目录
- 1 环境准备
- 1.1 安装MySQL 5.7.31
- 1.2 安装Hive 2.1
- 1.3 安装Zookeeper 3.4.6
- 1.4 安装Kafka 2.4.1
- 2 滴滴运营分析
- 2.1 需求说明
- 2.2 环境准备
- 2.2.1 工具类SparkUtils
- 2.2.2 日期转换星期
- 2.3 数据ETL保存
- 2.3.1 开发步骤
- 2.3.2 加载CSV数据
- 2.3.3 数据ETL转换
- 2.3.4 保存数据至Hudi
- 2.3.5 Hudi 表存储结构
- 2.4 指标查询分析
- 2.4.1 开发步骤
- 2.4.2 加载Hudi表数据
- 2.4.3 指标一:订单类型统计
- 2.4.4 指标二:订单时效性统计
- 2.4.5 指标三:订单交通类型统计
- 2.4.6 指标四:订单价格统计
- 2.4.7 指标五:订单距离统计
- 2.4.8 指标六:订单星期统计
- 2.5 集成Hive查询
- 2.5.1 创建表及查询
- 2.5.2 HiveQL 分析
- 3 结构化流写入Hudi
- 3.1 模拟交易订单
- 3.2 流式程序开发
- 3.3 Spark 查询分析
- 3.4 DeltaStreamer 工具类
- 4 集成 SparkSQL
- 4.1 启动spark-sql
- 4.2 快速入门
- 4.2.1 创建表
- 4.2.2 插入数据
- 4.2.3 查询数据
- 4.2.4 更新数据
- 4.2.5 删除数据
- 4.3 DDL 创建表
- 4.4 MergeInto 语句
- 4.4.1 Merge Into Insert
- 4.4.2 Merge Into Update
- 4.4.3 Merge Into Delete
1 环境准备

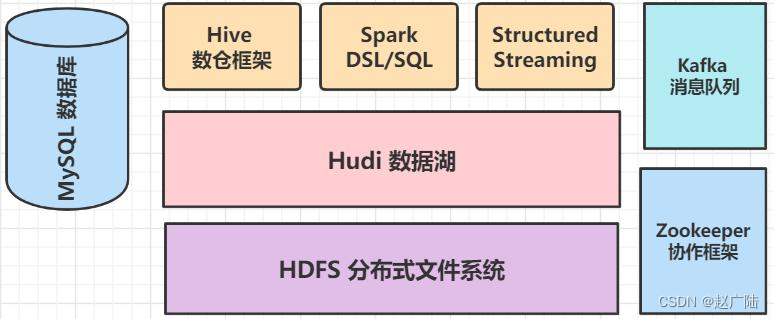
Hudi数据湖框架,开始与Spark分析引擎框架整合,通过Spark保存数据到Hudi表,使用Spark加载Hudi表数据进行分析,不仅支持批处理和流计算,还可以集成Hive进行数据分析,安装大数据其他框架:MySQL、Hive、Zookeeper及Kafka,便于案例集成整合使用。
1.1 安装MySQL 5.7.31
采用tar方式安装MySQL数据库,具体命令和相关说明如下
1. 检查系统是否安装过mysql
rpm -qa|grep mysql
2. 卸载CentOS7系统自带mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs.xxxxxxx
3. 删除etc目录下的my.cnf ,一定要删掉,等下再重新建
rm /etc/my.cnf
4. 创建mysql 用户组和用户
groupadd mysql
useradd -r -g mysql mysql
5. 下载安装,从官网安装下载,位置在/usr/local/
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
6. 解压安装mysql
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local/
mv mysql-5.7.31-linux-glibc2.12-x86_64 mysql
7. 进入mysql/bin/目录,编译安装并初始化mysql,务必记住数据库管理员临时密码
cd mysql/bin/
./mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql
8. 编写配置文件 my.cnf ,并添加配置
vi /etc/my.cnf
[mysqld]
datadir=/usr/local/mysql/data
port = 3306
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
symbolic-links=0
max_connections=400
innodb_file_per_table=1
lower_case_table_names=1
9. 启动mysql 服务器
/usr/local/mysql/support-files/mysql.server start
10. 添加软连接,并重启mysql 服务
ln -s /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
service mysql restart
11. 登录mysql ,密码就是初始化时生成的临时密码 X_j&N*wy1q7<
mysql -u root -p
12、修改密码,因为生成的初始化密码难记
set password for root@localhost = password('123456');
13、开放远程连接
use mysql;
update user set user.Host='%' where user.User='root';
flush privileges;
14. 设置开机自启
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
最后使用MySQL数据库客户端远程链接数据库,测试是否成功。
1.2 安装Hive 2.1
直接解压Hive框架tar包,配置HDFS依赖及元数据存储MySQL数据库信息,最后启动元数据服务Hive MetaStore和HiveServer2服务。
1. 上传,解压
[root@node1 ~]# cd /export/software/
[root@node1 server]# rz
[root@node1 server]# chmod u+x apache-hive-2.1.0-bin.tar.gz
[root@node1 server]# tar -zxf apache-hive-2.1.0-bin.tar.gz -C /export/server
[root@node1 server]# cd /export/server
[root@node1 server]# mv apache-hive-2.1.0-bin hive-2.1.0-bin
[root@node1 server]# ln -s hive-2.1.0-bin hive
2. 配置环境变量
[root@node1 server]# cd hive/conf/
[root@node1 conf]# mv hive-env.sh.template hive-env.sh
[root@node1 conf]# vim hive-env.sh
HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
3. 创建HDFS目录
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
[root@node1 ~]# hdfs dfs -mkdir -p /tmp
[root@node1 ~]# hdfs dfs -mkdir -p /usr/hive/warehouse
[root@node1 ~]# hdfs dfs -chmod g+w /tmp
[root@node1 ~]# hdfs dfs -chmod g+w /usr/hive/warehouse
4. 配置文件hive-site.xml
[root@node1 ~]# cd /export/server/hive/conf
[root@node1 conf]# vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1.oldlu.cn:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.oldlu.cn:9083</value>
</property>
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>123456</value>
</property>
</configuration>
5. 添加用户权限配置
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop
[root@node1 hadoop] vim core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
6. 初始化数据库
[root@node1 ~]# cd /export/server/hive/lib
[root@node1 lib]# rz
mysql-connector-java-5.1.48.jar
[root@node1 ~]# cd /export/server/hive/bin
[root@node1 bin]# ./schematool -dbType mysql -initSchema
7. 启动HiveMetaStore服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# nohup bin/hive --service metastore >/dev/null &
8. 启动HiveServer2服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/hive --service hiveserver2 >/dev/null &
9. 启动beeline命令行
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/beeline -u jdbc:hive2://node1.oldlu.cn:10000 -n root -p 123456
服务启动成功后,使用beeline客户端连接,创建数据库和表,导入数据与查询测试。
1.3 安装Zookeeper 3.4.6
上传Zookeeper软件至安装目录,解压和配置环境,命令如下所示:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software]# rz
zookeeper-3.4.6.tar.gz
给以执行权限
[root@node1 software]# chmod u+x zookeeper-3.4.6.tar.gz
解压tar包
[root@node1 software]# tar -zxf zookeeper-3.4.6.tar.gz -C /export/server
创建软链接
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s zookeeper-3.4.6 zookeeper
配置zookeeper
[root@node1 ~]# cd /export/server/zookeeper/conf
[root@node1 conf]# mv zoo_sample.cfg zoo.cfg
[root@node1 conf]# vim zoo.cfg
修改内容:
dataDir=/export/server/zookeeper/datas
[root@node1 conf]# mkdir -p /export/server/zookeeper/datas
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@node1 ~]# source /etc/profile
启动Zookeeper服务,查看状态,命令如下:
启动服务
[root@node1 ~]# cd /export/server/zookeeper/
[root@node1 zookeeper]# bin/zkServer.sh start
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Mode: standalone
1.4 安装Kafka 2.4.1
上传Kafka软件至安装目录,解压和配置环境,命令如下所示:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software~]# rz
kafka_2.12-2.4.1.tgz
[root@node1 software]# chmod u+x kafka_2.12-2.4.1.tgz
解压tar包
[root@node1 software]# tar -zxf kafka_2.12-2.4.1.tgz -C /export/server
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s kafka_2.12-2.4.1 kafka
配置kafka
[root@node1 ~]# cd /export/server/kafka/config
[root@node1 conf]# vim server.properties
修改内容:
listeners=PLAINTEXT://node1.oldlu.cn:9092 log.dirs=/export/server/kafka/kafka-logs
zookeeper.connect=node1.oldlu.cn:2181/kafka
创建存储目录
[root@node1 ~]# mkdir -p /export/server/kafka/kafka-logs
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export KAFKA_HOME=/export/server/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@node1 ~]# source /etc/profile
启动Kafka服务,查看状态,命令如下:
启动服务
[root@node1 ~]# cd /export/server/kafka
[root@node1 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
[root@node1 kafka]# jps
2188 QuorumPeerMain
2639 Kafka
2 滴滴运营分析
以滴滴为首的互联网叫车平台的出现,在重构线下叫车市场的同时,也为市场其他闲置资源提供了更多盈利的可能性。自与快的合并和并购Uber中国以后,滴滴牢牢占据着国内出行市场第一的位置,在飞速发展的同时也不断向广大用户提供多元化的服务,不断优化社会汽车出行方面的资源配置问题。本次样本为随机抽取2017年5月至10月海口市每天的滴滴订单数据,共14160162条。
海口市是南方的旅游大城,滴滴公司在此的业务发展由来已久,积累了大量的业务订单数据,在此利用其2017年下半年的订单数据,做一些简单的统计分析,来看在那段时间内滴滴公司在海口市的业务发展情况并尝试揭示海口市用户的部分出行特征。
■快车出行为滴滴运营过程中的主流订单类型;
■滴滴出行订单中,预约用车市占率极低,仍以实时预约为主;
■接送机订单仅占总订单量的4%;
■绝大多数订单距离集中在0-15公里,价格集中在0-100元;
■工作日期间,居民对网约车的出行需求降低,而在周末时较为旺盛;

