文章目录
- 0.ChatGPT大模型带来的影响
- 0.1 ChatGPT带来信息化革命性创新,目前尚不能处理专业知识但成长很快
- 0.2 Chat GPT为网安行业带来新的创新方向,也将引领新一轮投融资热潮
- 0.2.1 攻击方发起网络攻击的门槛降低
- 0.2.2 防守方合理使用ChatGPT可大幅减少安全运营工作量
- 0.2.3 针对AI网络安全应用的投融资将呈现井喷效应
- 0.3 Chat GPT的广泛应用将推动数据安全需求升级
- 0.4欧洲刑警组织:ChatGPT很有可能被滥用于网络犯罪
- 1. 多GPU并行训练
- 1.1 大模型训练-多GPU训练方法种类
- 1.1.1 两种GPU训练方法:DataParallel 和 DistributedDataParallel:
- 1.2 误差梯度如何在不同设备之间通信?
- 1.3 BN如何在不同设备之间同步?
- 2. 预训练模型发展历程
- 3. 面向预训练语言模型的Prompt-Tuning技术发展历程
0.ChatGPT大模型带来的影响
0.1 ChatGPT带来信息化革命性创新,目前尚不能处理专业知识但成长很快
2023年虽然才开始不久,但毫无疑问ChatGPT是今年最重大的科技话题之一。Chat GPT是生成式人工智能的开山之作,出道即巅峰,是继PC互联网、移动互联网之后又一次革命性创新,其创新性在于突破之前决策式AI基于规则的算法模型框架,跳出之前“数据搬运工”的传统模式,即在海量数据中寻找符合规则策略的数据,经过比对计算,基于当前的环境、条件和状态,准确的找到符合条件的数据,一步一步的走向算法和程序的终点,得出一个确定的决策。
生成式AI为决策式AI赋予了灵魂和思想,决策式AI需要在海量数据中挑选并使用符合规则的数据,自身并不创造新的数据,生成式AI的革命性创新的根本在于将逻辑和伦理以算法的形式植入,并产生新的数据,相当于为算法植入了思想和灵魂,尽管其智能水平与高水平人类仍有较大差距,但生成式AI在可无限扩展的算力和数据加持下,其成长性和发展前景将无比光明。
从2022年底至今,Chat GPT已经从3.0快速迭代到3.5,从3.5迭代到4.0,配合市场营销的宣传,ChatGPT已经成功打造了几个标签:
l 高富帅:超级算力+海量数据+机器学习+资本追捧
l 自学成才:自我学习,自我提升,快速进阶
l 会推理:读懂复杂问题,具备逻辑能力
0.2 Chat GPT为网安行业带来新的创新方向,也将引领新一轮投融资热潮
ChatGPT带来的网络安全问题也将被无限放大,微软近期推出Microsoft Security Copilot将下一代AI技术,使用其技术内置到网络安全系统中,微软将网络安全防护产品作为首个与ChatGPT能力结合的产品发布,就可以看到网络安全在人工智能领域的重要性,或者网络安全本身就是ChatGPT的一个场景应用。
0.2.1 攻击方发起网络攻击的门槛降低
尽管ChatGPT有内容审计,不提供完整的直接可用的网络攻击工具,但只要攻击者有一定专业技能,通过合理的提问编排,如与搜索引擎配合,网络攻击者可借助ChatGPT快速提升攻击能力和烈度,另外从攻击者的视角,任何一个点被攻破,都可以成为跳板,取得成效;笔者问了ChatGPT网络攻防方面的一些常规问题,回答的有模有样。
0.2.2 防守方合理使用ChatGPT可大幅减少安全运营工作量
运营方对自身IT资产及业务足够熟悉时,可以使用ChatGPT识别漏洞、编写安全运营自动化脚本、制定安全策略等,可在很大程度提升安全运营效率。ChatGPT作为网络安全攻防双方都可使用的工具,用在防守端可得到直接有效答案更方便,在内容审核方面ChatGPT对防守属性的内容更友好易用。ChatGPT作为安全攻防工具本身具有两面性,并将在某一时间点达到攻守的整体平衡,决定攻防态势的最终是人,由人来规划、建设和运营网络安全能力,对工具的使用熟练程度能在很大程度上起到提高效率的作用。
0.2.3 针对AI网络安全应用的投融资将呈现井喷效应
