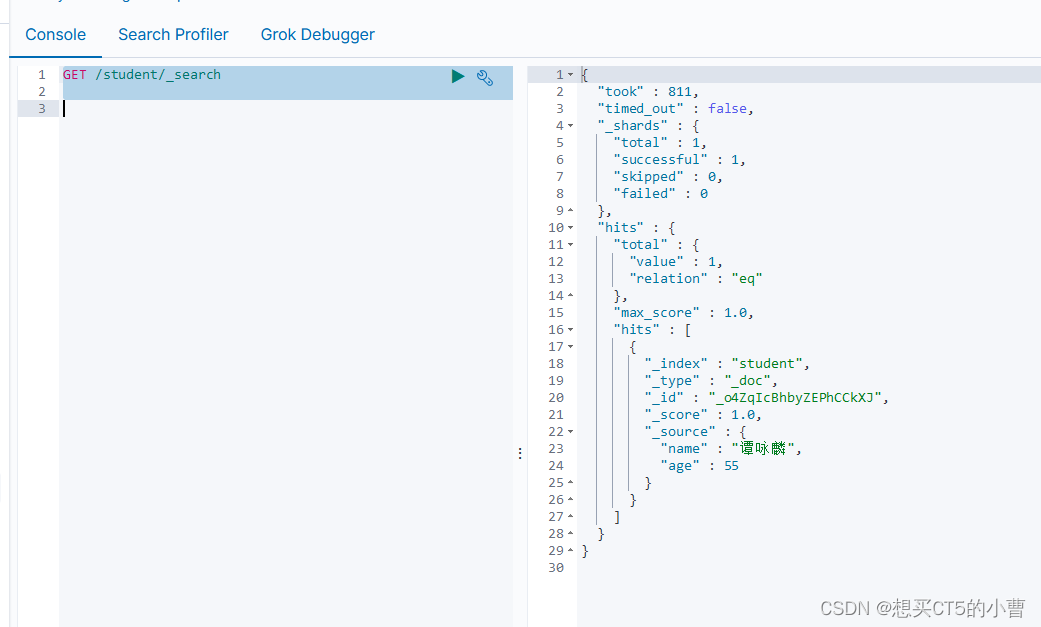
算法专项 Hash、BitMap、Set、布隆过滤器、中文分词、Lucene 倒排索引
Hash
思考:
- 给你N(1<N<10)个自然数,每个数的范围为(1~100)。现在让你以最快的速度判断某一个数是否在这N个数内,不得使用已经封装好的类,该如何实现
- 给你N(1<N<10)个自然数,每个数的范围为(1~10000000000)。现在让你以最快的速度判断某一个数是否在这N个数内,不得使用已经封装好的类,该如何实现。 A[] = new int[N+1]?
散列表
散列表英文就是Hash Table,也就是我们经常说的哈希表,大家肯定经常听到,其实刚刚上面我们的那个例子就是运用了散列表的思想来解决的
散列表用的是数组支持按照下标随机访问数据的特性,散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表
实际上,这个例子已经用到了散列的思想。在这个例子里,N自然数,并且与数组的下标形成一一映射,所以利用数组支持根据下标随机访问的特性
查找的时间复杂度是O(1)这一特性,就可以实现快速判断元素是否存在序列当中
Hash冲突
开放寻址:开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入
当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
缺点:
- 删除需要特殊处理
- 插入的数据如果过多会导致散列表很多冲突查找可能会退化成遍历
链路地址:使用链表, 链表法是一种更加常用的散列冲突解决办法,相比开放寻址法,它要简单很多
HashMap Hash冲突之链表优化
由于链表这种结构确实存在一些缺点,所以在我们的JDK中对之进行了优化,引入了更高效的数据结构:
红黑树
-
初始大小:HashMap默认的初始大小是16,这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数,这样会大大提高HashMap的性能
-
动态扩容:最大装载因子默认是0.75,当HashMap中元素个数超过
0.75*capacity(capacity表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小 -
Hash冲突解决办法:JDK1.7底层采用链表法。在JDK1.8版本中,为了对HashMap做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高HashMap的性能。当红黑树结点个数少于8个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小,最好使用2的整数倍
}
设计高效的企业级Hash表
这里大家可以借鉴HashMap 的设计思路:
- 必须要高效:即插入,删除 查找必须要快
- 内存:不能占用太多的内存,考虑用其他的结构,比如B+Tree,HashMap 10亿,存硬盘的算法:mysql B+tree
- Hash函数:这个要根据实际情况考虑.%
- 扩容:就是预估数据的大小,HashMap 默认的空间是16? 我知道我要存10000个数,
2^n > 10000 or 2^n-1 - Hash冲突后怎么解决:链表 数组
Hash应用
- 加密:MD5 哈希算法,不可逆
- 判断视频是否重复
- 相似性检测
- 负载均衡
- 分布式分库分表
- 分布式存储
- 查找算法 HashMap
Hash扩容算法在多线程时问题
- 多线程put操作,get会死循环()。这个确实可以优化掉,比如扩容的时候我们新开一个数组,不要使用共享的那个数组
- 多线程put可能会导致get取值错误
为什么会出现死循环呢?
