文章目录
- MySQL数据类型
- 一、数值类型
- 1.类型总览
- 2.BIT类型
- 3.INT系列类型
- 4.浮点数类型
- 1)float与double
- 2.float与decimal
- 二、字符串类型
- 1.类型总览
- 2.CHAR类型
- 3.VARCHAR类型
- 三、日期与时间类型
- 四、枚举类型
- 1.enum类型
- 2.set类型
- 3.在set中的查找
MySQL数据类型
MySQL中支持的数据类型大致可以分为四类:数值类型、文本/二进制类型、时间日期类型,以及字符串类型。下面分别加以总结:
一、数值类型
1.类型总览
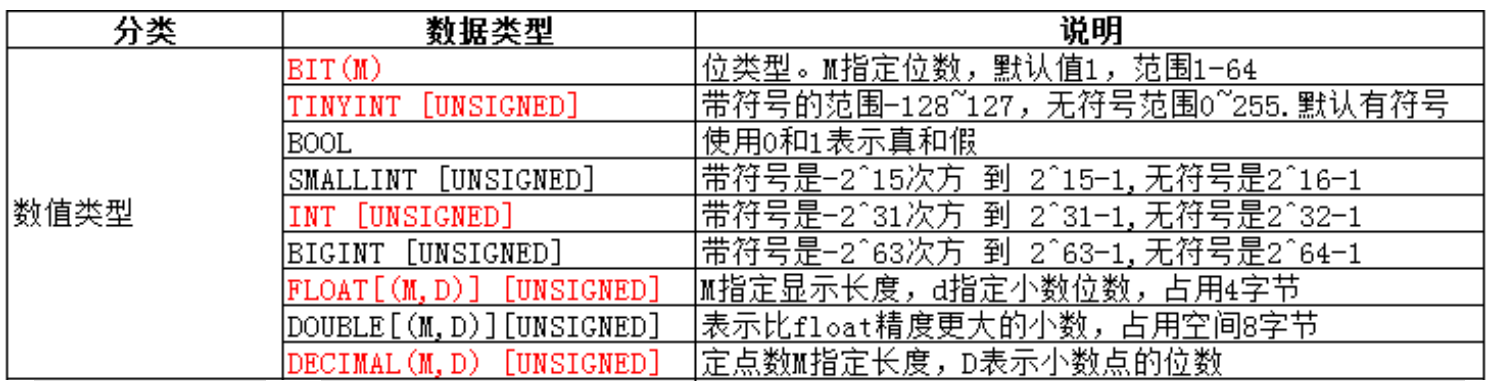
[基本说明]:
-
数据类型划分精细是很有必要的。例如我们存储用户的年龄,使用
TINYINT UNSIGNED占用1字节就足够了。如果INT占用4字节,虽然看起来只是多了3字节,但是×10万,×100万,加上数据库的备份拷贝,浪费的空间也是不少的 -
在C语言中,当我们的数据发生越界时,这些数据就会被截断。但是在MySQL中,数据发生越界时会直接终止当前操作,从而保证数据的可靠性。试想,如果允许截断,那么数据库中存储的1是它本来就是1,还是截断后变成1的,这就会产生歧义,但数据库对可靠性的要求是很高的。
这在本质上就是一种约束。约束在MySQL中是一种很重要的概念,它倒逼着程序员必须要遵守一定的规则。
2.BIT类型
①基本语法
bit[M] -- 位字段类型。M表示每个值的比特位数,范围从1~64,默认为1
- bit(1)则只能存储一个比特位的数值,数据范围在0~1
- bit(8)则可以存储八个比特位的数字,数据范围在0~255
②案例一
mysql> create table t1(
-> id int,
-> b bit(8)
-> );
Query OK, 0 rows affected (0.06 sec)
mysql> insert into t1 values(10, 10);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+------+------+
| id | b |
+------+------+
| 10 |
|
+------+------+
1 row in set (0.00 sec)
[问题一]:为什么类型为bit(8)的10,没有显示出来呢?
