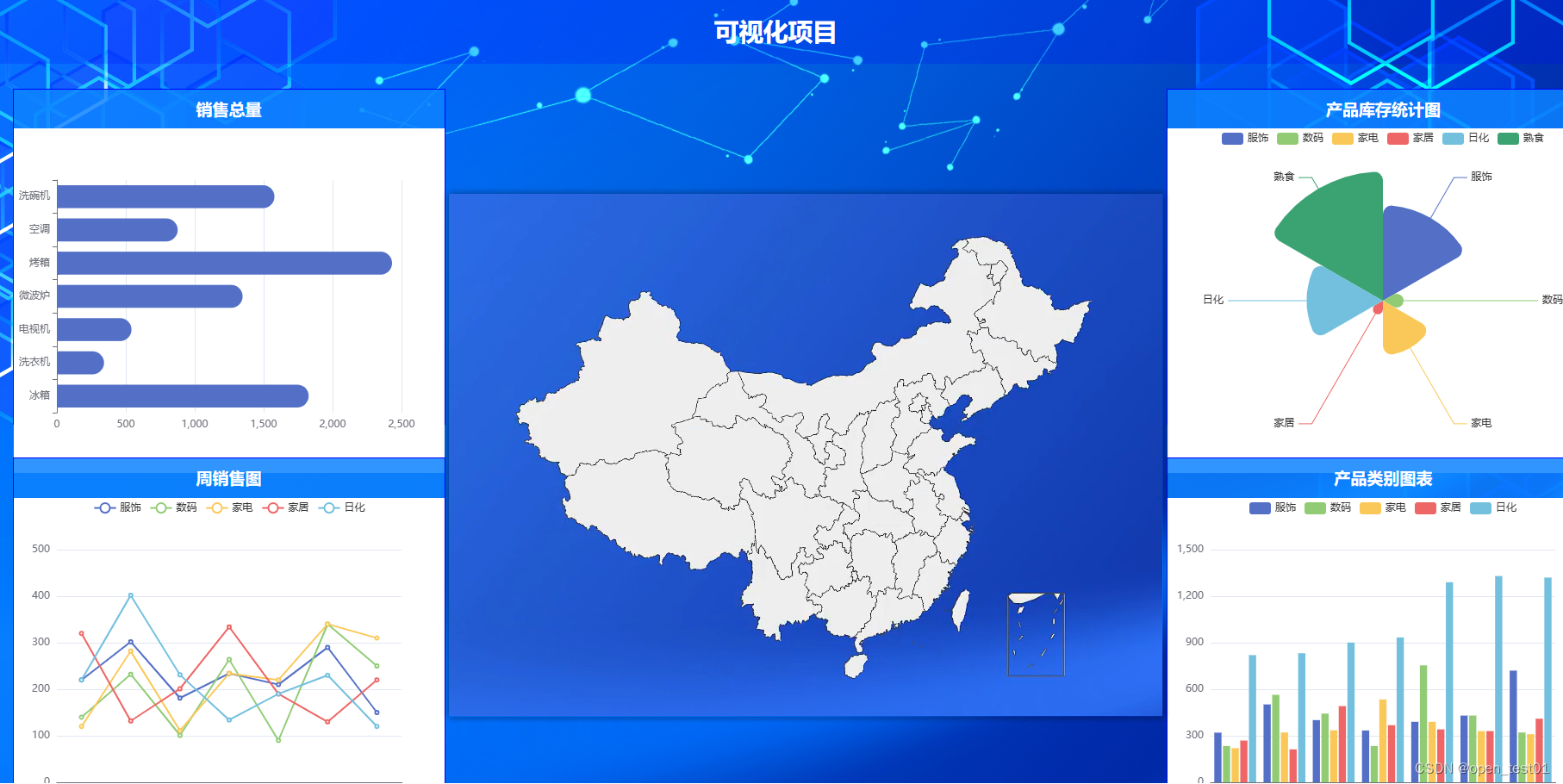
Chat GPT可以做什么?
- 分点列条的回答问题
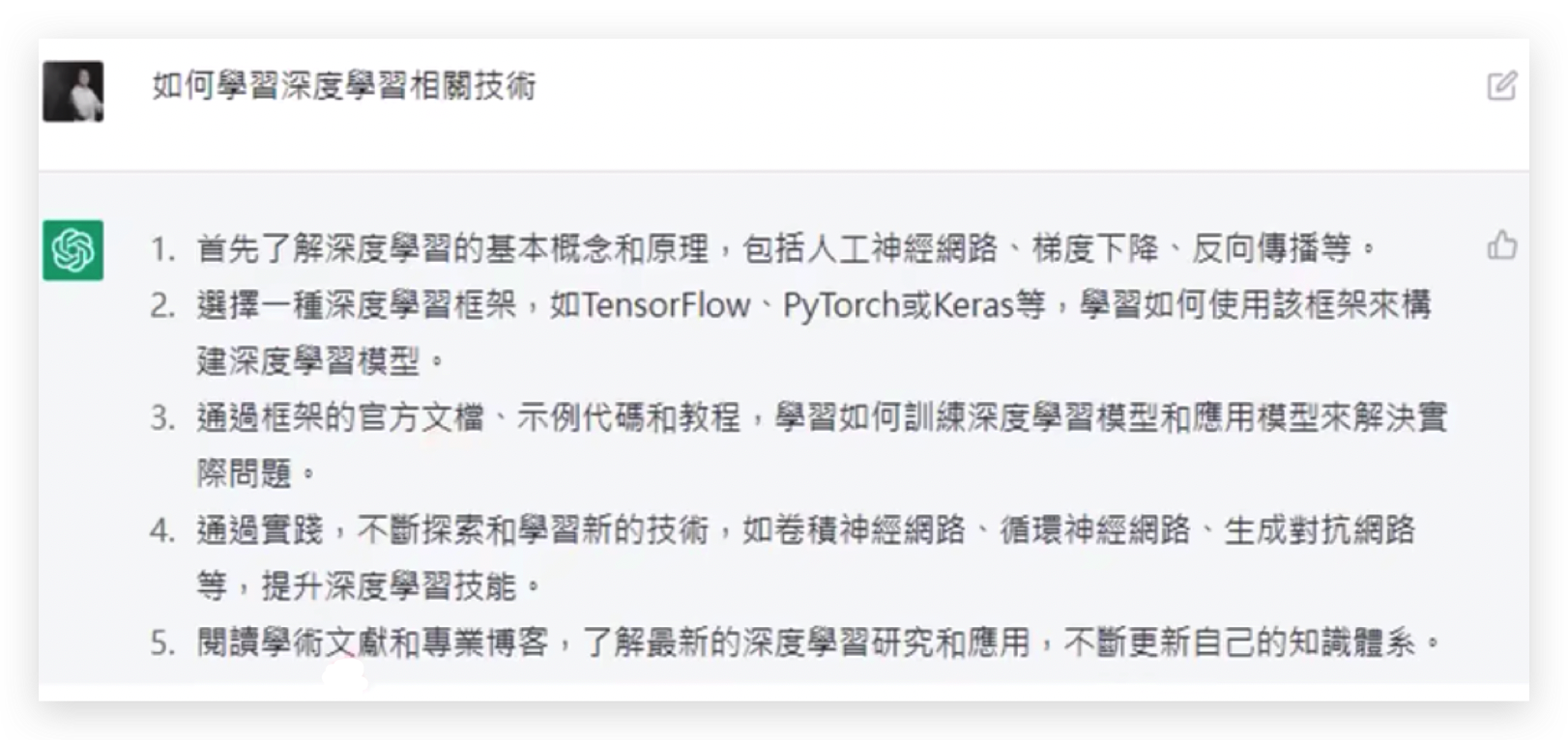
- 写代码或SQL
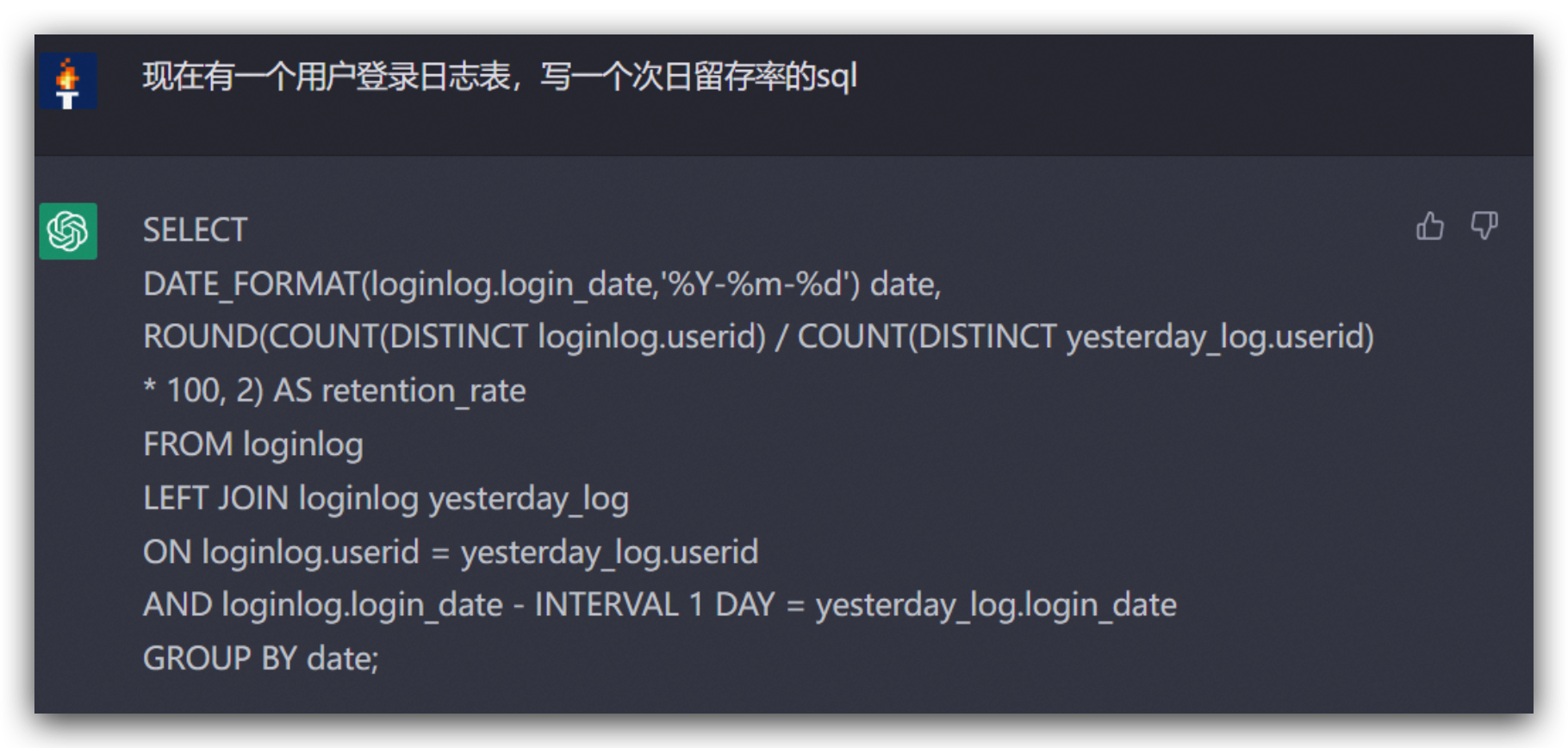