2.1 需求说明
滴滴出行数据为2017年5月1日-10月31日(半年)海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。具体字段含义说明如下所示:
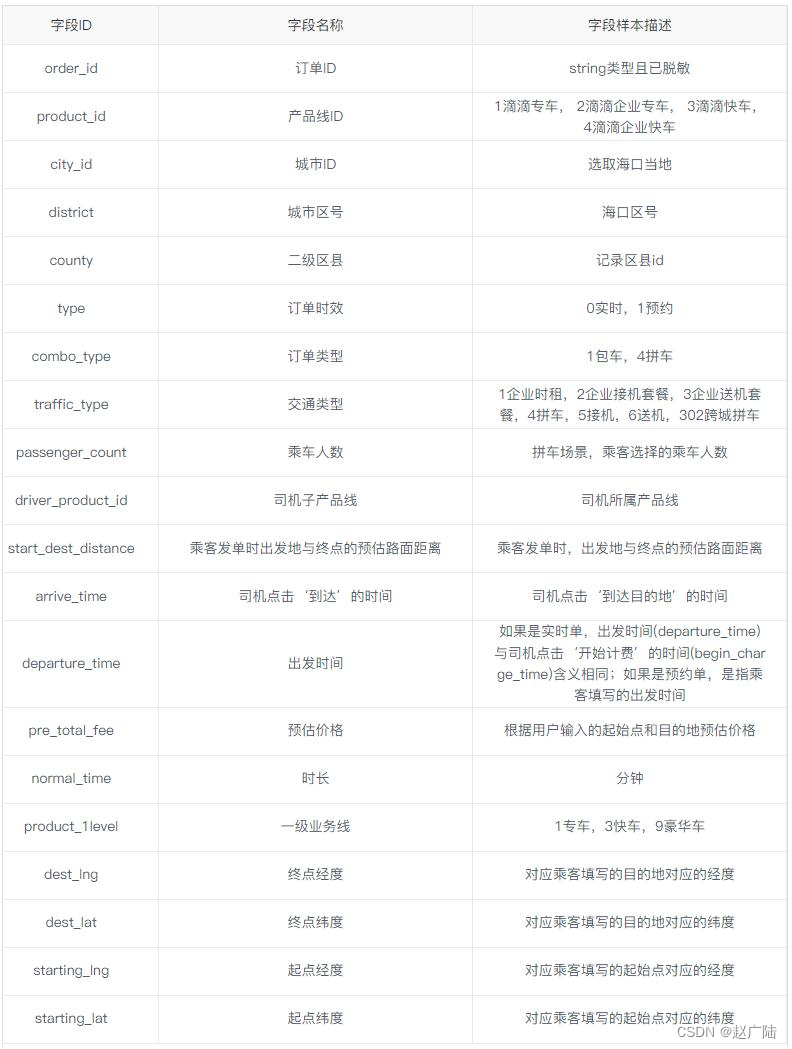
依据海口滴滴出行数据,按照如下需求统计分析:

