函数
- 1.前言
- 2. 什么是函数
- 3. 库函数
- 3.1 为什么会有库函数
- 3.2 如何学习库函数
- 3.3 参考文档学习库函数
- 3.31 strcpy函数
- 3.32 memset函数
- 3.33 使用库函数应该包含的头文件
- 4.自定义函数
- 5.函数的参数
- 5.1 交换两数题目详解
- 6. 函数的调用
- 6.1 传址调用
- 6.2 传值调用
- 7. 函数的嵌套调用和链式访问
- 7.1 嵌套调用
- 7.2 链式访问
- 8. 函数的声明和定义
- 8.1 函数的定义
- 8.2 函数的声明
- 9. 函数递归
- 9.1 什么是递归
- 9.2 使用递归的两个必要条件
- 9.3 递归练习(画图讲解)
- 9.31 打印1 2 3 4
- 9.32 求字符串长度
- 9.4 递归常见错误
- 10. 总结
1.前言
让我们紧接前一章的内容分支与循环,本章将收录于专栏C语言学习分享中,有兴趣学习更多C语言知识的可以跳转至上面内容.本篇文章将给大家详细介绍有关函数的内容
2. 什么是函数
数学中我们常见到函数的概念。但是你了解C语言中的函数吗?
维基百科中对函数的定义:子程序
- 在计算机科学中,子程序(英语:Subroutine, procedure, function, routine, method,
subprogram, callable unit),是一个大型程序中的某部分代码, 由一个或多个语句块组
成。它负责完成某项特定任务,而且相较于其他代 码,具备相对的独立性。- 一般会有输入参数并有返回值,提供对过程的封装和细节的隐藏。这些代码通常被集成为软件库。
C语言中的函数分类:
- 库函数
- 自定义函数
3. 库函数
像我们平常使用的scanf,printf函数就是库函数,是C语言自带的函数.那么为什么会出现库函数?
3.1 为什么会有库函数
- 我们知道在我们学习C语言编程的时候,总是在一个代码编写完成之后迫不及待的想知道结果,想把这个结果打印到我们的屏幕上看看。这个时候我们会频繁的使用一个功能:将信息按照一定的格式打印到屏幕上(printf)。
- 在编程的过程中我们会频繁的做一些字符串的拷贝工作(strcpy)。
- 在编程的同时我们也会遇见计算,总是会计算n的k次方这样的运算(pow)。
像上面我们描述的基础功能,它们不是业务性的代码。我们在开发的过程中每个程序员都可能用的到, 为了支持可移植性和提高程序的效率,所以C语言的基础库中提供了一系列类似的库函数,方便程序员进行软件开发。
3.2 如何学习库函数
既然C语言的很多功能库函数都已经帮我们实现过了,那么我们怎么样去学习库函数呢?
这里我给大家推荐一个网站:cplusplus 它类似于一个c语言的字典,我们可以在这个网站里搜索所有有关c语言的库函数. 若有同学找不到搜索栏,那你可能是进的最新的官网,我们只需要点击右上角的 legacy version 就可以切换到老版本开始搜索了

当我们进入这个界面后会看见我们熟悉的头文件和一些没有见过的头文件:
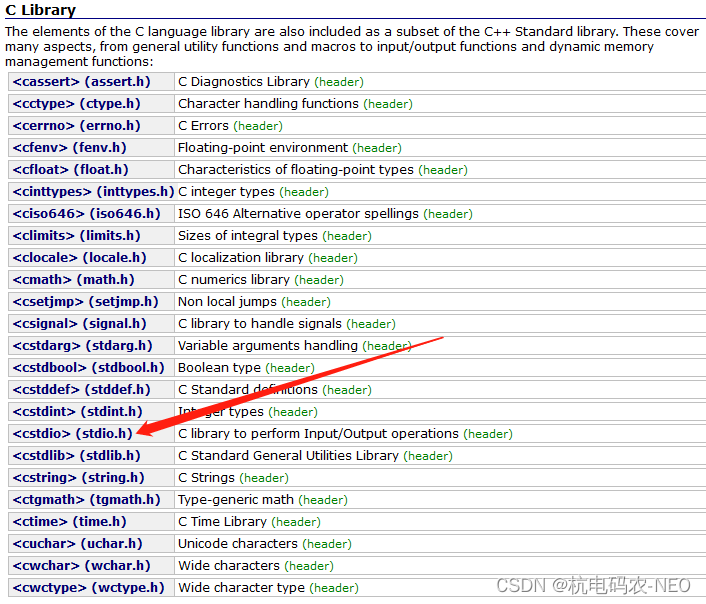
比如说我们点击我们熟悉的stdio.h头文件中,我们就可以看见这个头文件所包含的所有库函数
包括我们熟悉的scanf函数和printf函数