- 翻译

- 语法检查

ChatGPT官方还未公开论文,ChatGPT有一个“孪生兄弟”InstructGPT,InstructGPT有论文,可以根据InstructGPT论文推导ChatGPT的训练过程:
- ChatGPT的训练过程
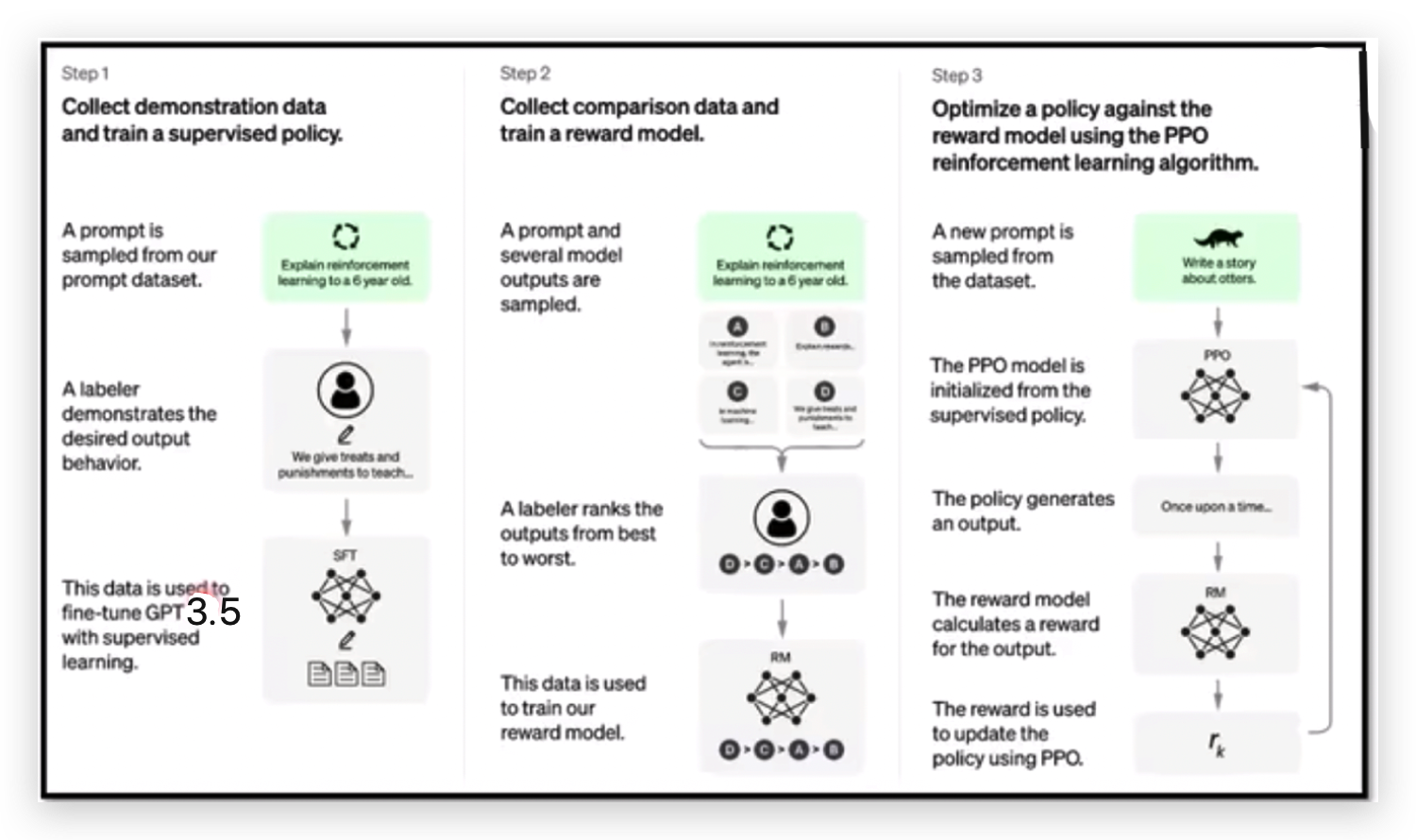
- InstructGPT的训练过程
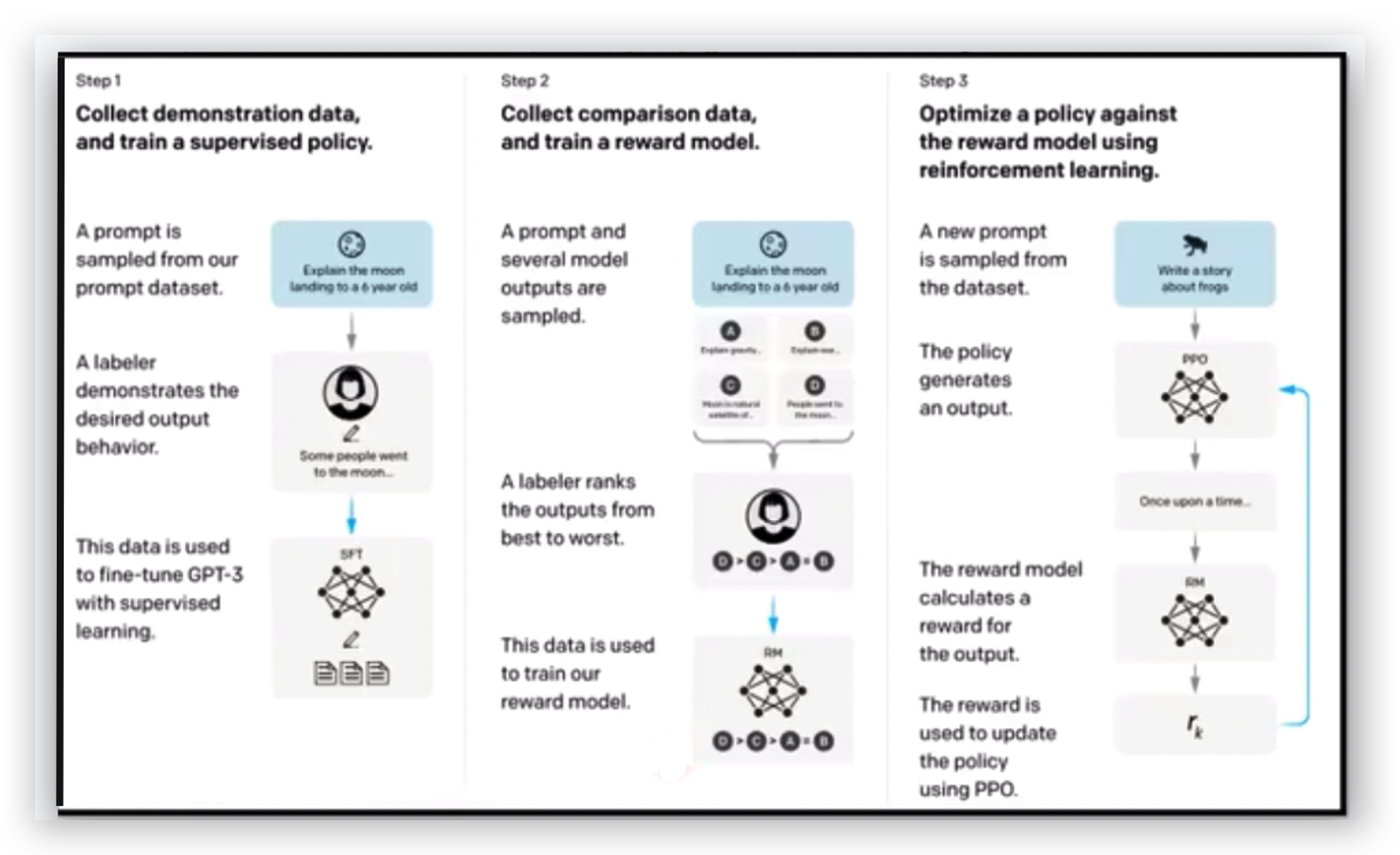
可以看到两者差距非常小,区别是两者使用的GPT版本不同。