2.2 环境准备
基于前面Maven Project,创建相关目录和包,结构如下图所示:
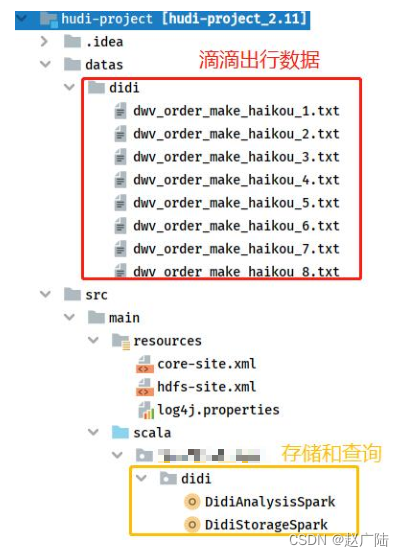
其中滴滴出行数据放在Maven Project工程【datas】本地文件系统目录下。对滴滴出行分析,程序分为两个部分:数据存储Hudi表【DidiStorageSpark】和指标计算统计分析【DidiAnalysisSpark】。
2.2.1 工具类SparkUtils
无论数据ETL保存,还是数据加载统计,都需要创建SparkSession实例对象,所以编写工具类SparkUtils,创建方法【createSparkSession】构建实例,代码如下:
package cn.oldlu.hudi.didi
import org.apache.spark.sql.SparkSession
/**
* SparkSQL操作数据(加载读取和保存写入)时工具类,比如获取SparkSession实例对象等
*/
object SparkUtils {
/**
* 构建SparkSession实例对象,默认情况下本地模式运行
*/
def createSparkSession(clazz: Class[_],
master: String = "local[4]", partitions: Int = 4): SparkSession = {
SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.master(master)
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.shuffle.partitions", partitions)
.getOrCreate()
}
}
2.2.2 日期转换星期
查询分析指标中,需要将日期时间字段值,转换为星期,方便统计工作日和休息日滴滴出行情况,测试代码如下,传递日期时间字符串,转换为星期。
package cn.oldlu.hudi.test
import java.util.{Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
/**
* 将日期转换星期,例如输入:2021-06-24 -> 星期四
* https://www.cnblogs.com/syfw/p/14370793.html
*/
object DayWeekTest {
def main(args: Array[String]): Unit = {
val dateStr: String = "2021-06-24"
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd")
val calendar: Calendar = Calendar.getInstance()
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek: String = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
println(dayWeek)
}
}
解析编写代码,本地文件系统加载滴滴出行数据,存储至Hudi表,最后按照指标统计分析。
2.3 数据ETL保存
从本地文件系统LocalFS加载海口市滴滴出行数据,进行相应ETL转换,最终存储Hudi表。
2.3.1 开发步骤
编写SparkSQL程序,实现数据ETL转换保存,分为如下5步:
■step1. 构建SparkSession实例对象(集成Hudi和HDFS)
■step2. 加载本地CSV文件格式滴滴出行数据
■step3. 滴滴出行数据ETL处理
■stpe4. 保存转换后数据至Hudi表
■step5. 应用结束关闭资源
数据ETL转换保存程序:DidiStorageSpark,其中MAIN方法代码如下:
package cn.oldlu.hudi.didi
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用 SparkSQL 操作数据,先读取 CSV 文件,保存至 Hudi 表。
* -1. 数据集说明
* 2017 年 5 月 1 日 -10 月 31 日海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的
订单属性数据。
* 数据存储为 CSV 格式,首行为列名称
* -2. 开发主要步骤* step1. 构建 SparkSession 实例对象(集成 Hudi 和 HDFS )
* step2. 加载本地 CSV 文件格式滴滴出行数据
* step3. 滴滴出行数据 ETL 处理
* stpe4. 保存转换后数据至 Hudi 表
* step5. 应用结束关闭资源
*/
object DidiStorageSpark {
// 滴滴数据路径
val datasPath: String = "datas/didi/dwv_order_make_haikou_2.txt"
// Hudi中表的属性
val hudiTableName: String = "tbl_didi_haikou"
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit = {
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass)
import spark.implicits._
// step2. 加载本地CSV文件格式滴滴出行数据
val didiDF: DataFrame = readCsvFile(spark, datasPath)
// didiDF.printSchema()
// didiDF.show(10, truncate = false)
// step3. 滴滴出行数据ETL处理并保存至Hudi表
val etlDF: DataFrame = process(didiDF)
//etlDF.printSchema()
//etlDF.show(10, truncate = false)
// stpe4. 保存转换后数据至Hudi表
saveToHudi(etlDF, hudiTableName, hudiTablePath)
// stpe5. 应用结束,关闭资源
spark.stop()
}
分别实现MAIN中三个方法:加载csv数据、数据etl转换和保存数据。
2.3.2 加载CSV数据
编写方法,封装SparkSQL加载CSV格式滴滴出行数据,具体代码如下:
/**
* 读取CSV格式文本文件数据,封装到DataFrame数据集
*/
def readCsvFile(spark: SparkSession, path: String): DataFrame = {
spark.read
// 设置分隔符为逗号
.option("sep", "\\t")
// 文件首行为列名称
.option("header", "true")
// 依据数值自动推断数据类型
.option("inferSchema", "true")
// 指定文件路径
.csv(path)
}
2.3.3 数据ETL转换
编写方法,对滴滴出行数据ETL转换,添加字段【ts】和【partitionpath】,方便保存数据至Hudi表时,指定字段名称。具体代码如下:
/**
* 对滴滴出行海口数据进行ETL转换操作:指定ts和partitionpath 列
*/
def process(dataframe: DataFrame): DataFrame = {
dataframe
// 添加分区列:三级分区 -> yyyy/MM/dd
.withColumn(
"partitionpath", // 列名称
concat_ws("/", col("year"), col("month"), col("day")) //
)
// 删除列:year, month, day
.drop("year", "month", "day")
// 添加timestamp列,作为Hudi表记录数据与合并时字段,使用发车时间
.withColumn(
"ts",
unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")
)
}
2.3.4 保存数据至Hudi
编写方法,将ETL转换后数据,保存到Hudi表中,采用COW模式,具体代码如下:
/**
* 将数据集DataFrame保存值Hudi表中,表的类型:COW
*/
def saveToHudi(dataframe: DataFrame, table: String, path: String): Unit = {
// 导入包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
// 保存数据
dataframe.write
.mode(SaveMode.Overwrite)
.format("hudi") // 指定数据源为Hudi
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性设置
.option(RECORDKEY_FIELD_OPT_KEY, "order_id")
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
// 表的名称和路径
.option(TABLE_NAME, table)
.save(path)
}
2.3.5 Hudi 表存储结构
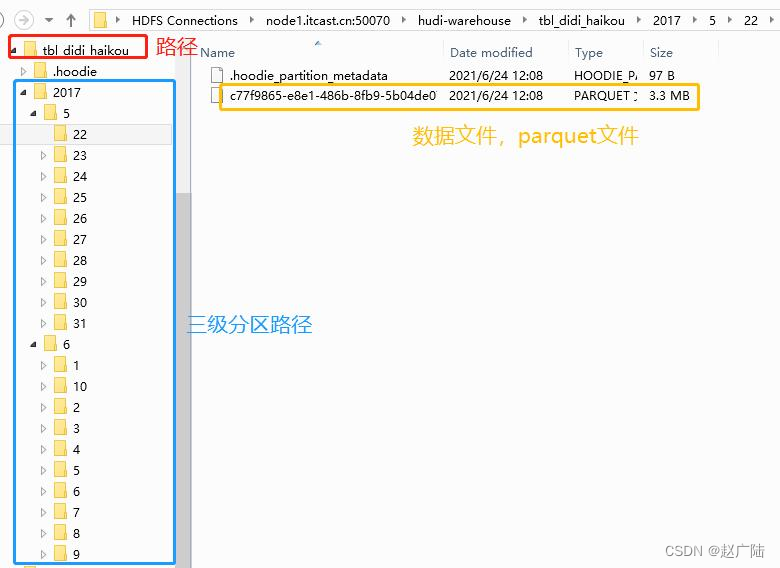
运行Spark程序,读取CSV格式数据,ETL转换后,保存至Hudi表,查看HDFS目录结构如下:
2.4 指标查询分析
按照查询分析指标,从Hudi表加载数据,进行分组聚合统计,分析结果,给出结论。

