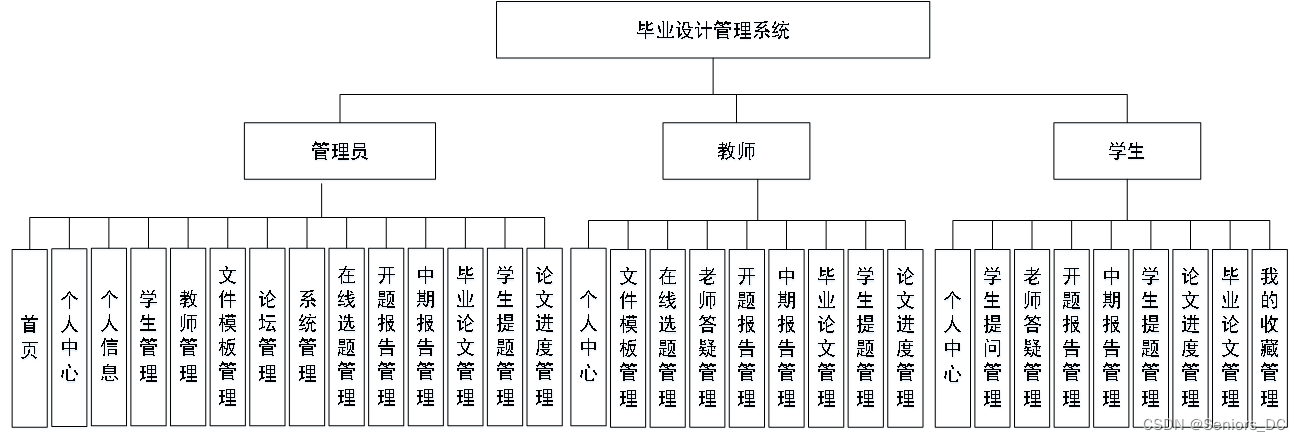
文章目录
- 1.前言
- 2.核心技术
- 2.1 文本分类方案全覆盖
- 2.1.1 分类场景齐全
- 2.1.2 多方案满足定制需求
- 方案一:预训练模型微调
- 方案二:提示学习
- 方案三:语义索引
- 2.2 更懂中文的训练基座
- 2.3 高效模型调优方案
- 2.4 产业级全流程方案
- 3. 快速开始
- 4. 常用中文分类数据集
- 5.参考文献
1.前言
PaddleNLP 完全基 PaddlePaddle (www.paddlepaddle.org)开发。PaddlePaddle 是中国首个、也是目前国内唯一开源开放,集核心框架、工具组件和服务平台为一体的端到端开源深度学习平台,其囊括支持面向真实场景应用、达到工业级应用效果的模型,并具备针对大规模数据场景的分布式训练能力、支持多种异构硬件的高速推理引擎。
PaddleNLP 提供依托于百度百亿级大数据的预训练模型,能够极大地方便 NLP 研究者和工程师快速应用。使用者可以用 PaddleNLP 快速实现文本分类、文本匹配、序列标注、阅读理解、智能对话等 NLP 任务的组网、建模和部署,而且可以直接使用百度开源工业级预训练模型进行快速应用。用户在极大地减少研究和开发成本的同时,也可以获得更好的基于工业实践的应用效果。
文本分类是自然语言处理中最常见的任务,也是应用场景比较广泛的任务。文本分类任务定义:简单的来说,给定一段文本,可以是句子,可以是文章,甚至是一个文件内容,机器使用分类模型进行分类,给出最终的分类标签结果。
文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。
文本分类任务按照高频场景可以大致分为三大类:多分类、多标签、层次分类。全套流程包括:打通数据标注-模型训练-模型调优-模型压缩-预测部署全流程,旨在解决细分场景应用的痛点和难点,包括常见的预训练模型、数据标注质量差、效果调优困难、AI入门成本高、如何高效训练部署等问题,快速实现文本分类产品落地