所以看了InstructGPT论文应该就可以知道ChatGPT大致怎么被训练出来的了。
ChatGPT学习的四阶段
1 学习文字接龙
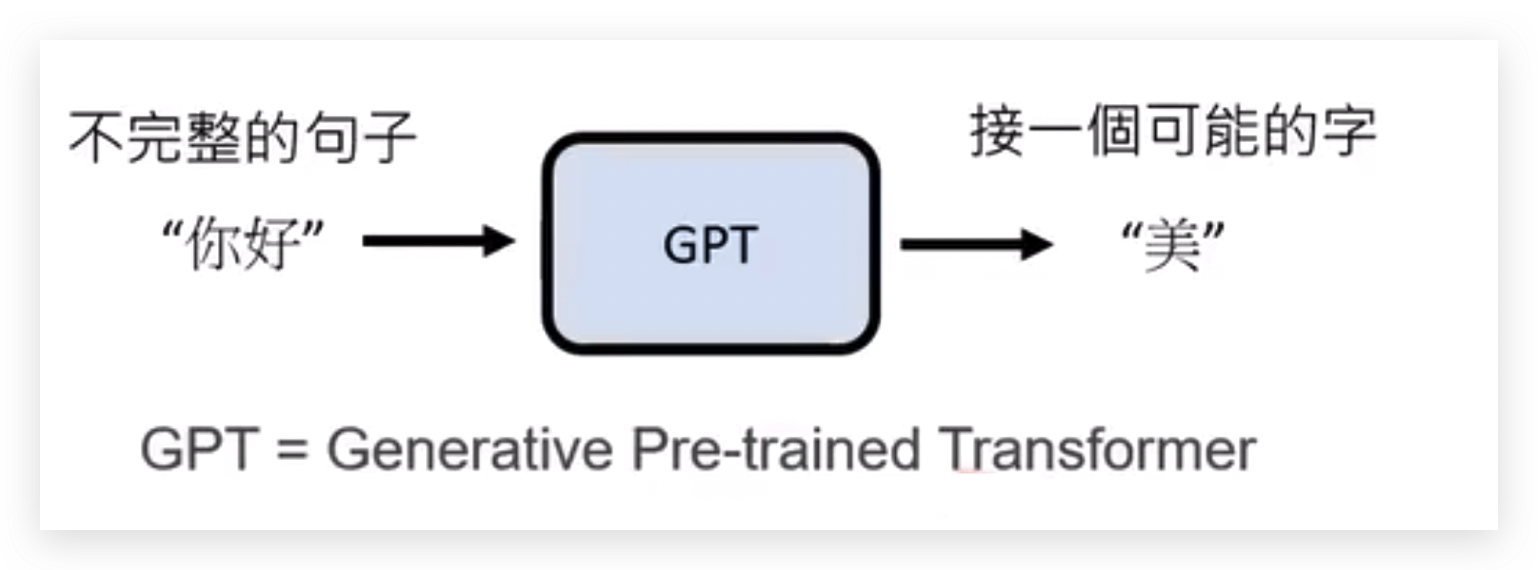
给GPT一个不完整的句子,GPT会想办法猜出这个句子接下来应该接哪字才是正确的。
怎么教一个模型做文字接龙?