2.4.1 开发步骤
创建对象DidiAnalysisSpark,编写MAIN方法,先从Hudi表加载数据,再依据指标分组聚合。
package cn.oldlu.hudi.didi
import java.util.{Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用SparkSQL操作数据,从加载Hudi表数据,按照业务需求统计。
* -1. 数据集说明
* 海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。
* 数据存储为CSV格式,首行为列名称
* -2. 开发主要步骤
* step1. 构建SparkSession实例对象(集成Hudi和HDFS)
* step2. 依据指定字段从Hudi表中加载数据
* step3. 按照业务指标进行数据统计分析
* step4. 应用结束关闭资源
*/
object DidiAnalysisSpark {
// Hudi中表的属性
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit = {
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass, partitions = 8)
import spark.implicits._
// step2. 依据指定字段从Hudi表中加载数据
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
// step3. 按照业务指标进行数据统计分析
// 指标1:订单类型统计
// reportProduct(hudiDF)
// 指标2:订单时效统计
// reportType(hudiDF)
// 指标3:交通类型统计
//reportTraffic(hudiDF)
// 指标4:订单价格统计
//reportPrice(hudiDF)
// 指标5:订单距离统计
//reportDistance(hudiDF)
// 指标6:日期类型:星期,进行统计
//reportWeek(hudiDF)
// step4. 应用结束关闭资源
spark.stop()
}
其中将加载Hudi表数据和各个指标统计,分别封装到不同的方法中,便于测试。
2.4.2 加载Hudi表数据
编写方法,封装SparkSQL从Hudi表加载数据,其中过滤获取指标统计时所需字段,代码如下:
/**
* 从Hudi表加载数据,指定数据存在路径
*/
def readFromHudi(spark: SparkSession, path: String): DataFrame = {
// a. 指定路径,加载数据,封装至DataFrame
val didiDF: DataFrame = spark.read.format("hudi").load({path)
// b. 选择字段
didiDF
// 选择字段
.select(
"order_id", "product_id", "type", "traffic_type", //
"pre_total_fee", "start_dest_distance", "departure_time" //
)
}
2.4.3 指标一:订单类型统计
对海口市滴滴出行数据,按照订单类型统计,使用字段:product_id,其中值【1滴滴专车, 2滴滴企业专车, 3滴滴快车, 4滴滴企业快车】,封装方法:reportProduct,代码如下:
/**
* 订单类型统计,字段:product_id
*/
def reportProduct(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("product_id").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 1滴滴专车, 2滴滴企业专车, 3滴滴快车, 4滴滴企业快车
(productId: Int) => {
productId match {
case 1 => "滴滴专车"
case 2 => "滴滴企业专车"
case 3 => "滴滴快车"
case 4 => "滴滴企业快车"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("product_id")).as("order_type"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
将统计结果使用柱状图展示,可以看出快车出行为2017年海口市滴滴运营过程中的主流订单类型。
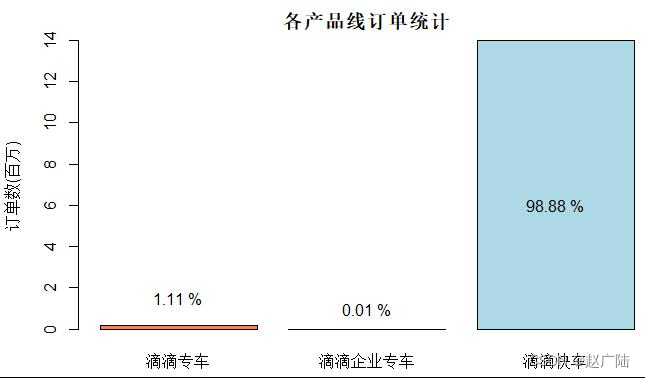
根据统计样本所提供的滴滴订单数据显示,几乎全部的订单都来自于滴滴快车产品线,滴滴专车只占了很小一部分订单量,企业专车产品线的订单量与之相比更是无足轻重。滴滴快车作为滴滴的传统招牌业务,是滴滴公司的支柱。而在14年底就推出的滴滴专车(后于18年改名“礼橙专车”),从17年的数据看来,至少在海口市的使用率不算太高。这也是情有可原的,毕竟滴滴专车的目标受众是更小的高端商务出行人群,旨在为商务出行提供优质服务的产品,其更高的价格与滴滴快车相比,无法成为普罗大众的首选。
2.4.4 指标二:订单时效性统计
依据用户下单的时效型:type,分组聚合统计,代码如下:
/**
* 订单时效性统计,字段:type
*/
def reportType(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 0实时,1预约
(realtimeType: Int) => {
realtimeType match {
case 0 => "实时"
case 1 => "预约"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("type")).as("order_realtime"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
使用柱状图展示结果,可以看出17年海口市滴滴出行订单中,预约用车市占率极低,仍以实时预约为主。
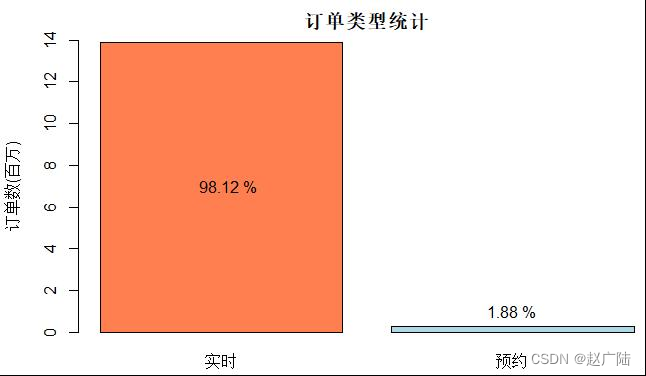
根据统计样本所提供的滴滴订单数据显示,尽管滴滴早已推出预约用车的业务,实时需求依旧是绝大部分用车订单的情景,但这并不意味着预约用车没有存在的价值。对于消费者而言,实时用车具有更高的灵活性,但预约用车提供了预先安排、避免特殊情况下打不到车的选择,让消费者能够将乘车出行融入生活的日程表中。
2.4.5 指标三:订单交通类型统计
对海口市滴滴出行数据,按照交通类型:traffic_type,分组聚合统计,代码如下:
/**
* 交通类型统计,字段:traffic_type
*/
def reportTraffic(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("traffic_type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 1企业时租,2企业接机套餐,3企业送机套餐,4拼车,5接机,6送机,302跨城拼车
(trafficType: Int) => {
trafficType match {
case 0 => "普通散客"
case 1 => "企业时租"
case 2 => "企业接机套餐"
case 3 => "企业送机套餐"
case 4 => "拼车"
case 5 => "接机"
case 6 => "送机"
case 302 => "跨城拼车"
case _ => "未知"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("traffic_type")).as("traffic_type"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
使用柱状图展示结果,可以看出接送机订单仅占总订单量的4%。
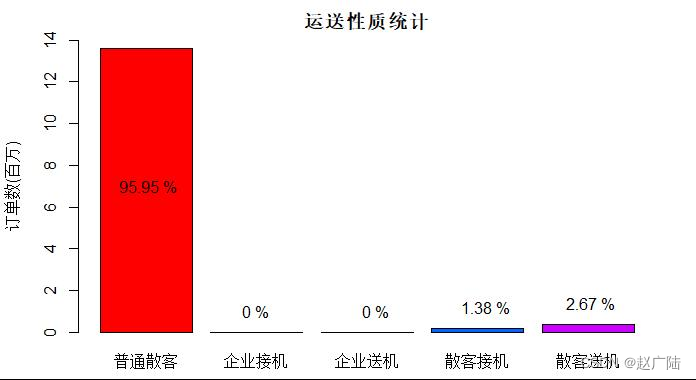
机场运送的衔接是滴滴出行的一个潜力市场,在统计样本记录的订单里,17年5月到11月,海口市散客的接送机订单加起来占了总订单量的4%,约56万订单。但企业接送机业务则没有记录。
2.4.6 指标四:订单价格统计
对滴滴出行订单数据,依据价格划分不同级别,分组聚合统计,代码如下:
/**
* 订单价格统计,将价格分阶段统计,字段:pre_total_fee
*/
def reportPrice(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 价格:0 ~ 15
sum(
when(
col("pre_total_fee").between(0, 15), 1
).otherwise(0)
).as("0~15"),
// 价格:16 ~ 30
sum(
when(
col("pre_total_fee").between(16, 30), 1
).otherwise(0)
).as("16~30"),
// 价格:31 ~ 50
sum(
when(
col("pre_total_fee").between(31, 50), 1
).otherwise(0)
).as("31~50"),
// 价格:50 ~ 100
sum(
when(
col("pre_total_fee").between(51, 100), 1
).otherwise(0)
).as("51~100"),
// 价格:100+
sum(
when(
col("pre_total_fee").gt(100), 1
).otherwise(0)
).as("100+")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
其中使用when条件函数和sum累加函数,巧妙的进行条件判断和累加统计。此外,通过结果可以看出【价格集中在0-50元】。
2.4.7 指标五:订单距离统计
对滴滴出行数据,按照每次订单行程距离,划分不同分段范围,分组聚合统计,代码如下:
/**
* 订单距离统计,将价格分阶段统计,字段:start_dest_distance
*/
def reportDistance(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 价格:0 ~ 15
sum(
when(
col("start_dest_distance").between(0, 10000), 1
).otherwise(0)
).as("0~10km"),
// 价格:16 ~ 30
sum(
when(
col("start_dest_distance").between(10001, 20000), 1
).otherwise(0)
).as("10~20km"),
// 价格:31 ~ 50
sum(
when(
col("start_dest_distance").between(200001, 30000), 1
).otherwise(0)
).as("20~30km"),
// 价格:50 ~ 100
sum(
when(
col("start_dest_distance").between(30001, 5000), 1
).otherwise(0)
).as("30~50km"),
// 价格:100+
sum(
when(
col("start_dest_distance").gt(50000), 1
).otherwise(0)
).as("50+km")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
此指标与指标四类似,使用when条件函数和sum求和函数进行统计。
2.4.8 指标六:订单星期统计
转换日期为星期,分组聚合统计,查看工作日和休息,滴滴出情况,代码如下:
/**
* 订单星期分组统计,字段:departure_time
*/
def reportWeek(dataframe: DataFrame): Unit = {
// a. 自定义UDF函数,转换日期为星期
val to_week: UserDefinedFunction = udf(
// 0实时,1预约
(dateStr: String) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd")
val calendar: Calendar = Calendar.getInstance()
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek: String = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
// 返回星期
dayWeek
}
)
// b. 转换日期为星期,并分组和统计
