文章目录
- 一、keepalived
- 1、KEEPALIVED作用
- 2、KEEPALIVED原理
- 3、KEEPALIVED工作模式
- 4、KEEPLIVED问题及优化
- 二、实验
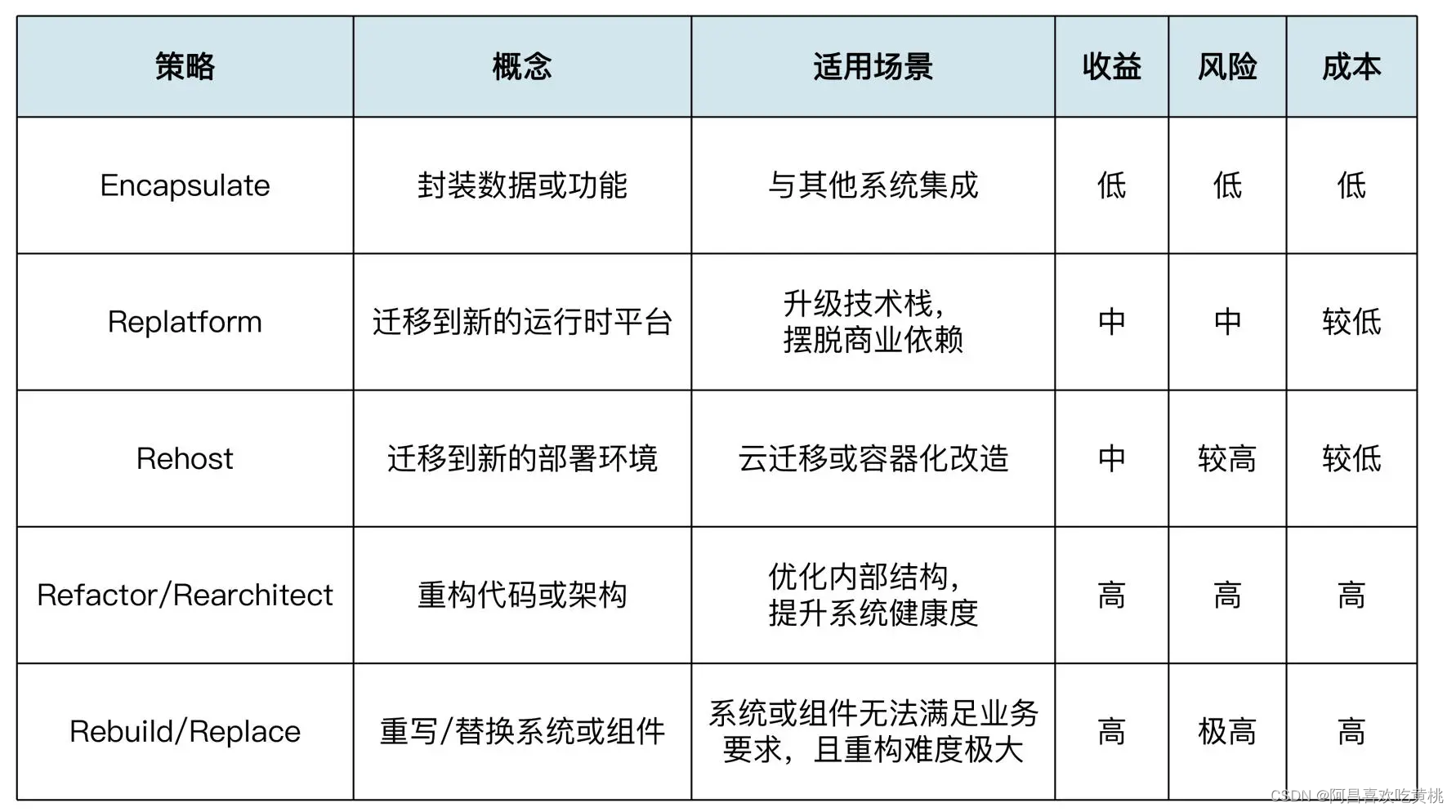
- 1.LVS+Keepalived 高可用群集
- 总结
一、keepalived
1、KEEPALIVED作用
保证负载均衡的高可用性,完美解决了LVS所有问题,可以检查后端服务器池种的服务器健康。
2、KEEPALIVED原理
利用VRRP协议原理,主备模式通过优先级判断谁是主谁是备。备机是否切换为主机依靠的是主备之间的心跳线。
3、KEEPALIVED工作模式
①抢占模式(默认模式):主坏了之后直接切换备为主服务器,主修好后直接抢占回主服务器。
②延时抢占模式:主坏了之后直接切换备为主服务器,主修好后检查是否完全稳定后再抢占回主服务器。
③不抢占模式:主坏了之后切换备为主服务器,原来的主服务器修好也不会再抢占为主服务器。
④心跳线模式:主备服务器之间心跳线模式默认是广播模式,可以根据需求改为组播或者单播模式。
4、KEEPLIVED问题及优化
①默认是抢占模式,根据需求改为非抢占模式或延时抢占模式。
②心跳线默认是广播模式,根据需求改为组播或单播模式。
③脑裂:备机由于种种原因收不到主机发送的心跳线,导致用户不知道访问那个服务器。例如:防火墙拦截心跳线广播报文、主备之间物理网线心跳线断裂等。
keepalived脑裂
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
脑裂的原因
高可用服务器对之间心跳线链路发生故障,导致无法正常通信。如心跳线坏了(包括断了,老化)。
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。
因心跳线间连接的设备故障(网卡及交换机)。
因仲裁的机器出问题(采用仲裁的方案)。
高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输。
Keepalived配置里同一 VRRP实例如果 virtual_router_id两端参数配置不一致也会导致裂脑问题发生。
vrrp实例名字不一致、优先级一致。
解决对策
添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
利用脚本检测、报警。
vim check_keepalived.sh
#!/bin/bash
$ip=192.168.169.10
while true
do
if [ `ip a show ens33 |grep $ip|wc -l` -ne 0 ]
then echo "keepalived is error!"
