[TOP] LSTM/循环神经网络的理解
前言自省:
- 作为一名已经研究深度学习网络多年的研究员,虽曾多次浅尝LSTM这种网络,但是都没有花时间对其进行深刻解读。
- 本文只谈对LSTM在逻辑思想上的理解,不进行技术解析。
1. 经典LSTM原理图
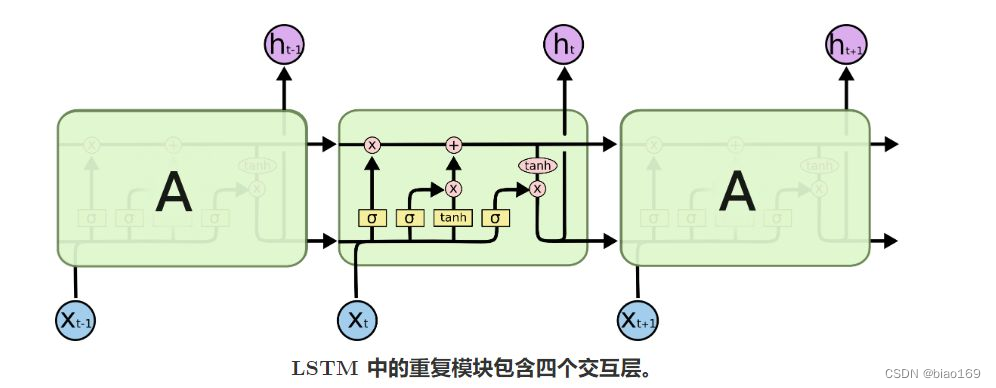
这里边涉及“遗忘门”、“记忆门”、“输出门”,具体解析可以参考:
-
【知乎】LSTM - 长短期记忆递归神经网络
-
“Understanding LSTM Networks.” Understanding LSTM Networks – Colah’s Blog
2. “长短时”记忆关于时间概念的理解
因为在pytorch里边,LSTM网络需要先定义输入的维度尺寸。
见下方代码,可以看到:
- LSTM网络在没有预给定隐藏层状态 hidden时(A处)
lstm在输出中包含隐藏层的状态,即hidden。可以看到这个hidden的维度和batch有关,而和seq_len无关。这不禁疑问, - 如此,在预定义隐藏层状态时(B处)
定义的矩阵岂不是需要batch的信息。会略微麻烦。因为,一般地,我们都希望batch的信息和网络没有关系。
lstm = nn.LSTM(10, 20, 6, batch_first=True) # input_len, hidden_size, num_layers
x = torch.ones([2, 3, 10]) # [batch, seq_len, input_len]
y, hidden = lstm(x, ) # A
print(y.shape)
print('hidden:', hidden[0].shape, hidden[1].shape , len(hidden))
# >> torch.Size([6, 2, 20]) torch.Size([6, 2, 20]) 2
y, hidden = lstm(x, hidden) # B
print(y.shape)
print('hidden:', hidden[0].shape, hidden[1].shape , len(hidden))
# >> torch.Size([6, 2, 20]) torch.Size([6, 2, 20]) 2
初理解: [LSTM最初是用于语义理解,即,解读文本预测与生成]
假如:
- 每个句子长度为3,即有3个词/字。 ===> seq_len = 3
- 每次输入网络的有2个句子。 ===> batch = 2
- 所有使用的词/字种类为10种,即词向量维度为10。 ===> input_len=10
那么,
- 网络会依次读取这2个句子的第一个词,第二个词……
- 循环3次(seq_len)次后结束
这里
循环的思想在于
LSTM会逐字读取
- x_{t-1} 为句子中的上一个词,x_{t}为当前词;所以,每个词都会考虑到上一个词的影响
LSTM 句子间的关联
- 按股票预测的案例(seq_len=1),每个batch内对于一个时间区内的 batch个时刻。每个时刻前后是有关联的,即,长短时记忆能力。
- 因为hidden是可以选择保存到下一个batch使用的,因此,长时间记忆的功能在此体现。
但,说实话,一个batch内的时序关系,体现不是很明显。从hidden参数来看,它们共用一个矩阵,这更像是cnn的整体考量,而不是有时序关系的逐一考量。
自我感觉,本文对LSTM的体悟纯正一定的缺漏和不足,请读者海涵!