目录
1.函数作用
2.步骤
3.code
4.函数解析
4.1 找出和当前帧具有公共单词(word)的所有关键帧
4.2 统计上述关键帧中与当前帧F具有共同单词最多的单词数maxCommonWords,用来设定阈值1
4.3 遍历上述关键帧,挑选出共有单词数大于阈值1的及其和当前帧单词匹配得分存入lScoreAndMatch
4.4 计算lScoreAndMatch中每个关键帧的共视关键帧组的总得分,得到最高组得分bestAccScore,并以此决定阈值2
4.5 得到所有组中总得分大于阈值2的,组内得分最高的关键帧,作为候选关键帧组
1.函数作用
用词袋找到与当前帧相似的候选关键帧。
2.步骤
* @brief 在重定位中找到与该帧相似的候选关键帧组
* Step 1. 找出和当前帧具有公共单词的所有关键帧
* Step 2. 只和具有共同单词较多的关键帧进行相似度计算
* Step 3. 将与关键帧相连(权值最高)的前十个关键帧归为一组,计算累计得分
* Step 4. 只返回累计得分较高的组中分数最高的关键帧
* @param F 需要重定位的帧
* @return 相似的候选关键帧数组
3.code
vector<KeyFrame*> KeyFrameDatabase::DetectRelocalizationCandidates(Frame *F) { list<KeyFrame*> lKFsSharingWords; // Search all keyframes that share a word with current frame // Step 1:找出和当前帧具有公共单词(word)的所有关键帧 { unique_lock<mutex> lock(mMutex); // mBowVec 内部实际存储的是std::map<WordId, WordValue> // WordId 和 WordValue 表示Word在叶子中的id 和权重 for(DBoW2::BowVector::const_iterator vit=F->mBowVec.begin(), vend=F->mBowVec.end(); vit != vend; vit++) { // 根据倒排索引,提取所有包含该wordid的所有KeyFrame list<KeyFrame*> &lKFs = mvInvertedFile[vit->first]; for(list<KeyFrame*>::iterator lit=lKFs.begin(), lend= lKFs.end(); lit!=lend; lit++) { KeyFrame* pKFi=*lit; // pKFi->mnRelocQuery起标记作用,是为了防止重复选取 if(pKFi->mnRelocQuery!=F->mnId) { // pKFi还没有标记为F的重定位候选帧 pKFi->mnRelocWords=0; pKFi->mnRelocQuery=F->mnId; lKFsSharingWords.push_back(pKFi); } pKFi->mnRelocWords++; } } } // 如果和当前帧具有公共单词的关键帧数目为0,无法进行重定位,返回空 if(lKFsSharingWords.empty()) return vector<KeyFrame*>(); // Only compare against those keyframes that share enough words // Step 2:统计上述关键帧中与当前帧F具有共同单词最多的单词数maxCommonWords,用来设定阈值1 int maxCommonWords=0; for(list<KeyFrame*>::iterator lit=lKFsSharingWords.begin(), lend= lKFsSharingWords.end(); lit!