目录
NUMA简介
NUMA开启与关闭
查看系统是否支持
关闭方法
numactl --hardware介绍
没有安装numactl工具下查看NUMA架构节点数:
查看每个NUMA节点的CPU使用情况:
看每个NUMA节点的内存使用情况:
查看NUMA下指定进程的运行情况
创建新进程时,指定NUMA的相关属性
新进程在指定节点上运行
新进程在所有节点上运行
NUMA简介
Numa(Non-Uniform Memory Access)是一种计算机架构,它允许多个处理器通过共享内存来访问系统的物理内存,但是不同的内存区域可能由不同的处理器处理,这种内存访问方式被称为“非一致性内存访问”。在这种架构中,每个处理器都有自己的本地内存,但它们可以访问其他处理器的内存。这种架构可以提高多处理器系统的性能,并使系统更具可扩展性。
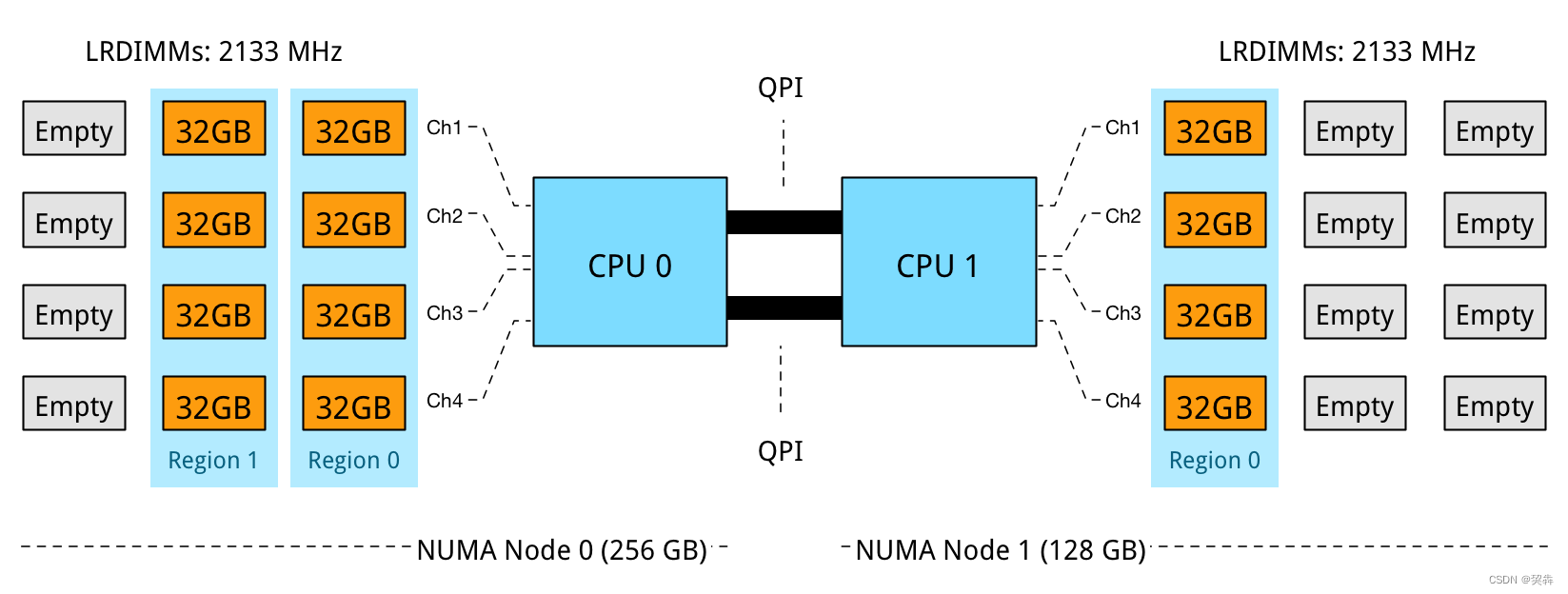
在Numa系统中,每个处理器有一个本地内存子系统,每个本地内存子系统都连接到一个全局内存交换网络。当处理器需要访问内存时,它们可以通过本地内存子系统直接访问本地内存,或者通过全局内存交换网络来访问远程内存。由于本地内存访问速度更快,因此在处理器需要访问本地内存时,它们会尽可能使用本地内存。
Numa架构通常用于高性能计算领域,例如科学模拟和数据分析等领域,以及大型企业服务器等需要高度可扩展性和性能的领域。
NUMA开启与关闭
查看系统是否支持
在大多数情况下,Numa是在硬件级别上实现的,并且通常无法通过软件直接开启或关闭。因此,如果你要使用Numa架构,你需要选择支持Numa的硬件。在现代的多处理器系统中,大多数服务器和工作站都支持Numa。
但是,在某些情况下,操作系统可能会使用不同的策略来管理内存访问,这可能会影响Numa性能。在Linux操作系统中,你可以使用numactl命令来管理Numa策略和配置。例如,可以使用numactl命令将进程绑定到特定的处理器和内存节点,以最大化Numa性能。可以使用以下命令来检查系统是否支持Numa:
$ numactl --hardware
如果系统中没有安装 numactl 工具,需要先安装该工具。在大多数 Linux 发行版中,可以使用以下命令进行安装:
sudo apt-get install numactl # Ubuntu/Debian
sudo yum install numactl # CentOS/Fedora
如果系统支持Numa,它将输出每个处理器和内存节点的详细信息。如果系统不支持Numa,则该命令将输出错误消息。
关闭方法
默认情况下在支持NUMA的硬件上,NUMA是开启的,有时 NUMA 会因为跨区域访问内存,导致速度变慢,因此可以通过 grub.conf 文件修改内存参数 numa=off,关闭该功能。
numactl --hardware介绍
[root@bj05-compute-10e33e16e229 ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 0 size: 261726 MB
node 0 free: 119515 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 1 size: 262144 MB
node 1 free: 118662 MB
node distances:
node 0 1
0: 10 21
1: 21 10 以上输出显示当前系统中有两个节点,分别是节点0和节点1。节点0具有16个物理CPU核心(编号为0到15和32到47),内存大小为261726 MB,可用内存大小为119515 MB。节点1具有与节点0相同数量的物理CPU核心,内存大小为262144 MB,可用内存大小为118662 MB。
表中最后三行的数字表示两个节点之间的距离,这是访问跨节点内存的相对延迟或成本的一种度量。在这种情况下,从节点0到节点0的距离为10,这意味着访问同一节点上的内存比访问另一个节点上的内存更快,后者的距离为21。类似地,从节点1到节点0的距离为21,而从节点1到节点1的距离为10。
没有安装numactl工具下查看NUMA架构节点数:
lscpu | grep numa -i
[secure@bj05-compute-10e33e16e229 ~]$ lscpu | grep numa -i