bit字段是按照ASCLL码对应的字符显示的。在ASCLL码中10对应回车符,所以结果如果。我们插入65观察结果,65对应的ASCLL码即为65
mysql> use info; Database changed mysql> insert into t1 values(11, 65); Query OK, 1 row affected (0.00 sec) mysql> select * from t1; +------+------+ | id | b | +------+------+ | 10 | | | 11 | A | +------+------+ 2 rows in set (0.00 sec)
如果我们有这样的值,比如存储用户的性别。只需要存放0或1,这时可以定义bit(1),这样可以节省空间。
现在尝试插入大于8比特位的数据(255)的数据,验证MySQL的约束作用。不出所料,我们的行为被直接终止了
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| b | bit(8) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> insert into t1 values(12, 256);
ERROR 1406 (22001): Data too long for column 'b' at row 1
3.INT系列类型
注意点:
- 使用时注意选择合适的类型
- 可以通过
UNSIGNED关键字来说明某个字段是无符号的,例如age TINYINT UNSIGNED
4.浮点数类型
1)float与double
①基本语法
float[(M, D)] [unsigned] -- M指定显示长度,d指定小数位数,占用空间4个字节
[说明]:
- M指定数据的最长总位数,D指定数据的小数的最长位数
- M与D也属于一种约束
- double在精度上比float更高,使用上没什么区别
②案例
float(4, 2)表示的数据范围为 -99.99~99.99。mysql5.7版本中,在保存值时会四舍五入(不同版本可能不同)
mysql> create table t2(
-> id int,
-> f float(4, 2)
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t2 values(1, 1.1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t2 values(1, 99.991); -- 发生四舍
Query OK, 1 row affected (0.00 sec)
mysql> insert into t2 values(1, 99.995); -- 五入时溢出报错
ERROR 1264 (22003): Out of range value for column 'f' at row 1
mysql> select * from t2;
+------+-------+
| id | f |
+------+-------+
| 0 | 1.10 |
| 1 | 99.99 |
+------+-------+
2 rows in set (0.00 sec)
如果指定类型为 float unsigned,那么数据范围就变成了 0 ~ 99.99,此时不存在四舍五入的问题,例如插入 -0.1就会失败:
mysql> create table t3(
-> id int,
-> f float unsigned
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t3 values(1, 0);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(1, -0.1);
ERROR 1264 (22003): Out of range value for column 'f' at row 1
2.float与decimal
①基本语法
decimal(M, D) [unsigned] -- M指定显示长度,d指定小数位数,占用空间可变
- decimal(5,2) 表示的范围是 -999.99 ~ 999.99
- decimal(5,2) unsigned 表示的范围 0 ~ 999.99
- decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略,默认是10。 值得注意的是,decimal是变长的。
②float与decimal的区别:
DECIMAL 类型之所以准确,是因为它采用的是定点数表示方式,即将一个数表示为整数部分和小数部分的组合,而小数部分的位数是固定的,在创建表时就需要指定。例如,DECIMAL(10,2) 表示总共有 10 位数字,其中小数部分占 2 位,整数部分最多占 8 位。在内部存储时,DECIMAL 类型的数值会被精确地表示为 10 进制数字串。
相比之下,FLOAT 和 DOUBLE 类型采用的是浮点数表示方式,即将一个数表示为尾数(mantissa)和指数(exponent)的乘积形式,其中尾数和指数都是用二进制表示的数值。由于浮点数的存储结构要求在表示大数时保证指数的大小范围,而尾数的精度会随着指数增长而下降。换言之,在表示大数时,尾数所能表示的有效位数变少,因此就会有一定的精度损失。浮点数在内存中的如何存储
-- 说明:float表示的小数精度大约是7位,decimal为30位
mysql> create table t4(
-> f float(12, 10),
-> d decimal(12, 10)
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t4 values(1.1234567, 1.234567);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t4 values(1.12345678, 1.2345678);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t4 values(1.123456789, 1.23456789);
Query OK, 1 row affected (0.01 sec)
mysql> select * from t4;
+--------------+--------------+
| f | d |
+--------------+--------------+
| 1.1234567165 | 1.2345670000 |
| 1.1234568357 | 1.2345678000 |
| 1.1234568357 | 1.2345678900 |
+--------------+--------------+
3 rows in set (0.00 sec)
从上面我们可以看出,如果我们想存储精度更高的小数,则应该使用decimal类型
二、字符串类型
1.类型总览

2.CHAR类型
①基本语法
char(L)-- 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
- L表示的是字符集中的字符数量,而不是字节数量。例如char(2)既可以存储
'UK'这两个英文字母,也可以存储'中国'这两个汉字,在utf8编码下,一个英文占用1字节,而存储一个中文需要3字节。 - L的最大值为255
②使用案例:
mysql> create table t5(
-> id int,
-> name char(3)
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t5 values(0, '唐僧');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t5 values(1, '孙悟空');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t5 values(0, '观音菩萨');
ERROR 1406 (22001): Data too long for column 'name' at row 1
mysql> select * from t5;
+------+-----------+
| id | name |
+------+-----------+
| 0 | 唐僧 |
| 1 | 孙悟空 |
+------+-----------+
2 rows in set (0.00 sec)
3.VARCHAR类型
①基本语法
varchar(L) -- 可变长度字符串,L表示字符长度,最大长度65535个字节
[说明]:
L同样表示最多存储的字符个数而非字节数。由于VARCHAR所能存储的最大字节长度为65535,因此当使用不同的字符集时,VARCHAR(n) 所能存储的最大字符数量也会不同:
-
因为varchar数据类型占用长度是可变的,因此有1 - 3 个字节用于记录数据的长度信息,所以说有效字节数是65532。
-
当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符最多占用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符最多占用2字节)。
②char与varchar的区别:

(假设一个字符占3字节)
char 类型是一种固定长度的数据类型,因此如果定义的 char(n) 列中存储的字符串长度不满足 n,MySQL 会自动在其后面添加空格,直到满足定义的长度为止。
varchar类型是一种变长的数据类型,根据实际字符数分配空间。虽然长度上仍然是有上限的,但这和变长并不冲突。
③如何选择定长或变长字符串?