else echo "keepalived is OK !"
fi
done
④日志分隔:keepalived的默认日志在/var/log/message里,通过修改 /etc/sysconfig/keepalived中参数KEEPALIVED_OPTIONS=“-D -S local数字” ,并利用rsyslog将日志分隔出来
二、实验
1.LVS+Keepalived 高可用群集
主DR 服务器:192.168.169.10
备DR 服务器:192.168.169.50
Web 服务器1:192.168.169.20
Web 服务器2:192.168.169.30
vip:192.168.169.40
客户端:192.168.169.60
1.配置负载调度器(主、备相同)
systemctl stop firewalld.service
setenforce 0
yum -y install ipvsadm keepalived
modprobe ip_vs
cat /proc/net/ip_vs
2.配置keeplived(主、备DR 服务器上都要设置)
cd /etc/keepalived/
cp keepalived.conf keepalived.conf.bak
vim keepalived.conf
global_defs { #定义全局参数
--10行--修改,邮件服务指向本地
smtp_server 127.0.0.1
--12行--修改,指定服务器(路由器)的名称,主备服务器名称须不同,主为LVS_01,备为LVS_02
router_id LVS_01
--14行--注释掉,取消严格遵守VRRP协议功能,否则VIP无法被连接
#vrrp_strict
}
vrrp_instance VI_1 { #定义VRRP热备实例参数
--20行--修改,指定热备状态,主为MASTER,备为BACKUP
state MASTER
--21行--修改,指定承载vip地址的物理接口
interface ens33
--22行--修改,指定虚拟路由器的ID号,每个热备组保持一致
virtual_router_id 10
