机器学习目录
2.1 探索性数据分析
2.2 数据清理
2.3 数据变换
2.4 特征工程
2.5 数据科学家的日常
Stanford University Practical machine learning
2.1 探索性数据分析
对目标的ftr数据进行处理,针对不同的信息做出不同的图形
输出数据集的行数和列数以及前十行元素
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消控制台输出行限制
pd.set_option('display.max_columns',None) #取消控制台输出列限制
pd.set_option('display.width',50000) #增加控制台输出每行的宽度
data = pd.read_feather('DataSet/house_sales.ftr')
#Let's check the data shape and the first a few examples
print(data.shape) #(行数,列数) shape[0]是行数 shape[1]是列数
print(data.head()) #前n行数据,默认前5行
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wD7SyZPM-1682338484127)(LiMu.assets/image-20230423081824914.png)]](https://img-blog.csdnimg.cn/7c51da2f58dc4a7388bc9f1a2fdc8cef.png)
删除百分之三十数据为空的列
#Warning: drop will delete data
#We drop columns that at least 30% values are null to simplify our EDA.
null_sum = data.isnull().sum()
print(data.columns[null_sum < len(data) * 0.3]) # columns will keep
谨慎运行,这个会删除数据集中的数据
控制台打印数据集的数据类型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消控制台输出行限制
pd.set_option('display.max_columns',None) #取消控制台输出列限制
pd.set_option('display.width',50000) #增加控制台输出每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Next we check the data types
print(data.dtypes)
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o30n7qvm-1682338484129)(LiMu.assets/image-20230423090558793.png)]](https://img-blog.csdnimg.cn/6e4c55621d43458b99250d2302400cfc.png)
我们可以看到很多数据的数据类型是
不正常的,这里我们对部分数据做数据类型的转换
对部分数据的数据类型进行转换操作
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None)#取消行限制
pd.set_option('display.max_columns',None)#取消列限制
pd.set_option('display.width',50000)#增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#Next we check the data types
print(data.dtypes)
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZV0lE3RN-1682338484130)(LiMu.assets/image-20230423091907691.png)]](https://img-blog.csdnimg.cn/725958e9f10d4ef7a95e72ccb0c4ec6c.png)
分析数值类型的数据信息
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None)#取消行限制
pd.set_option('display.max_columns',None)#取消列限制
pd.set_option('display.width',50000)#增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#Now we can check values of the numerical columns. You could see the min and max values for several columns do not make sense.
print(data.describe())
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AfspVG1H-1682338484131)(LiMu.assets/image-20230423092921912.png)]](https://img-blog.csdnimg.cn/758bdfaeecce4aca9b8c17fead9d39da.png)
对于其中的一些数据来说,最大值和最小值是没有意义的
筛选掉居住面积小于10或者大于1e4的房子
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None)#取消行限制
pd.set_option('display.max_columns',None)#取消列限制
pd.set_option('display.width',50000)#增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
print(sum(abnormal)) #输出不符合条件的数量
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gKvm5s9Z-1682338484131)(LiMu.assets/image-20230423094009508.png)]](https://img-blog.csdnimg.cn/f60d1036267b4a2d9f40ae5a71e1194a.png)
制作房子价格和数量的直方图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None)#取消行限制
pd.set_option('display.max_columns',None)#取消列限制
pd.set_option('display.width',50000)#增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
#Let's check the histogram of the 'Sold Price', which is the target we want to predict.
ax = sns.histplot(np.log10(data['Sold Price']))
ax.set_xlim([3,8]) #设置图形x轴的长度
ax.set_xticks(range(3, 9)) #列表的元素为图形的ticks的位置
ax.set_xticklabels(['%.0e'%a for a in 10**ax.get_xticks()]); #X轴的名称
plt.show();
输出图形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ghbcfiFI-1682338484132)(LiMu.assets/image-20230423100811825.png)]](https://img-blog.csdnimg.cn/4b049577f8794f09a2f94f837de368e7.png)
查询数量最多的二十种房子的类型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消行限制
pd.set_option('display.max_columns',None) #取消列限制
pd.set_option('display.width',50000) #增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
#A house has different types. Here are the top 20 types:
print(data['Type'].value_counts()[0:20])
print_line()
控制台输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-obtuwH72-1682338484132)(LiMu.assets/image-20230423102521950.png)]](https://img-blog.csdnimg.cn/036a4aa6aba54661b9262f2ec2f27d54.png)
制作每种房子价格和密度的关系图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消行限制
pd.set_option('display.max_columns',None) #取消列限制
pd.set_option('display.width',50000) #增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
#Price density for different house types.
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
sns.displot(pd.DataFrame({'Sold Price':np.log10(data[types]['Sold Price']),
'Type':data[types]['Type']}),
x = 'Sold Price', hue = 'Type', kind='kde')
plt.show()
输出图形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JwfLprKD-1682338484133)(LiMu.assets/image-20230423104859102.png)]](https://img-blog.csdnimg.cn/472606a76a304dc7b2f2a3f5060623fd.png)
制作房子类型和每英尺价格的箱线图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消行限制
pd.set_option('display.max_columns',None) #取消列限制
pd.set_option('display.width',50000) #增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
#Another important measurement is the sale price per living sqft. Let's check the differences between different house types.
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
ax = sns.boxplot(x = 'Type', y = 'Price per living sqft', data = data[types], fliersize = 0)
ax.set_ylim([0, 2000]);
plt.show();