文字接龙的学习是不需要人工标注的。
GPT要做的事情就是在网络上收集大量的文字,让GPT学文字接龙。
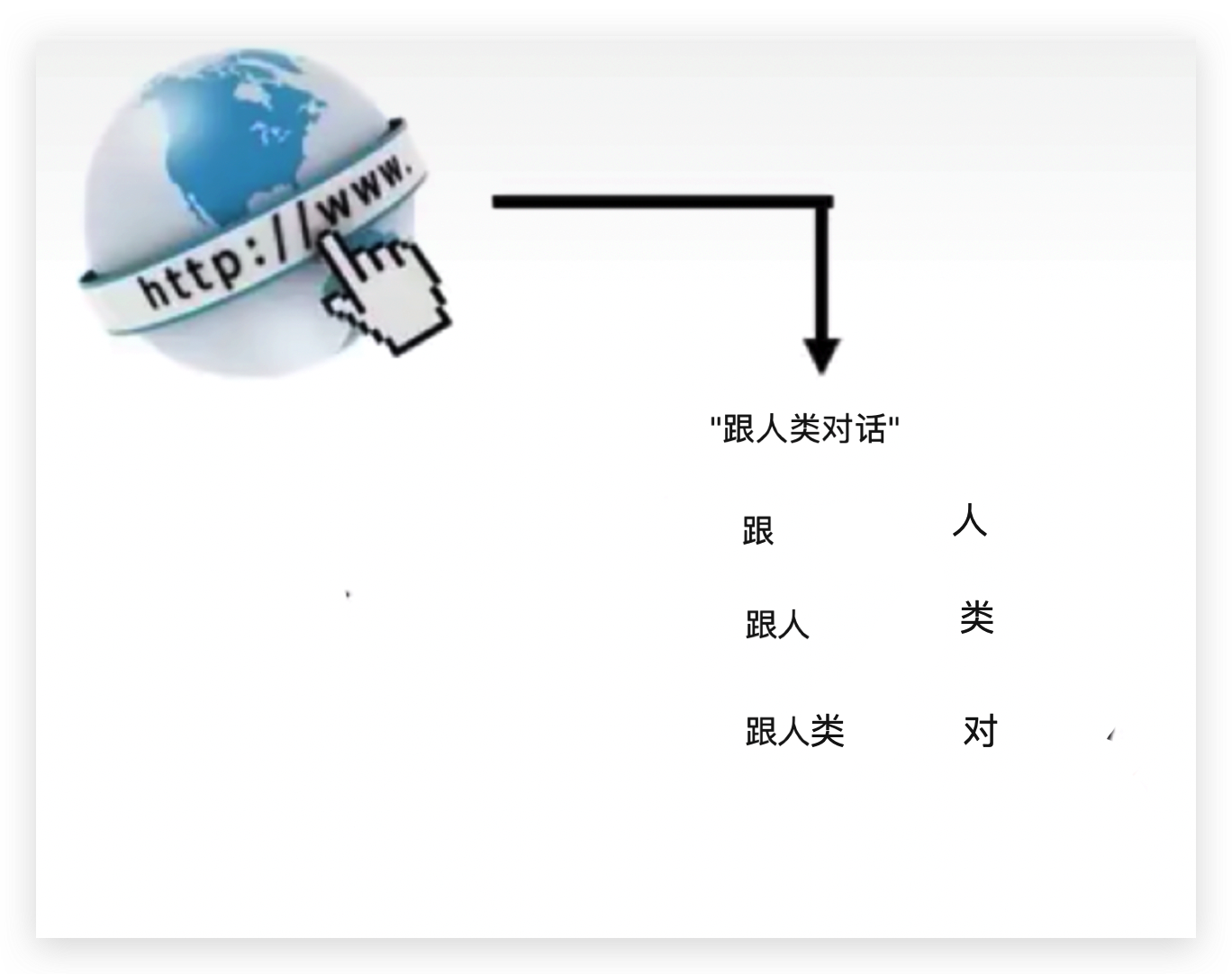
比如从网络上看到“跟人类对话”这句话,让GPT知道了“跟”后面跟“人”,“跟人”后面跟“类”,“跟人类”后面跟“对”。
“你好”这个不完整的句子后面可能接的词汇有很多,

GPT在学习做文字接龙的过程中,GPT真正输出的是一个几率分布。
比如输入“你好” ,后面跟“美”的几率,跟“高”的几率,跟“吗“的几率分别是多少。
接下来再从几率分布里随机抽取一个文字出来,几率比较高的字比较容易被抽取出来,几率比较低的字不太容易被抽取出来。
GPT的输出每一次都是不一样的。
让GPT补充一个不完整的句子,它每次补的结果都是随机性的。
每次补出来的结果都是不一样的,那学习文字接龙有什么用?