- 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低(长度字段的读取、更新等会降低效率)。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少
三、日期与时间类型
①基础语法
常用的日期有如下三个:
- date:日期格式为
yyyy-mm-dd,共占用三字节。 - datetime:时间日期格式
yyyy-mm-dd HH:ii:ss占用八字节。可以表示从公元 1000 年 1 月 1 日 00:00:00 到公元 9999 年 12 月 31 日 23:59:59.9999999 的所有日期和时间。 - timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss。格式和 datetime 完全一致,占用四字节 。
②案例:
mysql> create table t7(
-> t1 date,
-> t2 datetime,
-> t3 timestamp
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t7(t1, t2) values('2023-4-25', '2023-4-25 12:14:30');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t7;
+------------+---------------------+---------------------+
| time1 | time2 | time3 |
+------------+---------------------+---------------------+
| 2023-04-25 | 2023-04-25 12:14:30 | 2023-04-25 12:15:18 |
+------------+---------------------+---------------------+
1 row in set (0.00 sec)
特别说明:
timestamp是一种一种特殊的时间类型,不需要用户手动输入。在添加数据的时候,时间戳会根据当前操作的时间自动以yyyy-mm-dd HH:ii:ss的形式补上。同样的,当我们修改字段的数据时,时间戳也会自动修改:
mysql> update t7 set time1='2022-5-1';
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t7;
+------------+---------------------+---------------------+
| time1 | time2 | time3 |
+------------+---------------------+---------------------+
| 2022-05-01 | 2023-04-25 12:14:30 | 2023-04-25 12:19:53 |
+------------+---------------------+---------------------+
1 row in set (0.00 sec)
四、枚举类型
1.enum类型
①基本语法
enum('选项一','选项二','选项三'……) -- 枚举类型,单选
说明:
- 该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值
- 出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535个 (从1开始)
- 当我们添加枚举值时,也可以添加对应的数字编号
②使用案例
mysql> create table t8(
-> id int,
-> sex enum('男','女')
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t8 values(0,'男');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t8 values(1,1); -- 1就指代第一个选项
Query OK, 1 row affected (0.00 sec)
mysql> insert into t8 values(2,2); -- 同理2指代第二个
Query OK, 1 row affected (0.01 sec)
mysql> select * from t8;
+------+------+
| id | sex |
+------+------+
| 0 | 男 |
| 1 | 男 |
| 2 | 女 |
+------+------+
3 rows in set (0.00 sec)
2.set类型
①基本语法
set('选项一', '选型二', '选型三',……) -- 集合类型,多选
说明:
-
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值,即可以多选。
-
出于效率考虑,单元格中实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32。在表示多个选项时则将数字相与,本质是使用位图进行状态压缩。
以三个选项为例,则选项一用 001表示 ,选项二用010 表示,选项三用100表示。表示一三选项的组合则将其相与,即101。
不建议在添加枚举值,集合值的时候采用数字的方式,因为不利于阅读。
②使用案例
mysql> create table t9(
-> id int,
-> hobby set('爬山','游泳','篮球')
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t9 values(0, '爬山');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t9 values(0, 1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t9 values(1, '游泳,篮球');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t9 values(1, 3);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t9;
+------+---------------+
| id | hobby |
+------+---------------+
| 0 | 爬山 |
| 0 | 爬山 |
| 1 | 游泳,篮球 |
| 1 | 爬山,游泳 |
+------+---------------+
4 rows in set (0.00 sec)
3.在set中的查找
现有如下数据 :
+---------+----------------------+------+
| usrname | hobby | sex |
+---------+----------------------+------+
| 刘备 | 爬山,游泳,篮球 | 男 |
| 关羽 | 爬山,游泳 | 男 |
| 张飞 | 篮球 | 男 |
| 貂蝉 | 游泳 | 女 |
+---------+----------------------+------+
先要查找出所有喜欢游泳的人,使用如下语句查询:
mysql> select * from t10 where hobby='游泳';
+---------+--------+------+
| usrname | hobby | sex |
+---------+--------+------+
| 貂蝉 | 游泳 | 女 |
+---------+--------+------+
1 row in set (0.00 sec)
然而只有貂蝉被选出来了,但这显然是不合理的。刘备和关羽也喜欢游泳。
因此在集合中查询的时候,需要使用 find_in_set(sub,str_list) 函数
- 如果 sub 在 str_list 中,则返回下标;如果不在,返回0;
- str_list 用逗号分隔的字符串。
mysql> select * from t10 where find_in_set('游泳', hobby);
+---------+----------------------+------+
| usrname | hobby | sex |
+---------+----------------------+------+
| 刘备 | 爬山,游泳,篮球 | 男 |
| 关羽 | 爬山,游泳 | 男 |
| 貂蝉 | 游泳 | 女 |
+---------+----------------------+------+
3 rows in set (0.00 sec)