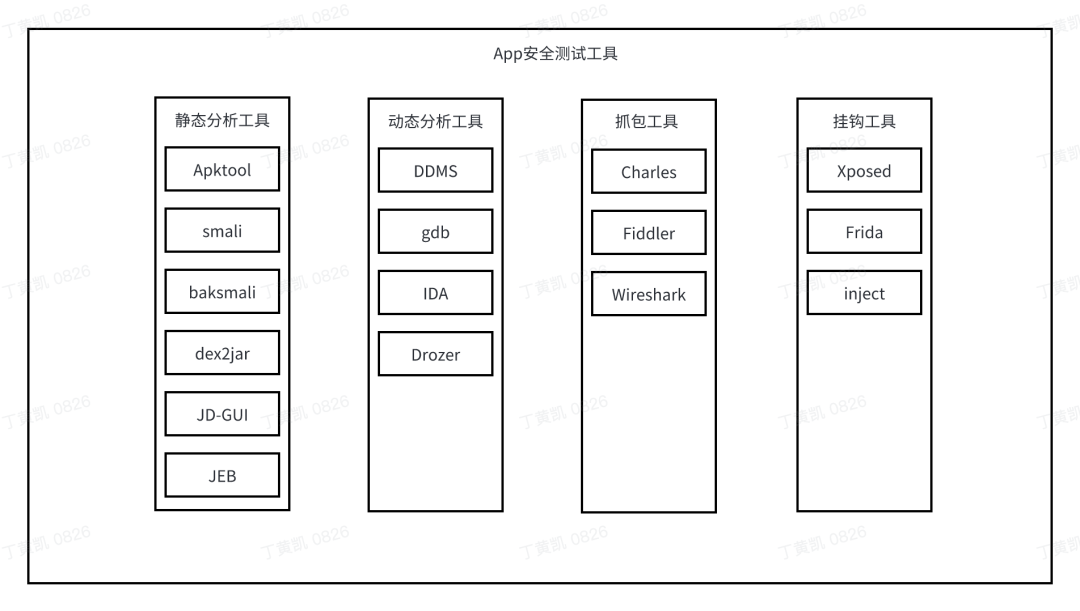
原文
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence.
这里还有一个译制版的很方便阅读
FixMatch:通过一致性和置信度简化半监督学习
代码
pytorch的代码有很多版本,我选择了比较简单的一个:
unofficial PyTorch implementation of FixMatch
其他版本的代码:
TorchSSL
数据加载分析
如果想要将fixmatch应用到自己的程序上,只需要修改数据部分的代码,所以先从这一部分分析。所有的参数都默认使用作者给出的例子:
python train.py --dataset cifar10 --num-labeled 4000 --arch wideresnet --batch-size 64 --lr 0.03 --expand-labels --seed 5 --out results/cifar10@4000.5数据集
原文中使用的是CIFAR-10,CIFAR-10 数据集由 10 个类别的 60000 个 32x32 彩色图像组成,每个类别包含 6000 个图像。有 50000 个训练图像和 10000 个测试图像。
这里作者想使用4000张带标签照片(每个类400张)来进行训练。
训练执行文件 train.py
从主文件开始(def main():)看,一步步分析每个函数的作用。
首先,有一些参数是数据加载比较重要的。
parser.add_argument('--dataset', default='cifar10', type=str, choices=['cifar10', 'cifar100'], help='dataset name') //选择哪个数据集
parser.add_argument('--num-labeled', type=int, default=4000, help='number of labeled data') //多少张带标签的图片
parser.add_argument("--expand-labels", action="store_true", help="expand labels to fit eval steps") //数据扩展来适应每个step的数据产生,一会会详细看着一点
parser.add_argument('--total-steps', default=2**20, type=int, help='number of total steps to run') //这里使用总步数来进行训练(epoch可由此算出)
parser.add_argument('--eval-step', default=1024, type=int, help='number of eval steps to run') //每个epoch中的步数
parser.add_argument('--batch-size', default=64, type=int, help='train batchsize') //batch size
parser.add_argument('--mu', default=7, type=int, help='coefficient of unlabeled batch size') //原文中的超参数μ
首先,我们看看dataset是怎样产生的,有了dataset类,我们才能创建DataLoader对象。
这里提一下Pytorch读取数据流程:Pytorch 数据产生 DataLoader对象详解

在代码中,Dataset是这样产生的:
labeled_dataset, unlabeled_dataset, test_dataset=DATASET_GETTERS[args.dataset](args, './data')上述代码是一个数据集加载代码,其中使用了一个名为 DATASET_GETTERS 的函数来根据 args.dataset 参数的值加载不同的数据集,并将加载后的数据集划分为labeled、unlabeled和test数据集。
以下是代码的解释:
args.dataset是一个参数,用于指定要加载的数据集的名称。假设这个参数的值是一个字符串,例如 'mnist'、'cifar10' 等,表示要加载的数据集的名称。DATASET_GETTERS是一个函数,接受args和数据集目录路径(在这里是./data)作为输入。它根据args.dataset参数的值来加载相应的数据集,并返回加载后的数据集。DATASET_GETTERS[args.dataset]是对DATASET_GETTERS函数的调用,其中args.dataset的值被用作函数的参数,用于选择要加载的数据集。DATASET_GETTERS[args.dataset](args, './data')是对DATASET_GETTERS函数的调用,传入args参数和数据集目录路径./data,从而加载指定的数据集。- 加载后的数据集被赋值给
labeled_dataset、unlabeled_dataset和test_dataset变量,这三个变量分别表示带标签、无标签和测试数据集。这里假设DATASET_GETTERS函数返回的数据集已经经过划分,可以直接赋值给这三个变量。
