目录
1.代码下载
2.数据集准备(.xml转.txt)
(1)修改图像文件名
(2)图片和标签文件数量不对应,解决办法
(3).xml转.txt
(4).txt文件随机划分出对应的训练集、测试集、验证集
3.训练数据集
(1)修改.yaml文件
(2)修改网络参数
(3)训练中断
1.代码下载
论文地址:https://arxiv.org/abs/2207.02696
论文代码下载地址:mirrors / WongKinYiu / yolov7 · GitCode
2.数据集准备(.xml转.txt)
(1)修改图像文件名
制作数据集运用到的一些功能代码_桦拾的博客-CSDN博客
(2)图片和标签文件数量不对应,解决办法
通过以下代码进行对比后,输出多余文件名,自己再根据实际情况和需要进行增删文件:python 两个文件夹里的文件名对比_inspur秃头哥的博客-CSDN博客
# -*- coding: utf-8 -*-
import os
path1 = r'./train'
path2 = r'./train_xml'
def file_name(image_dir,xml_dir):
jpg_list = []
xml_list = []
for root, dirs, files in os.walk(image_dir):
for file in files:
jpg_list.append(os.path.splitext(file)[0])
for root, dirs, files in os.walk(xml_dir):
for file in files:
xml_list.append(os.path.splitext(file)[0])
print(len(jpg_list))
diff = set(xml_list).difference(set(jpg_list)) # 差集,在a中但不在b中的元素
for name in diff:
print("no jpg", name + ".xml")
diff2 = set(jpg_list).difference(set(xml_list)) # 差集,在b中但不在a中的元素
print(len(diff2))
for name in diff2:
print("no xml", name + ".jpg")
if __name__ == '__main__':
file_name(path1,path2)
(3).xml转.txt
(需增加或减少数据集种类,只需修改classes列表、if语句部分,以及print部分;对应文件夹目录也需修改)
将xml转化为yolov5的训练格式txt - 知乎
import os
from glob import glob
import xml.etree.ElementTree as ET
xml_dir = r'F:\datasets\tomato_dataset\xml'####xml文件夹
output_txt_dir = r'F:\datasets\tomato_dataset\txt'####输出yolo所对应格式的文件夹
###进行归一化操作
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def load_xml():####这里是你自己的分类
classes = ['bruise','crack','blackspot', 'rot']
xml_list = glob(os.path.join(xml_dir, '*.xml'))
# print(len(xml_list), xml_list)
count_pictures = {}
count_detection = {}
count = 0
class_num0 = 0
class_num1 = 0
class_num2 = 0
class_num3 = 0
class_num4 = 0
class_num5 = 0
for file in xml_list:
count = count + 1
imgName = file.split('\\')[-1][:-4] # 文件名,不包含后缀
imglabel = os.path.join(output_txt_dir, imgName + '.txt') # 创建TXT(文件夹路径加文件名加.TXT)
# print(imglabel)
out_file = open(imglabel, 'w', encoding='UTF-8') # 以写入的方式打开TXT
tree = ET.parse(file)
root = tree.getroot()
for child in root:
if child.tag == 'size':
w = child[0].text
h = child[1].text
if child.tag == 'object':
x_min = child[4][0].text
y_min = child[4][1].text
x_max = child[4][2].text
y_max = child[4][3].text
box = convert((int(w), int(h)), (int(x_min), int(x_max), int(y_min), int(y_max)))
label = child[0].text
if label in classes:##按照上面的顺序填写标签,如果超过这些自己增加复制就行了
if label == 'bruise':
label = '0'
class_num0 += 1
out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n') # 把内容写入TXT中
if label == 'crack':
label = '1'
class_num1 += 1
out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')
if label == 'blackspot':
label = '2'
class_num2 += 1
out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')
if label == 'rot':
label = '3'
class_num3 += 1
out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')
print('ALL:', count, " bruise:", class_num0, " crack:", class_num1, " blackspot:", class_num2,
" rot:", class_num3)
return len(xml_list), classes, count_pictures, count_detection # return 用在函数内部表示当调用该函数时,
if __name__ == '__main__':
classes = load_xml()
print(classes)(4).txt文件随机划分出对应的训练集、测试集、验证集
此代码生成相应的 train.txt; val.txt; test.txt 文件。

YOLOv7保姆级教程(个人踩坑无数)----训练自己的数据集_AmbitionToFree的博客-CSDN博客
# 将图片和标注数据按比例切分为 训练集和测试集
# 直接划分txt文件jpg文件
#### 强调!!! 路径中不能出现中文,否则报错找不到文件
import shutil
import random
import os
# 原始路径
image_original_path = r"E:\0_net_code\datasets\images"
label_original_path = r"E:\0_net_code\datasets\txt"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
print("----------")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
print("----------")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
print("----------")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
print("----------")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
print("----------")
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + '\\' + name + '.jpg'
srcLabel = label_original_path + '\\' + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()3.训练数据集
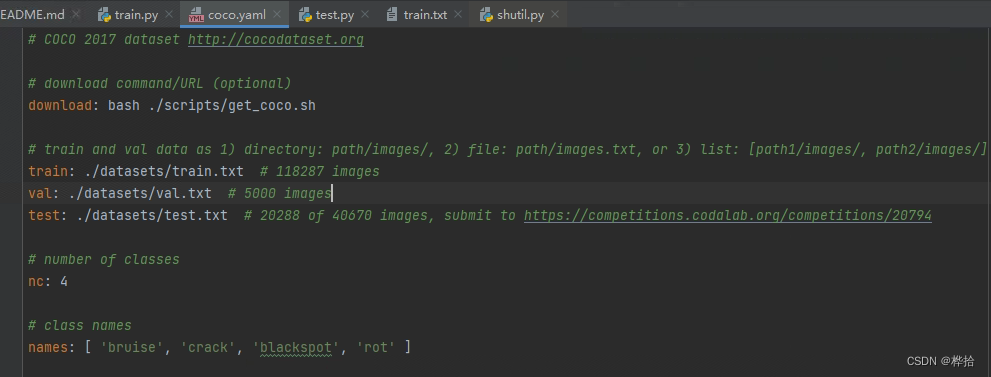
(1)修改.yaml文件
根据自己数据集情况,修改数据集文件路径、数据集种类、标签名
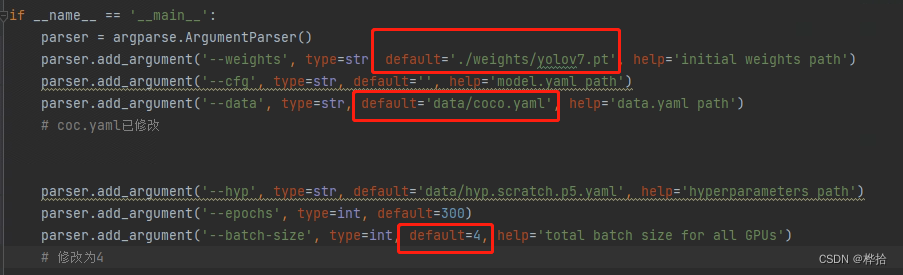
(2)修改网络参数
根据GPU情况修改参数,注意权重文件路径、yaml文件路径
(3)训练中断
若训练中断,可从最新的epcho开始训练,将resume参数的default改为True即可。