本次技术方案优势:
- 方案全面: 涵盖了三个高频分类场景:多分类、多标签、层次分类,提供预训练模型微调、小样本学习、语义匹配三种端到端全流程分类方案,满足开发者多样文本分类落地需求。
- 效果领先: 使用在中文领域内模型效果和模型计算效率有突出效果的ERNIE 3.0系列模型作为训练基座,ERNIE 3.0 轻量级系列提供多种尺寸的预训练模型满足不同需求,具有广泛成熟的实践应用性。
- 高效调优: 文本分类应用依托可解释性和数据增强,提供模型分析模块助力开发者实现模型分析,并提供稀疏数据筛选、脏数据清洗、数据增强等多种解决方案。
- 简单易用: 开发者无需机器学习背景知识,仅需提供指定格式的标注分类数据,一行命令即可开启文本分类训练,轻松完成上线部署,不再让技术成为文本分类的门槛。
2.核心技术
2.1 文本分类方案全覆盖

2.1.1 分类场景齐全
文本分类应用涵盖多分类(multi class)、多标签(multi label)、层次分类(hierarchical)三种场景,接下来以网易新闻的数据为例介绍三种分类场景的区别。

- 多分类
任务的标签类别在两个或者两个以上,所有训练数据有且只有一个标签,并且标签集合中的标签都是相互独立。在推理过程中,我们需要预测输入的短文本/长文本/中英文本/文章最可能来自n个标签类别中的一个类别。以上图多分类中新闻文本为例,该新闻文本的标签为 游戏。
- 多标签
任务的标签类别在两个或者两个以上,所有训练数据具有一个或者多个标签,并且标签集合中的标签都是相互独立。在推理过程中,我们需要预测输入的短文本/长文本/中英文本/文章最可能来自n个标签类别中的一个或者类别。以上图多标签中新闻文本为例,该新闻文本的标签为 汽车 和 新能源 。
- 层次分类
任务的标签类别具有多级标签且标签之间具有层级结构关系,所有训练数据具有一个或者多个标签。在推理过程中,我们需要预测输入的短文本/长文本/中英文本/文章最可能来自层级标签类别中的一个类别。以上图层次分类中新闻文本为例,该新闻一级分类标签为 体育,二级分类标签为 足球。
2.1.2 多方案满足定制需求
方案一:预训练模型微调
【方案选择】对于60-70%分类任务,推荐使用预训练模型微调作为首选的文本分类方案,预训练模型微调提供了数据标注-模型训练-模型分析-模型压缩-预测部署全流程,有效减少开发时间,低成本迁移至实际应用场景。
【方案介绍】ERNIE 3.0 语言模型一般是不能直接在文本分类任务上使用,预训练模型微调在预训练模型 [CLS] 输出向量后接入线性层作为文本分类器,用具体任务数据进行微调训练文本分类器,使预训练模型”更懂”这个任务。
【方案效果】下表展示在多标签任务CAIL2019—婚姻家庭要素提取数据集中ERNIE 3.0 系列模型效果评测。

方案二:提示学习
【方案选择】**提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。**在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。对于标注样本充足、标注成本较低的场景,我们仍旧推荐使用充足的标注样本进行文本分类预训练模型微调。
【方案介绍】提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。提示学习同时提供R-Drop 和 RGL 策略,帮助提升模型效果。
我们以下图情感二分类任务为例来具体介绍提示学习流程,分类任务标签分为 0:负向 和 1:正向 。在文本加入构造提示 我[MASK]喜欢。 将情感分类任务转化为预测掩码 [MASK] 的待预测字是 不 还是 很。具体实现方法是在掩码[MASK]的输出向量后接入线性分类器(二分类),然后用不和很的预训练向量来初始化分类器进行训练,分类器预测分类为 0:不 或 1:很 对应原始标签 0:负向 或 1:正向。而预训练模型微调则是在预训练模型[CLS]向量接入随机初始化线性分类器进行训练,分类器直接预测分类为 0:负向 或 1:正向。

