0:99999:7:::
# 由于输出的数据可以发现在两个文件的最左边栏都是相同账号,且以:分隔
[root@localhost ~]# join -t ':' /etc/passwd /etc/shadow | head -n 3
root:x:0:0:root:/root:/bin/bash:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:18353:0:99999:7:::
# 通过上面的操作,我们可以将两个文件第一栏位相同者整合成一行
# 第二个文件的相同栏位并不会显示(因为已经在最左边的栏位出现了)
我们知道/etc/passwd 第四个栏位是GID,这个GID记录在/etc/group 当中的第三个栏位,请问如何将两个文件整合?
[root@localhost ~]# head -n 3 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/group <==
root:x:0:
bin:x:1:
daemon:x:2:
# 从上面可以看出确实有相同的部分
[root@localhost ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
0:root:x:0:root:/root:/bin/bash:root:x:
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:
# 同样的,相同的栏位部分移动到了最前面,所以第二个文件的内容就每显示
paste
这个paste就要比join简单多了。相对于join必须要比对两个文件的数据相关性,paste就直接将两行贴在一起,且中间以【TAB】键隔开
paste [-d] file1 file2
选项:
-d:后面可以接分隔字符,默认是以【TAB】来分隔
- :如果file部分写错了 -,表示来自标准输入的数据的意思
使用案例
用root的身份,将/etc/passwd与/etc/shadow同行贴在一起,且仅取出前3行
[root@localhost ~]# paste /etc/passwd /etc/shadow - |head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7:::
# 注意同一行间是以【TAB】按键隔开的可以仔细看一下
先将/etc/group读出(用cat),然后与上述案例的那两个文件忒在一起,且仅取出前3行
[root@localhost ~]# cat /etc/group | paste /etc/passwd /etc/shadow - | head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7::: root:x:0:
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7::: bin:x:1:
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7::: daemon:x:2:
expand
这个命令就是在将【TAB】按键转成空格键
expand [-t] file
选项:
-t:后面可接数字,一般来说一个TAB按键可以用8个空格键来替换
我们也可以自定义一个【TAB】按键代表多少个字符
使用案例
将/etc/man_db.conf 内行首的MANPATH的字样就取出,仅取前三行
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
MANPATH_MAP /sbin /usr/share/man
# 行首的 ^ 的意思是找出以MANPATH的行
上述案例,如果我想要将所有的符号都列出来来?
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# cat -A 可以将【TAB】键显示为【^I】
承接上述案例,我将【TAB】按键设置成6个字符的话?

你可以仔细的看一下上面的数字说明,因为我是以6个字符代表一个【TAB】的长度你可以用 123456来对比一下中间的距离,如果你字符长度设置为 9 或 10就又不同了
还有个命令unexpand是将空格转成【TAB】命令
我们把上述的案例改一下 在让他转成【TAB】命令
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 8 -| unexpand -t 8 - | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# 就像这样 好像转空格了 又好像没转,左右摇摆
划分命令:split
split命令它可以帮你将一个大文件,依据文件大小或行数来划分,就可以将大文件划分为小文件了
split [-bl] file PREFIX
选项:
-b:后面可接欲划分成的文件大小,可加单位,例如b、k、m等
-l:以行数来进行划分
PREFIX:代表前缀字符的意思,可作为划分文件的前缀文字
使用案例
我的/etc/services 有600多K,若想要分成300K一个文件时
[root@localhost ~]# cd /tmp/;split -b 300K /etc/services services
[root@localhost tmp]# ll -k services*
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesaa
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesab
-rw-r--r--. 1 root root 55893 Apr 26 16:10 servicesac
# 这个文件名可随意取,我们只要写上前缀文字,小文件就会以xxxaaa,xxxab,xxxac等方式来建立小文件
如何将上面的三个小文件合成一个文件,文件名servicesback
[root@localhost tmp]# cat services* >> servicesback
[root@localhost tmp]# ls -l servicesback /etc/services
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
-rw-r--r--. 1 root root 670293 Apr 26 16:13 servicesback
使用ls -al /输出的信息中,每十行记录一个文件
[root@localhost tmp]# ls -al /etc/ | split -l 10 - lsroot
[root@localhost tmp]# wc -l lsroot*
0 lsroot
10 lsrootaa
10 lsrootab
10 lsrootac
10 lsrootad
.....
...
# 重点在这个-号,一般来说如果需要stdout或是stdin时,但偏偏又没有文件
# 有的只是 - 时,那么这个 - 就会被当成 stdin或stdout
参数代码:xargs
xargs是在做什么?以字面的意义来看,x是加减乘除的乘号,args则是参数的意思,所以说这个命令就是在产生某个目录的参数的意思。xargs可以读入stdin的数据,并且以空格符或换行符作为识别符,将stdin的数据分隔为参数。因为是以空格符作为分隔,所以,如果有一些文件名或是其他意义的名词内含有空格符的时候,xargs可能就会误判,用法如下
xargs [-0epn] command
选项:
-0:如果输入stdin含有特殊字符,例如:`、\、空格等特殊字符时,这个-0参数
可以将它还原成一般的字符,这个参数可以用于特殊状态
-e:这个是EOF的意思,后面可以接一个字符,当xargs分析到这个1字符时,就会停止工作
-p:在执行每个命令时,都会询问使用者的意思
-n:后面接次数,每次command命令执行时,要使用几个参数的意思
当xargs后面没有接任何命令的时候,默认是以echo 来进行输出
使用案例
将/etc/passwd内的第一栏取出,仅取三行,使用id这个命令将每个账号内容显示出来
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
# 通过-n处理,一次给予一个参数
同上,但是执行id时,都要询问使用者是否操作?
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -p -n 1 id
id root ?...y
uid=0(root) gid=0(root) groups=0(root)
id bin ?...y
uid=1(bin) gid=1(bin) groups=1(bin)
id daemon ?...y
uid=2(daemon) gid=2(daemon) groups=2(daemon)
将所有的/etc/passwd内的账号都以id查看,但查到sync就结束命令串
[root@localhost ~]# cat /etc/passwd | head -n 7
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | xargs -e'sync' -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
uid=3(adm) gid=4(adm) groups=4(adm)
uid=4(lp) gid=7(lp) groups=7(lp)
# 注意上述案例中那个-e'sync'是连在一起的,中间没有空格
# 可以看到我们查看 /etc/passwd sync在第6行,当分析到第6行内容时就自动停止了
关于减号【-】的用途
管道命令在bash的连续的处理程序中是相当重要的。另外,在日志文件的分析中也是相当的重要。在管道命令中,常常会使用到一个命令的标准输出(stdout)作为这次的标准输入(stdin),某些命令需要用到文件名(例如 tar)来进行处理时,该stdin与stdout可以利用减号【-】来替代,举例来说
[root@localhost ~]# tar -cvf - /home | tar -xvf - -C /tmp/homeback/
上面的例子是说:【我将/home里面的文件给他打包,但打包的数据不是记录到文件,而是传送到stdout,经过管道后,将tar -cvf - /home 串送给后面的 tar -xvf -】后面的这个【-】则是使用前一个命令的stdout,因此,我们就不需要文件名了。