- hash冲突时我们会采用了链式结构来保存冲突的值。如果我们在遍历这个链表时本身是这样的1->2->3->null
- 如果我们遍历到3本身应该是null的,这时候刚好有人把这个null给计算出了值,null => 1->3,这下就完了 原来的3本来是要指向null结束的 这下又变成指向1,而这个1又刚好指向3 ,这样是不是就一直循环下去了
BitMap
场景
- 数据判重
- 不重复数据排序
缺点
- 数据不能重复
- 数据量少时没有优势
- 无法处理字符串hash冲突
思考:如何在3亿个整数(0~2亿)中判断某一个数是否存在?内存限制500M,一台机器
- 分治:
- 布隆过滤器:神器
- Redis
- Hash: 开3亿个空间,HashMap(2亿) ?
- 数组:年龄问题;data[2亿] ?
- Bit:bitMap,位图;
类型基础:计算中最小的内存单位是bit,只可以表示0,1
- 1Byte = 8bit
- 1int = 4byte 32bit
- Float = 4byte 32bit
- Long=8byte 64bit
- Char 2byte 16bit
Int a = 1,这个1在计算中是怎么存储的?
0000 0000 0000 0000 0000 0000 0000 0001 toBinaryString (1) =1
运算符基础
左移 <<
8 << 2 = 8 * (2 ** 2) = 8 * 4 = 328 << 1 = 8 * (2 ** 1) = 8 * 2 = 16
0000 0000 0000 0000 0000 0000 0000 1000
<< 2
0000 0000 0000 0000 0000 0000 0010 0000
右移 >>
8 >> 2 = 8 / (2 ** 2) = 8 / 4 = 28 >> 1 = 8 / (2 ** 1) = 8 / 2 = 4
0000 0000 0000 0000 0000 0000 0000 1000
>> 2
0000 0000 0000 0000 0000 0000 0000 0010
位与 &
8 & 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 0000 = 0
位或 |
8 | 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 1111 = 23 + 22 + 21 + 20 = 8+4+2+1=15
BitMap
一个int占32个bit位。假如我们用这个32个bit位的每一位的值来表示一个数的话是不是就可以表示32个数字,也就是说32个数字只需要一个int所占的空间大小就可以了,瞬间就可以缩小空间32倍
比如假设我们有N{2,3,64}个数中最大的是MAX,那么我们只需要开int[MAX/32+1]个int数组就可以存储完这些数据,具体可以看以下结构:
Int a : 0000 0000 0000 0000 0000 0000 0000 0000 这里是32个位置,我们可以利用每个位置的0或者1来表示该位置的数是否存在,这样我们就可以得到以下存储结构:
Data[0]: 0~31 32位
Data[1]: 32~63 32位
Data[2]: 64~95 32位
Data[MAX / 32+1]
