题目背景
人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。对神经网络的研究一直是当今的热门方向,兰兰同学在自学了一本神经网络的入门书籍后,提出了一个简化模型,他希望你能帮助他用程序检验这个神经网络模型的实用性。
题目描述
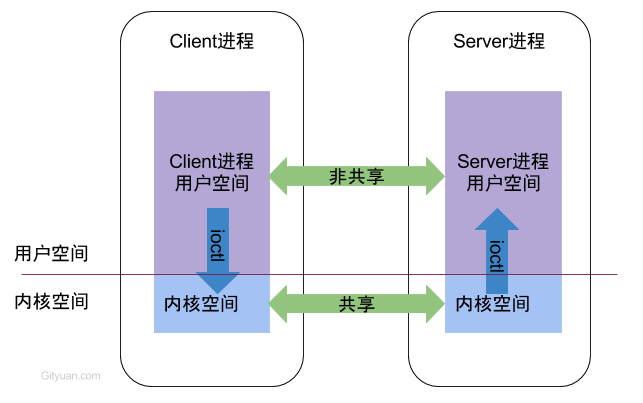
在兰兰的模型中,神经网络就是一张有向图,图中的节点称为神经元,而且两个神经元之间至多有一条边相连,下图是一个神经元的例子:
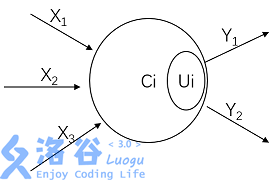
神经元〔编号为 �i)
图中,�1∼�3X1∼X3 是信息输入渠道,�1∼�2Y1∼Y2 是信息输出渠道,��Ci 表示神经元目前的状态,��Ui 是阈值,可视为神经元的一个内在参数。
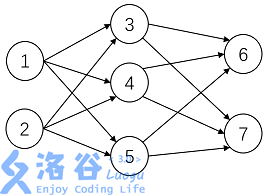
神经元按一定的顺序排列,构成整个神经网络。在兰兰的模型之中,神经网络中的神经元分为几层;称为输入层、输出层,和若干个中间层。每层神经元只向下一层的神经元输出信息,只从上一层神经元接受信息。下图是一个简单的三层神经网络的例子。
兰兰规定,��Ci 服从公式:(其中 �n 是网络中所有神经元的数目)
��=(∑(�,�)∈������)−��Ci=⎝⎛(j,i)∈E∑WjiCj⎠⎞−Ui
公式中的 ���Wji(可能为负值)表示连接 �j 号神经元和 �i 号神经元的边的权值。当 ��Ci 大于 00 时,该神经元处于兴奋状态,否则就处于平静状态。当神经元处于兴奋状态时,下一秒它会向其他神经元传送信号,信号的强度为 ��Ci。
如此.在输入层神经元被激发之后,整个网络系统就在信息传输的推动下进行运作。现在,给定一个神经网络,及当前输入层神经元的状态(��Ci),要求你的程序运算出最后网络输出层的状态。
输入格式
输入文件第一行是两个整数 �n(1≤�≤1001≤n≤100)和 �p。接下来 �n 行,每行 22 个整数,第 �+1i+1 行是神经元 �i 最初状态和其阈值(��Ui),非输入层的神经元开始时状态必然为 00。再下面 �P 行,每行由 22 个整数 �,�i,j 及 11 个整数 ���Wij,表示连接神经元 �,�i,j 的边权值为 ���Wij。
输出格式
输出文件包含若干行,每行有 22 个整数,分别对应一个神经元的编号,及其最后的状态,22 个整数间以空格分隔。仅输出最后状态大于 00 的输出层神经元状态,并且按照编号由小到大顺序输出。
若输出层的神经元最后状态均为 00,则输出 NULL。
输入输出样例
输入 #1复制
5 6 1 0 1 0 0 1 0 1 0 1 1 3 1 1 4 1 1 5 1 2 3 1 2 4 1 2 5 1
输出 #1复制
3 1 4 1 5 1
说明/提示
【题目来源】
NOIP 2003 提高组第一题
题目传送门
首先奉上AC代码:
我知道你们就是来看这个的咳咳
#include<queue>
#include<cstdio>
#include<algorithm>
#define N 102
#define M N*N
using namespace std;
queue<int> q;
struct edge{
int to,val,from,next;
} e[M];
struct answ{
int num,val;
} ans[N];
int h,i,m,n,t,u,v,w,x,c[N],hd[N];
bool out[N],vis[N];
int cnt=0,tot=0;
bool cmp(answ aa,answ bb)
{return aa.num<bb.num;}
void build(int u,int v,int w)
{
cnt++;
