文章目录
- 1、set
- multiset
- 2、map
- 3、map::operator[]
1、set
vector/list/deque等是序列式容器,map,set是关联式容器。序列式容器的特点就是数据线性存放,而关联式容器的数据并不是线性,数据之间有很强的关系。
它们的底层是平衡搜索二叉树。set解决key模型问题,map解决key/value模型问题。
set和之前的结构有很多相似之处,所以这里就不需要写那么多了。
set对于插入的数值会自动排序,并且重复的值只存入一个。
set<int> s1;
s1.insert(1);
s1.insert(1);
s1.insert(4);
s1.insert(7);
s1.insert(3);
s1.insert(5);
s1.insert(10);
set<int>::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;

set也有迭代器和范围for,但不支持在这两个里面修改数据,因为搜索树不允许修改,也就是key值不能修改,可能会破坏搜索的规则。
erase借助位置来删除,获取位置用find,find迭代器也不允许修改,因为set的普通迭代器也是const的。
swap函数用来交换;count函数用来查看一个值在不在。
void test_set2()
{
set<int> s1;
s1.insert(1);
s1.insert(1);
s1.insert(4);
s1.insert(7);
s1.insert(3);
s1.insert(5);
s1.insert(10);
int x;
while (cin >> x)
{
/*auto ret = s1.find(x);
if (ret != s1.end())
cout << "在" << endl;
else
cout << "不在" << endl;*/
if (s1.count(x))
{
cout << s1.count(x) << "";
cout << "在" << endl;
}
else
{
cout << "不在" << endl;
}
}
}
count找到后会返回有几个。
multiset
set中除了set,还有multiset。它允许多个键值,允许键值冗余,它的操作只有一个和set不同。
multiset<int> s1;
s1.insert(1);
s1.insert(1);
s1.insert(4);
s1.insert(7);
s1.insert(3);
s1.insert(5);
s1.insert(10);
multiset<int>::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
它只是排序,不去重。所以会有两个1出现。

如果find(1),会返回中序排序中出现的第一个1.所以即使找到了一个14,它也会往左子树继续找,知道找到最左的那一个,没有那就返回根处的位置。
auto ret = s1.find(1);
while (ret != s1.end() && *ret == 1)
{
cout << *ret << " ";
++ret;
}
cout << endl;
cout << s1.count(1) << endl;

2、map
map需要存入key,需要存入value,不过他数据的类型是库中定义的pair。
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;//一般情况下Key
T2 second;//一般情况下Value
pair() : first(T1()), second(T2())
{}
pair(const T1& a, const T2& b) : first(a), second(b)
{}
};
map的key是不允许修改的,value可以修改。
map<string, string> dict;
dict.insert(pair<string, string>("sort", "排序"));
dict.insert(pair<string, string>("string", "字符串"));
dict.insert(pair<string, string>("count", "计数"));
//map<string, string>::iterator dit = dict.begin();
auto dit = dict.begin();
while (dit != dict.end())
{
cout << (*dit).first << " : " << (*dit).second << endl;
++dit;
}

插入数据时也可以用一个库里的函数模板make_pair
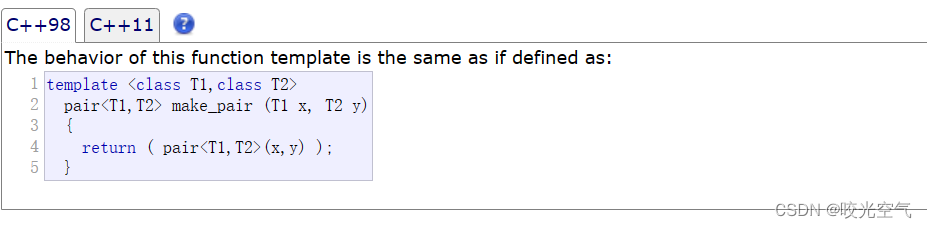
它会自动推导参数类型,所以也不需要传string。
迭代器那里也可以这样写
cout << dit->first << " : " << dit->second << endl;
如果像这样出现重复的
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("count", "计数"));
dict.insert(make_pair("string", "字-符-串"));
会出现插入失败。因为string这个key已经有了,所以它就不插入。
3、map::operator[]
看一个统计水果次数的问题
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉", "梨" };
map<string, int> countMap;
for (auto& e : arr)
{
auto ret = countMap.find(e);
if (ret == countMap.end())
{
countMap.insert(make_pair(e, 1));
}
else
{
ret->second++;
}
}
for (auto& kv : countMap)
{
cout << kv.first << " : " << kv.second << endl;
}
这个是个很常规的写法,进阶写法用方括号[]。这个东西在vector和deque有,map有它自己的用法。
for (auto& e : arr)
{
countMap[e]++;
/*auto ret = countMap.find(e);
if (ret == countMap.end())
{
countMap.insert(make_pair(e, 1));
}
else
{
ret->second++;
}*/
}
只用一行代码。
[]在库中的定义简化一下代码,应当是这样的:
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
K就是key, V就是value。比如从arr的第一个元素西瓜开始,插入后,插入成功,得到true,如果本身没有这个key,那么value生成的就是0,ret.first就是访问到了迭代器,新插入的key的迭代器,然后访问second,也就是次数,外头++,次数也就+1了。再次插入西瓜,插入失败,因为已经有了,所以是false,它就返回西瓜这个key的second。
它有四个功能,插入,修改,插入+修改,查找(查找value)。修改靠的是返回value的引用。它可以节点指针构造迭代器。insert插入的时候会遍历整个树,找到空才插入。
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("count", "计数"));
dict.insert(make_pair("string", "字-符-串"));//不能有效修改
dict["left"];//插入
dict["right"] = "右边";//插入+修改
dict["string"] = "字-符-串";//修改
cout << dict["string"] << endl;//茶找
cout << dict["s"] << endl;
//map<string, string>::iterator dit = dict.begin();
auto dit = dict.begin();
while (dit != dict.end())
{
//cout << (*dit).first << " : " << (*dit).second << endl;
cout << dit->first << " : " << dit->second << endl;
++dit;
}

left的value就是string默认构造的一个空串。
结束。
![P1038 [NOIP2003 提高组] 神经网络](https://img-blog.csdnimg.cn/img_convert/045bbba51ab9d289043296ef39f5ff17.png)