PIP:
https://github.com/apache/pulsar/issues/19744
具体设计
-
每个TC维护一个Map<ClientName,List> terminatedTxnMetaMap,维护每个客户端最新N个事务的状态,事务结束前,会把事务元数据写入这个List里,同时写入一个Compacted topic(persistent://pulsar/system/_terminated_txn_state${TCid})里持久化,Compacted topic的key为ClientName,从而能自动删除旧的事务元数据。
-
TC recovery时从Compacted topic里恢复维护的事务状态信息。
-
可以考虑只保留aborted的事务状态,committed状态的事务不用保留,那么如果找不到事务元数据时,默认是committed的事务。
为了避免用户不清楚pulsar能提供的能力,导致丢数时抱怨pulsar侧不抛错,这里还是选择同时保留committed、aborted的事务,如果在Preserver找不到事务元数据时仍然会抛出TransactionNotFound错误。 -
为了避免某个clientName废弃了,导致对应的事务元数据一直不清除,开启一个定时任务来清除内存中过期的事务元数据。
-
__terminated_txn_state_${TCid}的创建利用topic自动创建机制,因此分区数、是否为分区topic由broker.conf对应的配置决定,这个跟__transaction_buffer的机制是相同的。为__terminated_txn_state_${TCid}开启compaction也是类似的机制,persistent://pulsar/system/__terminated_txn_state_${TCid}是系统topic,默认强制开启compaction机制。
-
TransactionMetadataPreserver的实现不需要进行并发控制,因为操作都是在单线程池里执行。replay方法在TransactionMetadataStoreService的单线程池里执行,append、flush、expireTransactionMetadata方法在MLTransactionMetadataStore里的单线程池里执行。
-
batch跟key机制不相容。batch的第一条消息的key被视为是整个batch消息的key,因此开启batch机制会让compaction机制执行错误。如果开启key based batching机制可以保证同一个batch里的key都相同,但是针对compaction机制而言,同一个key的消息只有最新一条消息是有效的,因此还不如通过代码逻辑去避免无效消息的发送。因此设计流程如下:
变成aborting后修改内存数据,并记录将要发送消息的key;然后发送指令给tb,执行成功后会尝试变成aborted,但是变成aborted之前先清除事务元数据里的分区信息,然后遍历将要发送消息的key,同步发送到__terminated_txn_state。这样就可以压缩一下相同key的消息量了,而且避免了batch机制。 -
如果代码逻辑链路如下:
写日志条目,更新状态为Aborted -> 成功写入__terminated_txn_state -> 删除日志
则如果在 写日志条目,更新状态为Aborted -> 成功写入__terminated_txn_state 中间挂掉,recovey扫描日志时会直接把事务变成aborted,而不会写入__terminated_txn_state。因此要保证 成功写入__terminated_txn_state 在 写日志条目 之前。
因为成功写入__terminated_txn_state 在更新事务状态为ABORTED之前,因此写入的事务元数据是aborting,因此对于Preserver保存的事务数据,我们应当视aborting等同于aborted,因为aborting的事务最终只可能为aborted,而如果到了查询Preserver里的数据的逻辑,那此时肯定已经抛出TransactionNotFound错误,已经删除掉对应的事务元数据了,因此此时肯定是aborted了。
- 因为一旦对某个事务调用append方法,后面就可能立刻flush到__terminated_txn_state里,因此要保证append到Preserver在内存更新状态为 aborting后面,不然的话topic里的事务元数据可能为OPEN状态,如果只存储aborted事务数据倒还好,无所属事务状态,如果把committed的事务数据也存储进来,那么就很有所谓了,因此为了向前兼容,这里也应该要保证
append到Preserver在内存更新状态为 aborting后面。
因此整条链路如下: OPEN状态 -> 把aborting log entry写入tc log -> 内存更新状态为 aborting -> append到Preserver -> 发送指令给TB、TP -> flush元数据到__terminated_txn_state -> 把aborted log entry写入tc log -> 内存更新状态为aborted
整条链路的每个步骤都是幂等的,因此能保证是幂等的。
- 关注一下recover完成后的逻辑是否正确:由于 recover时不调用Preserver的逻辑 ,open状态不用分析,aborted也不用分析,因为已经走完流程了。那么分析一下aborting的事务, aborting的事务可能对TB发送过endTxn指令,可能写入元数据到__terminated_txn_state里,也可能都没有。 recoverTracker会对aborting事务重新abort,因此会重新触发上面两个步骤,因为它们也保证幂等的,因此能保证行为正确。
注记:recovery后的事务状态,如果为OPEN,则肯定没走到把aborting log entry写入tc log这一步;如果为ABORTING,则至少走完了把aborting log entry写入tc log,最多不会走到把aborted log entry写入tc log;如果为Aborted,则至少走完了把aborted log entry写入tc log。