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
[secure@bj05-compute-10e33e16e229 ~]$
查看每个NUMA节点的CPU使用情况:
[secure@bj05-compute-10e33e16e229 ~]$ numastat -c
Per-node numastat info (in MBs):
Node 0 Node 1 Total
---------- ----------- -----------
Numa_Hit 7216207925 10168038929 17384246853
Numa_Miss 0 0 0
Numa_Foreign 0 0 0
Interleave_Hit 440 437 876
Local_Node 7216168500 10167963974 17384132473
Other_Node 39425 74955 114380
以下是每个统计量的含义:
- Numa_Hit:表示进程成功从该节点的本地内存中获取的内存总量(单位为MB)。
- Numa_Miss:表示进程无法从该节点的本地内存中获取所需内存的总量(单位为MB)。
- Numa_Foreign:表示由于数据已从本地节点迁移而进程在远程 NUMA 节点上访问的内存总量(单位为MB)。
- Interleave_Hit:表示进程从多个节点交错分配的内存中获取的总量(单位为MB)。
- Local_Node:表示进程在每个节点的本地内存中使用的总量(单位为MB)。
- Other_Node:表示在该节点上分配了内存,但无法确定该内存被哪个节点使用,这可能是由于内存映射不完全或跨节点的共享内存导致的。
- Node 0:表示第一个NUMA节点的总内存使用情况(单位为MB)。
- Node 1:表示第二个NUMA节点的总内存使用情况(单位为MB)。
- Total:表示所有节点的总内存使用情况(单位为MB)。
numastat -c命令的输出表示的是自系统启动以来的历史内存使用情况
该输出表明:
- 进程所有访问基本都在在本地节点上完成的,只有很少量内存访问不能确定是否为跨CPU访问。
看每个NUMA节点的内存使用情况:
[secure@bj05-compute-s6-10e33e18e78 ~]$ numastat -m
Per-node system memory usage (in MBs):
Node 0 Node 1 Total
--------------- --------------- ---------------
MemTotal 384921.56 386909.59 771831.15
MemFree 29070.13 31174.23 60244.37
MemUsed 355851.43 355735.36 711586.79
Active 3402.52 4861.70 8264.22
Inactive 1912.20 1788.92 3701.12
Active(anon) 3268.76 4442.04 7710.80
Inactive(anon) 372.28 811.39 1183.66
Active(file) 133.76 419.67 553.43
Inactive(file) 1539.93 977.54 2517.46
Unevictable 897.04 417.89 1314.93
Mlocked 897.04 417.89 1314.93
Dirty 0.04 0.05 0.08
Writeback 0.00 0.00 0.00
FilePages 3111.70 4089.79 7201.49
Mapped 94.89 375.35 470.24
AnonPages 2887.79 2681.98 5569.77
Shmem 1434.30 2680.70 4114.99
KernelStack 18.70 21.51 40.20
PageTables 18.21 20.61 38.83
NFS_Unstable 0.00 0.00 0.00
Bounce 0.00 0.00 0.00
WritebackTmp 0.00 0.00 0.00
Slab 491.14 548.34 1039.48