到2025年,人工智能(AI)软件市场规模将从2021年的330亿美元增长到640亿美元。网络安全将是人工智能支出增长最快的细分市场,相关支出的复合年增长率(CAGR)高达22.3%,Forrester发布该报告时ChatGPT尚未出现,经过验证后的Chat GPT将极大推动后续以人工智能和机器学习为支撑技术的网络安全市场进一步繁荣,在大规模资产探测、漏洞管理、异常行为检测等细分方向推出更强能力网络安全产品,配合零信任的安全框架,实现可落地的弹性、动态、智能的网络安全防护体系。
0.3 Chat GPT的广泛应用将推动数据安全需求升级
ChatGPT基于问题交互式学习进化的方式出现,相当于将传统网络安全和数据安全建立的内外网的网格彻底刺破,相当于ChatGPT在以回答问题的形式收集和分析数据,企业和个人以正常业务的形式持续流出重要数据。针对以ChatGPT为代表是生成式人工智能工具,在合规定义方面至少要加强隐私保护(个人隐私、企业隐私、国家隐私)、合规审计(规划、建设、运营)、伦理监管(内容监管、舆情监管、公信监管)几方面的研究和设计,而且这些合规细则的推出已经到了的急迫程度。
从攻防的角度看,是通过防御和反制攻击来保护数据的安全性,其价值在于保护组织的敏感信息和知识产权,减少业务中断和损失,并维护组织的声誉。ChatGPT出现后,可以作为工具同时服务攻防两端,能够熟练使用ChatGPT的一方将对不掌握该技能的一方形成绝对优势,已知的使用Chat GPT进行数据安全类的攻击手段就有社会工程渗透、脱库撞库攻击、规模制造虚假信息(水军)、恶意收集凭证/密码等身份信息等,虽然这些手段在Chat GPT出现之前就已经存在,但是在使用Chat GPT后,攻击效率可大大提高。这些需求升级将导致数据安全的规划和建设在元数据的处置时就入局,如进行数据资产的盘点、数据的分级分类、数据脱敏、数据传输/存储加密等细分技术和方案的快速落地。
数据安全在业务支持方面主要是指为业务需求提供安全保障,以确保数据的保密性、完整性和可用性,价值在于支持业务的联结和增长,提高组织的效率和竞争力。主要应用于金融、电力、电子商务、医疗保健等对数据安全敏感的行业和场景。在Chat GPT的能力加持下数据安全在业务端的能力将更多的体现在在业务逻辑中对钓鱼检测、撞库检测、凭证伪造检测、弱密码检测、可疑身份检测等日常高发、高危类安全行为方面;
综上,合规、攻防和业务支持是数据安全的三个刚性需求,它们的价值和场景均以保护数据为核心,企业和组织需要在这三个方面进行整合,形成一个全面的数据安全策略。ChatGPT的可怕之处在于系统和平台会以“吸星大法”式的模式采集、分析和验证数据,在专业能力达到一定程度的问题处置上,先以“莫须有”的形式和逻辑给出自己一套答案,在一步一步的交互过程中验证AI的理解,而且整个过程中相关人员几乎不会有产生数据安全威胁的意识,这与传统的钓鱼网站、钓鱼邮件类的数据安全问题,对企业的数据安全破坏程度更高。因此,一方面需要数据安全合规、攻防和业务支撑方面做到位,另一方面还需结合专项的数据安全意识类培训,自上向下进行安全意识的培训,从数据安全管理的角度,多管齐下,提升效果。
0.4欧洲刑警组织:ChatGPT很有可能被滥用于网络犯罪
3月27日,欧洲刑警组织创新实验室与相关专家组织了一系列研讨会,探讨犯罪分子会如何滥用 ChatGPT 等大型语言模型,以及它如何协助调查人员的日常工作。会议报告名为“ChatGPT - the impact of Large Language Models on Law Enforcement(ChatGPT - 大型语言模型对执法的影响)”,该报告概述了 ChatGPT 的潜在滥用,并展望了未来可能发生的事情。
欧洲刑警组织的专家们指出,ChatGPT可能为以下三个犯罪领域提供了便利:
1、欺诈和社会工程:ChatGPT高度逼真的文本生成能力使其成为网络钓鱼的有力工具。LLMs语言模式再现能力可用于模仿特定个人或群体的说话风格。
2、假情报:AI擅长快速批量生成真假难辨的声音文本,用户能够借以生成及传播特定叙述的信息,这使其非常适合宣传虚假信息。