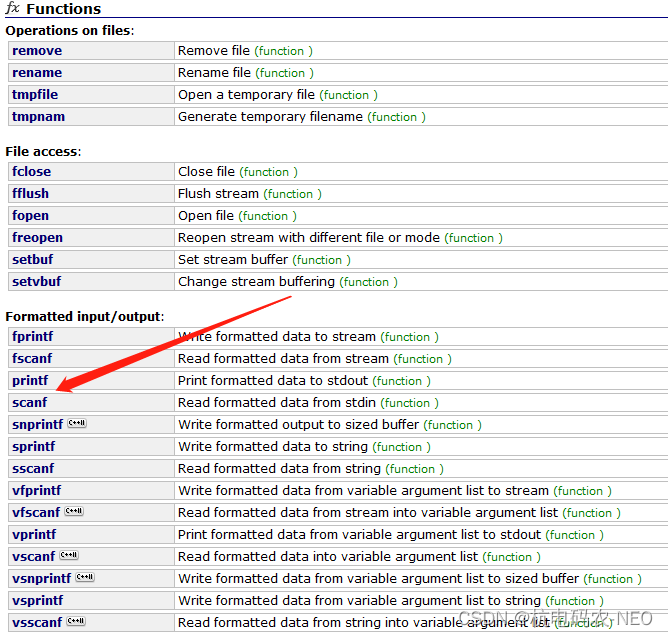
当然如果你想搜索学习某个特定特定的函数也可以直接在上面搜索.
3.3 参考文档学习库函数
下面我们就参考cplusplus上面的文档来学习两个库函数:
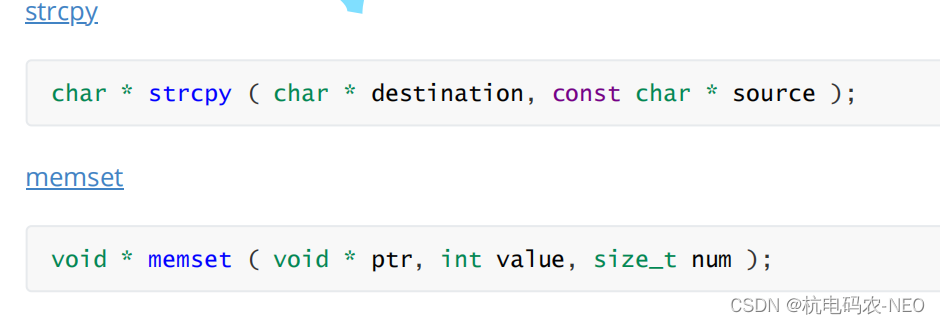
3.31 strcpy函数
我们先在搜索栏搜索strcpy:

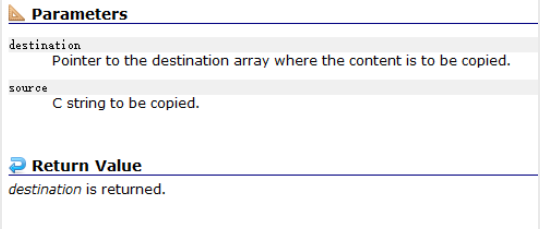
在文档给出的信息中可以看到strcpy函数的返回类型是char*,并且它接受两个char*类型的变量, 我们知道strcpy是字符串拷贝的意思,它两个形参名一个叫source:源头,一个叫destination:目的地.我们可以猜出它可能是把source指向的字符串拷贝到destination指向的字符串 ,但是你不知道也没有关系,它下面会有解释:

首先,这里它给出了这个函数的意图:copy string就是拷贝字符串.下面的第一段文字在说: 将source指向的C字符串复制到destination指向的字符串中,包括结束的null字符(并在该点停止)。 .看到这儿我们就已经很了解这个函数是在做什么事情了,紧接着下一行它还有一个提醒: 为了避免栈溢出,destination指向的数组的大小应该足够长,以包含与source相同的C字符串(包括结束的null字符),并且不应该在内存中与source重叠。 我们再往下看还有对形参和返回值的解释和库函数使用的用例,非常的方便:
根据它给的案例,我们可以自己敲代码感受一下
#include <stdio.h>
#include <string.h>
int main ()
{
char str1[]="Sample string";
char str2[40];
char str3[40];
strcpy (str2,str1);
strcpy (str3,"copy successful");
printf ("str1: %s\nstr2: %s\nstr3: %s\n",str1,str2,str3);
return 0;
}
3.32 memset函数
和我们学习strcpy一样的步骤,先搜索memset函数:

这个函数的功能是填充内存块,它传了三个参数进来.现在我们得到的信息不足以参透这个函数的作用,我们接着往下看:
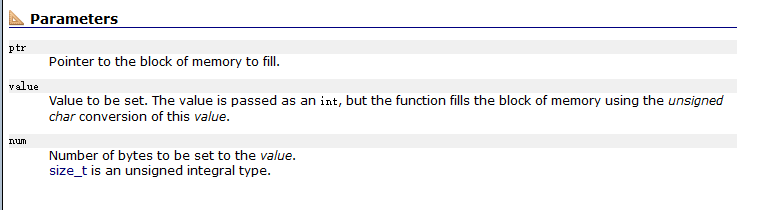
我们再来看看对于参数的解释: ptr是指向要填充的内存块的指针,value指的是我们填充在内存块的值,它是int类型.最后num指的是要设置为该值的字节数。 这里就要注意了,num的单位是字节而不是一个两个, 分析到这儿我们大概了解了这个函数要把ptr指向的空间用value来填充,填充num个字节,再来看看它的返回值

当我们填充完内存后再把这块内存给返回回来
最后我们再去看看它的用例,自己去敲一敲代码运行后感受一下它的实现:
#include <stdio.h>
#include <string.h>
int main ()
{
char str[] = "almost every programmer should know memset!";
memset (str,'-',6);
puts (str);
return 0;
}