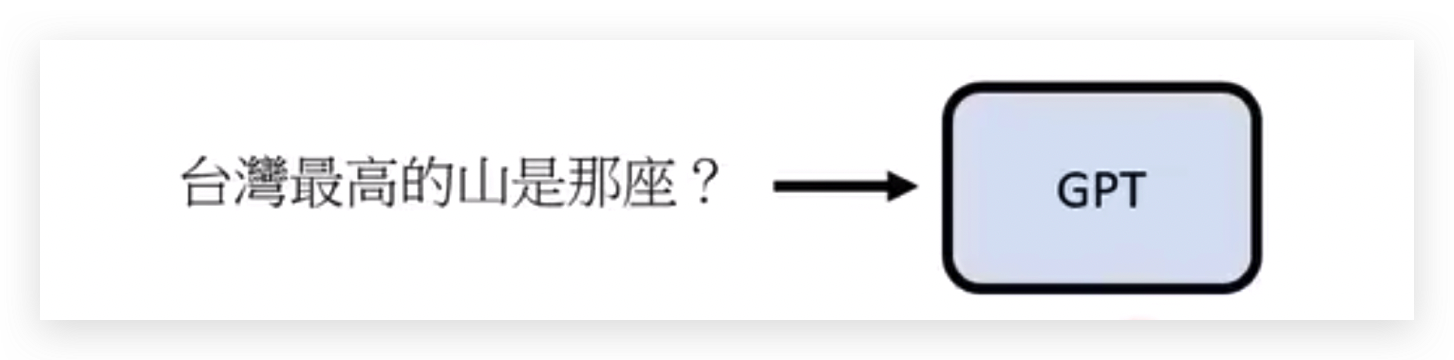
告诉GPT这是一个不完整的句子,接下来GPT想接哪个字呢?

第一个问题回答是“玉”,再将“玉”追加到第一个问题上作为新的问题再问GPT,回答“山”。
GPT的输出是随机的,GPT每次只会产生一个字。
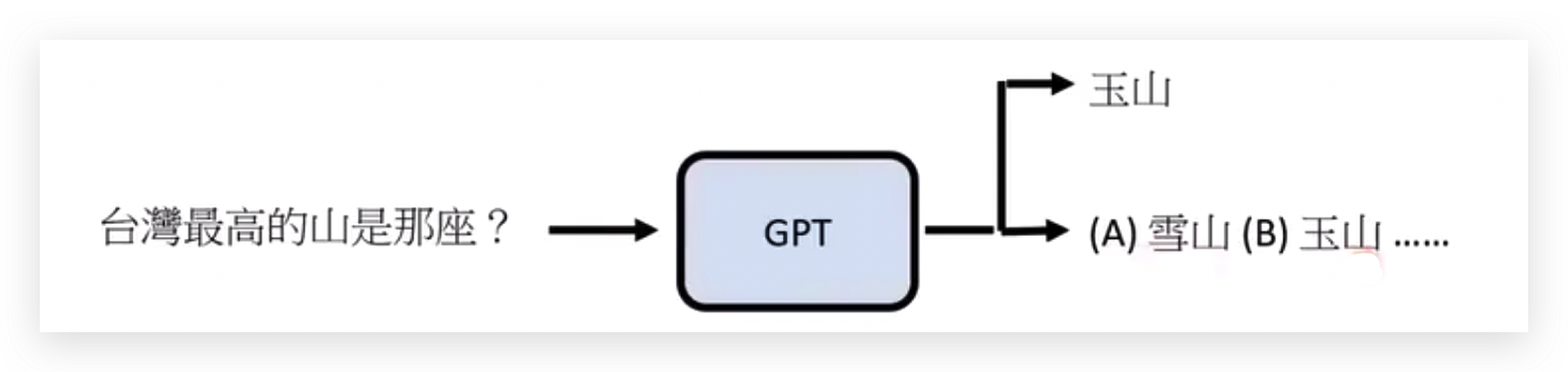
把所有产生的结果一次输出来,这样就形成一道选择题。
但实际产生的时候,还是一个字一个字产生的。
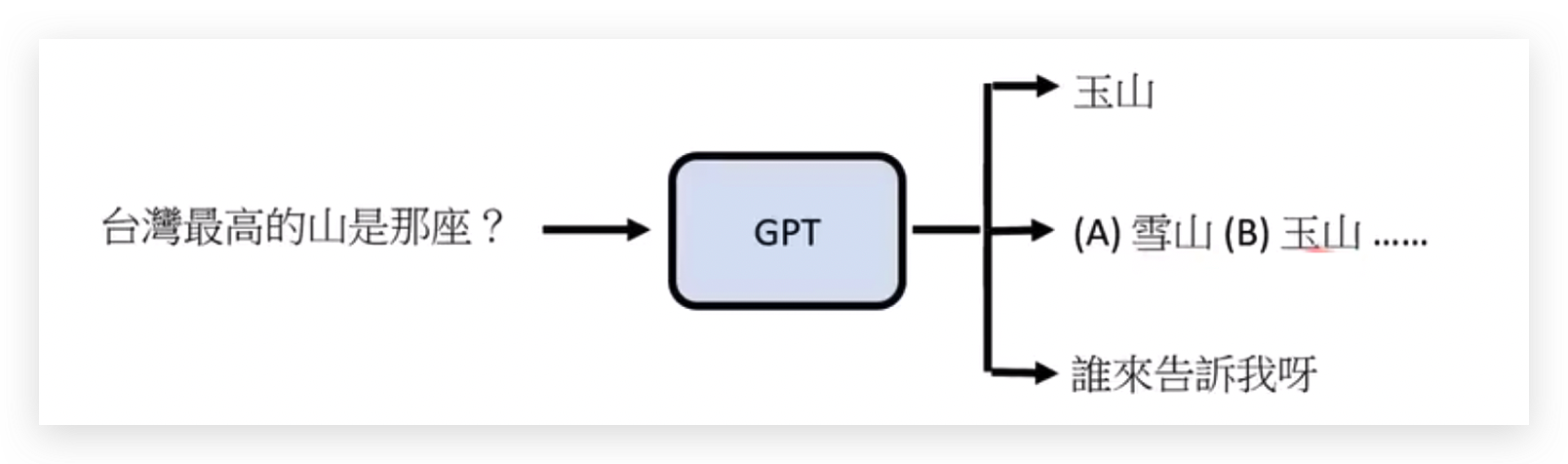
或者回答“谁来告诉我答案呀”,因为你并没有让它回答问题,所以可能会有这个答案。
GPT看到网络上有谁说过什么句子,它都可以拿来接,所以GPT在实际的使用上并没有那么好用,那怎么引导GPT产生有用的输出?