/**
* 解决:
* 1. 数据去重
* 2. 对没有重复的数据排序
* 3. 根据1和2扩展其他应用,比如不重复的数,统计数据
* 缺点: 数据不能重复、字符串hash冲突、数据跨多比较大的也不适合
*
* 求解2亿个数,判断某个数是否存在
*
* 最大的数是64 data[64/32] = 3
* data[0] 0000 0000 0000 0000 0000 0000 0000 0000 0~31
* data[1] 0000 0000 0000 0000 0000 0000 0000 0000 32~63
* data[2] 0000 0000 0000 0000 0000 0000 0000 0000 64~95
*
* 数字 2 65 2亿分别位置
* 2/32=0 说明放在data[0]数组位置, 2%32=2说明放在数组第3个位置
* 65/32=2 说明放在data[2]数组位置, 65%32=1说明放在数组第2个位置
*
* 2亿=M
* 开2亿个数组 2亿*4(byte) / 1024 /1024 = 762M
* 如果用BitMap: 2亿*4(byte)/32 / 1024 /1024 = 762/32 = 23M (int数组)
* 判断66是否存在 66/32=2 -> 66%32=2 -> data[2]里面找第三个位置是否是1
*/
public class BitMap {
byte[] bits; //如果是byte那就是只能存8个数
int max; //最大的那个数
public BitMap(int max) {
this.max = max;
this.bits = new byte[(max >> 3) + 1]; // max / 8 + 1
}
public void add(int n) { //添加数字
int bitsIndex = n >> 3; // 除8就可以知道在哪一个byte
int loc = n % 8; // n % 8 与运算可以标识求余 n & 8
//接下来要把bit数组里面bitsIndex下标的byte里面第loc个bit位置设置为1
// 0000 0100
// 0000 1000
// 或运算(|)
// 0000 1100
bits[bitsIndex] |= 1 << loc;
}
public boolean find(int n) {
int bitsIndex = n >> 3;
int loc = n % 8;
int flag = bits[bitsIndex] & (1 << loc);
if (flag == 0) {
return false; //不存在
} else {
return true; //存在
}
}
public static void main(String[] args) {
BitMap bitMap = new BitMap(100);
bitMap.add(2);
bitMap.add(3);
bitMap.add(65);
bitMap.add(64);
bitMap.add(99);
System.out.println(bitMap.find(2));
System.out.println(bitMap.find(5));