e[cnt].to=v;
e[cnt].val=w;
e[cnt].from=u;
e[cnt].next=hd[u];
hd[u]=cnt;
}
int main()
{
scanf("%d%d",&n,&m);
for(i=1;i<=n;++i)
{
hd[i]=0;out[i]=false;
scanf("%d%d",&c[i],&x);
if(c[i])
{q.push(i);vis[i]=true;}
else
{c[i]-=x;vis[i]=false;}
}
for(i=1;i<=m;++i)
{
scanf("%d%d%d",&u,&v,&w);
build(u,v,w);
out[u]=true;
}
while(!q.empty())
{
h=q.front();q.pop();
for(i=hd[h];i;i=e[i].next)
{
if(c[e[i].from]<=0) continue;
t=e[i].to;
c[t]+=(e[i].val*c[h]);
if(!vis[t])
{
q.push(t);
vis[t]=true;
}
}
}
for(i=1;i<=n;++i)
if(c[i]&&!out[i])
{
tot++;
ans[tot].num=i;
ans[tot].val=c[i];
}
if(tot==0) {printf("NULL");return 0;}
sort(ans+1,ans+tot+1,cmp);
for(i=1;i<=tot;++i)
printf("%d %d\n",ans[i].num,ans[i].val);
return 0;
}
(先别急着抄,这份代码有很多冗余部分,下面有更新版代码)
OK,切入正题
如果你不想听我bb想听干货请到下面的讲解区
其实这道题为什么用拓扑和具体思路楼上的几位大佬已经讲的很清楚了
所以说我这篇题解毫无用处
不不不,一定是有用处的
这道题是我练习拓扑的第一道题
本来想找个标程比着学习一下的
但是大佬们的码风都好清奇……
蒟蒻我直接看不懂……
于是我发誓要写一份简单易懂的拓扑代码
调了一天终于调出来了

不得不说坑点还真不少
讲解区
下面分几部分再详解一下这道题
1.读入+处理
注意,因为这是一个拓扑的题
所以我们拓展点的时候要借助队列
那如何发挥队列的用处呢?
由题意,只有最初状态为1的点才会往后传递
我们完全可以在读入的时候就把上述点push进队列中
楼上大佬也证明过了,阈值u(我的代码中是x)可以一开始直接减掉,我就不再赘述了。
scanf("%d%d",&n,&m);
for(i=1;i<=n;++i)
{
hd[i]=0;out[i]=false;
scanf("%d%d",&c[i],&x);
if(c[i])
{q.push(i);vis[i]=true;}
else
{c[i]-=x;vis[i]=false;}
}
注:hd数组即邻接表中的head;out表示这个点是否有出边,没有的话就是最后一层,这里后面会用到
vis数组表示点是否入过队,防止重复
2.建图(有向图)
for(i=1;i<=m;++i)
{
scanf("%d%d%d",&u,&v,&w);
build(u,v,w);
out[u]=true;
}
out数组上面提到过了
这个build多了一点小东西
void build(int u,int v,int w)
{
cnt++;
e[cnt].to=v;
e[cnt].val=w;
e[cnt].from=u;//没错就是这里
e[cnt].next=hd[u];
hd[u]=cnt;
}
from是干啥用的呢?
每个点(神经)传递信息的时候,我们要判断这条边的起点是否能传递
于是我用了个from来存这个起点的状态
upd on 2020.02.02:from其实不用哒,我们在队列中取出的front就是每次前向星遍历的from!