=lend; lit++) { if((*lit)->mnRelocWords>maxCommonWords) maxCommonWords=(*lit)->mnRelocWords; } // 阈值1:最小公共单词数为最大公共单词数目的0.8倍 int minCommonWords = maxCommonWords*0.8f; list<pair<float,KeyFrame*> > lScoreAndMatch; int nscores=0; // Compute similarity score. // Step 3:遍历上述关键帧,挑选出共有单词数大于阈值1的及其和当前帧单词匹配得分存入lScoreAndMatch for(list<KeyFrame*>::iterator lit=lKFsSharingWords.begin(), lend= lKFsSharingWords.end(); lit!=lend; lit++) { KeyFrame* pKFi = *lit; // 当前帧F只和具有共同单词较多(大于minCommonWords)的关键帧进行比较 if(pKFi->mnRelocWords>minCommonWords) { nscores++; // 这个变量后面没有用到 // 用mBowVec来计算两者的相似度得分 float si = mpVoc->score(F->mBowVec,pKFi->mBowVec); pKFi->mRelocScore=si; lScoreAndMatch.push_back(make_pair(si,pKFi)); } } if(lScoreAndMatch.empty()) return vector<KeyFrame*>(); list<pair<float,KeyFrame*> > lAccScoreAndMatch; float bestAccScore = 0; // Lets now accumulate score by covisibility // Step 4:计算lScoreAndMatch中每个关键帧的共视关键帧组的总得分,得到最高组得分bestAccScore,并以此决定阈值2 // 单单计算当前帧和某一关键帧的相似性是不够的,这里将与关键帧共视程度最高的前十个关键帧归为一组,计算累计得分 for(list<pair<float,KeyFrame*> >::iterator it=lScoreAndMatch.begin(), itend=lScoreAndMatch.end(); it!=itend; it++) { KeyFrame* pKFi = it->second; // 取出与关键帧pKFi共视程度最高的前10个关键帧 vector<KeyFrame*> vpNeighs = pKFi->GetBestCovisibilityKeyFrames(10); // 该组最高分数 float bestScore = it->first; // 该组累计得分 float accScore = bestScore; // 该组最高分数对应的关键帧 KeyFrame* pBestKF = pKFi; // 遍历共视关键帧,累计得分 for(vector<KeyFrame*>::iterator vit=vpNeighs.begin(), vend=vpNeighs.end(); vit!