System.out.println(bitMap.find(64));
}
}
Set
各种容器对比
- List:
可以重复存储对象
插入的顺序和遍历的顺序是一致的
常用的实现方式:链表+数组(ArrayList,LinkedList,Vector) - Set:
不允许重复对象
无法保证每个元素的插入和输出顺序,无序容器。
TreeSet是有序的
常用的实现方式:HashSet,TreeSet,LinkedHashSet(强行保证输出顺序和插入顺序一致,双向链表,耗费空间) - Map:
Map是键值对的形式存储,会有key+value:
Map不允许出现相同的key,出现就会倍覆盖
Map主要实现方式:HashMap,HashTable,TreeMap(也是一个有序的,默认按照自然顺序,其底层结构同样是红黑树)
布隆过滤器(不存在的就肯定不存在)
实现的思想:
- 插入:将一个插入的元素使用K个hash函数进行k次计算,将得到的Hash值所对应的bit数组下标置为1
- 查找:跟插入一样的道理,将查找的元素使用k个函数进行k次计算,将得到的值找出对应的bit数组下标,判断是否为1,如果都为1则说明这个值可能在序列中,反之肯定不在序列中
为什么是可能在序列中呢?存在误判率
- 删除:非常明确的告诉你,这玩意是不支持删除的
/**
* 应用场景 -- 允许一定误差率 0.1%
* 1. 爬虫
* 2. 缓存击穿 小数据量用hash或id可以用bitmap
* 3. 垃圾邮件过滤
* 4. 秒杀系统
* 5. hbase.get
*/
public class BloomFilter {
private int size;
private BitSet bitSet;
public BloomFilter(int size) {
this.size = size;
bitSet = new BitSet(size);
}
public void add(String key) {
bitSet.set(hash_1(key), true);
bitSet.set(hash_2(key), true);
bitSet.set(hash_3(key), true);
}
public boolean find(String key) {
if (bitSet.get(hash_1(key)) == false)
return false;
if (bitSet.get(hash_2(key)) == false)
return false;
if (bitSet.get(hash_3(key)) == false)
return false;
return true;
}
public int hash_1(String key) {
int hash = 0;
for (int i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return hash % size;
}
public int hash_2(String key) {
int p = 16777169;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.length()) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash) % size;
