参考资料:
[MLIR] CodeGen Pipeline总结 - 知乎 (zhihu.com)
本文主要以 tensorflow 为例,介绍了其接入 MLIR 后的 CodeGen 过程,以及简要分析了一些现在常用的 CodeGen pipeline。本文是本人在结合博客(Codegen Dialect Overview - MLIR - LLVM Discussion Forums)以及相关资料而写成,主体内容来源于翻译。

现状
Classification
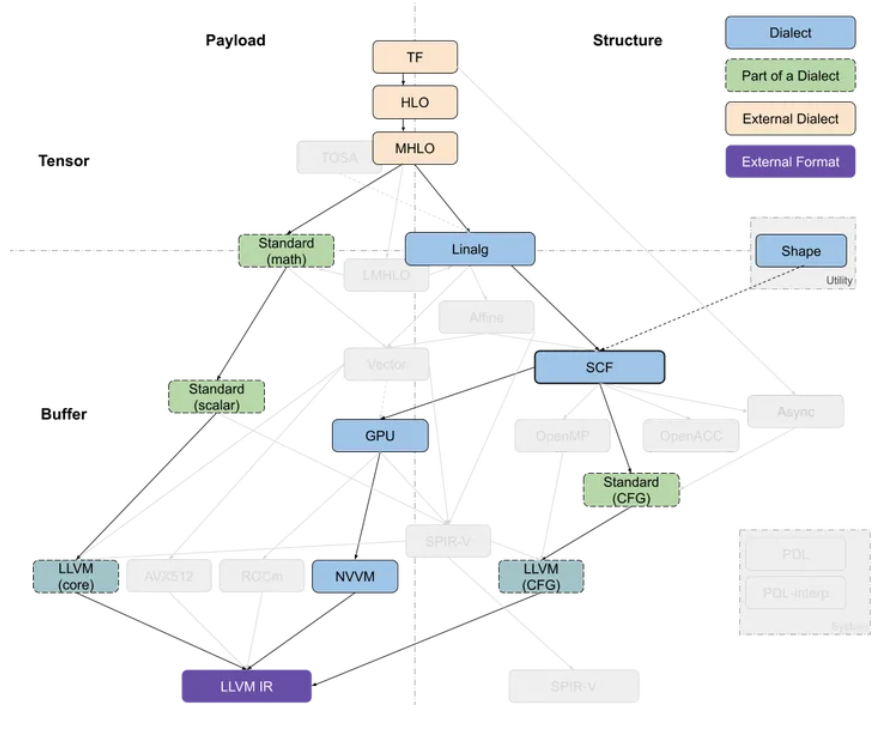
MLIR 中与代码生成相关的 dialects 大致可以沿着两个轴进行分解:tensor/buffer 和 payload/structure。
简单来说,MLIR是一种编译器中间表示语言,它可以帮助我们更好地处理机器学习代码。在MLIR中,dialects是指不同的语言方言,可以分为tensor/buffer和payload/structure两个方面。tensor/buffer主要是指不同的数据类型和内存管理方式,payload/structure则是指不同的计算操作和执行方式。这些dialects之间存在相互依存的关系,它们共同构成了MLIR的多层次抽象结构。
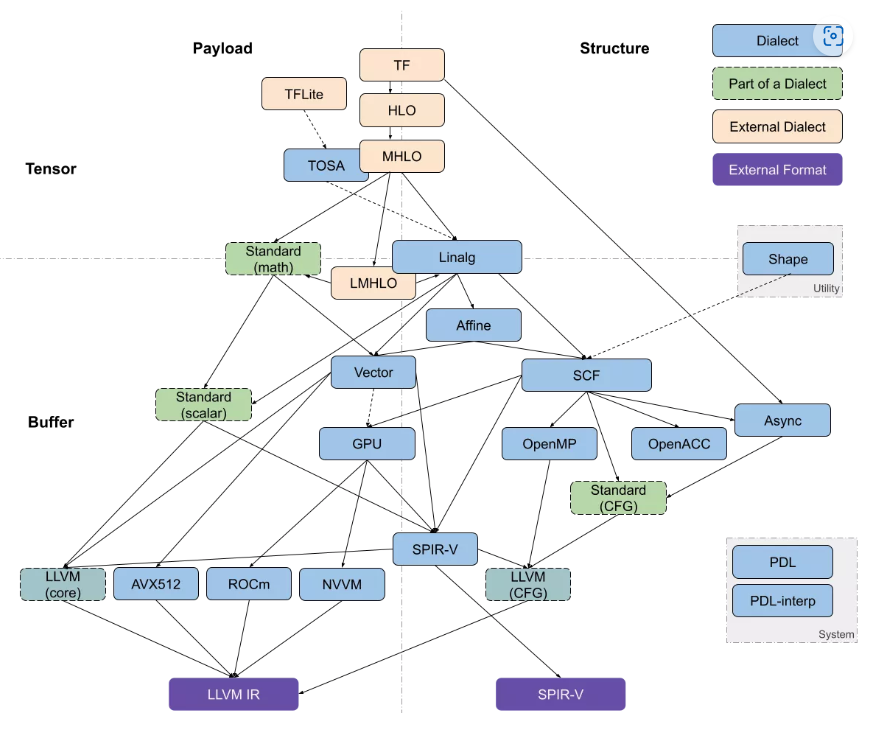
Dialects of Interest
我们写机器学习代码时,我们通常会使用高级别的数据结构,比如tensor。但是,这些高级别的结构不能直接在硬件上执行,需要经过一些中间步骤将它们转换为低级别的表示形式,比如buffer。这些中间步骤通常涉及到dialects,也就是不同的语言方言。在转换的过程中,我们会使用最近引入的dialects,也就是最适合当前转换的语言方言。这些dialects的目的是将高级别的结构转换为低级别的表示形式,以便最终在硬件上执行。
"Dialects" 是 MLIR 中的一个概念,它可以根据它所抽象的特征的级别来组织成一个堆栈,就像一个抽象的塔一样。在这个堆栈中,越高级别的抽象表示越抽象,越低级别的抽象表示越接近实际的底层实现。将较高级别的抽象表示向下转化成较低级别的抽象表示通常比较容易,因为较低级别的抽象已经包含了较高级别抽象的所有特征,相当于是将抽象的东西转化为更具体的东西。但是,反过来将较低级别的抽象表示提升到较高级别的抽象表示通常比较困难,因为较低级别的抽象不一定包含较高级别抽象的所有特征,需要通过一些复杂的技术和算法来推导和计算出来。
