1. 前置知识
目前通用的图像生成模型一般包含三个组件:
- Text Encoder 根据文字生成向量
- 生成模型 根据向量和Noise 生成 缩小版本的图像
- Image Decoder 根据小分辨率图像生成大分辨率图像


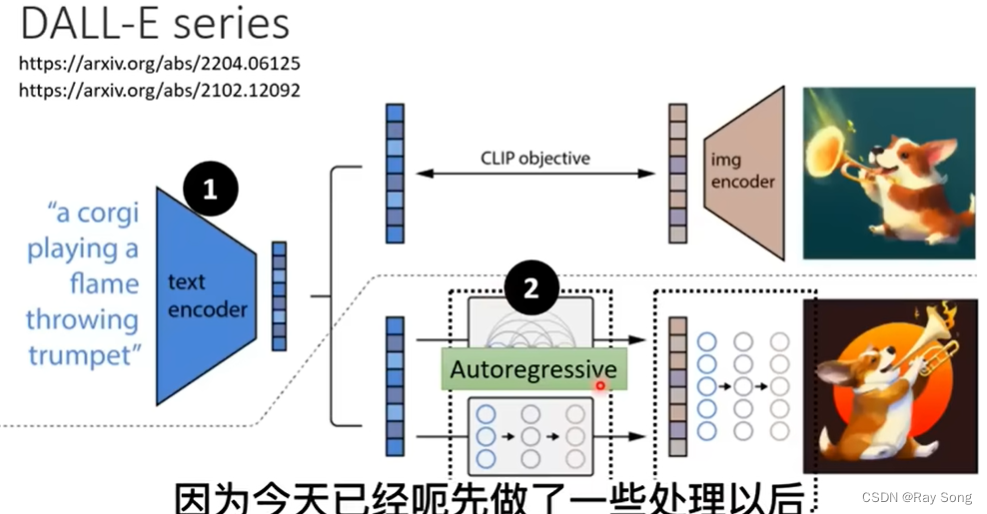
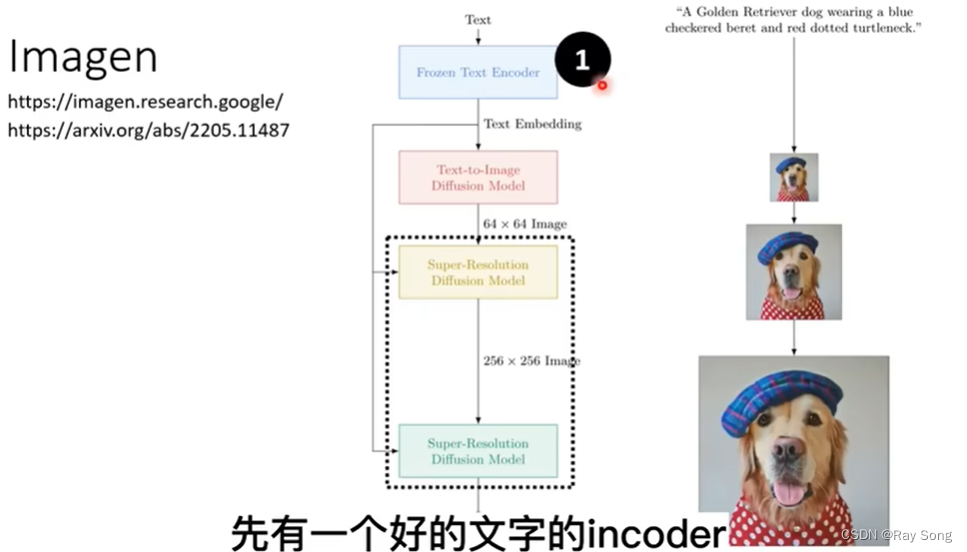
2. Text Encoder
