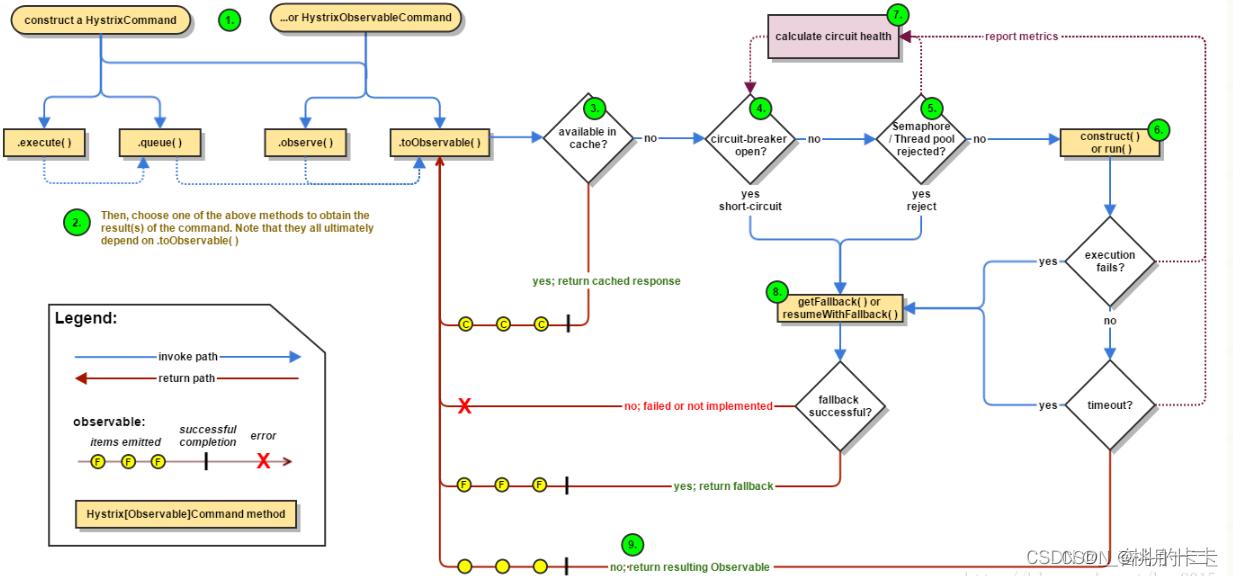
基于人类反馈的强化学习在LLM领域是如何运作的?
- 为什么需要强化学习
- RLHF
- Pre-training model
- Reward Model
- Fine-tune with RL
- 参考
为什么需要强化学习
指标无法衡量。在过去的nlp任务中,词性标注、机器翻译、语义判别等任务是nlp任务的主力军,然而这些任务基于规则的评估指标(如 BLEU 和 ROUGE)不能与在问答系统中人类想要的结果做对齐。
顺序决策是必要的。我们在寻求一个答案或者一个决策的时候,枉枉不可能一蹴而就,需要一步一步来(把大象装进冰箱需要几步),与CoT的观点不谋合。
但是当我们与聊天机器人去一步步互动(agent与环境)的时候,我们不知道什么样的答案是最好的,但是可以用一些学习的策略,去验证它是好是坏,比如说agent与环境交互(我们像chatgpt提问),agent反馈了一个action(next token 或者 下一组tokens),然后通过奖励模型(也可以是LLM),得到一个好坏的评分,强化学习的目标就是最大化这个奖励。