然后,跳到下一小节看对DATASET_GETTERS的分析。Dataset对象 cifar.py
通过dataset类,我们产生dataloader对象:
train_sampler=RandomSampler if args.local_rank == -1 else DistributedSampler
labeled_trainloader = Dataloader(
labeled_dataset,
sampler=train_sampler(labeled_dataset),
batch_size=args.batch_size,
num_workers=args.num_workers,
drop_last=True)
unlabeled_trainloader = Dataloader(
unlabeled_dataset,
sampler=train_sampler(unlabeled_dataset),
batch_size=args.batch_size * args.mu,
num_workers=args.num_workers,
drop_last=True)
test_loader = Dataloader(
test_dataset,
sampler=SequentialSampler(test_dataset),
batch_size=args.batch_size,
num_workers=args.num_workers)
上述代码用于将加载的数据集划分为labeled和unlabeled的训练数据集以及test数据集,并配置数据加载器(DataLoader)用于在训练和测试过程中加载数据。
以下是代码的解释:
train_sampler是一个用于对train dataset进行采样的采样器对象。根据args.local_rank的值是否为 -1(表示非分布式训练),选择RandomSampler(随机采样)或DistributedSampler(分布式采样)作为采样器。如果args.local_rank的值为 -1,则使用RandomSampler对数据进行随机采样;否则,使用DistributedSampler进行分布式采样。labeled_trainloader是用于加载带标签训练数据集的数据加载器。使用DataLoader函数将labeled_dataset数据集和前面定义的train_sampler采样器配置为数据加载器。同时,设置批量大小为args.batch_size,设置并行加载的工作进程数为args.num_workers,并设置drop_last参数为True,表示在最后一个批次数据不足时丢弃该批次。unlabeled_trainloader是用于加载无标签训练数据集的数据加载器。类似于labeled_trainloader,使用DataLoader函数将unlabeled_dataset数据集和train_sampler采样器配置为数据加载器。不过,这里将批量大小设置为args.batch_size*args.mu,其中args.mu是一个超参数,用于控制无标签数据集的批量大小。test_loader是用于加载测试数据集的数据加载器。使用DataLoader函数将test_dataset数据集和SequentialSampler(顺序采样)采样器配置为数据加载器。设置批量大小为args.batch_size,设置并行加载的工作进程数为args.num_workers。
请注意,上述代码中的参数和采样器的选择可能需要根据具体的任务和模型需求进行调整。在实际使用中,应根据数据集的格式、任务的需求以及硬件资源的情况,配置合适的数据加载器和参数设置。
关于dataloader的参数:
一文弄懂Pytorch的DataLoader,Dataset,Sampler之间的关系_别致的SmallSix的博客-CSDN博客

数据加载部分差不多就结束了,最后我们再看看在循环中是如何调用这些数据的吧。首先,作者使用了x, y = next(iter(training_loader))结构,其原理:

作者的代码如下,当迭代到最后的轮次时会报错,所以加上except开始新一轮的迭代。
labeled_iter = iter(labeled_trainloader)
for batch_idx in range(1024):
try:
inputs_x, targets_x = labeled_iter.next()
print(targets_x.shape[0])
except:
labeled_iter = iter(labeled_trainloader)
inputs_x, targets_x = labeled_iter.next()
print(targets_x.shape[0])上述代码是一个示例的数据加载和迭代过程的代码。代码使用了一个带有 try-except 的循环,从 labeled_trainloader 数据加载器中迭代加载训练数据,并输出每个批次的目标(标签)数量。
以下是代码的解释:
labeled_iter是一个labeled_trainloader数据加载器的迭代器,用于迭代加载训练数据集的批次。- 循环从
batch_idx为 0 开始,迭代到 1023。这里使用了一个固定的循环次数,加载了 1024 个批次的训练数据。 - 在每次循环中,使用