在编译器一系列转换程序的过程中,越来越多的高层次的简明信息被打散,转换为低层次的细碎指令,这个过程被称为代码表示递降
lowerinng,与之相反的过程被称为代码表示递升raising。raising远比lowering困难,因为需要在庞杂的细节中找出宏观脉络。
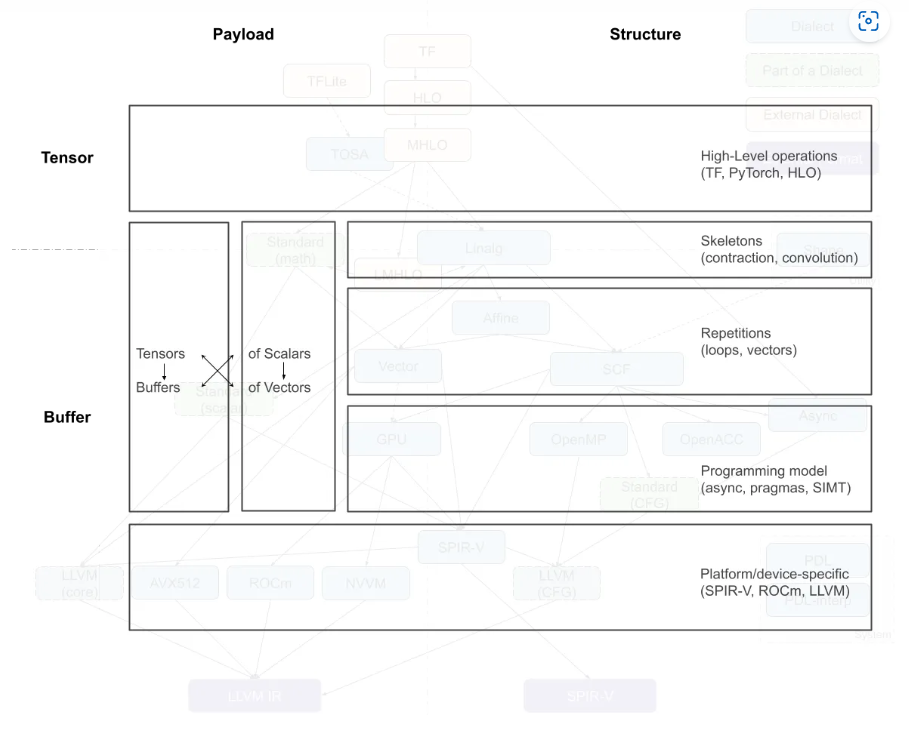
在MLIR中,我们可以使用不同的“方言”(即不同的语言变体)来表示不同的操作和计算。
其中,Linalg方言是用于表示结构化计算的一种方言,它支持使用通用的表示形式来表示结构化数据上的结构化计算,并且支持在不改变操作本身的情况下将tensor转换为buffer。此外,Linalg方言还提供了一些特定的操作(如矩阵乘法和卷积),以及用于定义结构的通用操作。这些操作可以相互转换,并且可以通过迭代结构转换为向量操作或循环操作。这些特性使得Linalg方言非常适合于编译器的优化和代码生成。
Async Dialect 是一个用于编写异步代码的工具集合,可以帮助程序员在不同的层次上表示异步计算。它可以在高层次上组织大型计算块,例如跨多个设备的计算任务,同时在低层次上包装基本的指令序列。在异步编程中,我们经常需要协调多个任务之间的执行,因为这些任务的执行可能是不确定的或者受到其他任务的影响。Async Dialect 提供了一种基于异步计算块的方式来组织这些任务,并且可以在这些计算块之间建立依赖关系来协调它们的执行顺序。除此之外,Async Dialect 还提供了一些原语来处理异步计算的基本操作,例如异步等待、异步执行和取消异步任务等。这些原语可以在低层次上包装成指令序列,使得程序员可以直接使用它们来编写异步代码。
后面还有很多的dialect。
一些现存的 pipelines
TensorFlow Kernel Generator
IREE Compiler (LLVM Target)
IREE Compiler (SPIR-V Target)
Polyhedral Compiler
分析
1111111111111111111