}
public int hash_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash) % size;
}
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter(Integer.MAX_VALUE);//21亿/8/1024/1024=250M
System.out.println(bloomFilter.hash_1("1"));
System.out.println(bloomFilter.hash_2("1"));
System.out.println(bloomFilter.hash_3("1"));
bloomFilter.add("1111");
bloomFilter.add("1112");
bloomFilter.add("1113");
System.out.println(bloomFilter.find("1"));
System.out.println(bloomFilter.find("1112"));
}
}
Google Guava Test
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId> <!-- google bloomfilter 布隆过滤器 -->
<version>22.0</version>
</dependency>
public class GoogleGuavaBloomFilterTest {
public static void main(String[] args) {
int dataSize = 1000000; //插入的数据N
double fpp = 0.001; //0.1% 误判率
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), dataSize, fpp);
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
//测试误判率
int t = 0;
for (int i = 2000000; i < 3000000; i++) {
if (bloomFilter.mightContain(i)) {
t++;
}
}
System.out.println("误判个数:" + t);
}
}
中文分词
Trie树
-
什么是Trie树:trie树就是我们平常说的字典树,它是一种专门用来处理字符串匹配的数据结构。特别适合用来在很多字符串中快速查找某一个特定的字符串。前缀树,赫夫曼树,前缀编码
-
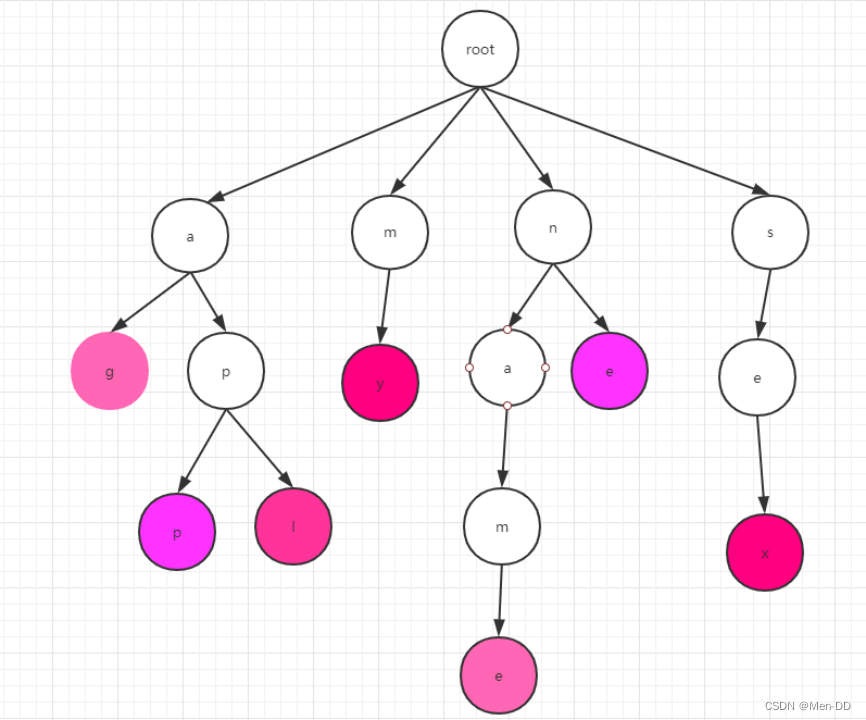
Trie的数据结构:假设我们有以下几个英文单词:my name apple age sex,假如我们要查找里面某一个字符串是否存在,你怎么去找呢?利用字符串的公共前缀,将重复的合在一起组成一颗树,即为我们所要讲的trie树
-
Trie树的构建:我们要先将词分成一个个的字母,然后再依次插入到树中。如右图所示,根节点root,如果我们要插入app
则首先将app分成:a,p,p,然后从root点开始,一层层的插入,注意的是
