文章目录
- 前言
- 一、DBNet多分类
- 二、步骤
- 1.训练、训练模型推理、模型转换
- 2.通过推理模型进行推理
- 三、解决思路
- 1、查看模型
- 2、tools/infer/predict_det.py修改
- 3、utility.py修改
- 总结
前言
最近涉及到了身份证识别,为了便于匹配识别结果的属性,如姓名、身份证号、地址等,便想到在dbnet的基础上加个分类的分支,本篇便用于记录过程中遇到的bug。
一、DBNet多分类
当自己产生这个想法的时候,先通过度娘查看了一下是否有实现的案例,结果发现已有大佬实现,所以就直接参考大佬的代码进行了修改,参考链接为:DBNet多分类。这个想法可以适应于身份证、银行卡等证件的识别。
二、步骤
1.训练、训练模型推理、模型转换
根据上文提到的链接或者PaddleOCR里的PaddleOCR/applications/快速构建卡证类OCR.md进行代码修改即可,亲测可行。
2.通过推理模型进行推理

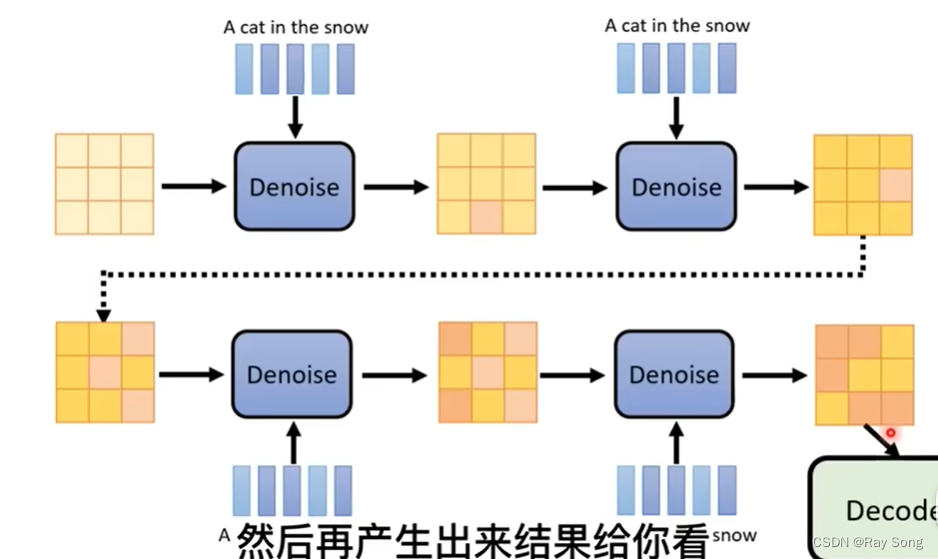
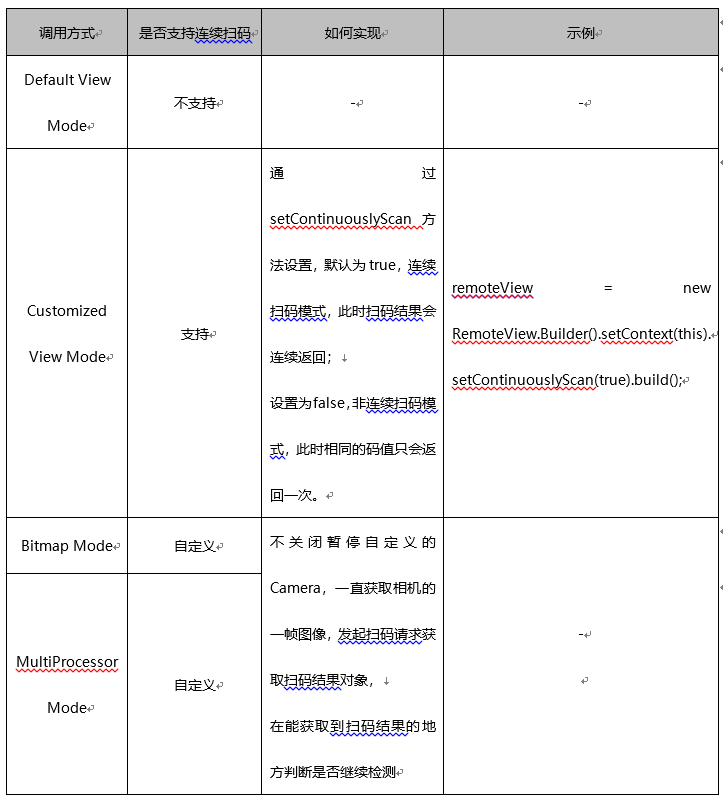
这里直接运行的话,虽然不会报错,但是推理的结果可能不尽人意,如下图(图片是自己合成的,忽略信息):