-
序列化事务元数据时,其实只需要把事务ID号序列化即可,因此数据量是很小的,这里实现时顺便把事务状态也序列化了。至于其他成员数据量比较大,如分区信息,都不序列化。因此TransactionMetaPersistCount的上限,瓶颈不在于读写__terminated_txn_state,而在于维护太多事务元数据,对内存的占用。
-
在要变成aborted之前,可以把分区信息给清除掉,降低内存占用。因为tc发送给tb的命令肯定执行成功了。删除分区信息后立马写入topic。写入成功才变成aborted。分区信息为空列表后,后面再次触发endTxnInTransactionBuffer会直接返回成功。
-
实际保存的事务量:因为客户端在创建事务时,实际上是按round robin模式选TC的,比如说默认创建16个TC,则会轮询使用16个TC来服务它。如果TC Preserver设置TransactionMetaPersistCount为5,则实际上服务端侧会为客户端保存5*16=80个最近完成的事务元数据,如果单个客户端的事务吞吐量为5txn/s,那么TC Preserver仅能为客户端保存80/5=16s时间范围内的事务元数据。
但是也会有异常情况,如果集群异常,最终只有一个TC能提供服务,那么就只能保存5个最近的事务状态了,当然这是极端异常的情况了。 -
客户端侧不可避免地需要实现一套commit/abort失败后自动重试commit/abort的机制,虽然对于某些报错,如TransactionCoordinatorNotFound、TransactionPreserverClosed错误,客户端在接收到这两种错误类型时会自动重新发送请求给broker,但是对于其他报错类型是直接返回给用户的,如PulsarClientException.TimeoutException,超过一定时间请求没有响应客户端也会收到报错,这种情况下用户实际上是不知道事务的真实状态的,因此必须要重试commit。尽管把operation timeout调大可以规避这个报错,但是这会影响到客户端的其他行为,因此,客户端侧不可避免地需要实现一套重试commit/abort的机制。
-
该模块依赖topic compaction,依靠topic compaction机制来读取同一个clientName的最新一份事务元数据,如果滚动重启时从__terminated_txn_state读数据时无法保证是最新的,那么就可能报TransactionNotFound错误。因此需要保证从__terminated_txn_state读取数据时是跟写入顺序一致的。
因为无论是RoundRobinPartition还是SinglePartition路由模式,只要消息带上了Key,则消息都会根据Key的hash值来选取分区,因此同一个client的事务元数据都会发往同一个分区,因此我们只需要保证消息发送是同步的即可。
实验也证明了这一点:

-
目前TC log batch功能有问题,开启后会导致事务状态发生回滚,从而导致丢数,目前先禁用,对性能影响也不大。
https://github.com/apache/pulsar/issues/20150
增加配置
服务端配置
@FieldContext(
category = CATEGORY_TRANSACTION,
doc = "Max number of txnMeta of aborted transaction to persist in broker."
+ "If the number of aborted transaction is greater than this value, the oldest aborted transaction will be "
+ "removed from the cache and persisted in the store."
+ "default value is 0, disable persistence of aborted transaction."
)
private int TransactionMetaPersistCount = 0;
@FieldContext(
category = CATEGORY_TRANSACTION,
doc = "Time in hour to persist the transaction metadata in TransactionMetadataPreserver."
)
private long TransactionMetaPersistTimeInHour = 72;
@FieldContext(
category = CATEGORY_TRANSACTION,
doc = "Interval in seconds to check the expired transaction in TransactionMetadataPreserver."
)
private long TransactionMetaExpireCheckIntervalInSecond = 300;
- TransactionMetaPersistCount暂定为5,即整个集群正常情况下能为每个客户端保存5*16=80个已完成的事务元数据。
- TransactionMetaPersistTimeInHour为72,即超过3天的事务元数据会被定时任务自动删除掉。
- TransactionMetaExpireCheckIntervalInSecond为300,即检查过期事务元数据的定时任务每5min执行一次检查。
- __terminated_txn_state 的分区数待定,根据集群的事务吞吐量来决定,而且这个可以动态进行扩分区。
客户端配置
@ApiModelProperty(
name = "clientName",
value = "Client name that is used to save transaction metadata."
)
private String clientName;
修改传输协议
enum ServerError {
...