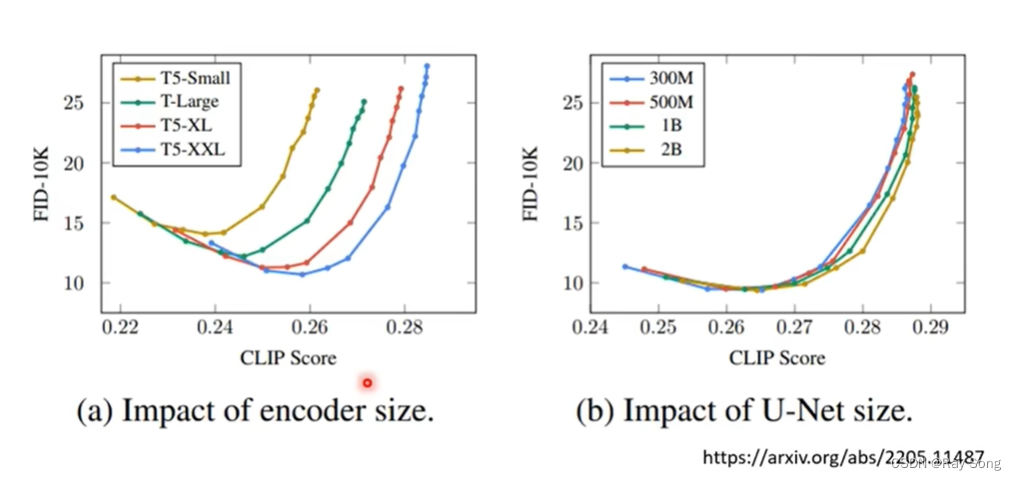
文字的Encoder对于结果的影响很大,增大Diffusion Model对结果的影响比较有限。
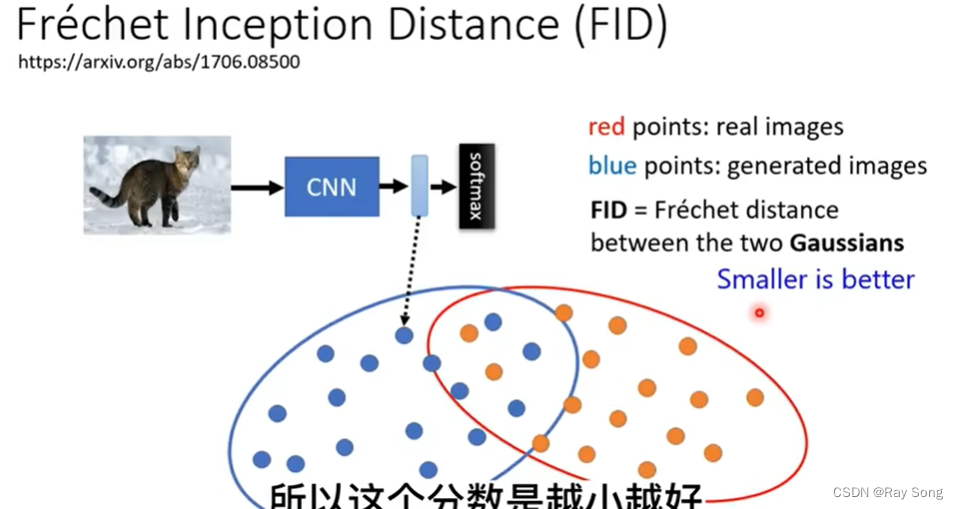
FID : 衡量一个图像好坏的一个标准,需要sample很多的Image进行标准衡量
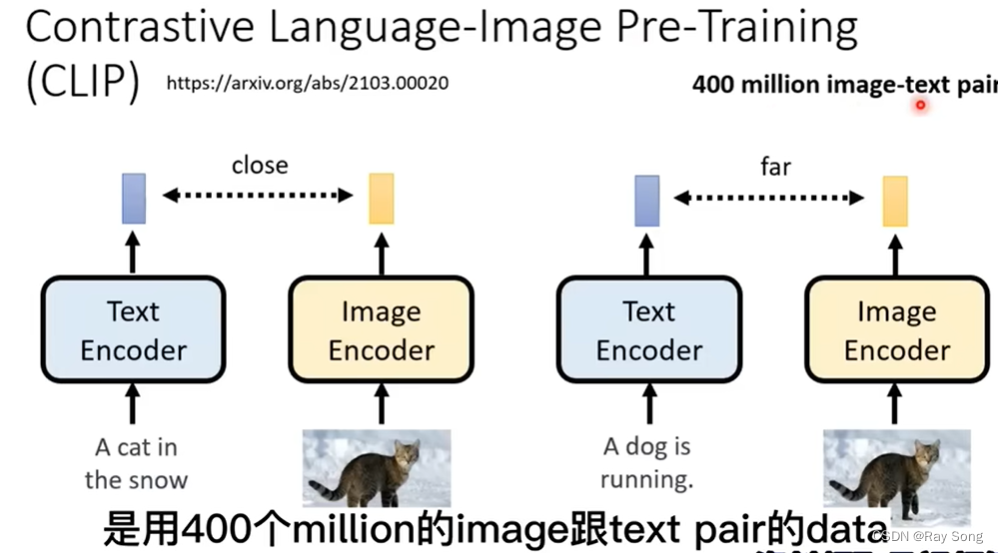