其实上述步骤也可以用SFT的步骤代替,但是有一些局限性,以监督学习的方式去微调大模型,本质上就是让大模型去学习标注者标注的内容的风格,这是缺乏多样性、创造性的。而且与视觉标注信息不同,不是单单的‘画个框’那么简单,更像是给labeler做一个阅读理解类型的问题,也大大增加了标注的成本。
RLHF
rlhf是一项具有挑战性的工作,因为它涉及了多个模型的训练过程。
Pre-training model
这个阶段与InstructGPT的SFT阶段对应,OpenAI 在使用了较小版本的 GPT-3,Anthropic 使用了 10M到52B参数的Transformer进行训练,DeepMind是用来280B参数模型Gopher。
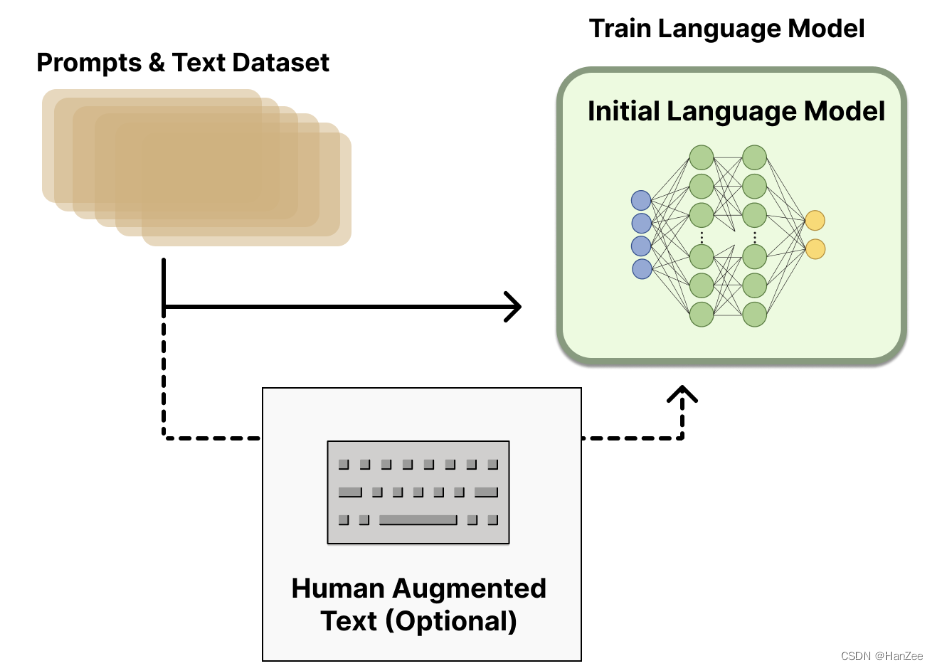
具体细节参照:InstrcutGPT
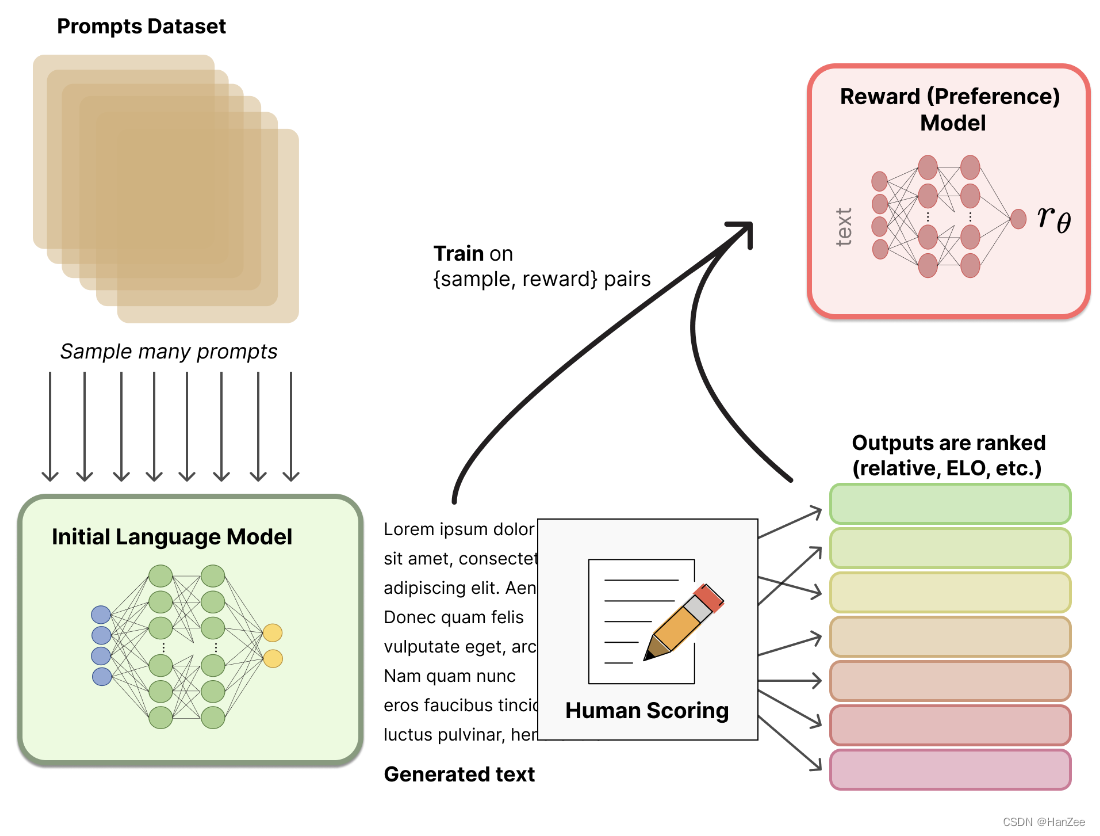
Reward Model
奖励模型的输入是agent的action(chatgpt回答的内容),然后返回一个标量,这个标量的数值代表人的偏好程度。这个奖励模型可以是端到端的语言模型,也可以是模块化的系统。关于选择什么结构的奖励模型、通过什么数据微调,至今没有一个最好的选择。