输出图形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sJzEvEn1-1682338484134)(LiMu.assets/image-20230423110956767.png)]](https://img-blog.csdnimg.cn/1da597a6d9c647269f38a37a8446ef36.png)
制作房子邮政编码和每英寸价格的箱线图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消行限制
pd.set_option('display.max_columns',None) #取消列限制
pd.set_option('display.width',50000) #增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
#We know the location affect the price. Let's check the price for the top 20 zip codes.
d = data[data['Zip'].isin(data['Zip'].value_counts()[:20].keys())]
ax = sns.boxplot(x = 'Zip', y = 'Price per living sqft', data = d, fliersize = 0)
ax.set_ylim([0, 2000])
ax.set_xticklabels(ax.get_xticklabels(), rotation = 90)
plt.show()
输出图形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rG6DKurW-1682338484134)(LiMu.assets/image-20230423112408389.png)]](https://img-blog.csdnimg.cn/6da03238495c4a75b5046b0dac15484a.png)
制作房子价格、挂牌价格、年纳税额和每英尺的价格相关矩阵
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
pd.set_option('display.max_rows',None) #取消行限制
pd.set_option('display.max_columns',None) #取消列限制
pd.set_option('display.width',50000) #增加每行的宽度
data = pd.read_feather('..\DataSet\house_sales.ftr')
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal] #把筛选条件取反
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
#Last, we visualize the correlation matrix of several columns.
_, ax = plt.subplots(figsize=(4, 4))
columns = ['Sold Price', 'Listed Price', 'Annual tax amount', 'Price per living sqft']
sns.heatmap(data[columns].corr(),annot=True,cmap='RdYlGn', ax=ax)
plt.show()
输出图形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8OXGelj7-1682338484135)(LiMu.assets/the correlation matrix of several columns..png)]](https://img-blog.csdnimg.cn/891706392c724121bd3b4eb6c40fe8a0.png)
完整代码
#课程PPT链接:https://c.d2l.ai/stanford-cs329p/_static/notebooks/cs329p_notebook_eda.slides.html#/import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython import display
display.set_matplotlib_formats('svg')
# import matplotlib_inline
# matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def print_line():
print('-' * 200)
#设置显示行数
np.set_printoptions(threshold=np.inf) # np.inf表示正无穷
#如果报错,请安装 pyarrow
# pd.set_option('display.max_columns', 5000)
# pd.set_option('display.width', 5000)
# pd.set_option('display.max_colwidth', 5000)
pd.set_option('display.max_rows',None)#取消行限制
pd.set_option('display.max_columns',None)#取消列限制
pd.set_option('display.width',1000)#增加每行的宽度
data = pd.read_feather('DataSet/house_sales.ftr')
#Let's check the data shape and the first a few examples
print(data.shape) #(行数,列数) shape[0]是行数 shape[1]是列数
print(data.head()) #前n行数据,默认前5行
print_line()
#Warning: drop will delete data
#We drop columns that at least 30% values are null to simplify our EDA.
# null_sum = data.isnull().sum()
# print(data.columns[null_sum < len(data) * 0.3]) # columns will keep
#Next we check the data types
print(data.dtypes)
print_line()
#Convert currency from string format such as $1,000,000 to float.
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace( #三个符号转成空,空字符串转nan
r'^\s*$', np.nan, regex=True).astype(float)
#???
#Also convert areas from string format such as 1000 sqft and 1 Acres to float as well.
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
#Now we can check values of the numerical columns. You could see the min and max values for several columns do not make sense.
print(data.describe())
print_line()
#We filter out houses whose living areas are too small or too hard to simplify the visualization later.
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal]
print(sum(abnormal))
print_line()
#Let's check the histogram of the 'Sold Price', which is the target we want to predict.
ax = sns.histplot(np.log10(data['Sold Price']))
ax.set_xlim([3,8]) #设置图形x轴的长度
ax.set_xticks(range(3, 9)) #列表的元素为图形的ticks的位置
ax.set_xticklabels(['%.0e'%a for a in 10**ax.get_xticks()]); #X轴的名称
plt.show();
#A house has different types. Here are the top 20 types:
print(data['Type'].value_counts()[0:20])
print_line()
#Price density for different house types.
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
sns.displot(pd.DataFrame({'Sold Price':np.log10(data[types]['Sold Price']),
'Type':data[types]['Type']}),
x = 'Sold Price', hue = 'Type', kind='kde')
plt.show()
#Another important measurement is the sale price per living sqft. Let's check the differences between different house types.
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
ax = sns.boxplot(x = 'Type', y = 'Price per living sqft', data = data[types], fliersize = 0)
ax.set_ylim([0, 2000]);
plt.show();
#We know the location affect the price. Let's check the price for the top 20 zip codes.
d = data[data['Zip'].isin(data['Zip'].value_counts()[:20].keys())]
ax = sns.boxplot(x = 'Zip', y = 'Price per living sqft', data = d, fliersize = 0)
ax.set_ylim([0, 2000])
ax.set_xticklabels(ax.get_xticklabels(), rotation = 90)
plt.show()
#Last, we visualize the correlation matrix of several columns.
_, ax = plt.subplots(figsize=(8, 8))
columns = ['Sold Price', 'Listed Price', 'Annual tax amount', 'Price per living sqft', 'Elementary School Score', 'High School Score']
sns.heatmap(data[columns].corr(),annot=True,cmap='RdYlGn', ax=ax)
plt.show()
2.2 数据清理
数据的错误
- 收集到的数据与真实观测值不一致【数值丢失,数值错误,极端的值】
- 好的模型对错误是有容忍度的【给了错误的数据一样是能够收敛但是精度会比用干净的数据低一点】
- 部署了这样的模型后可能会影响新收集来的数据结果
数据错误的类型
- 数据中某个样本的数值不在正常的分布区间中(Outlier)
- 违背了规则(Rule violations)
- 违反了语法上或语义上的限制(Pattern violations)
对数值的变换