labeled_iter.next()从labeled_trainloader数据加载器中获取下一个批次的数据。其中,inputs_x是输入数据,targets_x是对应的目标(标签)数据。 - 使用
targets_x.shape[0]输出目标数据的数量,即当前批次的标签数量。 - 如果在迭代过程中发生异常(如到达数据集末尾),则使用
labeled_iter = iter(labeled_trainloader)重新初始化labeled_iter,从数据加载器的头部重新开始迭代,并继续输出下一个批次的标签数量。
请注意,上述代码中的循环次数和异常处理逻辑可能需要根据具体的任务和数据集情况进行调整,以确保正确加载和处理数据。在实际使用中,应根据数据集的大小和需求,灵活调整循环次数和异常处理逻辑。
Dataset对象 cifar.py
在dataset文件夹中的cifar.py文件中定义了dataset类。
首先,我们使用get_cifar10函数:
DATASET_GETTERS = {'cifar10': get_cifar10,
'cifar100': get_cifar100}上述代码定义了一个字典 DATASET_GETTERS,其中包含了两个键值对:
- 键
'cifar10',对应值get_cifar10:表示获取 CIFAR-10 数据集的方法,这里假设get_cifar10是一个函数或方法,用于从数据集获取 CIFAR-10 数据并返回数据加载器或数据集对象。 - 键
'cifar100',对应值get_cifar100:表示获取 CIFAR-100 数据集的方法,这里假设get_cifar100是一个函数或方法,用于从数据集获取 CIFAR-100 数据并返回数据加载器或数据集对象。
这样,通过使用 DATASET_GETTERS 字典,可以根据不同的键(即数据集名称)来获取对应的数据集,并调用相应的获取数据集的方法,从而获取相应的数据加载器或数据集对象。例如,可以通过 DATASET_GETTERS['cifar10'] 调用 get_cifar10 方法来获取 CIFAR-10 数据集,通过 DATASET_GETTERS['cifar100'] 调用 get_cifar100 方法来获取 CIFAR-100 数据集。这种方式可以方便地扩展和管理多个不同的数据集,并在代码中统一管理它们的获取方法。
def get_cifar10(args, root):
transform_labeled = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(size=32,
padding=int(32*0.125),
padding_mode='reflect'),
transforms.ToTensor(),
transforms.Normalize(mean=cifar10_mean, std=cifar10_std)
])
transform_val = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=cifar10_mean, std=cifar10_std)
])
base_dataset = datasets.CIFAR10(root, train=True, download=True)
train_labeled_idxs, train_unlabeled_idxs = x_u_split(
args, base_dataset.targets)
train_labeled_dataset = CIFAR10SSL(
root, train_labeled_idxs, train=True,
transform=transform_labeled)
train_unlabeled_dataset = CIFAR10SSL(
root, train_unlabeled_idxs, train=True,
transform=TransformFixMatch(mean=cifar10_mean, std=cifar10_std))
test_dataset = datasets.CIFAR10(
root, train=False, transform=transform_val, download=False)
return train_labeled_dataset, train_unlabeled_dataset, test_dataset上述代码定义了一个名为 get_cifar10 的函数,用于获取 CIFAR-10 数据集,并返回包含 labeled_dataset、unlabeled_dataset 和 test_dataset 的元组。
函数的输入参数包括 args 和 root。args 是一个参数对象,包含了在调用该函数时传入的参数,用于配置数据集的获取方式。root 是数据集的根目录,用于指定数据集在本地的存储路径。
函数内部进行了以下操作:
- 定义了两个数据变换(transform):
transform_labeled:包括随机水平翻转、随机裁剪和转换为张量,并应用了 CIFAR-10 数据集的均值和标准差进行标准化。transform_val:仅包括转换为张量,并应用了 CIFAR-10 数据集的均值和标准差进行标准化。
- 使用
datasets.CIFAR10类从root下载或加载 CIFAR-10 数据集,包括训练集和测试集,并保存在base_dataset中。 - 调用