3.33 使用库函数应该包含的头文件
最后,如果我们想看看我们的库函数在使用时应该包含哪个头文件时,这时我们看页面的左边一栏:
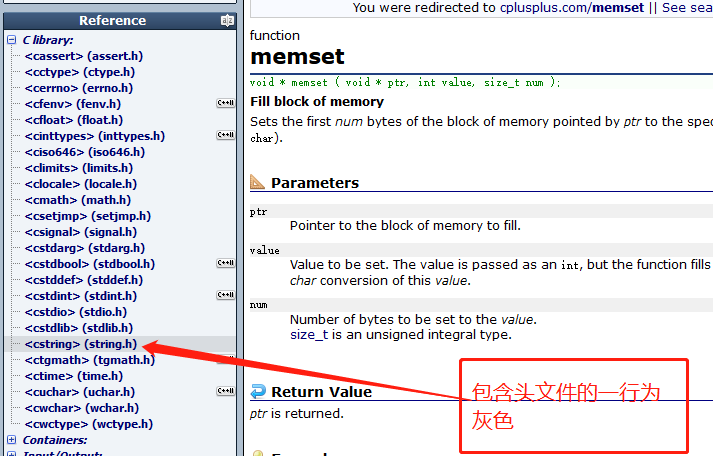
最后,我们不需要把所有库函数都背下来,我们一般在C语言的学习过程中遇见了一个就去查阅一次文档,就熟悉一个,虽然我们不需要记住全部的库函数,但是我们需要掌握学习库函数的方法.
4.自定义函数
如果库函数能干所有的事情,那还要程序员干什么?
所有更加重要的是 自定义函数。
自定义函数和库函数一样,有函数名,返回值类型和函数参数。
但是不一样的是这些都是我们自己来设计。这给程序员一个很大的发挥空间
自定义函数和库函数一样,包含了返回类型,函数名,和参数.
ret_type fun_name(para1)
{
statement;//语句项
}
//ret_type 返回类型
//fun_name 函数名
//para1 函数参数
比如我们写一个函数返回两个变量的最大值:
#include<stdio.h>
int get_max(int x, int y)
{
return (x>y)?(x):(y);
}
int main()
{
int num1 = 10;
int num2 = 20;
int max = get_max(num1, num2);
printf("max = %d\n", max);
我们再写一个函数来交换两个变量的值:
void Swap1(int x, int y)
{
int tmp = 0;
tmp = x;
x = y;
y = tmp;
}
int main()
{
int num1 = 1;
int num2 = 2;
Swap1(num1, num2);
printf("Swap1::num1 = %d num2 = %d\n", num1, num2);
return 0;
}
我们会发现一个问题, 这个代码是可以运行的,但是num1和num2的值是没有被交换的,这个时候我们常常会摸不着头脑,那就让我们开始调试一下 !我们在VS编译器上按F11进入调试,然后按照下面的视频把监视窗口打开,输入num1,num2和x,y,以及它们的地址来查看情况
vs编译器监视窗口
当我们调出监视窗口之后,我们接着按F11往下走,走到定义num1和num2对的位置后,监视窗口中num1和num2的值和地址会显示出来,当我们进入函数后,x和y的值以及它们的地址也会显示出来. 这个地方我们发现,当我们把num1和num2的值传过去之后,x和y的值确实是和num1和num2对应相同的:
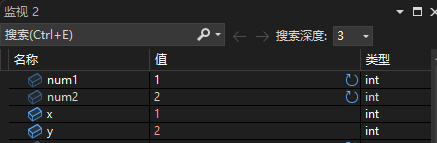
但是我们会发现,x,y以及num1和num2的地址是不一样的!,在我的电脑上它们的地址分别是:
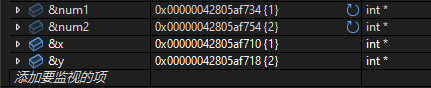
它们前面都是一样的,但是在最后num1和num2是34和54,但是x和y是10和18.所以我们得出一个结论: 当main函数调用我们自定义函数的时候,我们的形参 (这里的x和y) 是实参 (这里的num1和num2) 的一份临时拷贝,它们拥有两个完全不同的地址,当我们改变形参时,实参是不会受到影响的 .所以这个地方就能解释为什么我们写的函数不能交换两个变量的值了.