TransactionPreserverClosed = 26; // Transaction metadata preserver is closed
}
message CommandNewTxn {
required uint64 request_id = 1;
optional uint64 txn_ttl_seconds = 2 [default = 0];
optional uint64 tc_id = 3 [default = 0];
optional string client_name = 4;
}
message CommandEndTxn {
required uint64 request_id = 1;
optional uint64 txnid_least_bits = 2 [default = 0];
optional uint64 txnid_most_bits = 3 [default = 0];
optional TxnAction txn_action = 4;
optional string client_name = 5;
}
message TransactionMetadataEntry {
...
optional string clientName = 12;
}
异常处理
注记:记当前分析的commit报错的事务对应的checkpoint为checkpoint n,要回滚的话,就回滚到 checkpoint n-1。
Pulsar侧commit失败时可能的错误类型:
-
TransactionNotFound:事务元数据已经被删除了,Pulsar侧不确定事务最终状态,可能committed,也可能是aborted。
- 策略1:flink catch到该异常直接终止任务,此时pulsar侧人工介入排查,通过人工读取topic信息来获取事务真实状态,如果是committed就忽略;如果是aborted就从checkpoint n-1恢复重新执行即可。但是用户不一定能接受任务的终止,而且pulsar侧人工介入排查也需要耗费不短时间,因为需要扫描大量的数据,这会对用户方的任务造成较长的不可用时间,而且无法保证一定能找到该事务的数据。因此不采纳。
- 策略2:仿照Kafka的行为,忽略该报错并打日志,或者再加一个监控,让用户知道有丢数风险。同样地这也是极端中的极端情况了,有了Pulsar幂等性功能不应该出现这种报错。
-
InvalidTxnStatusException:重新commit已经被超时aborted的事务,flink需要抛出该异常,从checkpoint n-1恢复重新执行即可保证一致性。
注记:不可能重新abort已经被committed的事务,因为flink侧不会对一个事务调用一下commit,再调用一下abort。 -
TimeoutException:请求超时,这种错误重启Flink任务重新commit即可,或者不重启任务直接重试commit即可。
-
其他错误类型:重启Flink任务重新commit即可,因为Pulsar滚动重启过程中commit可能产生各种报错,但是只要服务恢复正常重试commit就能成功。
测试
一致性测试
压测的场景是:只有事务Producer的场景,当然Flink+Pulsar也是只用到事务Producer。
下面结果是使用下面压测工具完成的。
https://github.com/apache/pulsar/pull/19781
配置:单个client,TransactionMetaPersistCount为1000,__terminated_txn_state分区数为1。
此时事务吞吐量为800txn/s。
那么可以分析一下,这个配置下能为客户端保存多长时间范围内的事务元数据?因为客户端在创建事务时,实际上是按round robin模式选TC的,比如说默认创建16个TC,则会轮询使用16个TC来服务它。如果TC Preserver设置TransactionMetaPersistCount为2,则实际上服务端侧会为客户端保存2*16个最近完成的事务元数据。
因此,当前配置会为客户端保存1000*16=16000条元数据,吞吐量为800txn/s,则能保存16000/800=20s的事务元数据。
| 测试情景 | 结果 |
|---|---|