【方案效果】我们比较预训练模型微调与提示学习在多分类、多标签、层次分类小样本场景的模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值),可以看到在样本较少的情况下,提示学习比预训练模型微调有明显优势。

方案三:语义索引
【方案选择】基于语义索引的文本分类方案适用于标签类别不固定的场景,对于新增标签类别或新的相关分类任务无需重新训练,模型仍然能获得较好预测效果,方案具有良好的拓展性。
【方案介绍】语义索引目标是从海量候选召回集中快速、准确地召回一批与输入文本语义相关的文本。基于语义索引的文本分类方法具体来说是将标签集作为召回目标集,召回与输入文本语义相似的标签作为文本的标签类别。

2.2 更懂中文的训练基座
随着“大模型”的盛行,研究者们都希望通过大规模的语料进行无监督学习或者弱监督学习来训练模型,模型能够学习到语言或者领域相关的知识。预训练模型可以避免从零开始训练模型、节省成本。
预训练语言模型与文本分类的结合可以大致理解为,预训练语言模型已经学习到了特定领域的句法、语义的语言特性,用具体的数据集使得语言模型更加懂得具体的任务。预训练语言模型在具体数据集学习到的特征可以使文本分类任务事半功倍。
文本分类使用ERINE3.0轻量级模型做为预训练模型。ERINE3.0轻量版本是在ERINE3.0大模型的基础上通过模型蒸馏得到的轻量化版本。下面是ERNIE 3.0 效果-时延图,ERNIE 3.0 轻量级模型在精度和性能上的综合表现已全面领先于 UER-py、Huawei-Noah 以及 HFL 的中文模型,具体的测评细节可以见ERNIE 3.0 效果和性能测评文档。
横坐标表示在 IFLYTEK 数据集 (最大序列长度设置为 128) 上测试的延迟(latency,单位:ms),纵坐标是 CLUE 10 个任务上的平均精度(包含文本分类、文本匹配、自然语言推理、代词消歧、阅读理解等任务),其中 CMRC2018 阅读理解任务的评价指标是 Exact Match(EM),其他任务的评价指标均是 Accuracy。图中越靠左上的模型,精度和性能水平越高。

2.3 高效模型调优方案
文本分类应用依托TrustAI可信增强能力和数据增强API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化方案,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。
数据决定了场景效果的上限,而模型和算法只是接近这个上限。数据在机器学习场景是显得尤为重要的。文本分类依托TrustAI可信增强能力和数据增强API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本量少等问题,提供稀疏数据筛选、脏数据清洗和数据增强三个数据层面的优化方案。
稀疏数据筛选基于特征相似度的实例级证据分析方法挖掘待预测数据中缺乏证据支持的数据(也即稀疏数据),并进行有选择的训练集数据增强或针对性筛选未标注数据进行标注来解决稀疏数据问题,有效提升模型表现。

采用在多分类、多标签、层次分类场景中评测_稀疏数据-数据增强策略和稀疏数据-数据标注策略_,下图表明稀疏数据筛选方案在各场景能够有效提高模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值)。

脏数据清洗基于表示点方法的实例级证据分析方法,计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(标注错误样本)。脏数据清洗方案通过高效识别训练集中脏数据(也即标注质量差的数据),有效降低人力检查成本。

我们采用在多分类、多标签、层次分类场景中评测脏数据清洗方案,实验表明方案能够高效筛选出训练集中脏数据,提高模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值)。

数据增强在数据量较少的情况下能够增加数据集的多样性,提升模型的效果。PaddleNLP内置数据增强API,通过词替换、词删除、词插入、词置换、基于上下文生成词(MLM预测)、TF-IDF等多种策略。以CAIL2019—婚姻家庭要素提取数据子集(500条)为例,我们在数据集应用多种数据增强策略,策略效果如下表。