x_u_split函数,根据参数args和base_dataset.targets对训练集的样本进行有监督和无监督样本的划分,得到train_labeled_idxs和train_unlabeled_idxs,分别表示有监督和无监督样本的索引。 - 使用
CIFAR10SSL类分别构建train_labeled_dataset和train_unlabeled_dataset,并传入相应的数据变换和划分得到的索引。 - 使用
datasets.CIFAR10类构建test_dataset,表示测试集,包括对应的数据变换和不下载数据集。 - 返回
train_labeled_dataset、train_unlabeled_dataset和test_dataset,作为函数的返回值,以便后续在代码中使用这些数据集进行训练、验证和测试操作。
这个函数还是比较复杂的,我们一点点看。
base_dataset = datasets.CIFAR10(root, train=True, download=True)上述代码使用 datasets.CIFAR10 类从指定的 root 目录中加载 CIFAR-10 数据集的训练集,并将数据集存储在 base_dataset 变量中。
datasets.CIFAR10 类是 PyTorch 提供的用于加载 CIFAR-10 数据集的类,其中的参数含义如下:
root:数据集的根目录,表示数据集在本地的存储路径。train:布尔值,表示是否加载训练集。当设置为True时,加载训练集;当设置为False时,加载测试集。download:布尔值,表示是否下载数据集。当设置为True时,如果本地没有该数据集,会自动从互联网上下载并存储在root目录下;当设置为False时,如果本地没有该数据集,会抛出异常。
在这里,train 被设置为 True,表示加载 CIFAR-10 数据集的训练集;download 被设置为 True,表示如果本地没有 CIFAR-10 数据集,则会自动从互联网上下载。加载的数据集会被存储在 base_dataset 变量中,后续可以使用该变量来获取训练集中的样本和标签。
(自己理解)这里下载了cifar10数据集,只是加载了train_dataset。
这是使用cifar数据的常用方法,我们可以查看其返回的对象
for (image, target) in base_dataset:
image.show()
print(target)
print(len(base_dataset.targets)) //50000上述代码使用一个 for 循环遍历 base_dataset,并从中获取每个样本的图像和标签。
在循环中,每次迭代都会从 base_dataset 中获取一个样本的图像和标签,并通过 image.show() 方法显示图像,然后通过 print(target) 打印该样本的标签。
最后,通过 len(base_dataset.targets) 获取 base_dataset 中所有样本的数量。这里的 base_dataset.targets 是一个包含所有训练集样本的标签的列表,其长度就是训练集中样本的数量5000。
综合而言,这段代码的作用是遍历并显示 CIFAR-10 数据集的训练集中的图像,并打印对应的标签,并计算训练集中样本的数量。
之后,使用x_u_split函数将带标签与不带标签的数据索引分开:
train_labeled_idxs, train_unlabeled_idxs = x_u_split(
args, base_dataset.targets)上述代码调用了一个名为 x_u_split 的函数,将 args 和 base_dataset.targets 作为参数传入,并返回两个变量 train_labeled_idxs 和 train_unlabeled_idxs。
x_u_split 函数的作用是将数据集中的样本划分为有标签数据和无标签数据的索引。具体而言,train_labeled_idxs 存储了有标签数据的索引,train_unlabeled_idxs 存储了无标签数据的索引。
这个函数可能是根据某种策略,如半监督学习或者自监督学习的要求,将数据集中的样本划分为有标签和无标签数据集。划分的依据可能包括标签的可用性、数量、分布等因素,具体实现细节需要查看 x_u_split 函数的实现代码。
def x_u_split(args, labels):
label_per_class = args.num_labeled // args.num_classes
labels = np.array(labels)
labeled_idx = []
# unlabeled data: all data (https://github.com/kekmodel/FixMatch-pytorch/issues/10)
unlabeled_idx = np.array(range(len(labels)))
for i in range(args.num_classes):
idx = np.where(labels == i)[0]
idx = np.random.choice(idx, label_per_class, False)
labeled_idx.extend(idx)
