Spark计算速度
- Hadoop的多个job之间的数据通信是基于磁盘的
Hadoop偏存储,其MR框架,是基于磁盘的计算,多个MR作业之间的数据交互,依赖于磁盘的IO,这会影响计算性能。
job1:读取磁盘文件,MR计算,结果存储到磁盘
job2:读取磁盘的job1结果,迭代计算,结果继续存储到磁盘 - Spark的多个job之间的数据通信是基于内存的
Spark是基于内存的计算,中间过程直接缓存在内存中,计算完成后,才会把最终结果存储到磁盘。所以Spark的计算速度比Hadoop快很多,但对资源的要求也比较高。
job1:读取磁盘文件,Spark计算,结果缓存到内存
job2:直接对job1的结果进行迭代计算,计算完成后,结果存储到磁盘
Spark核心模块

- Spark SQL:操作结构化数据的组件,通过Spark SQL,用户可以用sql、hql查询数据
- Spark Streaming:操作实时数据的流式计算组件,提供了处理数据流的各种API
- Spark MLlib:机器学习算法库
- Spark Graphx:图计算的算法库
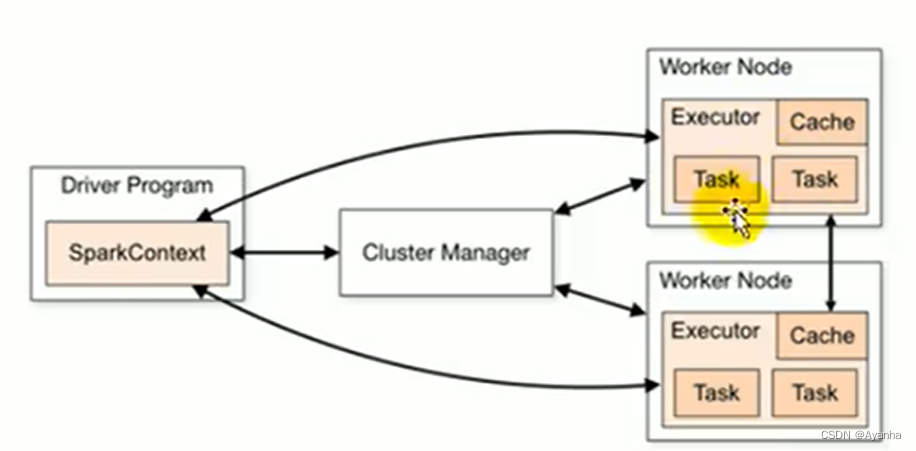
Spark核心组件
- Master:负责资源调度分配、集群监控的进程
- Worker:运行任务的进程,一个Worker会运行在集群中的一个服务器上,由Master为其分配资源,来运行task
- ApplicationMaster:Driver通过ApplicationMaster向Master申请程序执行的资源容器,便于将各个程序的运行、监控、错误处理等独立管控
- Driver:驱动组件,使整个程序运行起来
- Executer:执行组件,是集群工作节点worker中的一个JMV进程,负责执行任务task(任务之间相互独立),然后将任务结果反馈给Driver。若一个Executer崩溃了,其中出错的任务节点会调度到另一个Executer上继续运行。Executer还会给程序中要求缓存的RDD提供内存式存储(RDD直接缓存在进程内,所以任务在运行时可以充分利用缓存数据加速运算)
Excuter的配置参数:
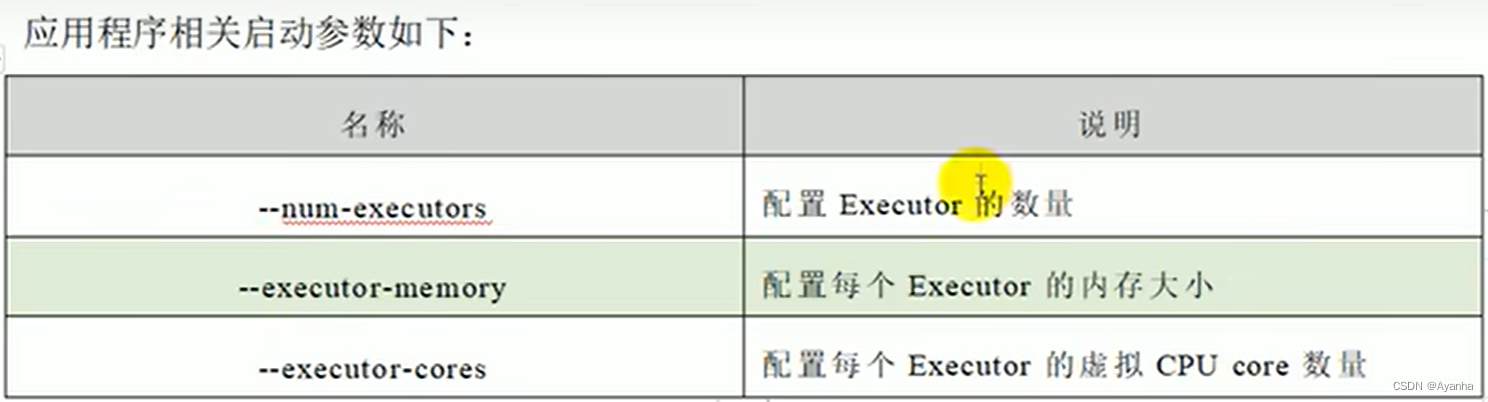
每个Excuter的虚拟CPU core:指的是并发度,即一个核分为n个虚拟核进行资源分配使用
并行度:一个程序在集群上的同时执行的任务数量,即Excuter的数量
![[附源码]SSM计算机毕业设计校园自行车租售管理系统JAVA](https://img-blog.csdnimg.cn/a249e16921784f4091bad90ad92a747d.png)







![解决nginx: [emerg] unknown directive “stream“ in /etc/nginx/nginx.conf问题](https://img-blog.csdnimg.cn/18c00def152f4c959ad63991439232dd.png)