2.4 产业级全流程方案
文本分类应用提供了简单易用的数据标注-模型训练-模型调优-模型压缩-预测部署全流程方案。我们将以预训练模型微调方案为例介绍文本分类应用的全流程:

1.数据准备阶段
我们根据文本分类任务选择对应的场景目录: 多分类场景目录、 多标签场景目录、层次分类场景目录。
如果没有标注的数据集,推荐用doccano工具进行标注。如果已经有标注的训练数据,我们就是需要根据不同的任务将数据集整理为模型的输入格式。
2.训练阶段
数据准备好之后,就可以进行模型的微调阶段。可以根据具体情况设置模型的参数,可以设置选择GPU或CPU进行模型训练,脚本默认保存开发集的最佳效果。
训练完成之后,分析模型调优模块可以对模型进行分析和调优,同时模型分析模块提供了TrustAI可信增强能力和数据增强提供稀疏数据筛选、脏数据清洗和数据增强三种数据层面的优化方案来进行模型调优。模型层面也可以根据情况调整模型内部参数,例如learning_rate、batch_size和max_length等等。
模型训练、调优好之后,就可以通过预测脚本加载最佳模型,利用测试集,打印模型预测结果。
3.模型部署
显示部署的时候,需要同时考虑到模型的性能和精度。文本分类应用接入PaddleNLP模型压缩API。采用DynaBert宽度自适应剪裁策略,对预训练模型中的多头注意力机制中的多头进行排序,保证重要的头不被剪裁,然后用原模型作为教师模型,宽度较小的作为学生模型,蒸馏得到的学生模型就是我们需要的剪裁之后的模型。实验证明,蒸馏能够减少模型的体积、减少内存占用、提高推理速度。

模型部署需要将最佳模型的参数(动态图参数)转成静态图参数,用于后续的模型推理。
文本分类应用提供了离线部署方案,并且支持在GPU设备上使用FP16,在CPU设备使用动态量化的低精度加速推理。同时提供了Paddle Serving 在线服务部署,详见各分类场景文档中模型部署介绍。
3. 快速开始
- 快速开启多分类 👉 多分类指南
- 快速开启多标签分类 👉 多标签指南
- 快速开启层次分类 👉 层次分类指南
4. 常用中文分类数据集
多分类数据集:
- THUCNews新闻分类数据集
- 百科问答分类数据集
- 头条新闻标题数据集TNEWS
- 复旦新闻文本数据集
- IFLYTEK app应用描述分类数据集
- CAIL 2022事件检测
情感分类数据集(多分类):
- 亚马逊商品评论情感数据集
- 财经新闻情感分类数据集
- ChnSentiCorp 酒店评论情感分类数据集
- 外卖评论情感分类数据集
- weibo情感二分类数据集
- weibo情感四分类数据集
- 商品评论情感分类数据集
- 电影评论情感分类数据集
- 大众点评分类数据集
多标签数据集:
- 学生评语分类数据集
- CAIL2019婚姻要素识别
- CAIL2018 刑期预测、法条预测、罪名预测
层次分类数据集:
- 头条新闻标题分类-TNEWS的升级版
- 网页层次分类数据集
- 医学意图数据集(CMID)
- 2020语言与智能技术竞赛事件分类
5.参考文献
- PaddleNLP/applications/text_classification at develop · PaddlePaddle/PaddleNLP
- 10分钟完成高精度中文情感分析 — PaddleNLP 文档
- PaddleNLP基于ERNIR3.0文本分类以CAIL2018-SMALL数据集罪名预测任务为例【多标签】 - 腾讯云开发者社区-腾讯云





![[附源码]Python计算机毕业设计Django大学生创新项目管理系统](https://img-blog.csdnimg.cn/7e4d74cc0c1a44c88eaf46e1f9c1dbd7.png)