CLIP-Score : 也是一个衡量标准,如下图,两个encoder生成出来的向量距离远近
3. Decoder
额外的Decoder不需要piar的资料,只需要图像就可以把Decoder训练出来
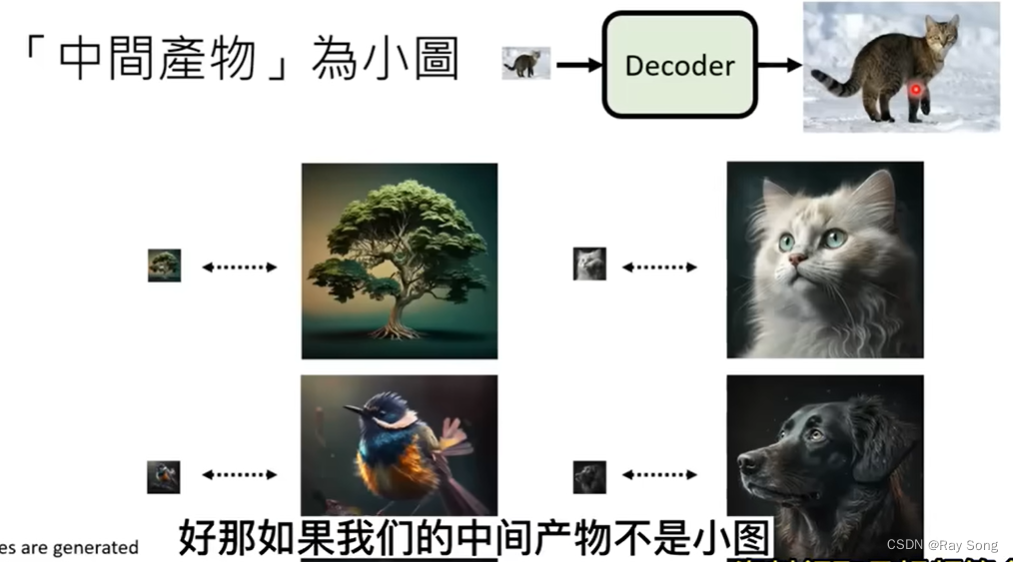
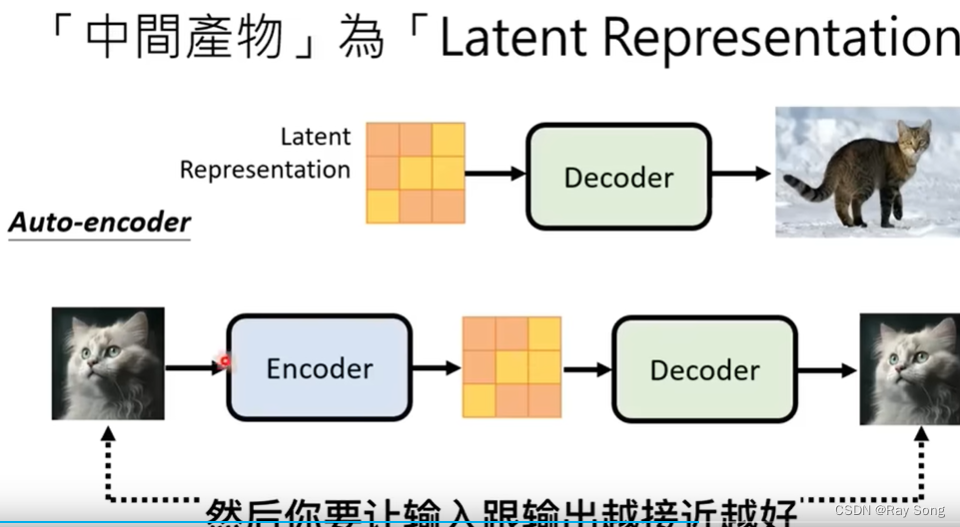
Imagen用到就是把小图当作中间产物,Stable