val resultDF: DataFrame = dataframe
.select(
to_week(col("departure_time")).as("week")
)
.groupBy(col("week")).count()
.select(
col("week"), col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
看出结果,可以看出【工作日期间,海口市居民对出租车的出行需求降低,而在周末时较为旺盛】。
2.5 集成Hive查询
前面将滴滴出行数据存储在Hudi表中,使用SparkSQL读取数据,接下来集成Hive表数据,从Hudi表读取数据。
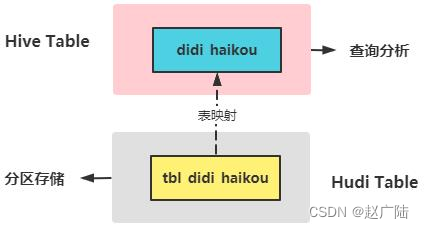
2.5.1 创建表及查询
在Hive中创建表,关联至Hudi表,需要将集成JAR包:hudi-hadoop-mr-bundle-0.9.0.jar,放入至$HIVE_HOME/lib目录下。
[root@node1 ~]# cp hudi-hadoop-mr-bundle-0.9.0.jar /export/server/hive/lib/
拷贝依赖包到 Hive 路径是为了 Hive 能够正常读到 Hudi 的数据,至此服务器环境准备完毕。
前面Spark 将滴滴出行数据写到Hudi表,想要通过Hive访问到这块数据,就需要创建一个Hive外部表,因为 Hudi 配置了分区,所以为了能读到所有的数据,此时外部表也得分区,分区字段名可随意配置
1. 创建数据库
create database db_hudi ;
2. 使用数据库
use db_hudi ;
3. 创建外部表
CREATE EXTERNAL TABLE tbl_hudi_didi(
order_id bigint ,
product_id int ,
city_id int ,
district int ,
county int ,
type int ,
combo_type int ,
traffic_type int ,
passenger_count int ,
driver_product_id int ,
start_dest_distance int ,
arrive_time string ,
departure_time string ,
pre_total_fee double ,
normal_time string ,
bubble_trace_id string ,
product_1level int ,
dest_lng double ,
dest_lat double ,
starting_lng double ,
starting_lat double ,
partitionpath string ,
ts bigint
)
PARTITIONED BY (
`yarn_str` string, `month_str` string, `day_str` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'/ehualu/hudi-warehouse/idea_didi_haikou' ;
5. 添加分区
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='22') location '/hudi-warehouse/tbl_didi_haikou/2017/5/22' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='23') location '/hudi-warehouse/tbl_didi_haikou/2017/5/23' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='24') location '/hudi-warehouse/tbl_didi_haikou/2017/5/24' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='25') location '/hudi-warehouse/tbl_didi_haikou/2017/5/25' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='26') location '/hudi-warehouse/tbl_didi_haikou/2017/5/26' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='27') location '/hudi-warehouse/tbl_didi_haikou/2017/5/27' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='28') location '/hudi-warehouse/tbl_didi_haikou/2017/5/28' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='29') location '/hudi-warehouse/tbl_didi_haikou/2017/5/29' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='30') location '/hudi-warehouse/tbl_didi_haikou/2017/5/30' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='31') location '/hudi-warehouse/tbl_didi_haikou/2017/5/31' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='1') location '/hudi-warehouse/tbl_didi_haikou/2017/6/1' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='2') location '/hudi-warehouse/tbl_didi_haikou/2017/6/2' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='3') location '/hudi-warehouse/tbl_didi_haikou/2017/6/3' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='4') location '/hudi-warehouse/tbl_didi_haikou/2017/6/4' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='5') location '/hudi-warehouse/tbl_didi_haikou/2017/6/5' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='6') location '/hudi-warehouse/tbl_didi_haikou/2017/6/6' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='7') location '/hudi-warehouse/tbl_didi_haikou/2017/6/7' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='8') location '/hudi-warehouse/tbl_didi_haikou/2017/6/8' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='9') location '/hudi-warehouse/tbl_didi_haikou/2017/6/9' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='10') location '/hudi-warehouse/tbl_didi_haikou/2017/6/10' ;
查看分区信息
show partitions tbl_hudi_didi ;
上述命令执行完成以后,Hive表数据与Hudi表数据关联成功,可以在Hive中编写SQL语句分析Hudi数据,SELECT语句查询表的数据。
设置非严格模式
set hive.mapred.mode = nonstrict ;
SQL查询前10条数据
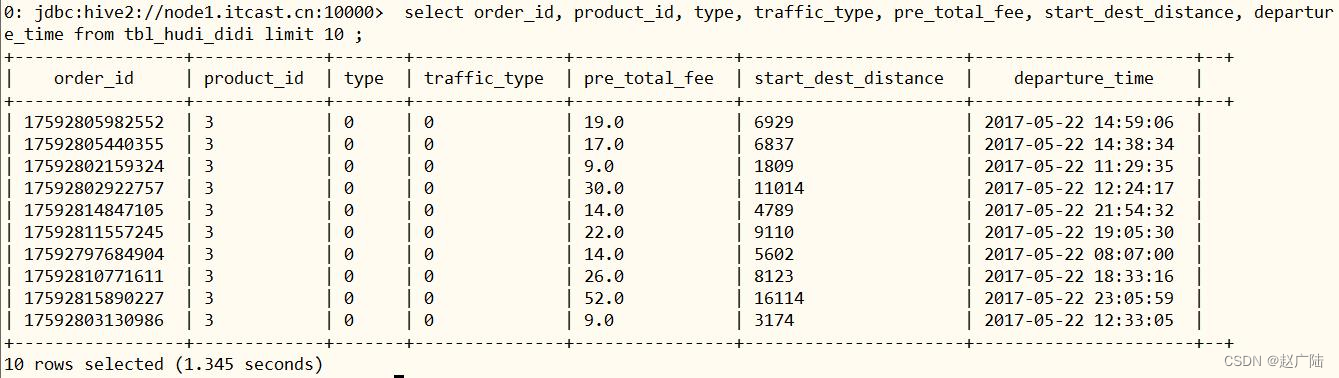
select order_id, product_id, type, traffic_type, pre_total_fee, start_dest_distance, departure_time
from db_hudi.tbl_hudi_didi limit 10 ;
显示结果如下所示:
2.5.2 HiveQL 分析
在Hive框架beeline命令行中编写HiveQL语句,对前面5.4节指标统计分析。
设置Hive本地模式
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.tasks.max=10;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
12345
■指标一:订单类型统计
WITH tmp AS (
SELECT product_id, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY product_id
)
SELECT
CASE product_id
WHEN 1 THEN "滴滴专车"
WHEN 2 THEN "滴滴企业专车"
WHEN 3 THEN "滴滴快车"
WHEN 4 THEN "滴滴企业快车"
END AS order_type,
total
FROM tmp ;
分析结果(仅仅导入小部分滴滴出行数据至Hudi表),如下图所示:
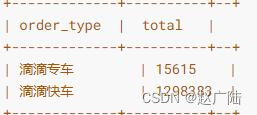
■指标二:订单时效性统计
WITH tmp AS (
SELECT type AS order_realtime, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY type
)
SELECT
CASE order_realtime
WHEN 0 THEN "实时"
WHEN 1 THEN "预约"
END AS order_realtime,
total
FROM tmp ;
分析结果(仅仅导入小部分滴滴出行数据至Hudi表),如下图所示:
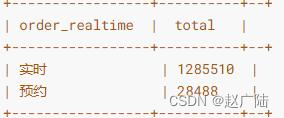
■指标三:订单交通类型统计
WITH tmp AS (
SELECT traffic_type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY traffic_type
)
SELECT
CASE traffic_type
WHEN 0 THEN "普通散客"
WHEN 1 THEN "企业时租"
WHEN 2 THEN "企业接机套餐"
WHEN 3 THEN "企业送机套餐"
WHEN 4 THEN "拼车"
WHEN 5 THEN "接机"
WHEN 6 THEN "送机"
WHEN 302 THEN "跨城拼车"
ELSE "未知"
END AS traffic_type,
total
FROM tmp ;
分析结果(仅仅导入小部分滴滴出行数据至Hudi表),如下图所示:
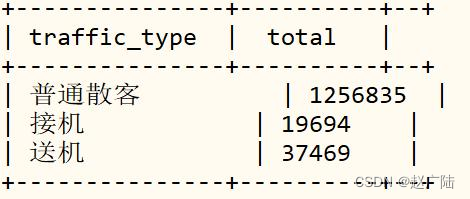
■指标四:订单价格统计
SELECT
SUM(
CASE WHEN pre_total_fee BETWEEN 1 AND 15 THEN 1 ELSE 0 END
) AS 0_15,
SUM(
CASE WHEN pre_total_fee BETWEEN 16 AND 30 THEN 1 ELSE 0 END
) AS 16_30,
SUM(
CASE WHEN pre_total_fee BETWEEN 31 AND 50 THEN 1 ELSE 0 END
) AS 31_150,
SUM(
CASE WHEN pre_total_fee BETWEEN 51 AND 100 THEN 1 ELSE 0 END
) AS 51_100,
SUM(
CASE WHEN pre_total_fee > 100 THEN 1 ELSE 0 END
) AS 100_
FROM
db_hudi.tbl_hudi_didi;
分析结果(仅仅导入小部分滴滴出行数据至Hudi表),如下图所示:

