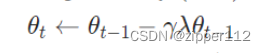文章目录
- Adagrad
- SGD
- RMSprop
- Adam
- AdamW
Adagrad
Adagrad是一种可以自动调节每个参数更新的梯度的优化器,也可以做到在梯度平缓时走的步长大,在梯度小时走的步长小,从而防止loss出现剧烈震荡的情况。这里默认你已知道了他的原理了,如果不知道可以看李宏毅老师的课。以下优化器也同理。
先看Adagrad的Pytorch的计算公式:

t表示时间,也就是step的次数。可以看到,学习率
γ
\gamma
γ是会随着t的增加而越来越小的,也就是学习率会逐渐地衰减。
然后就是
g
t
g_t
gt的计算,可以发现他加上了一项
λ
θ
t
\lambda \theta_t
λθt这就是L2正则项了,也就是Weight Decay。需要注意的是偏置
b
b
b是不用计算weight decay的
然后就是
s
t
a
t
e
_
s
u
m
t
state\_sum_{t}
state_sumt就是正常的计算,他计算就是以前+现在每一时刻梯度平方和。
最后计算时分母上加了一个
ϵ
\epsilon
ϵ就是eps了,这是为了防止分母为0出现无穷大。

接下来说主要的参数,上面其实也已经标明了
- params:网络的所有参数
- lr: 初始学习率
- lr_decay: 学习率随step衰减速度,越小衰减越慢,如果等于0,则不衰减。
- weight_decay: L2正则权重,越大的话,正则惩罚力度越大
- eps: 计算自适应梯度时分母上的平滑项,防止梯度趋于无穷
- maximize: 如果设置为True,就会变成梯度上升,而不是梯度下降(其实给loss加个负号也能实现)
SGD
SGD是最经典的优化器,也就是随机梯度下降

我们来看Pytorch的计算公式
- 首先计算梯度 g t g_t gt
- 然后加上L2正则 λ θ t \lambda \theta_t λθt
- 然后计算momentum,也就是 b t b_t bt,其中τ的作用是控制对动量的依赖
- 然后判断是否要计算Nesterov 动量
- 最后判断是否为梯度上升,还是梯度下降

1 . params:网络的所有参数
2 . lr: 初始学习率
3 . momentum: 控制对动量的依赖程度,如果越大,则动量参与的权重也就越大
4 . dampening: 控制梯度的参与程度,如果越大,梯度参与的越少
5 . nesterov: 计算nesterov 动量详情见文章
6 .maximize: 如果设置为True,就会变成梯度上升,而不是梯度下降
RMSprop

RMSprop修改了求自适应梯度的算法,Adagrad在求梯度时平等的考虑了所有历史的梯度,但是这可能会影响后续的计算所以RMSprop又给加了一个权重,用于削弱太久远的梯度对最近梯度的影响。
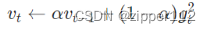
其中上图的
α
\alpha
α就是用来削弱这个影响的,其余的计算都大同小异
alpha: 平滑常数,越大话月考虑以往的梯度对梯度自适应的影响
momentum: 设置动量的影响, 越大的话动量的影响程度越大
weight_decay : L2正则系数,同上
Adam

Adam在RMSprop上新增了梯度平滑和偏差修正。
这里的梯度平滑看起来很像momentum,但其实不是,因为momentum是不需要除以平方和开根号项的
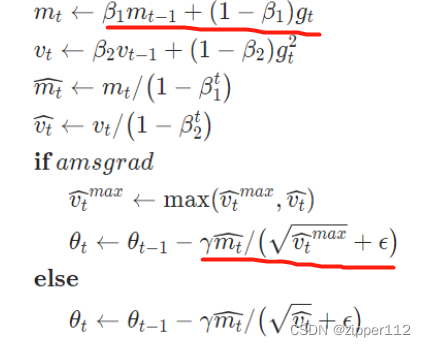
所以这里其实是和把以往梯度和现在的梯度做了一个平均化,也有类似momentum的效果。
然后平方和向
v
t
v_t
vt和RMSprop一样,然后就是两个偏差修正
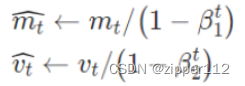
这两个是为了防止一开始梯度为0的情况出现,因为
β
1
,
β
2
\beta_1,\beta_2
β1,β2是比较接近于1的。
betas :即上述的两个beta
amsgrad :用于计算ams梯度,如果启用的话,每次都会使用历史平方和最大的那个作为分母
AdamW

AdamW与Adam基本类似,但它的效果一般更好,他做出了一个比较重要的改变,那就是吧weight decay给抽离出来,不让其参加自适应grad和平均梯度的计算,因为weight decay提供的信息与梯度无关,会造成干扰。
所以直接单独吧weight decay减到
θ
\theta
θ上即可