我们修改我们的代码,传参时我们传地址过去就能很好的解决这个问题了:(后面会分析为什么这样可以)
//正确的版本
void Swap2(int* px, int* py)
{
int tmp = 0;
tmp = *px;
*px = *py;
*py = tmp;
}
int main()
{
int num2 = 2;
int num1 = 1;
Swap2 (&num1, &num2);
printf("Swap2::num1 = %d num2 = %d\n", num1, num2);
return 0;
}
5.函数的参数
- 实参: 真实传给函数的参数,叫实参。
实参可以是:常量、变量、表达式、函数等。
无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。
- 形参:形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内存单元),所以叫形式参数。形式参数当函数调用完成之后就自动销毁了。因此形式参数只在函数中有效。
上面Swap1和Swap2函数中的参数x,y,px,py都是形式参数。
在main函数中传给swap1的num1,num2和传给Swap2函数的&num1,&num2是实际参数
5.1 交换两数题目详解
在上面的题目中:
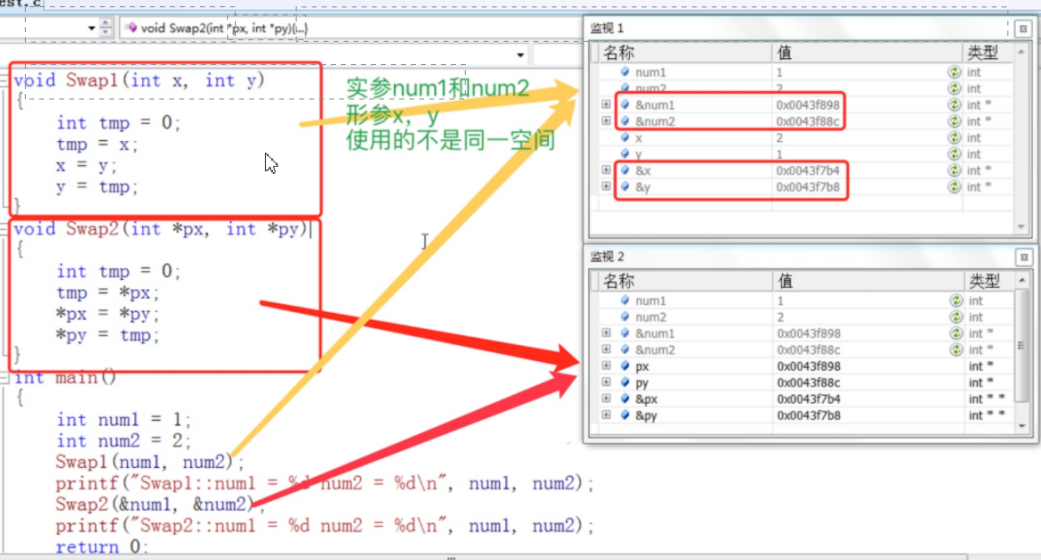
当我们现在传指针进函数后,px和py存的是num1和num2的地址,我们对px和py使用解引用操作就可以修改num1和num2的值了,并且我们可以发现px和py的地址是两个与num1和num2毫无相关的值,也就是说我们这里的px和py也是一份临时拷贝,只不是它们存的是地址,我们可以通过地址来间接改变num1和num2的值.