- 把一个列里面的数值的最小值与最大值都限定到一个固定区间内,然后把所有的元素只通过线性变化出来【将数据的单位放到合理的区间】;
- Z-score 一个更常见的算法:通过算法使得均值变为0,方差变为1
- 把一列的数据换成是-1到1之间的数据
- 对数值都是大于0,且数值变换比较大可以试一下log一下【log上面的加减等于原始数据的乘除,可以将计算基于百分比的】。
对图片的变换:

- 将图片的尺寸变小【机器学习对低分辨率的图片不在意】
- 图片采样的比较小,且jpeg选用中等质量压缩,可能会导致精度有1%的下降(ImageNet)【数据的大小与质量要做权衡】
对视频的变换:

- 使用短视频(10s以内),将视频切到感兴趣的部分;
对文本的变换:

- 词根化(语法化):把一个词变成常见的形式
- 词元化(机器学习算法中最小的单元)
2.4 特征工程
为什么需要特征工程:
因为机器学习的算法比较喜欢定义的比较好的、它能比较好的去处理的、固定长度的输入输出。
对表的数据

- 对于整型或浮点型的数据,可以直接用或者是把最大最小值拿出来,再把这个数据分成n个区间,如果值在区间中,则会给它对应区间的下标i【这样可以让机器学习算法不去纠结一个具体的值(细粒度的值)】
- 对于类别的数据,一般采用one-hot(独热)编码(虽然有n列,但是只有每一列有值)【虽然有很多的类别但是常见的只有几个类,可以将少数的类别变成不确定的类别,只保留那些比较重要的类别,这样可以把这些重要的类别放到可控的单元内】
- 对于时间的特征,将时间的数据弄成机器学习算法能知道这些天数中是有特殊意义的日子(周末、休息日、新年之类的)
- 特征组合:这样子能拿到两两特征之间相关性的东西
对文本的数据
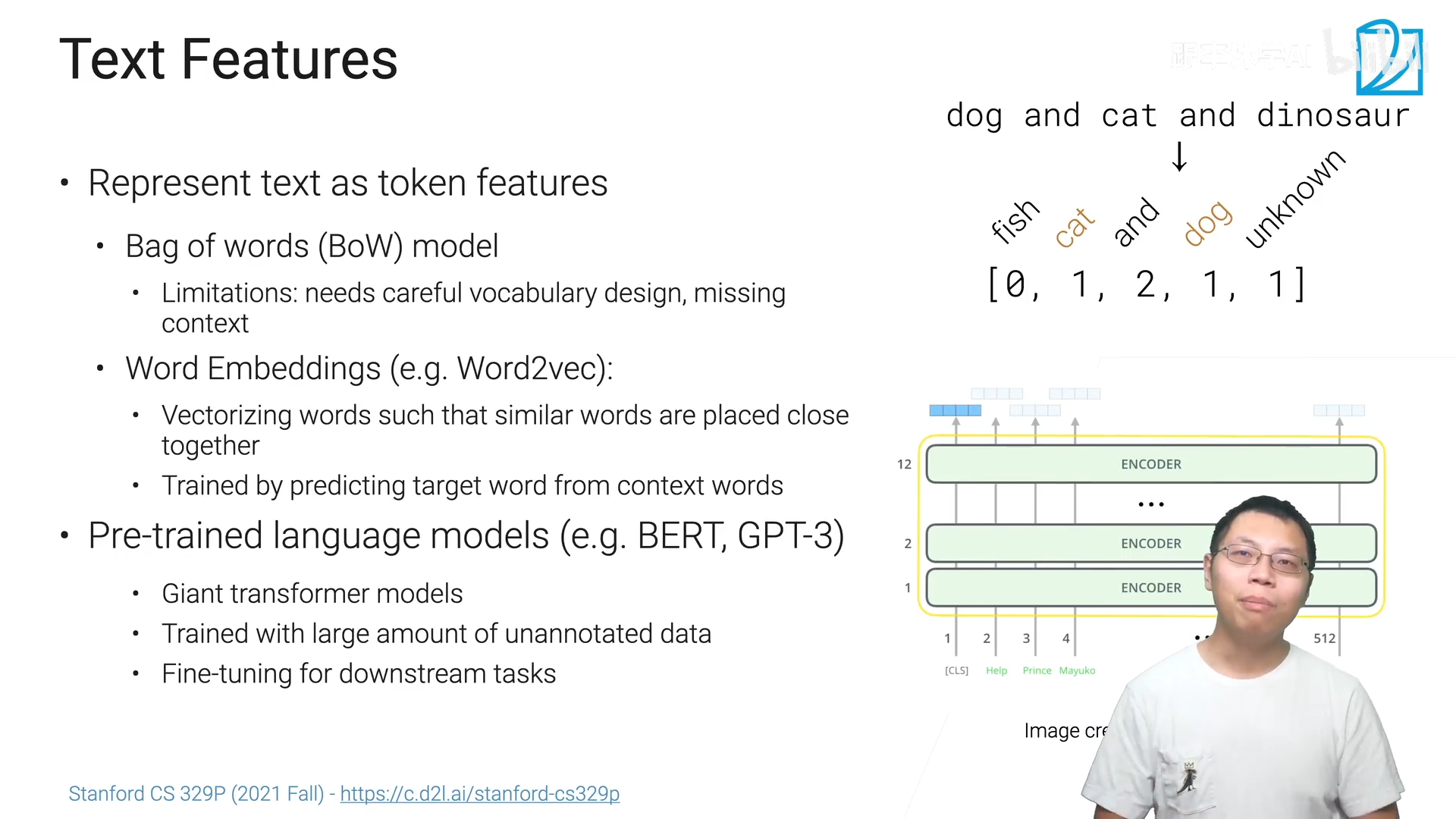