3 结构化流写入Hudi
整合Spark StructuredStreaming与Hudi,实时将流式数据写入Hudi表中,对每批次数据batch DataFrame,采用Spark DataSource方式写入数据。
属性参数说明:https://hudi.apache.org/docs/writing_data#datasource-writer
3.1 模拟交易订单
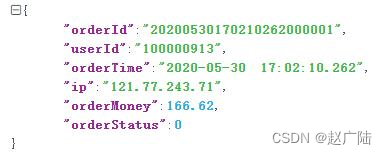
编程模拟生成交易订单数据,实时发送Kafka Topic,为了简单起见交易订单数据字段如下,封装到样例类OrderRecord中:
/**
* 订单实体类(Case Class)
*
* @param orderId 订单ID
* @param userId 用户ID
* @param orderTime 订单日期时间
* @param ip 下单IP地址
* @param orderMoney 订单金额
* @param orderStatus 订单状态
*/
case class OrderRecord(
orderId: String,
userId: String,
orderTime: String,
ip: String,
orderMoney: Double,
orderStatus: Int
)
编写程序【MockOrderProducer】,实时产生交易订单数据,使用Json4J类库转换数据为JSON字符,发送Kafka Topic中,代码如下:
import java.util.Properties
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
/**
* 模拟生产订单数据,发送到Kafka Topic中
* Topic中每条数据Message类型为String,以JSON格式数据发送
* 数据转换:
* 将Order类实例对象转换为JSON格式字符串数据(可以使用json4s类库)
*/
object MockOrderProducer {
def main(args: Array[String]): Unit = {
var producer: KafkaProducer[String, String] = null
try {
// 1. Kafka Client Producer 配置信息
val props = new Properties()
props.put("bootstrap.servers", "node1.oldlu.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 2. 创建KafkaProducer对象,传入配置信息
producer = new KafkaProducer[String, String](props)
// 随机数实例对象
val random: Random = new Random()
// 订单状态:订单打开 0,订单取消 1,订单关闭 2,订单完成 3
val allStatus = Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
while (true) {
// 每次循环 模拟产生的订单数目
val batchNumber: Int = random.nextInt(1) + 5
(1 to batchNumber).foreach { number =>
val currentTime: Long = System.currentTimeMillis()
val orderId: String = s"${getDate(currentTime)}%06d".format(number)
val userId: String = s"${1 + random.nextInt(5)}%08d".format(random.nextInt(1000))
val orderTime: String = getDate(currentTime, format = "yyyy-MM-dd HH:mm:ss.SSS")
val orderMoney: String = s"${5 + random.nextInt(500)}.%02d".format(random.nextInt(100))
val orderStatus: Int = allStatus(random.nextInt(allStatus.length))
// 3. 订单记录数据
val orderRecord: OrderRecord = OrderRecord(
orderId, userId, orderTime, getRandomIp, orderMoney.toDouble, orderStatus
)
// 转换为JSON格式数据
val orderJson = new Json(org.json4s.DefaultFormats).write(orderRecord)
println(orderJson)
// 4. 构建ProducerRecord对象
val record = new ProducerRecord[String, String]("order-topic", orderId, orderJson)
// 5. 发送数据:def send(messages: KeyedMessage[K,V]*), 将数据发送到Topic
producer.send(record)
}
Thread.sleep(random.nextInt(500))
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != producer) producer.close()
}
}
/** =================获取当前时间================= */
def getDate(time: Long, format: String = "yyyyMMddHHmmssSSS"): String = {
val fastFormat: FastDateFormat = FastDateFormat.getInstance(format)
val formatDate: String = fastFormat.format(time) // 格式化日期
formatDate
}
/** ================= 获取随机IP地址 ================= */
def getRandomIp: String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/** =================将Int类型IPv4地址转换为字符串类型================= */
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
运行应用程序,模拟生成交易订单数据,格式化后:
3.2 流式程序开发
编写Structured Streaming Application应用:HudiStructuredDemo,实时从Kafka的【order-topic】消费JSON格式数据,经过ETL转换后,存储到Hudi表中。
package cn.oldlu.hudi.streaming
import org.apache.spark.internal.Logging
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
/**
* 基于StructuredStreaming结构化流实时从Kafka消费数据,经过ETL转换后,存储至Hudi表
*/
object HudiStructuredDemo extends Logging{
def main(args: Array[String]): Unit = {
// step1、构建SparkSession实例对象
val spark: SparkSession = createSparkSession(this.getClass)
// step2、从Kafka实时消费数据
val kafkaStreamDF: DataFrame = readFromKafka(spark, "order-topic")
// step3、提取数据,转换数据类型
val streamDF: DataFrame = process(kafkaStreamDF)
// step4、保存数据至Hudi表中:COW(写入时拷贝)和MOR(读取时保存)
saveToHudi(streamDF)
// step5、流式应用启动以后,等待终止
spark.streams.active.foreach(query => println(s"Query: ${query.name} is Running ............."))
spark.streams.awaitAnyTermination()
}
/**
* 创建SparkSession会话实例对象,基本属性设置
*/
def createSparkSession(clazz: Class[_]): SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 设置属性:Shuffle时分区数和并行度
.config("spark.default.parallelism", 2)
.config("spark.sql.shuffle.partitions", 2)
.getOrCreate()
}
/**
* 指定Kafka Topic名称,实时消费数据
*/
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.oldlu.cn:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
/**
* 对Kafka获取数据,进行转换操作,获取所有字段的值,转换为String,以便保存Hudi表
*/
def process(streamDF: DataFrame): DataFrame = {
/* 从Kafka消费数据后,字段信息如
key -> binary,value -> binary
topic -> string, partition -> int, offset -> long
timestamp -> long, timestampType -> int
*/
streamDF
// 选择字段,转换类型为String
.selectExpr(
"CAST(key AS STRING) order_id", //
"CAST(value AS STRING) message", //
"topic", "partition", "offset", "timestamp"//
)
// 解析Message,提取字段内置
.withColumn("user_id", get_json_object(col("message"), "$.userId"))
.withColumn("order_time", get_json_object(col("message"), "$.orderTime"))
.withColumn("ip", get_json_object(col("message"), "$.ip"))
.withColumn("order_money", get_json_object(col("message"), "$.orderMoney"))
.withColumn("order_status", get_json_object(col("message"), "$.orderStatus"))
// 删除Message列
.drop(col("message"))
// 转换订单日期时间格式为Long类型,作为Hudi表中合并数据字段
.withColumn("ts", to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss.SSSS"))
// 订单日期时间提取分区日期:yyyyMMdd
.withColumn("day", substring(col("order_time"), 0, 10))
}
/**
* 将流式数据集DataFrame保存至Hudi表,分别表类型:COW和MOR
*/
def saveToHudi(streamDF: DataFrame): Unit = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-streaming")
// 针对每微批次数据保存
.foreachBatch((batchDF: Dataset[Row], batchId: Long) => {
println(s"============== BatchId: ${batchId} start ==============")
writeHudiMor(batchDF) // TODO:表的类型MOR
})
.option("checkpointLocation", "/datas/hudi-spark/struct-ckpt-100")
.start()
}
/**
* 将数据集DataFrame保存到Hudi表中,表的类型:MOR(读取时合并)
*/
def writeHudiMor(dataframe: DataFrame): Unit = {
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
dataframe.write
.format("hudi")
.mode(SaveMode.Append)
// 表的名称
.option(TBL_NAME.key, "tbl_kafka_mor")
// 设置表的类型
.option(TABLE_TYPE.key(), "MERGE_ON_READ")
// 每条数据主键字段名称
.option(RECORDKEY_FIELD_NAME.key(), "order_id")
// 数据合并时,依据时间字段
.option(PRECOMBINE_FIELD_NAME.key(), "ts")
// 分区字段名称
.option(PARTITIONPATH_FIELD_NAME.key(), "day")
// 分区值对应目录格式,是否与Hive分区策略一致
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
// 插入数据,产生shuffle时,分区数目
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 表数据存储路径
.save("/hudi-warehouse/tbl_order_mor")
}
}
上述代码中有两个细节,对于流式应用来说很关键:
■ 第一、从Kafka消费数据时,通过属性【maxOffsetsPerTrigger】,设置每批次最大数据量,实际生产项目需要结合流式数据波峰及应用运行资源综合考虑设置;
■ 第二、将ETL后数据保存至Hudi中,设置检查点位置Checkpoint Location,便于流式应用运行失败后,可以从Checkpoint恢复,继续上次消费数据,进行实时处理;
运行上述程序,查看HDFS上Hudi表存储交易订单数据存储目录结构:
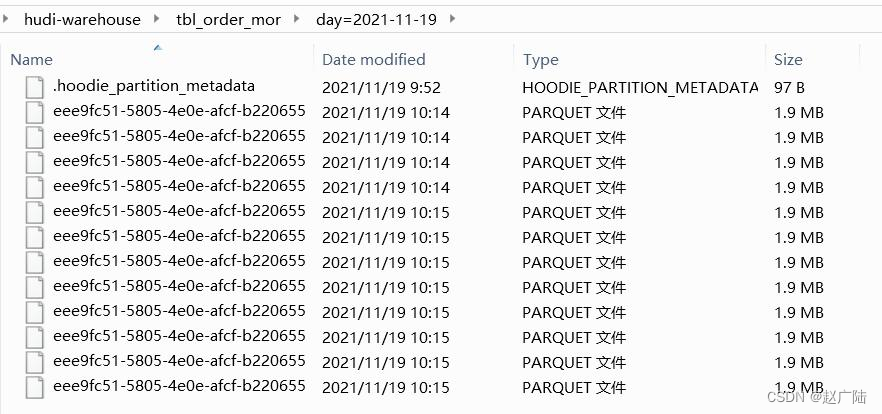
3.3 Spark 查询分析
启动spark-shell命令行,查询Hudi表存储交易订单数据,命令如下:
/export/server/spark/bin/spark-shell --master local[2] --jars /root/hudi-jars/org.apache.hudi_hudi-spark3-bundle_2.12-0.9.0.jar,/root/hudi-jars/org.apache.spark_spark-avro_2.12-3.0.1.jar,/root/hudi-jars/org.spark-project.spark_unused-1.0.0.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
指定Hudi表数据存储目录,加载数据:
val orderDF = spark.read.format("hudi").load("/ehualu/hudi-warehouse/tbl_order_mor")
查看Schema信息
orderDF.printSchema()