这就进入下一个阶段,
2 由人类老师引导文字接龙的方向
需要找人类来思考想问GPT的问题,提出问题之后,还需要人工把答案标记出来,有了这些资料以后,再丢给GPT做进一步的学习。
之前GPT在网络上看到一些有用的或没用的内容,GPT它不能分辨, 反正就是照单全收。
现在由人类提供想问GPT的问题并由人类提供标准的答案。
就让GPT多读一些我们觉着有意义的语料,真正帮人类做事的有用的内容,期待它可以变成人类真正的帮手。
那我们会不会穷举所有人类可能会问到的问题呢?答案是不用的。
虽然今天ChatGPT的论文还没有出,但是看instruct GPT你会发现并没有使用非常多人为标注的问题和答案,只有数万字而已。
那为什么不需要标注非常多的问题跟答案呢
因为这些答案本来GPT是就有能力产生的,只是它不知道哪些答案是人类希望它产生的。
GPT在网络上看到各式各样的内容,所以可能会产生各式各样奇怪的答案。
人类要做的事情只是激发它本来就有的力量,叫它讲出我们希望它讲的话,所以在第二阶段,可能每种类型的问题,提供几个范例可能就足够了。
3 模仿人类老师的喜好
openapi线上公开GPT api,就会有很多人使用这个api,就会有很多人不断的去问,接下来把这些问题收集好,让GPT产生这些问题的答案,因为GPT的答案是有随机性的,所以同一个问题会产生不同的答案。
接下来就由人类去标注哪些答案是好的答案,哪些答案是差的答案,人类老师并不一定要提供完整的正确答案,只需要告诉机器说哪个答案是比较好的,哪个答案是比较差的。
有了这个信息以后,接下来就要训练一个模仿老师的模型Teacher model,
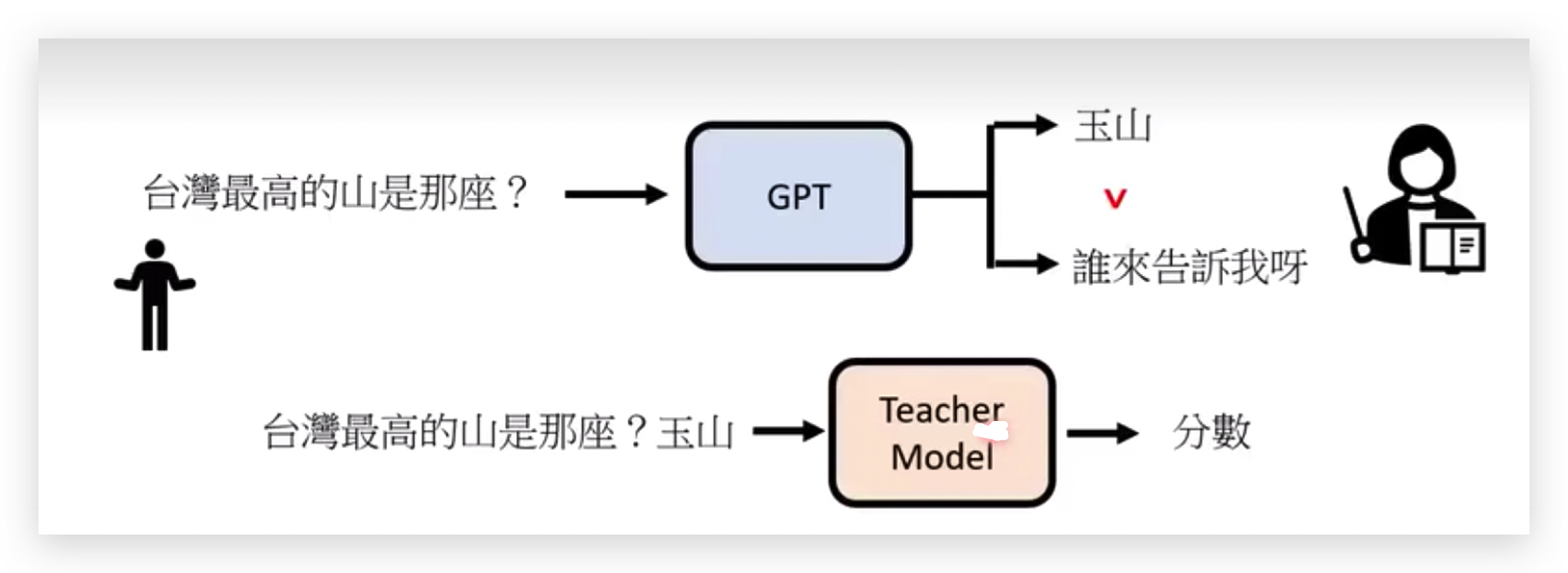