6. 函数的调用
6.1 传址调用
传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。 这种传参方式可以让函数和函数外边的变量建立起真正的联系,也就是函数内部可以直接操 作函数外部的变量。*
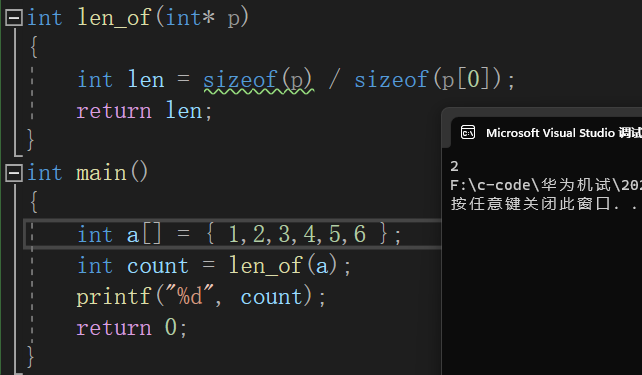
int a[]={1,2,3,4,5,6};
int len=sizeof(a)/sizeof(a[0]);//求数组a的元素个数
但是,当我们这个地方和函数结合起来后,似乎就不能这样写了:
int len_of(int* p)
{
int len=sizeof(p)/sizeof(p[0]);
return len;
}
int main()
{
int a[]={1.,2,3,4,5,6];
int count=len_of(a);
return 0;
}
我们说数组名是首元素地址,这个地方我们传数组a的首元素地址过去后,p只接受了数组首元素的地址,实参本质上不是一个数组而是一个指针,这个地方用sizeof求长度会遇见问题,下面我们可以看见长度不是我们期望的"6", 是因为我的机器是64位的,指针变量的大小位8个字节,我们sizeof ( p ) 就等于8,然后我们的sizeof(p[0])就是整型的长度为4,所以我们得到的值是2. .新手在这个地方比较容易犯错,要注意
6.2 传值调用
传值调用时,函数的形参和实参分别占有不同内存块,对形参的修改不会影响实参。参考我们上面写的函数:交换两个变量的值
7. 函数的嵌套调用和链式访问
函数和函数之间可以根据实际的需求进行组合的,也就是可以互相调用的
7.1 嵌套调用
我们函数的嵌套调用就像生产汽车一样,我生产一些部件,你也生产一些部件,最后生产完后再把我们合并起来组成一辆车,来看看例子:
#include <stdio.h>
void new_line()
{
printf("hehe\n");
}
void three_line()
{
int i = 0;
for(i=0; i<3; i++)
{
new_line();
}
}
int main()
{
three_line();
return 0;
}
这个地方我们main函数调用three_line函数,然后在three_line函数中又调用了new_line函数,这就是函数的嵌套调用,我们这个地方的three_line函数的作用是实现三次循环,new_line函数的作用是打印"hehe",把它们两个合在一起组成新的功能
注意: 函数可以嵌套调用,但是不能嵌套定义 .
7.2 链式访问
链式访问就是把一个函数的返回值作为另外一个函数的参数。
我举一个比较简单的例子来说明一下:求字符串abc的长度
#include<stdio.h>
#include<string.h>
int main()
{
int len = 0;
len = strlen("abc");
printf("%d", len);
return 0;
}
如果我们用链式访问的方式来实现这个功能:
#include<stdio.h>
#include<string.h>
int main()
{
printf("%d", strlen("abc"));
return 0;
}
第二个代码就是将strlen函数的返回值作为printf函数的参数来使用. 再举个例子:
#include<stdio.h>
int main()
{
printf("%d", printf("%d", printf("%d", 43)));//会打印什么出来?
}
这个地方逻辑应该是比较清楚的,我们的第一层printf函数打印第二层printf函数的返回值,然后第二层printf函数打印第三层printf函数的返回值,第三层printf函数打印43. 我们可能从来没有遇见过printf函数的返回值是什么,这个时候我们去cplusplus上学习一下这个函数的返回值:

这里说:如果成功,则返回写入的字符总数。那我们就知道了第三层printf函数的返回值应该是2,因为43是两个字符,以此类推我们这个代码将打印:4321出来.
8. 函数的声明和定义
8.1 函数的定义
我们之前说,main函数可以放在我们程序的任一位置,假如我们现在这样写代码来实现两个数相加:
#include<stdio.h>
int main()
{
int a = 10;
int b = 20;
int sum = Add(a, b);
printf("%d",sum);
return 0;
}
int Add(int x, int y)//函数的定义
{
return x + y;
}
当我们一编译,程序会报错":Add未定义"

这是因为代码在扫描的时候是从前往后扫描,当我们代码扫描到调用函数这一行时,发现我们前面从来没有遇见过Add函数.这个地方我们虽然定义了函数,但是别人不知道,所以我们要在前面加一个声明
8.2 函数的声明
- 告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,函数
声明决定不了。 - 函数的声明一般出现在函数的使用之前。要满足先声明后使用。
- 函数的声明一般要放在头文件中的。
修改代码后:
#include<stdio.h>
int Add(int x, int y);//在最前面加上声明
int main()
{
int a = 10;
int b = 20;
int sum = Add(a, b);
printf("%d", sum);
return 0;
}
int Add(int x, int y)
{
return x + y;
}
这样的写法是比较啰嗦的,所以我们一般都把自定义函数放在main函数的上面,这样就不用去声明函数了.
其实函数的声明的真正的用法是我们在test.c文件中调用其他文件中的函数时,我们需要声明一下函数,这个我们后面将C语言实现三子棋和扫雷时会详细讲解.