- 可以将文本换成一些词元(token)
- Bag of woeds(BoW) model:把每一个词元(token)弄成one-hot编码,再把句子里的所有词元加起来【这里要注意的是 怎么样把词典构造出来,不能太大也不能太小;BoW model最大的问题在于原句子的信息丢失了】。
- Word Embeddings(词嵌入):将词变成一个向量,向量之间具有一定的语义性的(两个词之间对应的向量之间的内积比较近的话,说明这两个词在语义上来说是比较相近的)
- 可以使用预训练的模型(BERT,GPT-3)
对于图片与视频

- 传统是用手动的特征方式如SIFT来做
- 现在用预训练好的深度神经网络来做(ResNet,I3D)
2.5 数据科学家的日常
要启动一个机器学习任务
- 有没有足够的数据? 没有的话就去收集数据【发掘在哪里找数据;数据增强;生成自己需要的数据;(以上方法都不可以可能这个任务不那么适合机器学习)】
- 对数据进行提升。 标号?数据质量?模型?
- 对模型之后会展开
- 提升标号:没有标号可以去标;标号里面有很多错误的话,要对它进行清理;【数据标注:半监督学习;有钱可以众包;看看数据长什么样子,找其他的规则,从数据中提起有弱噪音的标号,也是可以用来训练模型的】
- 数据预处理:看看数据长什么样子;通常来说数据是有很多噪音的,要对数据清洗;将数据变成我们需要的格式;特征工程;
- 上面的过程可以说是一个迭代的过程;
挑战

- 数据的质与量要做权衡;
- 数据质量:
- 数据的多样性:产品所关心的方方面面都要考虑;
- 无偏差:数据不能只是偏向于一个方面
- 公平性:不区别对待数据
- 大数据的管理是一件很难的事情:存储;快速处理;版本控制;数据安全。