查看订单表前10条数据,选择订单相关字段:
orderDF.select("order_id", "user_id", "order_time", "ip", "order_money", "order_status", "day").show(false)

查看数据总条目数:
orderDF.count()
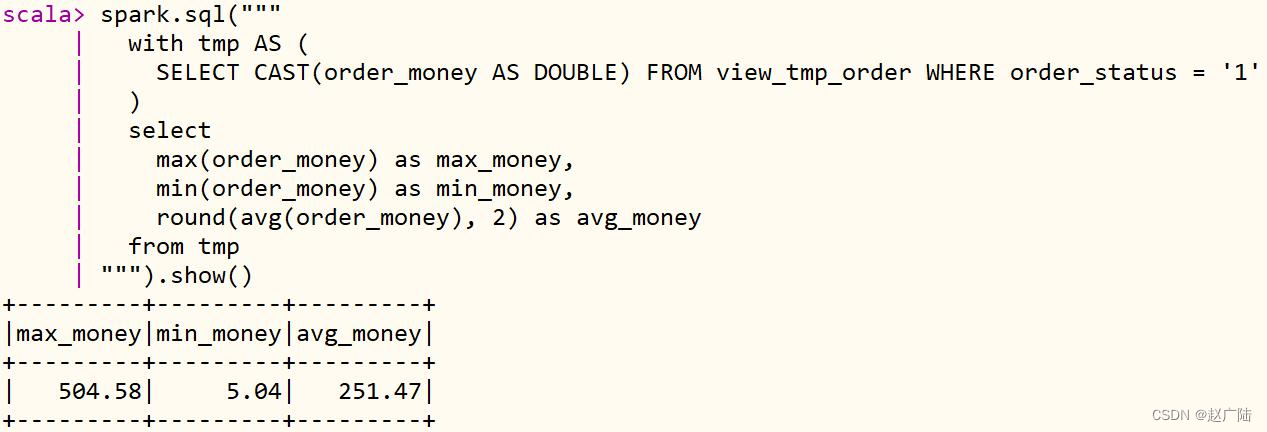
交易订单数据基本聚合统计:最大金额max、最小金额min、平均金额avg
spark.sql("""
with tmp AS (
SELECT CAST(order_money AS DOUBLE) FROM view_tmp_order WHERE order_status = '0'
)
select
max(order_money) as max_money,
min(order_money) as min_money,
round(avg(order_money), 2) as avg_money
from tmp
""").show()
3.4 DeltaStreamer 工具类
HoodieDeltaStreamer工具 (hudi-utilities-bundle中的一部分) 提供了从DFS或Kafka等不同来源进行摄取的方式,并具有以下功能:
■从Kafka单次摄取新事件
■支持json、avro或自定义记录类型的传入数据
■管理检查点,回滚和恢复
■利用DFS或Confluent schema注册表的Avro模式
■支持自定义转换操作
工具类:HoodieDeltaStreamer,本质上运行Spark 流式程序,实时从获取数据,存储奥Hudi表中,执行如下命令,查看帮助文档:
spark-submit --master local[2] \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/root/hudi-utilities-bundle_2.11-0.9.0.jar \
--help
注意:工具类所在jar包【hudi-utilities-bundle_2.11-0.9.0.jar】,将其添加CLASSPATH。
官方提供案例:实时消费Kafka中数据,数据格式为Avro,将其存储到Hudi表。
4 集成 SparkSQL
在Hudi最新版本0.9.0支持与SparkSQL集成,直接在spark-sql交互式命令行编写SQL语句,极大方便用户对Hudi表的DDL/DML操作。文档:https://hudi.apache.org/docs/quick-start-guide
4.1 启动spark-sql
Hudi表数据存储在HDFS文件系统,先启动NameNode和DataNode服务。
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
启动spark-sql交互式命令行,设置依赖jar包和相关属性参数。
/export/server/spark/bin/spark-sql --master local[2] --jars /root/hudi-jars/org.apache.hudi_hudi-spark3-bundle_2.12-0.9.0.jar,/root/hudi-jars/org.apache.spark_spark-avro_2.12-3.0.1.jar,/root/hudi-jars/org.spark-project.spark_unused-1.0.0.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Hudi默认upsert/insert/delete的并发度是1500,对于演示小规模数据集设置更小的并发度。
set hoodie.upsert.shuffle.parallelism = 1;
set hoodie.insert.shuffle.parallelism = 1;
set hoodie.delete.shuffle.parallelism = 1;
设置不同步Hudi表元数据:
set hoodie.datasource.meta.sync.enable=false;
4.2 快速入门
使用DDL和DML语句,创建表、删除表和对数据CURD操作。
4.2.1 创建表
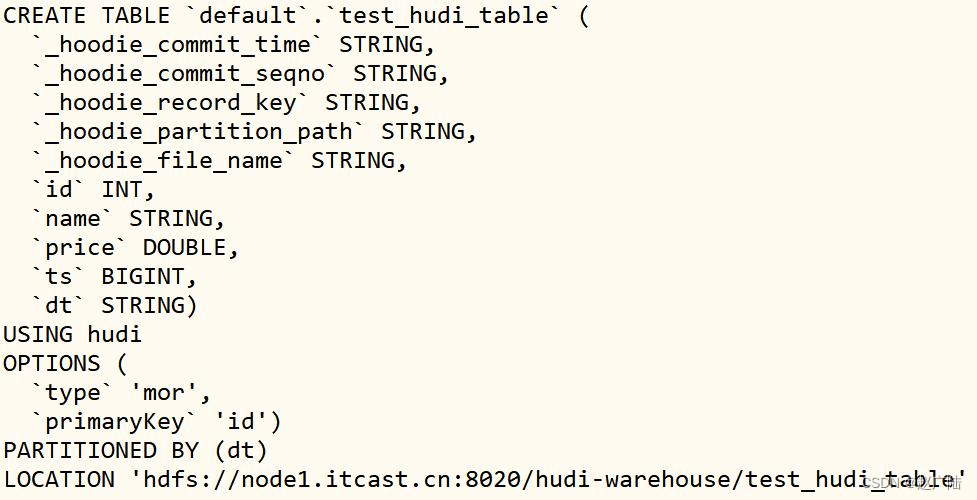
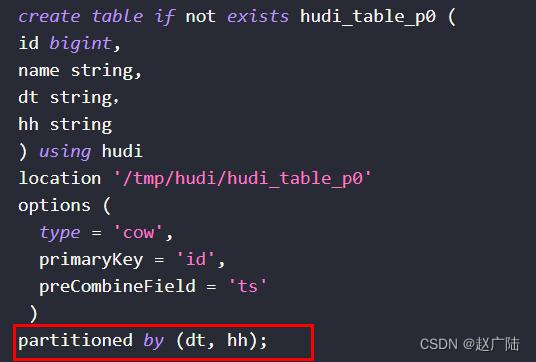
编写DDL语句,创建Hudi表,表的类型:MOR和分区表,主键为id,分区字段为dt,合并字段默认为ts。
create table test_hudi_table (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
type = 'mor'
)
location 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/test_hudi_table' ;
创建Hudi表后查看创建的Hudi表
show create table test_hudi_table
4.2.2 插入数据
使用INSERT INTO 插入数据到Hudi表中:
insert into test_hudi_table select 1 as id, 'hudi' as name, 10 as price, 1000 as ts, '2021-11-01' as dt;
insert完成后查看Hudi表本地目录结构,生成的元数据、分区和数据与Spark Datasource写入均相同。