#nopreempt #如果设置非抢占模式,两个节点state必须为bakcup,并加上配置 nopreempt
--23行--修改,指定优先级,数值越大优先级越高,这里设置主为100,备为80
priority 100
advert_int 1 #通告间隔秒数(心跳频率)
authentication { #定义认证信息,每个热备组保持一致
auth_type PASS #认证类型
--27行--修改,指定验证密码,主备服务器保持一致
auth_pass abc123
}
virtual_ipaddress { #指定群集vip地址
192.168.169.188
}
}
--36行--修改,指定虚拟服务器地址(VIP)、端口,定义虚拟服务器和Web服务器池参数
virtual_server 192.168.169.188 80 {
delay_loop 6 #健康检查的间隔时间(秒)
lb_algo rr #指定调度算法,轮询(rr)
--39行--修改,指定群集工作模式,直接路由(DR)
lb_kind DR
persistence_timeout 0 #连接保持时间(秒)
protocol TCP #应用服务采用的是 TCP协议
--43行--修改,指定第一个Web节点的地址、端口
real_server 192.168.169.20 80 {
weight 1 #节点的权重
--45行--删除,添加以下健康检查方式
TCP_CHECK {
connect_port 80 #添加检查的目标端口
connect_timeout 3 #添加连接超时(秒)
nb_get_retry 3 #添加重试次数
delay_before_retry 3 #添加重试间隔
}
}
real_server 192.168.169.30 80 { #添加第二个 Web节点的地址、端口
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
##删除后面多余的配置##
}
修改主的配置文件
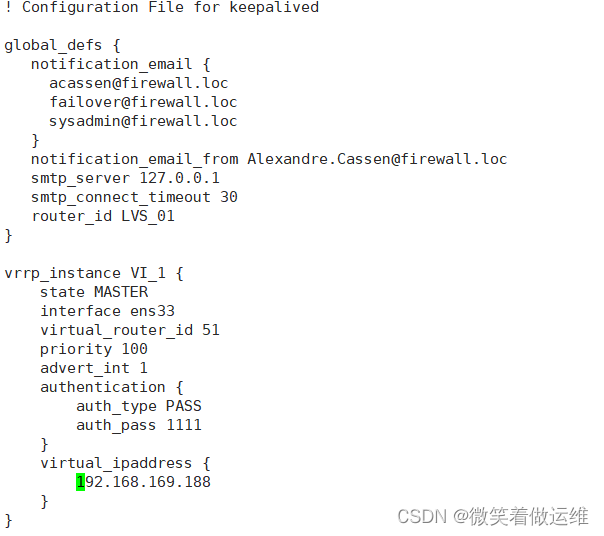
修改备的配置文件改名字优先级
重启一下服务