9. 函数递归
9.1 什么是递归
程序调用自身的编程技巧称为递归( recursion)。
递归做为一种算法在程序设计语言中广泛应用。 一个过程或函数在其定义或说明中有直接或间接
调用自身的一种方法, 它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的
题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程
序的代码量。
9.2 使用递归的两个必要条件
- 存在限制条件,当满足这个限制条件的时候,递归便不再继续。
- 每次递归调用之后越来越接近这个限制条件。
9.3 递归练习(画图讲解)
9.31 打印1 2 3 4
我们先来看一段代码:
#include <stdio.h>//打印1 2 3 4
void my_print(int n)
{
if(n>9)
{
my_print(n/10);
}
printf("%d ", n%10);
}
int main()
{
int num = 1234;
print(num);
return 0;
}
这个代码是将我们的1234打印为1 2 3 4;我们来看看它满不满足我们递归的两个条件:

现在我们用画图的方式来解析一下这个递归:
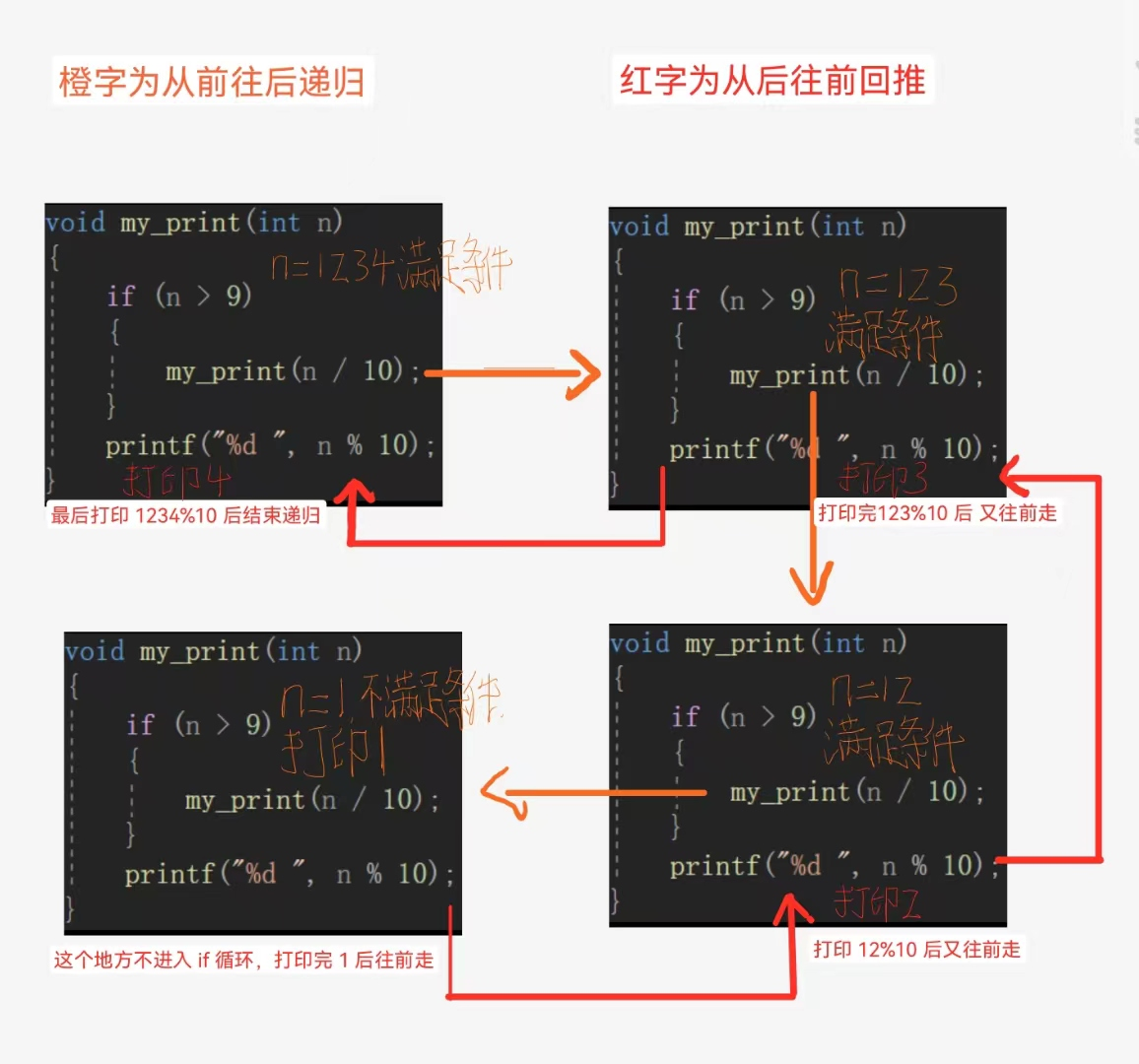
当我们第一次进入函数时,我们的n>9是成立的,所以我们又进入到了第二层函数中,注意,这个时候我们的第一层函数还在if语句里面.当我们第二次进入函数,n>9也是成立的,又进入if循环中进入第三层递归,这个时候,我们的第一层函数和第二层函数都处于if语句里面.以此类推到n>9不成立的函数时,我们这时不进入if循环中,而是直接打印出1.当我们最里面这层递归不满足条件后,我们又逐层往前回退,不断打印新的内容.