在InstructGPT中,作者采用了一个小型的GPT3,在模型的最后一层接上一个linear层,输出维度为一。
在训练RM的时候,它的训练数据作者起初是让labeler直接为数据标注标注得分,但是由于labeler的价值观各不相同,导致数据噪声较大。
于是作者后来让labeler标注文本的排名,文本可能来自于相同prompt不同模型的输出,或者来自相同prompt相同模型通过beam search的方法得到不同的输出,然后把排名通过EIO机制转换成标量分数,归一化后,得到训练数据。
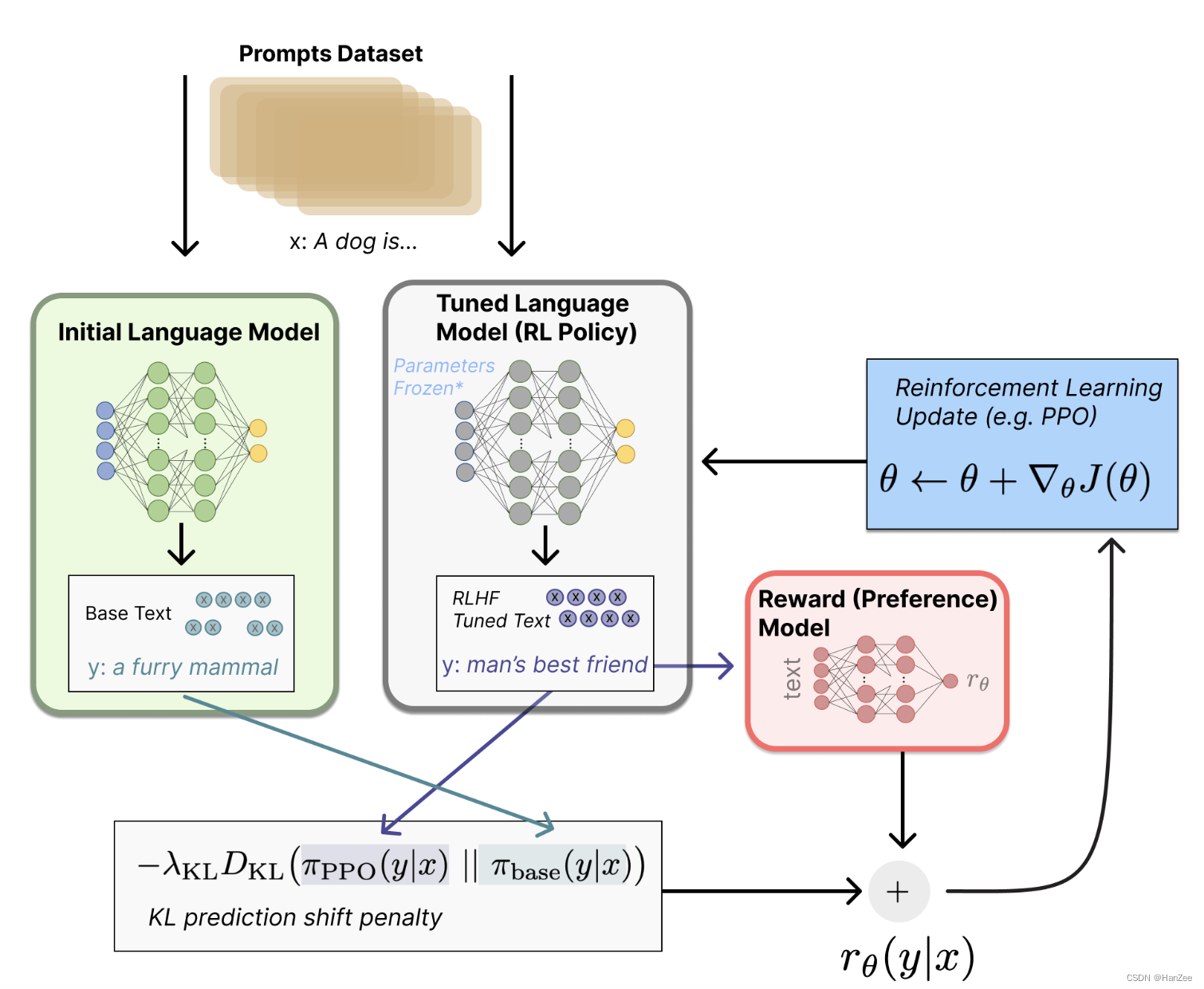
Fine-tune with RL
把一个微调问题转换成一个强化学习问题,首先定义策略(也叫智能体),它其实就是一个大语言模型,输入prompt,输出一系列文本,或者文本的概率分布。行动空间vocabulary txt,观察空间是input sequence,奖励模型就是之前训练的偏好模型,用来约束策略参数优化。
奖励模型把之前所有的概念都联系在了一起,给定一个prompt、x,生成两个text:y1、y2,一个来自SFT后的模型,一个来自于当前策略的输出。把当前策略输出的模型输入奖励模型,得到一个标量偏好分数
r
θ
r_\theta
rθ。然后比较这两个text y1、y2的差距,也是比较y1的概率分布与y2概率分布,计算惩罚,这个惩罚在OpenAI、Anthropic和DeepMind的文献中,这种惩罚被设计为两者规范化后的KL散度
r
K
L
r_{KL}
rKL。这个KL散度用来惩罚当前策略在每个batch中与原始模型的偏离程度,以确保输出不改变太多。如果没有这个限制,模型会生成一些胡乱写的文本,但是也可以欺骗奖励函数去得到一个不错的分数。最终奖励模型被定义为:

一些RLHF系统在奖励功能中添加了额外的条款。例如,OpenAI通过将额外的预训练梯度(来自人类注释集)混合到PPO的更新规则中,成功地在InstructGPT上进行了实验。随着RLHF的进一步研究,这个奖励函数的公式可能会继续演变。
参考
https://huggingface.co/blog/zh/rlhf
https://blog.replit.com/llm-training