使用ISNERT INTO语句,多插入几条数据,命令如下:
insert into test_hudi_table select 2 as id, 'spark' as name, 20 as price, 1100 as ts, '2021-11-01' as dt;
insert into test_hudi_table select 3 as id, 'flink' as name, 30 as price, 1200 as ts, '2021-11-01' as dt;
insert into test_hudi_table select 4 as id, 'sql' as name, 40 as price, 1400 as ts, '2021-11-01' as dt;
4.2.3 查询数据
使用SQL查询Hudi表数据,全表扫描查询:
select * from test_hudi_table ;

查看表中字段结构,使用DESC语句:
desc test_hudi_table ;
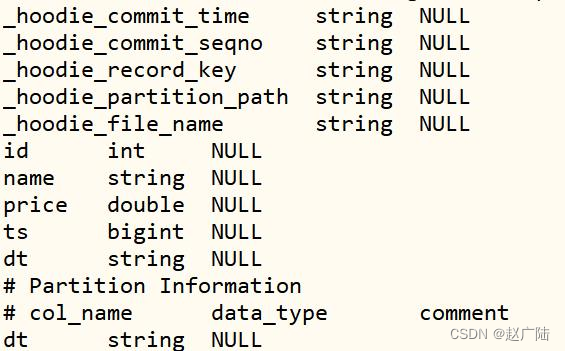
指定查询字段,查询表中前几天数据:
SELECT _hoodie_commit_time,_hoodie_record_key,_hoodie_partition_path, id, name, price, ts, dt FROM test_hudi_table ;

4.2.4 更新数据
使用update语句,更新id=1数据中price为100,语句如下:
update test_hudi_table set price = 100.0 where id = 1 ;
再次查询Hudi表数据,查看数据是否更新:
SELECT id, name, price, ts, dt FROM test_hudi_table WHERE id = 1;
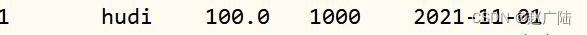
4.2.5 删除数据
使用DELETE语句,将id=1的记录删除,命令如下:
delete from test_hudi_table where id = 1 ;
再次查询Hudi表数据,查看数据是否更新:
SELECT COUNT(1) AS total from test_hudi_table WHERE id = 1;
查询结果如下,可以看到已经查询不到任何数据了,表明Hudi表中已经不存在任何记录了。

4.3 DDL 创建表
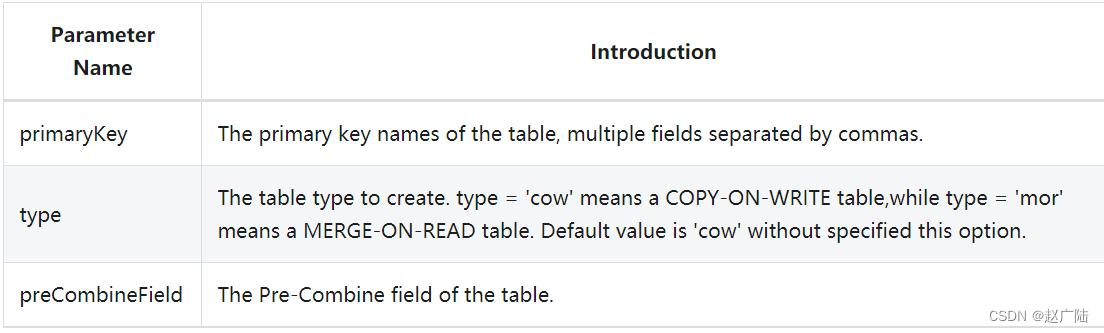
在spark-sql中编写DDL语句,创建Hudi表数据,核心三个属性参数:
■指定Hudi表的类型:

官方案例:创建COW类型Hudi表。

■管理表与外部表:创建表时,指定location存储路径,表就是外部表

■创建表时设置为分区表:partitioned table
■支持使用CTAS:Create table as select方式创建表
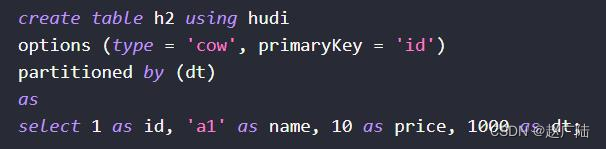
在实际应用使用时,合理选择创建表的方式,建议创建外部及分区表,便于数据管理和安全。
4.4 MergeInto 语句
在Hudi中提供MergeInto语句,依据判断条件,决定对数据操作时,属于插入insert、更新update,还是删除delete,语法如下:
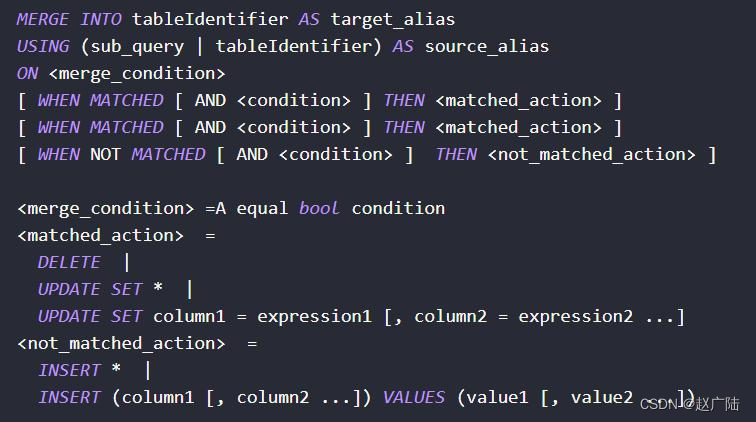
4.4.1 Merge Into Insert
当不满足条件时(关联条件不匹配),插入数据到Hudi表中
merge into test_hudi_table as t0
using (
select 1 as id, 'hadoop' as name, 1 as price, 9000 as ts, '2021-11-02' as dt
) as s0
on t0.id = s0.id
when not matched then insert * ;
查询Hudi表数据,可以看到Hudi表中存在一条记录
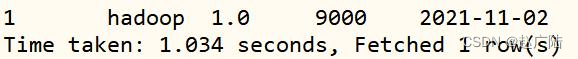
4.4.2 Merge Into Update
当满足条件时(关联条件匹配),对数据进行更新操作:
merge into test_hudi_table as t0
using (
select 1 as id, 'hadoop3' as name, 1000 as price, 9999 as ts, '2021-11-02' as dt
) as s0
on t0.id = s0.id
when matched then update set *
查询Hudi表,可以看到Hudi表中的分区已经更新

4.4.3 Merge Into Delete
当满足条件时(关联条件匹配),对数据进行删除操作:
merge into test_hudi_table t0
using (
select 1 as s_id, 'hadoop3' as s_name, 8888 as s_price, 9999 as s_ts, '2021-11-02' as dt
) s0
on t0.id = s0.s_id
when matched and s_ts = 9999 then delete







![[JAVA数据结构]顺序表ArrayList](https://img-blog.csdnimg.cn/44b30e2321404e33a35cb50d391367e3.png)
![[NLP]如何训练自己的大型语言模型](https://img-blog.csdnimg.cn/08de86f9cf984997b4916afbb692747c.png)