labeled_idx = np.array(labeled_idx)
assert len(labeled_idx) == args.num_labeled
if args.expand_labels or args.num_labeled < args.batch_size:
num_expand_x = math.ceil(
args.batch_size * args.eval_step / args.num_labeled)
labeled_idx = np.hstack([labeled_idx for _ in range(num_expand_x)])
np.random.shuffle(labeled_idx)
return labeled_idx, unlabeled_idx每个类带标签数据的个数是均衡的,每个类带标签的数据个数 = 带标签数据总个数//类数。
所以,使用一个循环(10个类):
对于每一个类,找出他们在总数据(labels)中的数据索引,并用random.choice随机选择label_per_class个数据,将他们加入到带标签的数据索引labeled_idx中。
对于不带标签的数据,原文作者使用了所有的数据(包含带标签的数据),所以他的索引为全部数据的索引。
需要注意的一个点是,args.expand_labels参数作者默认为true的,所以我们要进行数据重复。
这里重复的次数num_expand_x为 64(batch_size )* 1024(eval_step)/ 4000 (num_labeled)=17次
所以带标签的数据为 68000个(每个索引都重复了17次)。
上述代码定义了一个名为 x_u_split 的函数,该函数接受两个参数 args 和 labels,并返回两个值 labeled_idx 和 unlabeled_idx。
该函数的作用是将数据集中的样本划分为有标签数据和无标签数据的索引。具体实现如下:
- 计算每个类别的有标签样本数目
label_per_class,通过将args.num_labeled(要求有标签样本的总数目)除以args.num_classes(类别数目)得到; - 将输入的标签
labels转换为 numpy 数组; - 初始化一个空列表
labeled_idx,用于存储有标签样本的索引; - 初始化一个包含所有样本索引的 numpy 数组
unlabeled_idx,作为无标签样本的索引; - 针对每个类别循环处理: a. 获取当前类别的样本索引
idx; b. 从idx中随机选择label_per_class个索引,保证每个类别有足够的有标签样本,并将其添加到labeled_idx列表中; - 将
labeled_idx转换为 numpy 数组; - 检查
labeled_idx的长度是否等于args.num_labeled,确保有标签样本的总数目满足要求; - 如果
args.expand_labels或者args.num_labeled小于args.batch_size,则对labeled_idx进行扩展,使其包含足够多的重复样本索引,以满足后续的批量加载要求; - 对
labeled_idx进行随机洗牌; - 返回
labeled_idx和unlabeled_idx作为函数的输出。
train_labeled_dataset = CIFAR10SSL(
root, train_labeled_idxs, train=True,
transform=transform_labeled)
train_unlabeled_dataset = CIFAR10SSL(
root, train_unlabeled_idxs, train=True,
transform=TransformFixMatch(mean=cifar10_mean, std=cifar10_std))
test_dataset = datasets.CIFAR100(
root, train=False, transform=transform_val, download=False)上述代码分别创建了三个数据集对象,分别为 train_labeled_dataset、train_unlabeled_dataset 和 test_dataset,用于加载 CIFAR-10 数据集的有标签数据、无标签数据和测试数据。
-
train_labeled_dataset对象使用CIFAR10SSL类进行初始化,传入参数root(数据集的根目录路径)、train_labeled_idxs(有标签样本的索引)、train=True(表示加载训练数据集)、transform=transform_labeled(对有标签样本应用的数据变换,包括随机水平翻转、随机裁剪、转换为 Tensor 格式以及数据标准化)。 -
train_unlabeled_dataset对象使用CIFAR10SSL类进行初始化,传入参数root、train_unlabeled_idxs(无标签样本的索引)、train=True、transform=TransformFixMatch(mean=cifar10_mean, std=cifar10_std)(对无标签样本应用的数据变换,包括 FixMatch 算法中使用的数据增强方法,例如随机强化)。 -