9.32 求字符串长度
我们用递归的方法来求字符串长度:
#include <stdio.h>
int my_Strlen(const char*str)
{
if(*str == '\0')//递归结束条件
{
return 0;
}
else
{
return 1+my_Strlen(str+1);//str+1,不断往后读取字符串,不断靠近递归结束条件
}
}
int main()
{
char *p = "abcd";
int len = my_Strlen(p);
printf("%d\n", len);
return 0;
}
我们再用画图的方法来剖析一下这个递归是怎么进行的:
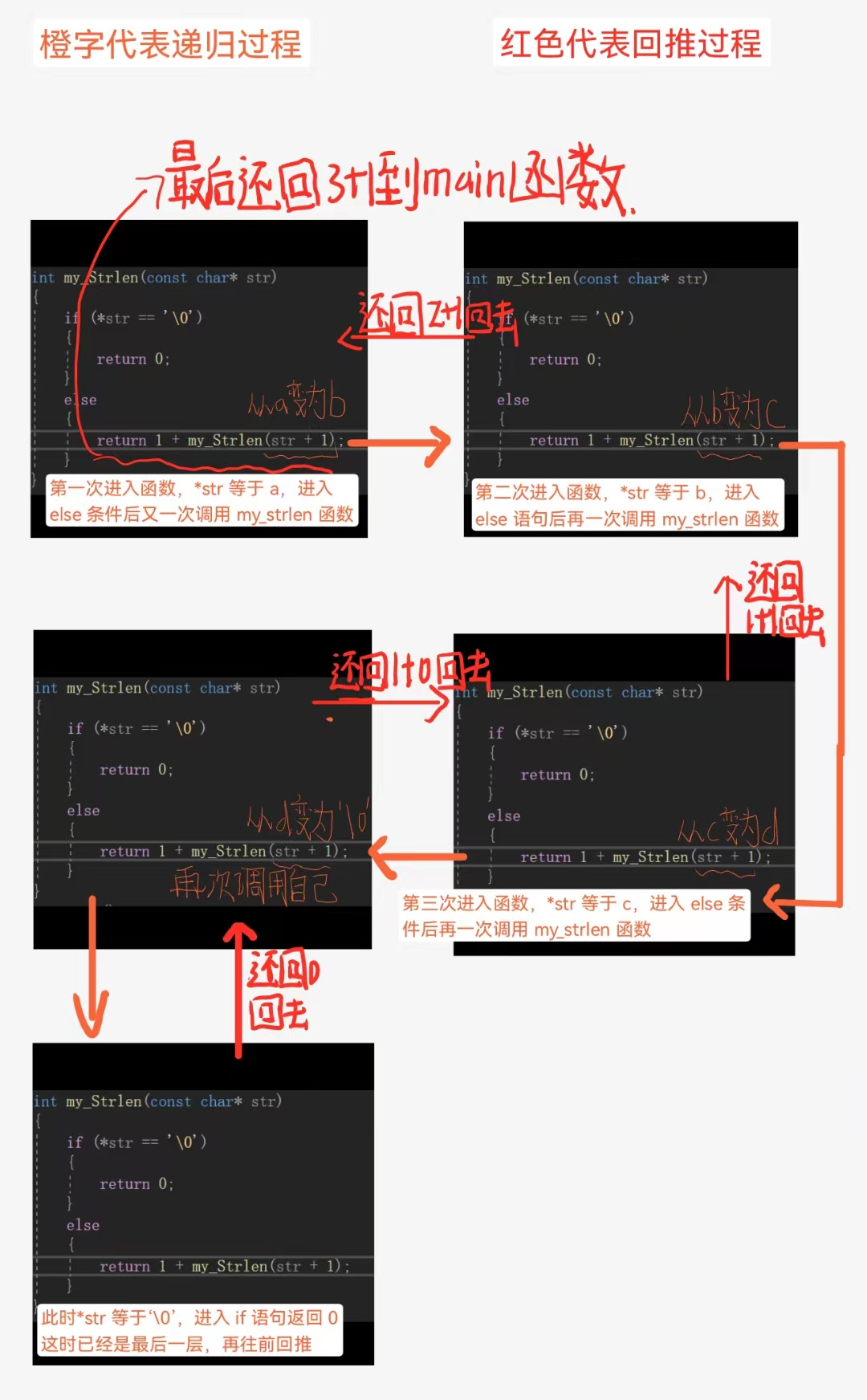
这两个递归都有一个特性,那就递归到最后一次的时候,我们要往回推一遍才能得到最终的值
9.4 递归常见错误
我们来看看下面的代码:
int fib(int n)//用递归求斐波那契数列
{
if (n <= 2)//递归结束条件
return 1;
else
return fib(n - 1) + fib(n - 2);//n不断减少,越来越接近结束递归的条件
}
还有一个代码:
int factorial(int n)//求n的阶乘
{
if(n <= 1)
return 1;
else
return n * factorial(n-1);
}
代码很简单,我们的推导形式和之前的步骤是大同小异的,所以这两个题的递归推导就交给你们自己动手实现了
但是我们发现有问题;
- 使用 fib 这个函数的时候如果我们要计算第50个斐波那契数字的时候特别耗费时间。
- 使用 递归求10000的阶乘(不考虑结果的正确性),程序会崩溃。
_
这个地方就不得不提我们递归的常见错误:栈溢出(stack overflow)
栈溢出:
- 在调试 factorial 函数的时候,如果你的参数比较大,那就会报错: stack overflow(栈溢出)
这样的信息。- 系统分配给程序的栈空间是有限的,但是如果出现了死循环,或者(死递归),这样有可能导致一直开辟栈空间,最终产生栈空间耗尽的情况,这样的现象我们称为栈溢出。
我们可以看见报错信息为:stack overflow