| 无干扰 | 1e条无重复无丢失 |
| 滚动重启一次 | 1e条无重复无丢失 |
| 宕机不可用时间5min | 1e条无丢失,重复一个事务的数据,即800条。排查发现原因是:该事务元数据找不到,即TransactionNotFoundException。因此保存20s的事务元数据还不够,需要保存更多数据才能避免报TransactionNotFoundException错误。 |
注记:因为宕机时间长达5min,为了模拟Flink的使用场景,这里事务超时时间设为10min;因为Pulsar客户端对发出去的请求还会有一个超时时间限制,即operation-timeout,默认为30s,超过这个时间请求没有响应也会报错,要避免这个报错可以把operation-timeout也调为10min,比宕机时间长即可,或者客户端有重试请求的机制,则也可以不设置该配置,遇到这个报错客户端重试commit即可。当前Flink commit遇到报错会重启任务重新commit,因此是可以不设置operation-timeout的。
下面把TransactionMetaPersistCount调大为2000,继续测试。
配置:单个client,TransactionMetaPersistCount为2000,__terminated_txn_state分区数为1。
但是事务吞吐量下降为500。(后续可以调大__terminated_txn_state分区数来优化,而且TransactionMetaPersistCount实际使用不能调这么大,也不能让用户搞这么高的事务吞吐量,单个客户端事务并发量高的话还可以调小compaction的时间间隔来减少recovery时读取的数据量,从而加快recovery,这里测试优先关注数据的一致性,暂时不考虑其他的)
根据上面信息可知,当前能保存2000*16/500=64s时间范围内的事务元数据。
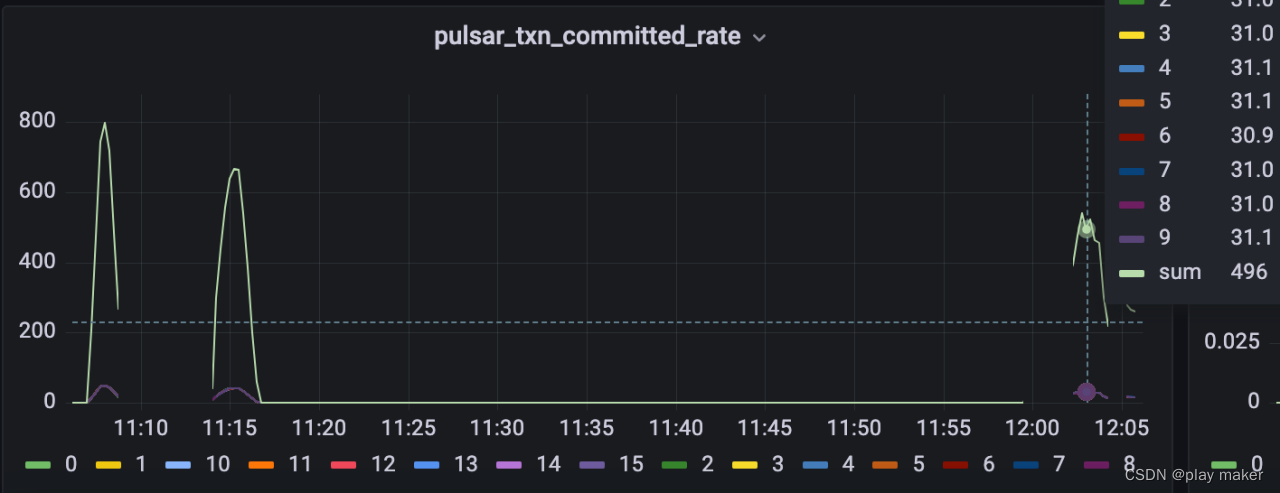
| 测试情景 | 结果 |
|---|---|
| 宕机不可用时间5min | 1e条无重复无丢失 |
| 滚动重启10次 | 10e条无重复无丢失 |
以上实验重复多次,均通过一致性检验,无重复、无丢失。
性能测试
两步拆分的压缩效果
分成两步的消息压缩效果如下:
总共完成了125000个事务。
2023-04-18T12:18:50,999+0800 [Thread-0] INFO org.apache.pulsar.testclient.PerformanceProducer - --- Transaction : 125000 transaction end successfully - -- 2 transaction end failed --- 125002 transaction open successfully --- 5 transaction open failed --- 0.001 Txn/s
cat logs/pulsar-broker-sg-testhdfs-dn6.bigdata.bigo.inner.out.1 | grep -a "No need to flush transaction" | wc -l

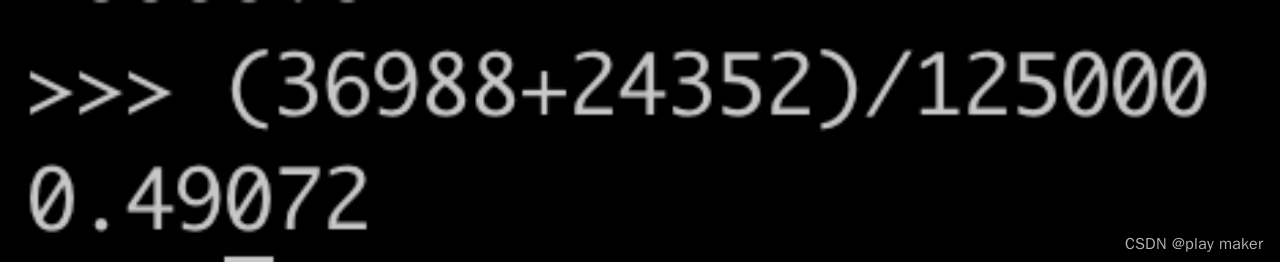
把49.07%的消息量给压缩掉了。
多次测试下来,能把25%~60%的消息给压缩掉,当然这是在客户端高事务并发量的情况下的结果,低并发的情况下压缩效果应该会差很多。
内存占用分析
一个事务元数据大概按400byte来算。
估算一下的话,如果每个TC为client保存5个事务元数据,那么10w个客户端就会消耗190M,即每个TC需要消耗190M内存。

但是整个集群有16个TC,因为有16个TC轮询给客户端提供服务,因此实际上整个集群会为一个客户端保存5*16=80个事务元数据。
那么整个集群需要消耗190M*16=3G的内存。
注记:因为一个broker是可能加载多个TC的,因此可能出现极端情况:16个TC都加载到同一个broker上了,那么内存消耗全部由一个broker来承担,因此就会有OOM的风险,因此有必要在负载均衡策略上对于TC的分配上尽量均衡。当前是根据hash进行随机分配的,因此目前没有影响。