Diffusion和DALL-E把latent representation当作中间产物
4. Generative Model
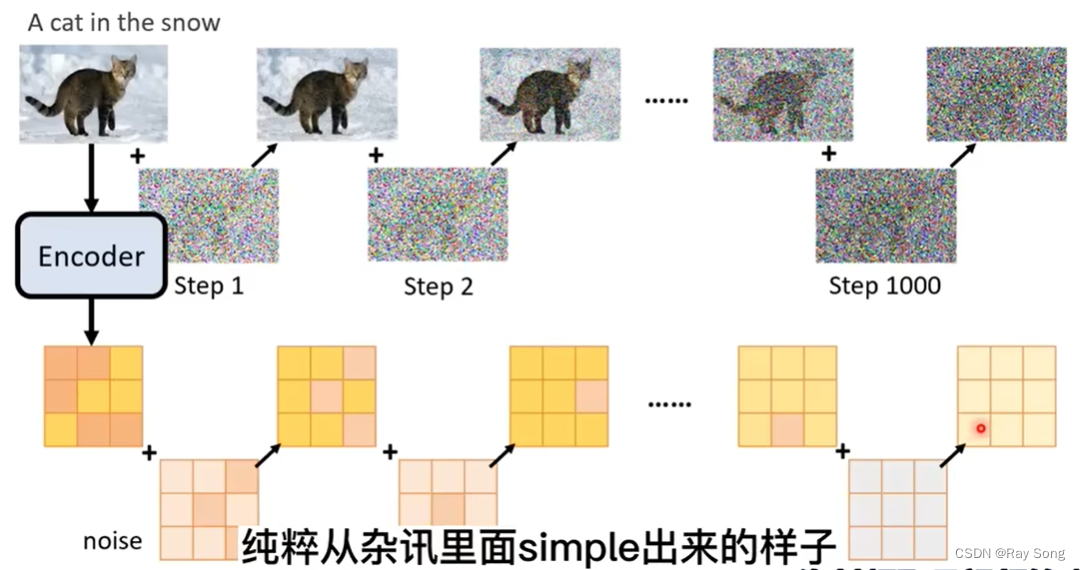
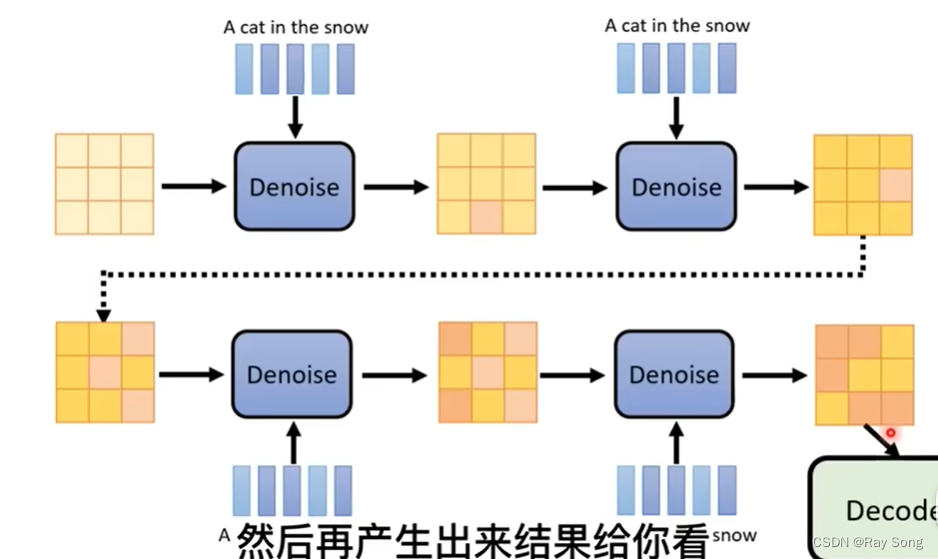
Midjourney 生图的时候,从模糊到清楚,其原理就是把每次Denoise的中间产物经过Decoder再次加工,所以可以看到比较清楚,而不是噪声