3.拓扑处理(核心部分)
上面我已经说过了,用队列来维护拓扑序列。
这个地方我写的比较明白,具体注释放代码里了,往下看吧
while(!q.empty())
{
h=q.front();q.pop();
for(i=hd[h];i;i=e[i].next)
{
if(c[e[i].from]<=0) continue;
t=e[i].to;//t记录该边终点
c[t]+=(e[i].val*c[h]);//题目里的求和公式就是这个意思,终点值+=起点值*边权
if(!vis[t])
{
q.push(t);
vis[t]=true;
}
}
}
到这里有大佬已经看出来了,我好像没用“入度”这个数组来进行拓扑排序啊
没错,这个题确实没用……
因为我们只需要统计输出层
也就是没有出边的点
upd on 2020.02.02,这一部分也有更新,具体看最下方新版代码
4.记录答案
for(i=1;i<=n;i++)
if(!out[i]&&c[i]>0)
{printf("%d %d\n",i,c[i]);flag=1;}
if(!flag) {puts("NULL");return 0;}
我突然发现,我当时好菜啊……
几位大佬用的优先队列,按照编号重载运算符之后输出
受启发我用了结构体+排序输出的最后ans,but in fact……完全没必要啊……
我们只需要for循环从小到大找,越靠前找到的合法输出层就是编号越小的啊……符合题意。直接输出就好了……
5.return 0;完结撒花❀
最后再bb一句
啊不是
总结一下
1.关于拓扑排序输入的时候可以干很多事,比如说预处理vis,元素入队等等,这道题还直接减去了阈值
2.build的时候不要太死板打板子,这道题中加一个from有助于后续操作
3.拓扑排序不一定都要用入度的,某些特定情况下可以用一些别的方法实现拓扑
4.(这好像是句废话)存某些信息的时候不一定要用高级数据结构,数组大法好!
看在我写了这么多而且代码和这么好懂的份上求管理大大通过吧QAQ
补充:楼上几位大佬的程序真的很难懂(现在我是二楼了hhhh),也没有讲解核心代码,希望管理员能通过这篇题解谢谢啦
分割线
update on 2020.02.02.20:20 (千年难遇的大回文日期)
当时写这篇题解的时候算是初学者,对图论,拓扑理解都不是很深,题目中一些概念也没太弄明白。一年以后的现在,通过这一年的磨练,以及评论区大佬们的指导,更新一份新的AC代码,更简洁明了。思路和上面讲解一样。
所以我上面说了吗,不要急着抄代码嘛,下面有更短的咳咳
下面奉上AC代码plus:
#include<queue>
#include<cstdio>
#include<algorithm>
#define N 101
using namespace std;
struct edge{
int to,val,nxt;
} e[N*N];
struct answer{
int id,val;
} ans[N];
int h,i,m,n,t,u,v,w,U,c[N],hd[N],out[N],vis[N];
queue <int> q;
int cnt=0,flag=0;
inline bool cmp(answer aa,answer bb)
{return aa.id<bb.id;}
inline void build(int u,int v,int w)
{
cnt++;
e[cnt].to=v;
e[cnt].val=w;
e[cnt].nxt=hd[u];
hd[u]=cnt;
}
int main()
{
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
{
vis[i]=out[i]=0;
scanf("%d%d",&c[i],&U);
//这里不可以直接减,初始层也有可能有阈值,但不能减去.(题目要求)
if(c[i]>0)
{q.push(i);vis[i]=1;}//vis表示是否已入过队
else c[i]-=U;
}
for(i=1;i<=m;i++)
{
scanf("%d%d%d",&u,&v,&w);
build(u,v,w);
out[u]=1;//out表示有无出边,用于最后找输出层
}
while(!q.empty())
{
h=q.front();q.pop();
if(c[h]<=0) continue;
for(i=hd[h];i;i=e[i].nxt)
{
t=e[i].to;
c[t]+=e[i].val*c[h];
if(!vis[t])
{
q.push(t);
vis[t]=1;
}
}
}
for(i=1;i<=n;i++)
if(!out[i]&&c[i]>0)
{printf("%d %d\n",i,c[i]);flag=1;}
if(!flag) {puts("NULL");return 0;}
return 0;
}
修改的地方:
- (修改了一点点码风)
- 拓扑排序时把continue的判断放到了前向星遍历之前,理论上讲(至少我现在是这么理解的)更科学一点
- 好吧看来看自己一年前的代码
翻看自己三年前的空间一样果然惊喜不断,最后我们成功又缩短了不少,思路也更清晰了一点。 - 所以,既然我又加强了一下题解,何不