这个模型的作用是给GPT的问题和GPT输出的答案输出一个分数,这个模型学习的目标就是模仿人类老师评分的标准,如果人类的标注告诉GPT,“玉山”这个答案好于“谁来告诉我”这个答案,那Teacher model模型就可以模仿人类的偏好。
4 用增强式学习向模拟老师学习
用增强式学习(Reinforcement Learning)让GPT向模拟老师学习,
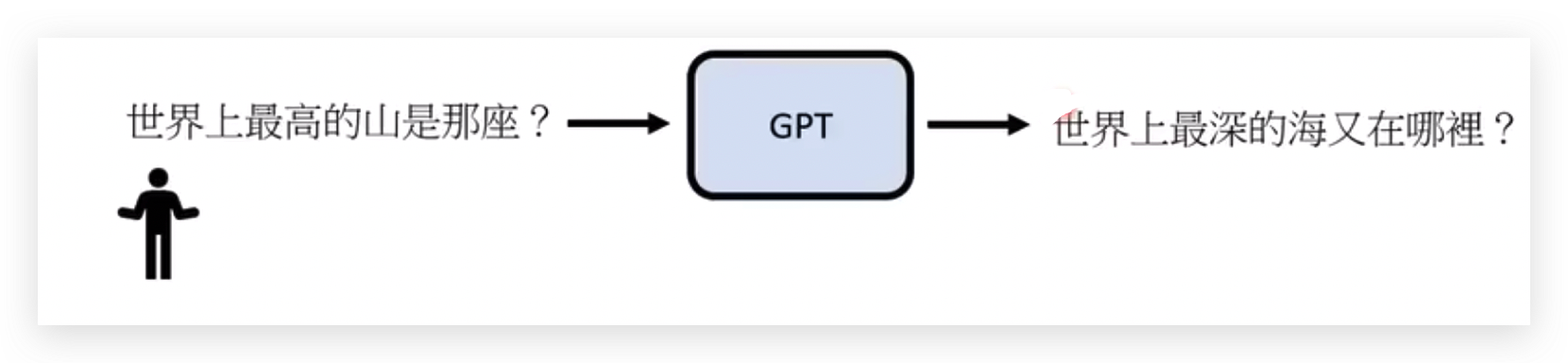
比如问这个问题,回答这个答案。
这虽然是一个正确的接法,但不是人类想要的。
那现在GPT有了一个老师的模型,那就把输入的问题和答案一起丢给老师模型,这个老师模型就会学了人类的偏好。
GPT在前面的学习中知道,如果答案是一个问句,则不是一个好的答案,应该要给予低分。
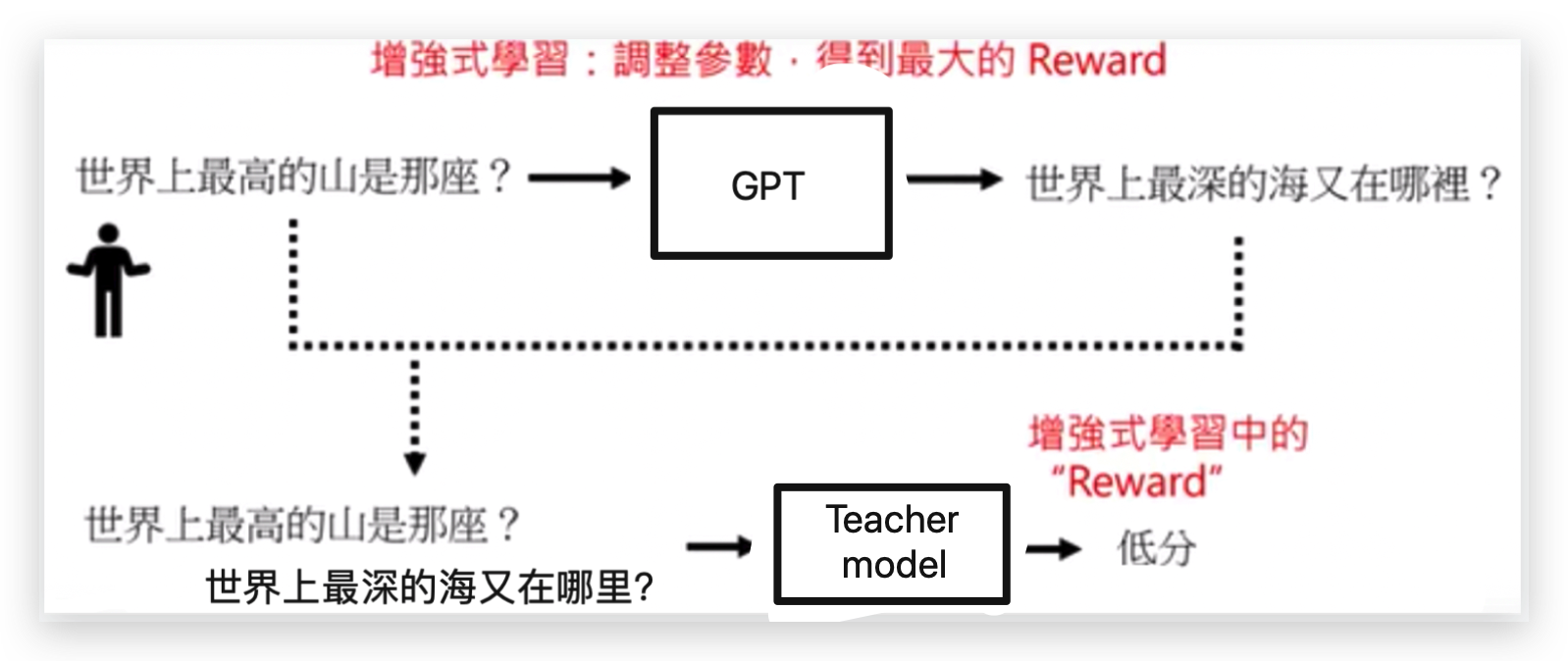
那Teacher model模型输出的就是增强式学习(Reinforcement Learning)的reward。
接下来用增强式学习的技术来调整GPT参数,调整的目标就是希望得到最高的reward,即希望GPT的输出结果会让Teacher model给予高分,也就是人类会觉的满意的答案。
透过Reinforcement Learning技术让GPT可能会学到:问“世界上最高的山是哪座?“,不会再随便接一个问句,而是输出“喜马拉雅山”。
即把问题和答案都丢给Teacher model模型,这个模型会评估出一个分数比较高的答案。
GPT经过增强式学习(Reinforcement Learning)之后,就是Chat GPT了。