P会挂在a下面,后面的一个p会挂在前面的p上。单词的末尾我们就用紫色表示。
这里需要注意我们插入的时候每一层的字母都是有序的。 -
Trie的查找:
查找我们就从root点开始,再第一层找第一个字母,依次往下找到我们所要的单词。
注意要找到末尾的标记才算完成一个单词的查找。比如app,我们要找ap
虽然字典树里面有ap,但是这个p不是紫色那么ap还是不存在字典树中的。 -
Trie树的实现: Trie树是一颗多叉树。这里我们应该要想到B+Tree&B-Tree,是有些类似的。
Trie树又是巧妙的利用了数组的下标,因为英文字母刚好是26个,所以我们可以开一个26长度的数组
A[] = new int[26];
A[0] = ‘a’ => 下标就是’a’-97 这里刚好就是0,利用的是ascii计算。
所以它的数据结构应该是
class TrieNode {
Char c;//存储当前这个字符
TrieNode child[26] = new TrieNode[];//存储这个字符的子节点
}
- Trie树的分析:
- 时间复杂度:非常高效 O(单词的长度)
- 空间复杂度:以空间来换效率的数据结构。因为每个单词理论上都有26个子节点,所有它的空间复杂度就是26^n,n表示的是树的高度。
- 优化:
- 重复的字母不要重复建
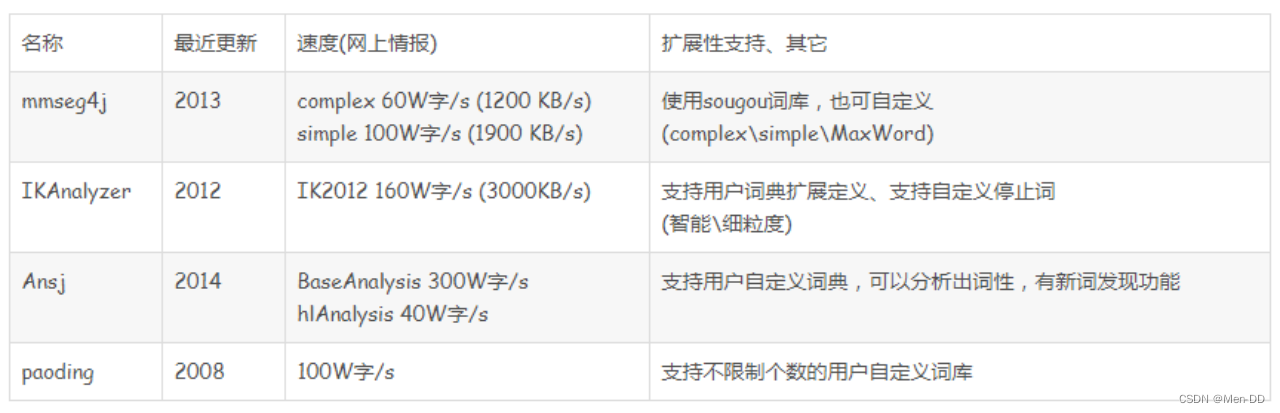
- 因为我们每个node都开了26个空间来存储节点。但实际情况可能不需要这么多,所以这里其实我们可以考虑用散列表来实现,
这里大家可以去看IK的源码,当子节点少的时候是用的数组,但是节点大于3个是它是用的hashMap,这个再一定的程度上是可以节省很多的空间的。
中文分词
-
分词的原理:
(1)英文分词:my name is WangLi
(2)中文分词:我是中国人 -
中文分词器IK
-
中文分词需要特别注意的是它有两种方式:
- Smart:智能分词,这里不会分出一句话的所有情况,比如我是中国人,会分成 我 / 是 /中国人
- 最小颗粒(非Smart):会分出一句话里面的所有情况,比如 我是中国人 会分成 我 / 是 / 中国 / 中国人 /国人
-
中文的歧义问题:利用词库,复杂的还会运用到AI技术 机器学习算法等
武汉市长江大桥- 武汉市/长江大桥
- 武汉/市长/江大桥
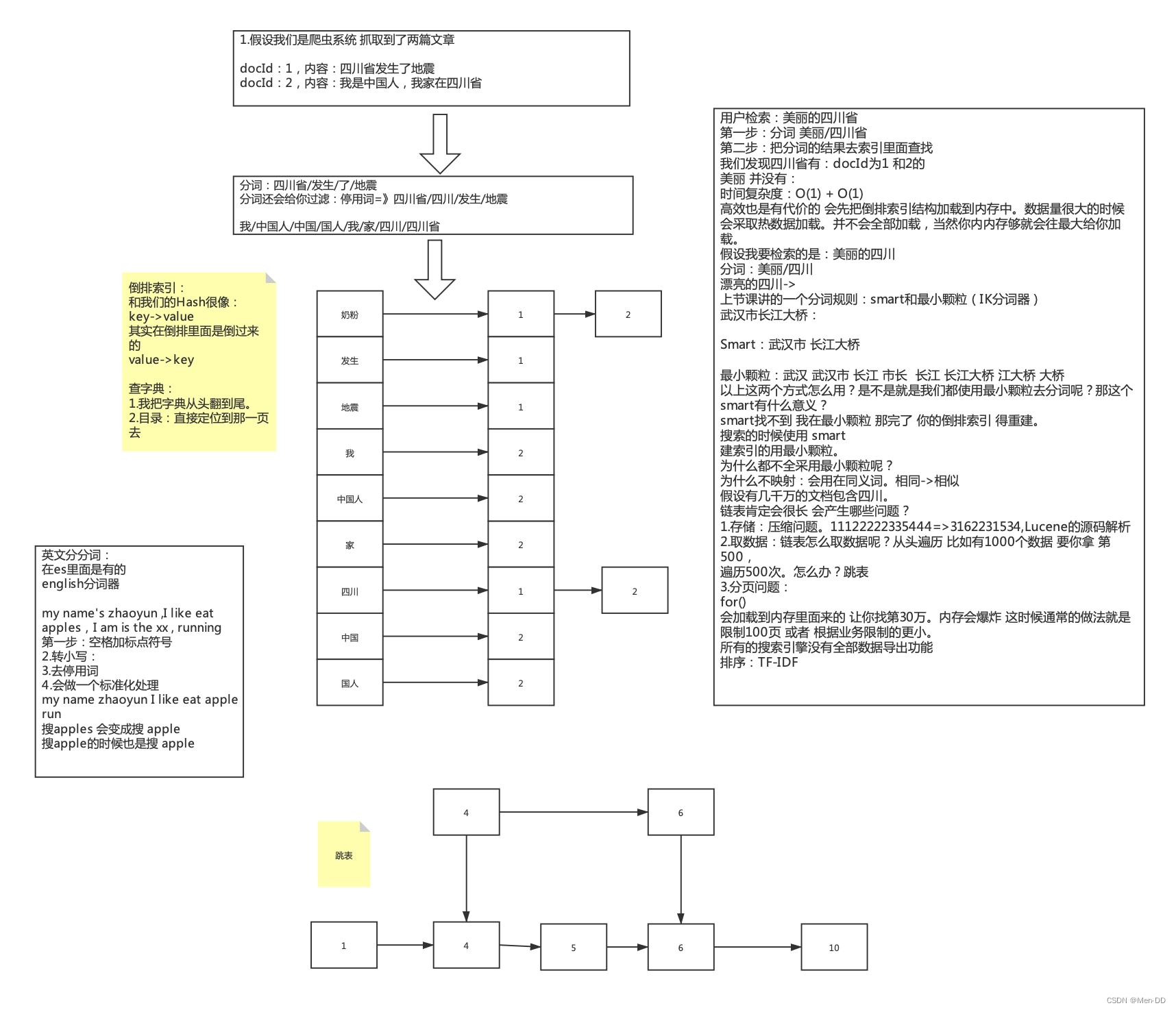
Lucene 倒排索引
搜索引擎
-
数据结构:数据结构在所有的文档中出现了多少次。如果有10篇文章,竟然都出现了数据结构。是不是就表示没有什么区分度
-
TF:词频 一篇doc中包含了多少这个词,包含越多表明越相关。只计算一篇文档的数量
-
DF:文档频率 包含这个词的文档总数,DF在一篇文档算一次
-
IDF:DF取反 也就是 1/DF;如果包含该词的文档越少,也就是DF越小,IDF越大,则说明词对这篇文档重要性就越大
-
TF-IDF: TF*IDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,这篇文章的得分也就越高。
有什么问题?长度的有大有小,一篇文章就2个词,搜其中一个讲道理是50%的权重,有一篇文章有100个词,48词 -
归一化处理:主要是对TF-IDF做处理,会根据文章的长度
-
打分的定制加成