3、网络犯罪:只要提供明确的需求,ChatGPT 就能够使用多种不同的编程语言生成用户所需的代码。对于欠缺技术知识的潜在犯罪分子来说,它就是生成恶意代码的有力工具。
欧洲刑警组织的报告旨在提高人们对LLMs潜在滥用的认识,与人工智能公司开展对话,帮助他们建立更好的保障措施,并促进安全可靠的人工智能系统的发展。报告中特别强调了执法机构需要了解这些技术的积极和消极应用,以便应对未来的挑战。可以看到,尽管目前AI的发展未臻完美,但其能力与日俱进,任何人都十分有必要提高对其的认知。
1. 多GPU并行训练
- 有两种原因:第一种是模型在一块GPU上放不下,两块或多块GPU上就能运行完整的模型(如早期的AlexNet)。第二种是多块GPU并行计算可以达到加速训练的效果。想要成为“炼丹大师“,多GPU并行训练是不可或缺的技能。
1.1 大模型训练-多GPU训练方法种类
常见的多GPU训练方法:
1.模型并行方式:如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
2.数据并行方式:将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。
1.1.1 两种GPU训练方法:DataParallel 和 DistributedDataParallel:
- DataParallel是单进程多线程的,仅仅能工作在单机中。而DistributedDataParallel是多进程的,可以工作在单机或多机器中。
- DataParallel通常会慢于DistributedDataParallel。所以目前主流的方法是DistributedDataParallel。
1.2 误差梯度如何在不同设备之间通信?
在每个GPU训练step结束后,将每块GPU的损失梯度求平均,而不是每块GPU各计算各的。
1.3 BN如何在不同设备之间同步?
假设batch_size=2,每个GPU计算的均值和方差都针对这两个样本而言的。而BN的特性是:batch_size越大,均值和方差越接近与整个数据集的均值和方差,效果越好。使用多块GPU时,会计算每个BN层在所有设备上输入的均值和方差。如果GPU1和GPU2都分别得到两个特征层,那么两块GPU一共计算4个特征层的均值和方差,可以认为batch_size=4。注意:如果不用同步BN,而是每个设备计算自己的批次数据的均值方差,效果与单GPU一致,仅仅能提升训练速度;如果使用同步BN,效果会有一定提升,但是会损失一部分并行速度。
2. 预训练模型发展历程

- 第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
- 第二阶段 :逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
- 第三阶段 :走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
3. 面向预训练语言模型的Prompt-Tuning技术发展历程
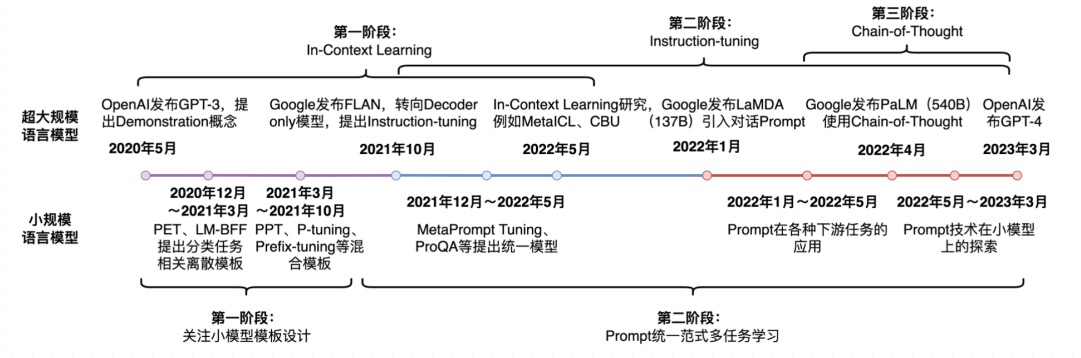
- Prompt-Tuning自从GPT-3被提出以来,从传统的离散、连续的Prompt的构建、走向面向超大规模模型的In-Context Learning、Instruction-tuning和Chain-of-Thought。
- 自从GPT、EMLO、BERT的相继提出,以Pre-training + Fine-tuning 的模式在诸多自然语言处理(NLP)任务中被广泛使用,其先在Pre-training阶段通过一个模型在大规模无监督语料上预先训练一个 预训练语言模型(Pre-trained Language Model,PLM) ,然后在Fine-tuning阶段基于训练好的语言模型在具体的下游任务上再次进行 微调(Fine-tuning) ,以获得适应下游任务的模型。




![复现永恒之蓝[MS17_010]](https://img-blog.csdnimg.cn/2aabf4266cfd48ec97163506dae89ea5.png)