systemctl start keepalived
systemctl enable keepalived.service
用ip addr查看一下主的会有设置ip 备的没有
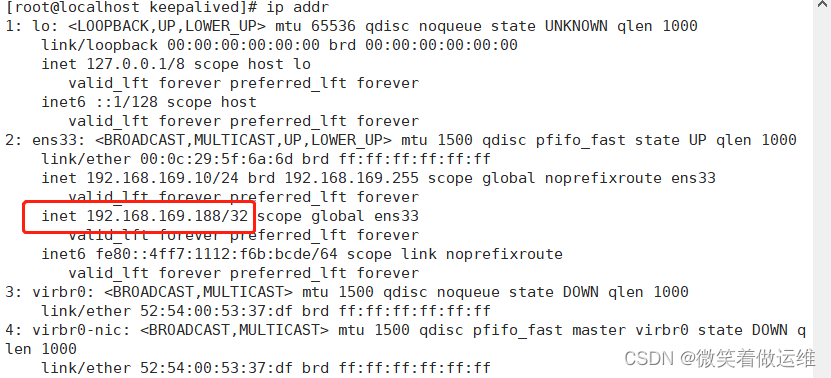
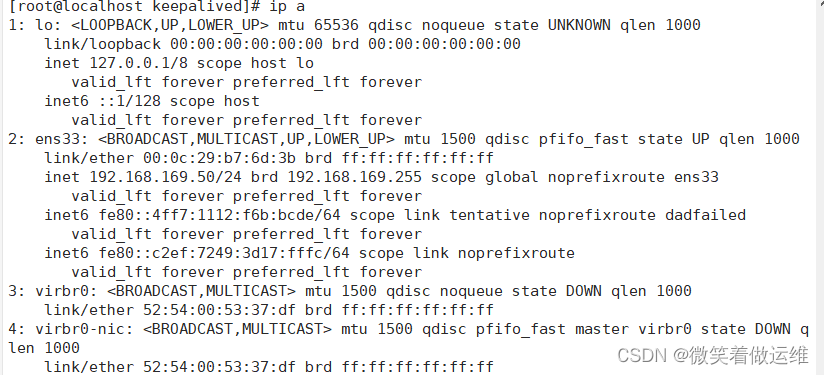
测试当把主停了备会不会有ip来顶替
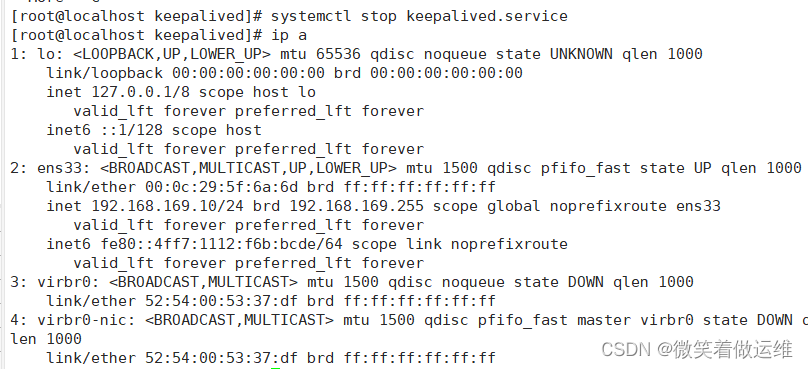

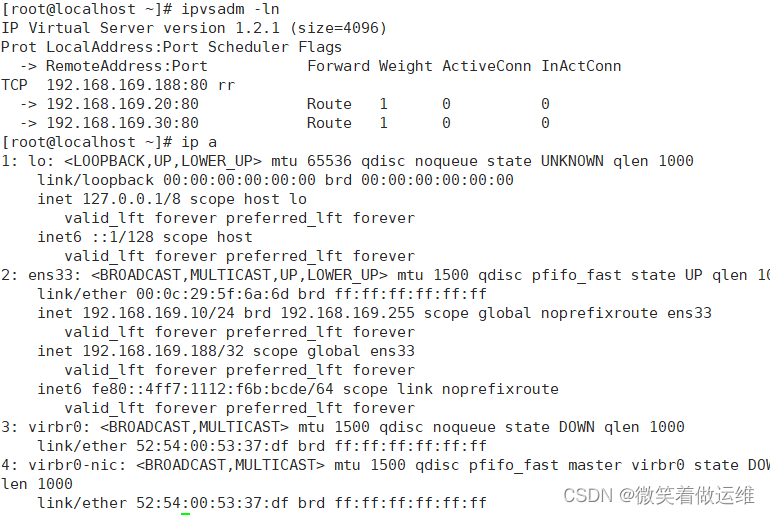
这里一开始遇到主ip出不来的情况后面重启服务解决了
ipvsadm -ln
#如没有VIP 的分发策略,则重启 keepalived 服务
systemctl restart keepalived
ok这时候我们的keepalive就布置好了
修改NFS共享网页内容
用客户端检测一下

测试验证
在客户端访问 http://192.168.169.188/
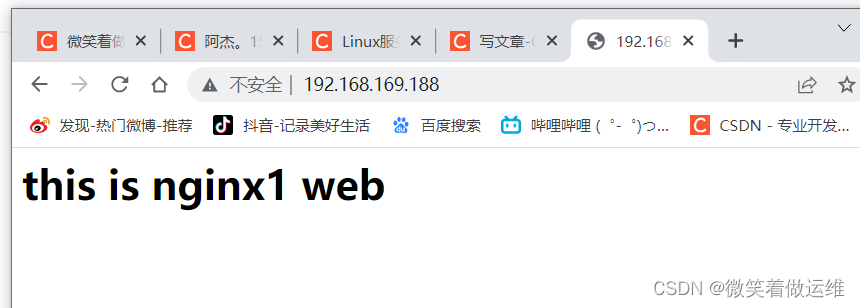
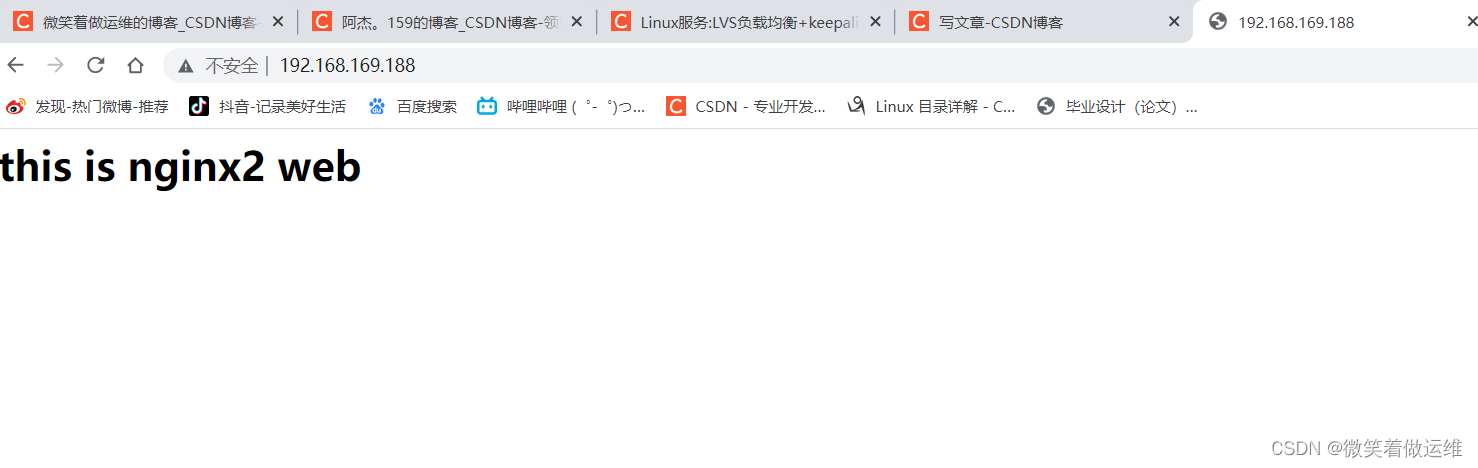
再在主服务器关闭 keepalived 服务后再测试
systemctl stop keepalived
实验成功自动切换为备
IP漂移
实现高可用负载均衡
总结
Keepalived通过什么判断哪台主机为主服务器,通过什么方式配置浮动IP?
答案:
Keepalived首先做初始化先检查state状态,master为主服务器,backup为备服务器。
然后再对比所有服务器的priority,谁的优先级高谁是最终的主服务器。
优先级高的服务器会通过ip命令为自己的电脑配置一个提前定义好的浮动IP地址。
keepalived的抢占与非抢占模式:
抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP
非抢占式俩节点state必须为bakcup,且必须配置nopreempt。
注意:这样配置后,我们要注意启动服务的顺序,优先启动的获取master权限,与优先级没有关系了。