test_dataset对象使用datasets.CIFAR100类进行初始化,传入参数root、train=False(表示加载测试数据集)、transform=transform_val(对测试样本应用的数据变换,包括转换为 Tensor 格式以及数据标准化)、download=False(表示不下载测试数据集,因为 CIFAR-100 数据集已经下载过了)。
这样,通过上述代码,可以得到三个数据集对象,分别包含了 CIFAR-10 数据集中的有标签数据、无标签数据和测试数据,并且已经应用了相应的数据变换和数据增强方法。
然后,使用继承CIFAR10的CIFAR10SSL类产生dataset对象。验证集直接使用就行,只需要将数据转化为tensor。
class CIFAR10SSL(datasets.CIFAR10):
def __init__(self, root, indexs, train=True,
transform=None, target_transform=None,
download=False):
super().__init__(root, train=train,
transform=transform,
target_transform=target_transform,
download=download)
if indexs is not None:
self.data = self.data[indexs]
self.targets = np.array(self.targets)[indexs]
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img) //array转换成image
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target上述代码定义了一个名为 CIFAR10SSL 的自定义类,该类继承自 datasets.CIFAR10 类,并添加了一些自定义的功能。
-
__init__(self, root, indexs, train=True, transform=None, target_transform=None, download=False)方法:初始化方法,用于创建CIFAR10SSL类的对象。接收以下参数:root:数据集的根目录路径。indexs:样本索引,用于指定从数据集中选择哪些样本。可以是有标签样本或无标签样本的索引。train:布尔值,表示是否加载训练数据集,默认为True。transform:数据变换操作,用于对样本进行数据增强或数据预处理,默认为None。target_transform:目标变换操作,用于对样本的目标进行处理,默认为None。download:布尔值,表示是否下载数据集,默认为False。
在该方法中,首先调用父类
datasets.CIFAR10的__init__方法进行初始化,传入相应的参数。然后,根据传入的indexs参数,对self.data和self.targets进行切片操作,以选择对应索引的样本数据和标签。 self.data=self.data[indexs],self.targets=np.array(self.targets)[indexs] -
__getitem__(self, index)方法:用于获取指定索引处的样本。接收一个整数index作为参数,表示样本的索引。在该方法中,根据索引从self.data和self.targets中获取对应的样本数据和标签,并进行相应的数据变换和目标变换操作,最后返回变换后的样本数据和标签。 img,target=self.data[index],self.targets[index] img=Image.fromarray(image)
通过上述代码,定义了一个自定义的数据集类 CIFAR10SSL,用于加载 CIFAR-10 数据集中的有标签或无标签样本,并且可以应用指定的数据变换和目标变换操作。
根据索引返回对应的img和target,用transform参数控制强弱变。
弱增强是一种标准的翻转和移位增强策略. 例如在数据集上以 50% 的概率随机水平翻转图像, 并且在垂直和水平方向上随机平移。
对于"强"增强,文中尝试了两种基于 AutoAugment 的方法, 然后是 Cutout。AutoAugment 使用强化学习来查找包含来自 Python Imaging Library 的转换的增强策略,这需要标记数据来学习增强策略, 这使得在可用标记数据有限的 SSL 设置中使用存在问题。因此, 使用不需要利用标记数据学习增强策略的 AutoAugment 变体, 例如 RandAugment 和 CTAugment。RandAugment 和 CTAugment 都没有使用学习策略, 而是为每个样本随机选择转换。对于 RandAugment,控制所有失真严重程度的幅度是从预定义的范围内随机采样的。具有随机幅度的 RandAugment 也被用于 UDA。 而对于 CTAugment, 单个变换的幅度是即时学习的。
OK,现在我们已经得到了带标签的数据集,不带标签的数据集,验证集的dataset数据,然后我们回到主文件。Dataset对象 cifar.py




![P1034 [NOIP2002 提高组] 矩形覆盖](https://img-blog.csdnimg.cn/img_convert/5aa1b680b59744370162ea66833dd157.png)