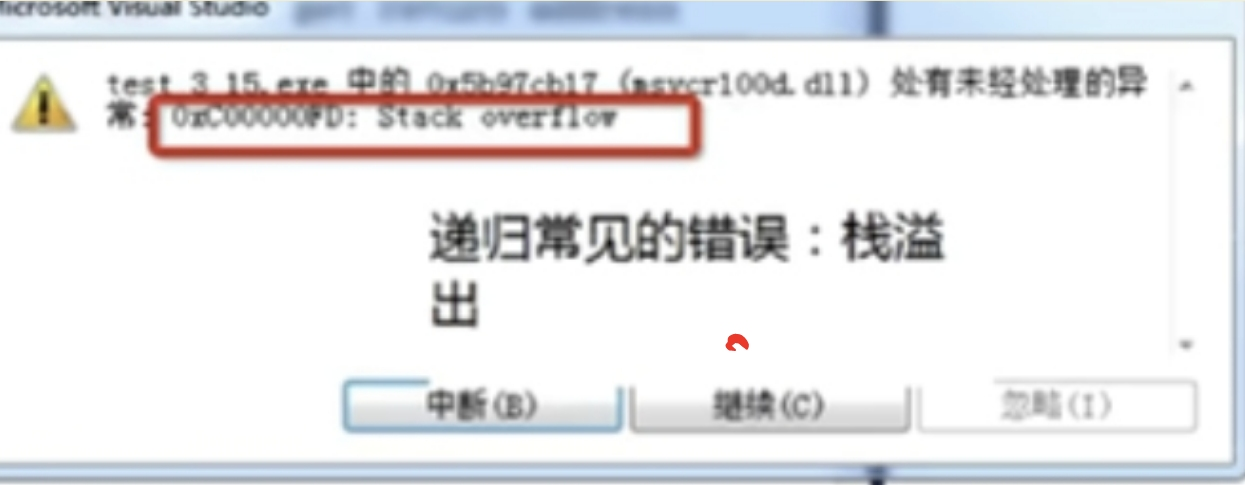
那么我们遇见这种递归报错了应该怎么解决这种问题呢?
下面我给出一点方法仅供参考:
- 将递归改写成非递归。
- 使用 static 对象替代 nonstatic 局部对象。在递归函数设计中,可以使用 static 对象替
nonstatic 局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放
nonstatic 对象的开销,而且 static 对象还可以保存递归调用的中间状态,并且可为各个调用
所访问.
我们可以优化求阶乘和求斐波那契数列的代码:
//求n的阶乘
int factorial(int n)
{
int result = 1;
while (n > 1)
{
result *= n ;
n -= 1;
}
return result;
}
//求第n个斐波那契数
int fib(int n)
{
int result;
int pre_result;
int next_older_result;
result = pre_result = 1;
while (n > 2)
{
n -= 1
next_older_result = pre_result;
pre_result = result;
result = pre_result + next_older_result;
}
return result;
}
10. 总结
有关函数的详细知识已经讲解完了,这里还是需要注意几点:
- 库函数不用特意去背,只需要你知道怎么样学习库函数就可以了
- 写自定义函数时,根据你想要实现的功能来选择传值调用还是传址调用
- 许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更为清晰。
但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些。
- 当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿它所带来的运行时开销。
最后有什么不对或者需要补充的地方,请在评论区讨论!