=vend; vit++) { KeyFrame* pKF2 = *vit; if(pKF2->mnRelocQuery!=F->mnId) continue; // 只有pKF2也在重定位候选帧中,才能贡献分数 accScore+=pKF2->mRelocScore; // 统计得到组里分数最高的KeyFrame if(pKF2->mRelocScore>bestScore) { pBestKF=pKF2; bestScore = pKF2->mRelocScore; } } lAccScoreAndMatch.push_back(make_pair(accScore,pBestKF)); // 记录所有组中最高的得分 if(accScore>bestAccScore) bestAccScore=accScore; } // Return all those keyframes with a score higher than 0.75*bestScore // Step 5:得到所有组中总得分大于阈值2的,组内得分最高的关键帧,作为候选关键帧组 //阈值2:最高得分的0.75倍 float minScoreToRetain = 0.75f*bestAccScore; set<KeyFrame*> spAlreadyAddedKF; vector<KeyFrame*> vpRelocCandidates; vpRelocCandidates.reserve(lAccScoreAndMatch.size()); for(list<pair<float,KeyFrame*> >::iterator it=lAccScoreAndMatch.begin(), itend=lAccScoreAndMatch.end(); it!=itend; it++) { const float &si = it->first; // 只返回累计得分大于阈值2的组中分数最高的关键帧 if(si>minScoreToRetain) { KeyFrame* pKFi = it->second; // 判断该pKFi是否已经添加在队列中了 if(!spAlreadyAddedKF.count(pKFi)) { vpRelocCandidates.push_back(pKFi); spAlreadyAddedKF.insert(pKFi); } } } return vpRelocCandidates; }
4.函数解析
4.1 找出和当前帧具有公共单词(word)的所有关键帧
因为我们要进行重定位,因此要找到先前的一帧和当前帧特征点匹配较多的。
因此我们要找到和当前帧有相同特征点(描述子)的帧。
mBowVec里面的第一维是该帧的特征点在ORB词典中的索引,我们根据倒排索引,得到和该帧的某一特征点共视的所有帧。
mnRelocQuery标记是标记某一帧是哪个帧的重定位参考帧,遍历倒排索引,取出每一个与当前关键帧有共视的关键帧。
如果这个帧还没有标记为当前帧的重定位关键帧(这个帧的mnRelocQuery不是当前待重定位关键帧 ),则置位mnRelocQuery为当前待重定位的关键帧,将mnRelocWords(和当前帧的共视程度)置为0。
