DORE: Document Ordered Relation Extraction based on Generative Framework
文章的主要目标是对文档级的关系抽取。以往的研究主要是基于分类的研究,生成式关系抽取研究较少而且性能不佳。
文档级相比于句子级的关系抽取存在序列长度过长,以及实体定位不准确等问题。作者提出一种利用生成模型范式解决文档级关系抽取问题。以往的研究中采用的生成范式是直接生成出对应的词组(lexicon 生成范式),但此类方法不能很好的适应文档级关系抽取。所以现有的生成式文档级关系抽取方法表现不佳,并不是模型能力不足,而是模型训练的范式不足导致的,因此作者提出DORE范式。
这篇文章其实就是文档抽取实体,再将实体符号化并排序,最后将所有实体转化成二维矩阵填充关系。解码过程刚好反过来,先解码符号,再将符号解码成实体文本。(论文中还提到了五元组,我当做没看见……)

什么是Lexical生成范式?
- ①使用不同的自然语言表示同一实体,例如 “Julian Reinard” 和 “He”;
- ②两个相似的关系使模型识别时产生冲突,例如 “country” and “country of citizenship”;
- ③模型可能输出该文本中未出现的单词;
- ④预测三元组顺序不遵循人类阅读顺序,例如预测 “country of citizenship” 应出现在“league” 之前。
Lexical范式主要存在两个缺点:①不会产生特定长度的目标序列; ②可能出现生成序列过长的现象。
为了解决以上问题作者提出DORE范式:Document Ordered Relation Extraction Paradigm(文档顺序关系生成范式)
优势:①易于学习和控制生成; ②解决输出过长问题。
符号化实体关系类型:使用特殊符号 表示,其中 i∈[1,100] 表示实体类型,i∈[101,200] 表示关系类型。
同一实体可能出现多次且可能以不同的自然语言表达。使用特殊符号表示保证实体和关系的唯一性,且不需要使用分隔符区分包含多个 token 的实体和关系。
作者比较 Lexical 生成范式和 DORE 范式(图),Lexical 范式构建关系抽取还需要进一步处理;
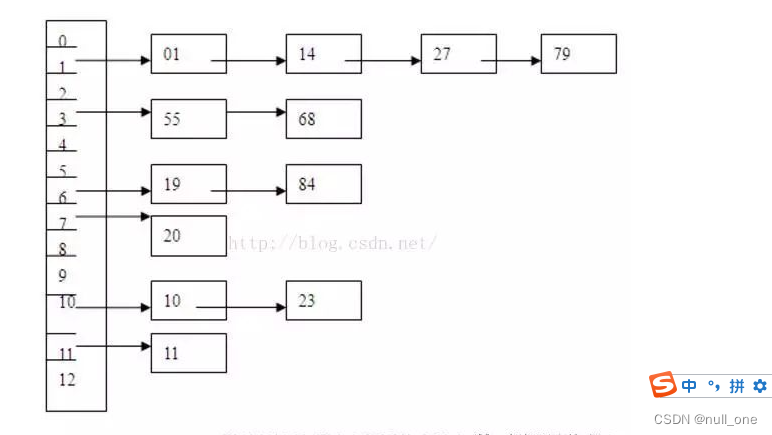
将生成出来的DORE范式中的实体首次出现在文档中的顺序进行排列,分别按照行、列组织关系矩阵。其中每个单元格对应于存在关系或不存在关系的实体对。
文档 D 中存在实体集 E={e_1,e_2,…} ,其中每个实体由多个单词组成 e_i={e_i1,e_i2,…}
每个抽取出来的实例都可以表示为一个关系三元组 (e_1,e_2,r)
如图所示,将所有的实例建模成关系矩阵,其中关系矩阵中的每一个单元格 (i, j) 对应一对实体对 (e_i,e_j) ,计算每种关系的条件概率。
训练目标:寻找最可能的关系矩阵。
生成关系矩阵的损失函数是将交叉熵应用于关系矩阵中的每个元素。
为了更好的训练模型,作者提出了负采样和并行化生成辅助措施。
负采样策略:在训练过程中添加没有关系的实体对作为负采样实例,能够有效的提升模型性能。R+ 表示正实例组,R- 表示负实例组。
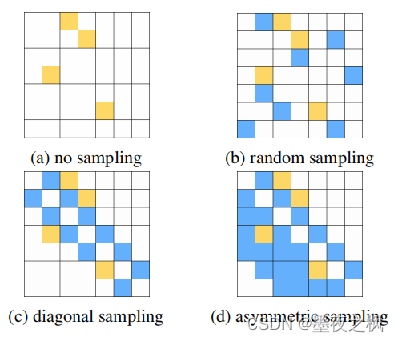
并行化行生成 (Parallel Row Generation):每次生成一行关系矩阵,而不是一次生成整个关系矩阵。该过程由于输入是相同的,因此可以是并行的,从而节省了时间和生成的长度。缺点:失去关系间的部分依赖。
约束解码考虑到参考序列完全是一系列用于二元关系提取的三元组,与lexical 生成范式相比,利用相对简单的约束解码方法来控制生成。解码器所需的词汇表很小,仅限于一定范围的特殊标记。相反,词汇生成需要预测实体的文本形式,则需要完整的词表。
实验:
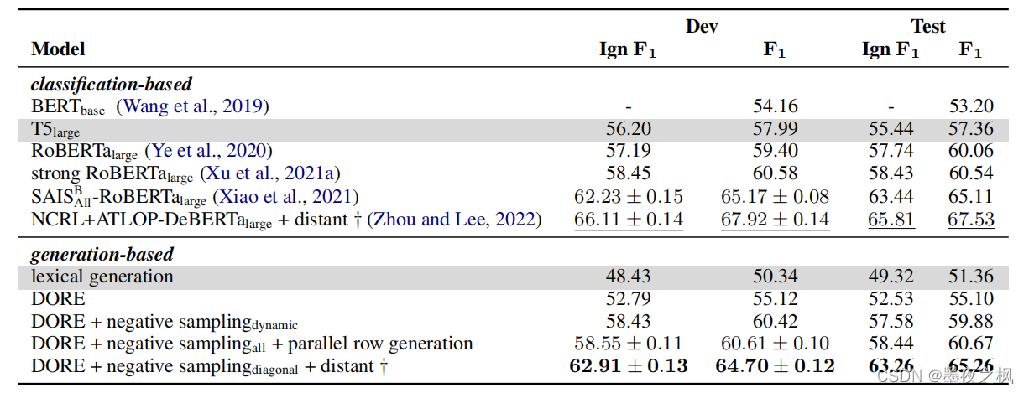
总结:使用生成模型实现文档级实体关系抽取;
创新点:DORE范式,一种符号化实体关系类型的范式。这么做有利于易于学习和控制生成,以及解决输出过长问题。
关系矩阵:以表填充作为核心解决方式,按照实体出现在文本中的顺序生成关系矩阵,单元格内填充关系。