SReclaimable 181.18 133.42 314.61
SUnreclaim 309.96 414.92 724.88
AnonHugePages 2170.00 1902.00 4072.00
ShmemHugePages 0.00 0.00 0.00
ShmemPmdMapped 0.00 0.00 0.00
HugePages_Total 345088.00 344064.00 689152.00
HugePages_Free 219136.00 145408.00 364544.00
HugePages_Surp 0.00 0.00 0.00
[secure@bj05-compute-s6-10e33e18e78 ~]$ free -g
total used free shared buff/cache available
Mem: 753 687 58 4 7 56
Swap: 0 0 0
MemFree显示每个节点当前可用的内存。
查看NUMA下指定进程的运行情况
numastat -p <pid>
其中,<pid> 是要查看的进程 ID。该命令将显示指定进程在每个节点上的 CPU 使用情况。以下是一个kvm虚拟机进程示例输出:
[root@bj05-compute-s6-10e33e18e78 ~]# numastat -p 4080714
Per-node process memory usage (in MBs) for PID 4080714 (qemu-kvm)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 16384.00 0.00 16384.00
Heap 77.62 0.00 77.62
Stack 0.91 0.00 0.91
Private 204.70 35.27 239.96
---------------- --------------- --------------- ---------------
Total 16667.22 35.27 16702.48
[root@bj05-compute-s6-10e33e18e78 ~]#
该输出表明,进程的主要 CPU 使用量在节点 0上,而在其他节点上几乎没有 CPU 使用量。
numastat命令本身并不知道该进程是qemu-kvm进程。输出中显示的进程名称是由操作系统内核提供的,通过查询进程的PID获取。在该输出中,操作系统内核提供了PID为4080714的进程的相关信息,并将其标记为qemu-kvm进程。因此,numastat命令只是输出了该进程在 NUMA 节点上的内存使用情况,并没有直接提供关于该进程的详细信息,如进程名称、用户、进程状态等等
创建新进程时,指定NUMA的相关属性
新进程在指定节点上运行
要在创建进程时指定NUMA相关信息,可以使用numactl命令的--membind和--cpunodebind选项。--membind选项用于将进程的内存绑定到指定的NUMA节点,而--cpunodebind选项用于将进程的CPU绑定到指定的NUMA节点。
例如,要将一个名为myprog的进程绑定到NUMA节点0上的内存和CPU,可以使用以下命令:
numactl --membind=0 --cpunodebind=0 ./myprog
这将创建一个进程,它的内存和CPU都绑定在NUMA节点0上。可以根据需要将--membind和--cpunodebind选项设置为不同的NUMA节点编号。
新进程在所有节点上运行
要将进程绑定到所有的CPU和内存上,您可以使用numactl命令的--interleave=all选项。这将使操作系统在所有NUMA节点之间交错分配内存,从而使进程能够在所有的NUMA节点上运行。
以下是一个使用numactl命令将进程绑定到所有CPU和内存上的示例:
numactl --interleave=all ./myprog
这将创建一个进程,它的内存将被交错分配到所有的NUMA节点上,从而使进程能够在所有的NUMA节点上运行。CPU将被自动绑定到系统中可用的所有CPU上。
需要注意的是,将进程绑定到所有的CPU和内存上可能会影响性能,因为在NUMA节点之间交错分配内存可能会导致额外的内存访问延迟。因此,在使用--interleave=all选项时,需要谨慎考虑其对性能的影响,并进行必要的基准测试和优化。