如果这个帧标记为当前帧的重定位关键帧了,则将共视程度mnRelocWords++。
执行完这一步后我们得到了与当前待重定位帧的所有共视关键帧并且得到共视程度。
这些帧被存放在lKFsSharingWords中。
4.2 统计上述关键帧中与当前帧F具有共同单词最多的单词数maxCommonWords,用来设定阈值1
我们遍历lKFsSharingWords容器,统计和当前帧的最大共视次数存放在maxCommonWords,我们设置最小阈值minCommonWords(不超过这个阈值则抛弃关键帧)为0.8倍的maxCommonWords。
4.3 遍历上述关键帧,挑选出共有单词数大于阈值1的及其和当前帧单词匹配得分存入lScoreAndMatch
遍历lKFsSharingWords容器,挑选出共有单词数大于阈值1的及其和当前帧单词匹配得分存入lScoreAndMatch。我们遍历这个容器,对于每个关键帧,我们将这个帧和当前帧的共视程度和minCommonWords比对,若满足阈值,则记录共视地图点的相似得分记录在si中,将满足阈值的帧pkFi和得分si做成对组存储在lScoreAndMatch中。
4.4 计算lScoreAndMatch中每个关键帧的共视关键帧组的总得分,得到最高组得分bestAccScore,并以此决定阈值2
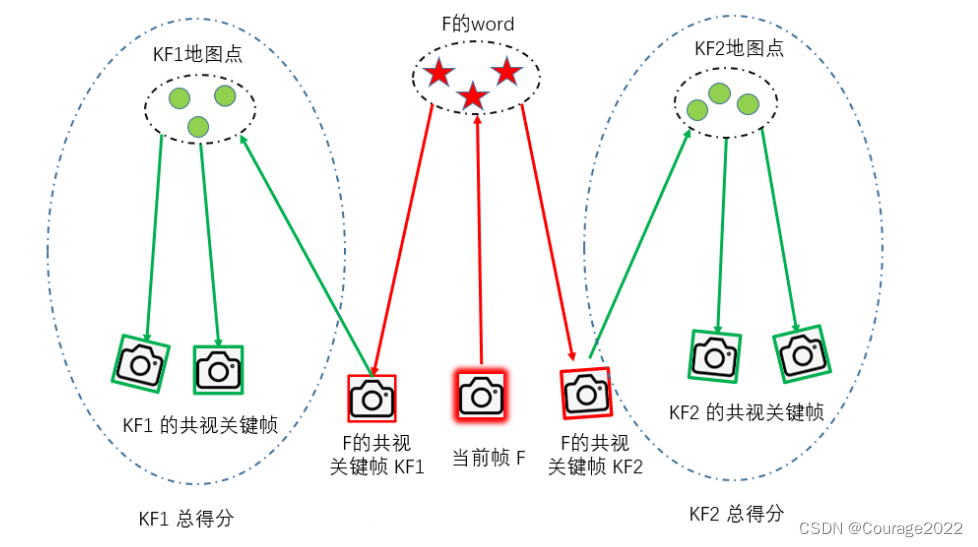
我们遍历lScoreAndMatch对组,单单计算当前帧和某一关键帧的相似性是不够的,这里将与关键帧共视程度最高的前十个关键帧归为一组,计算累计得分。
我们将lScoreAndMatch中的每个帧视为一组关键帧,我们取出lScoreAndMatch中的每个帧共视程度最高的前10个关键帧存入vpNeighs中,将该组的最高分数初始化为当前帧的scorebestScore,该组最高分数对应的关键帧设置为pBestKF,我们遍历所有共视关键帧(10帧中的每一帧)如果这帧是被标记了当前追踪候选帧,我们累加accScore的值,并统计这组中的分数最高的关键帧,更新变量pBestKF、bestScore。
在完成一次遍历后,我们添加这组中数最高的KeyFramepBestKF及这组的累计得分accScore放入lAccScoreAndMatch对组中。并记录所有组中最高得分bestAccScore。
4.5 得到所有组中总得分大于阈值2的,组内得分最高的关键帧,作为候选关键帧组
我们定义最后的阈值为上步中的累计得分最高的0.75倍(0.75f*bestAccScore)
我们创建帧的集合spAlreadyAddedKF,帧的容器vpRelocCandidates。
遍历lAccScoreAndMatch容器,取出得分与阈值判断,若大于阈值,且该关键帧没有添加到队列spAlreadyAddedKF中,则将该帧作为最终候选匹配关键帧并将其放入容器vpRelocCandidates中,返回给上层函数。





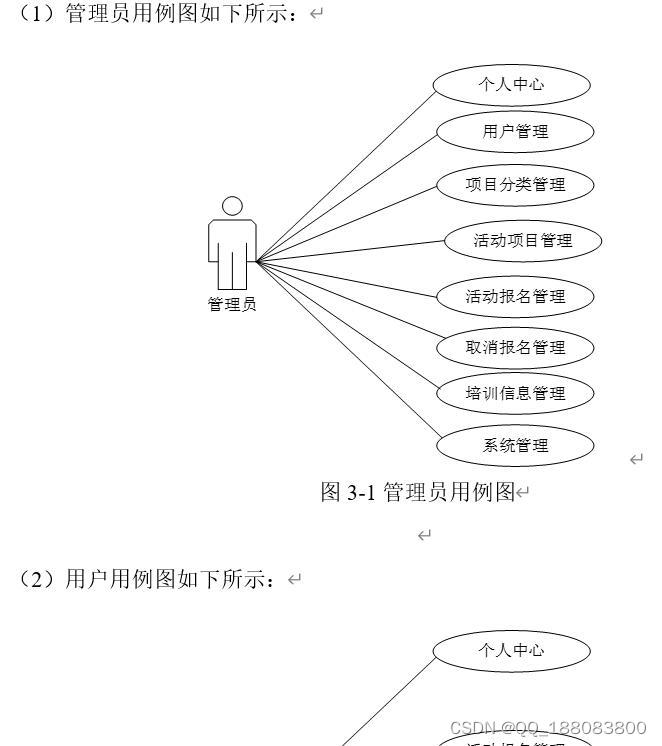
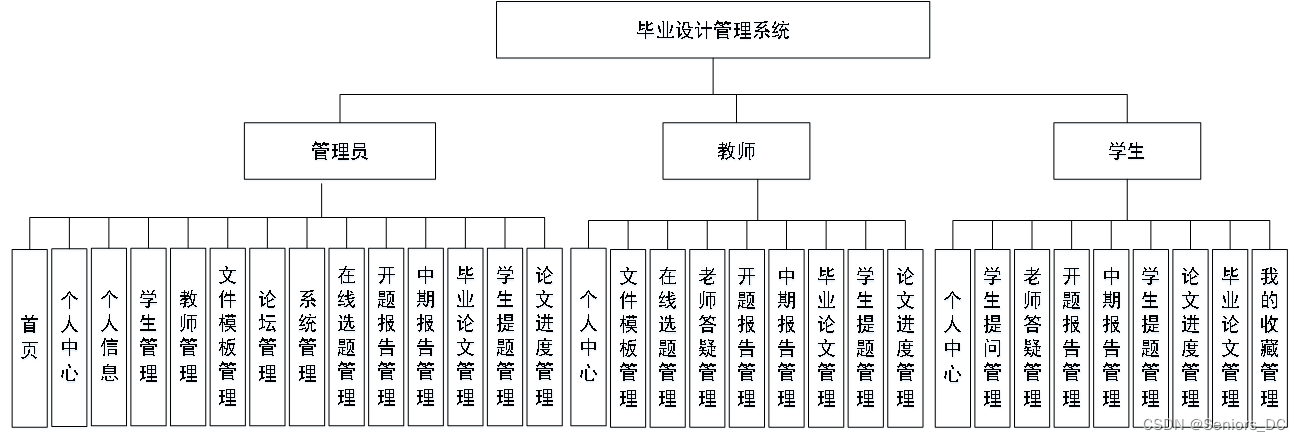


![[附源码]Python计算机毕业设计Django大学生创新项目管理系统](https://img-blog.csdnimg.cn/7e4d74cc0c1a44c88eaf46e1f9c1dbd7.png)