从上图可见,框的位置不对,并且没有显示类别,我想实现的结果为:

那么如何达到我的目标呢?解决方案继续往下看。
三、解决思路
1、查看模型
刚开始,想的是自己的模型转换不对,便用netron查看了转换后的模型,netron网页版网址为:netron
如果你的模型打开后是这样的

那说明你的模型有问题,先去用自己的训练模型去推理,看结果是否正确。如果你的模型是这样:

那说明你的模型转换也是对的,请继续往下走。
2、tools/infer/predict_det.py修改
首先我们在大约250行左右输出下outputs,如图:
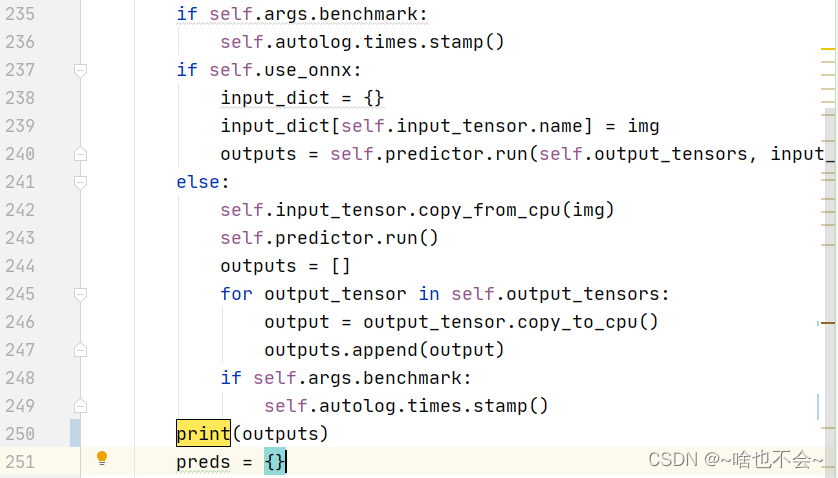
输出结果如下:

运行结果中看,我们有2个输出,那说明成功了一半。第一个输出类型为int,而我们在二、1中改的代码中class分支的输出为int类型,由此猜想,是不是第一个输出为分类的,第二个是dbnet的。再结合我们的结构图:

由此,我们可以将第一个输出定为class分支,第二个输出定为dbent的,所以有如下更改:

这里修改完成后,后处理的输入就之前我们改的部分就对应上了,拿到后处理的结果后,只需要按照如上方式,对展示部分进行修改即可,如下:
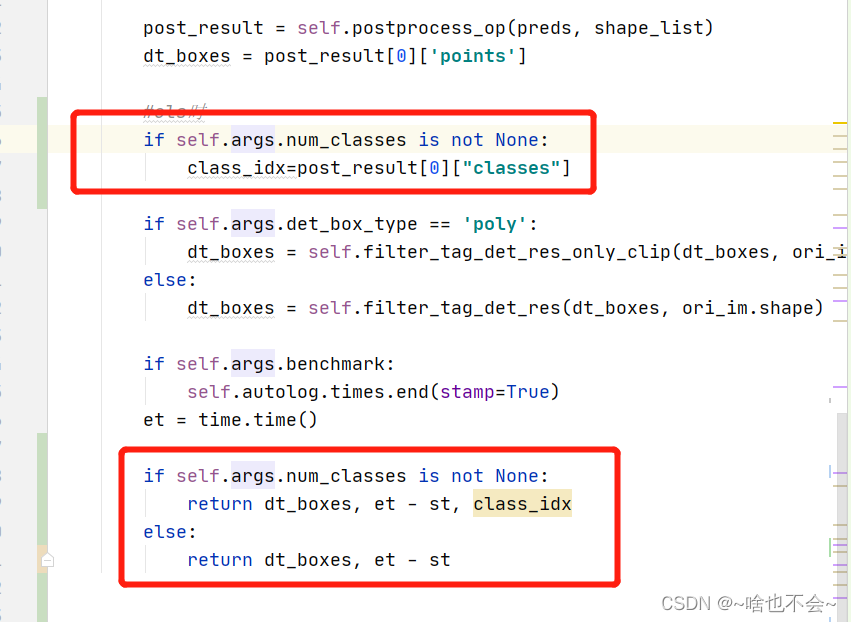
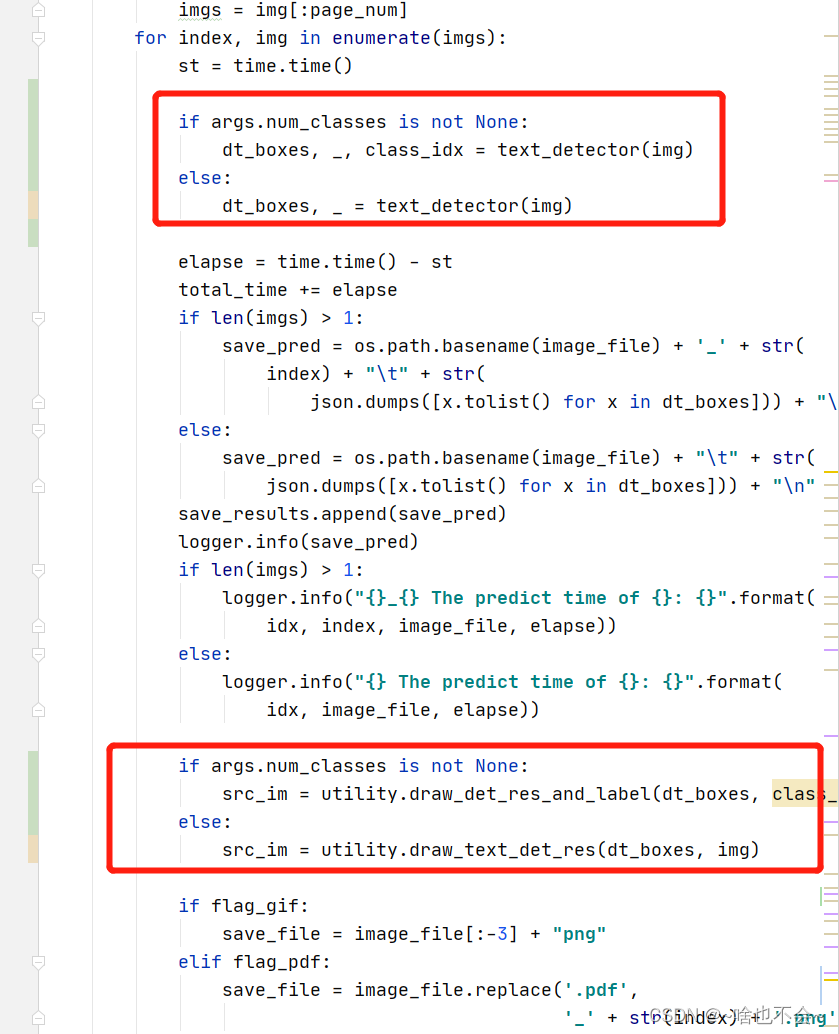
其中用到的draw_det_res_and_label()函数和args.num_classes等均在下一步呈现。
3、utility.py修改
首先我们需要增加两个参数,如下:

这里类别数和类别标签文件路径都改为自己的即可,当不想展示类别时,将num_classes的默认值改为None即可。其次,我们还需要添加一个用于可视化结果的函数,和原来的进行区分开:如下:
def draw_det_res_and_label(dt_boxes, classes, label_file_path, img):
label_list = label_file_path
labels = []
if label_list is not None:
if isinstance(label_list, str):
with open(label_list, "r+", encoding="utf-8") as f:
for line in f.readlines():
labels.append(line.replace("\n", ""))
else:
labels = label_list
if len(dt_boxes) > 0:
import cv2
index = 0
src_im = img
for box in dt_boxes:
box = box.astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(src_im, [box], True, color=(255, 255, 0), thickness=2)
font = cv2.FONT_HERSHEY_SIMPLEX
src_im = cv2.putText(src_im, labels[classes[index]], (box[0][0][0], box[0][0][1]), font, 0.5, (255, 0, 0), 1)
index += 1
return src_im
改到这里就OK了,大家可以去亲自实践下。
总结
这就是本篇的全部内容,如果有自己理解错误的地方,烦请评论区指正,最后再次感谢大佬的贡献,https://blog.csdn.net/YY007H/article/details/124491217