目录
前言
文献阅读:基于ARIMA-WOA-LSTM模型的空气污染物预测
背景
ARIMA-WOA-LSTM模型
思路
主要贡献
积分移动平均自回归 (ARIMA)
鲸鱼优化算法
搜索超参数
CEEMDAN
结论
LSTM-Kriging
主要目标
理论猜想
问1:克里金插值中的半方差函数拟合方法是什么?
问2:可以用LSTM来替换克里金插值中的半方差函数拟合嘛?
问3:那应该怎么做?
总结
前言
This week I studied an article which proposed an accurate method for predicting air pollutants, aiming to ensure the efficiency of air pollution control. The ARIMA-WOA-LSTM model was presented, which uses ARIMA to extract the linear part of air pollutant data and outputs the non-linear part, while WOA-LSTM model is used to predict the non-linear part. The whale optimization algorithm is utilized to find the optimal hyperparameters of LSTM, including the number of neurons and modeling of learning rate and batch length. In addition, I have some new hypotheses about kriging interpolation.
本周我学习了一篇文章。在这篇文章中,作者提出了一种准确预测空气污染物的方法,目的是确保空气污染管理的效率。提出的ARIMA-WOA-LSTM模型使用ARIMA提取空气污染数据的线性部分并输出非线性部分,而WOA-LSTM模型用于预测非线性部分,其中鲸鱼算法用于寻找LSTM的完美超参数,搜索的目标包括神经元的数量, 对学习率和批量长度进行建模。除此之外,我对于克里金插值有一些新的猜想。
文献阅读:基于ARIMA-WOA-LSTM模型的空气污染物预测
--Jun Luo, Yaping Gong,
Air pollutant prediction based on ARIMA-WOA-LSTM model,
Atmospheric Pollution Research,
2023,
101761,
ISSN 1309-1042,
https://doi.org/10.1016/j.apr.2023.101761.
背景
空气污染问题一直困扰着人们的生活,没有对各种污染物浓度的预测和评估,就无法实现空气污染的管理。
为了应对普遍存在的空气污染问题,有必要建立高效可行的预测模型。关于空气质量预测的研究非常丰富,不同的学者提供了不同的预测方法,这些方法都有助于提高空气质量预测的准确性。LSTM模型是时间序列预测中最常用的深度学习模型之一。
空气污染数据的复杂性和不可预测性受到多种因素的影响,使得使用模型实现准确的预测变得困难。为了克服这一挑战,分解空气污染数据可能是简化预测模型并提高其有效性的有用方法。对于数据处理,具有自适应噪声的完整EEMD(CEEMDAN)和经验模态分解 (EMD)是常用的数据处理方法。模态分解模型的主要原理是将空气污染数据分解为几个复杂度不同的IMF元素,以降低模型预测的难度,最后重新组合模型预测的IMF元素,得到最终的预测值。除了模态分解,通过Prophet分解方法将数据划分为趋势、周期和误差项,并使用Prophet预测其中的趋势和周期项,并使用LSTM模型预测误差项。
ARIMA-WOA-LSTM模型
ARIMA 统计模型在线性时间序列数据预测方面具有出色的性能,而 LSTM 在非线性时间序列数据预测方面具有更显着的性能优势。对于空气污染物数据,它由线性分量和非线性分量组成,表示为:
![]()


ARIMA- LSTM
思路
在本文中,我们提出了一种准确预测空气污染物的方法,目的是确保空气污染管理的效率。提出的ARIMA-WOA-LSTM模型使用ARIMA提取空气污染数据的线性部分并输出非线性部分,而WOA-LSTM模型用于预测非线性部分,其中鲸鱼算法用于寻找LSTM的完美超参数,搜索的目标包括神经元的数量, 对学习率和批量长度进行建模。
主要贡献
- 提出了一种预测稳定性更好的空气质量预测模型。
- 基于鲸鱼算法优化LSTM模型超参数.
- ARIMA-WOA-LSTM模型在预测精度和预测稳定性方面具有较好的性能。
积分移动平均自回归 (ARIMA)
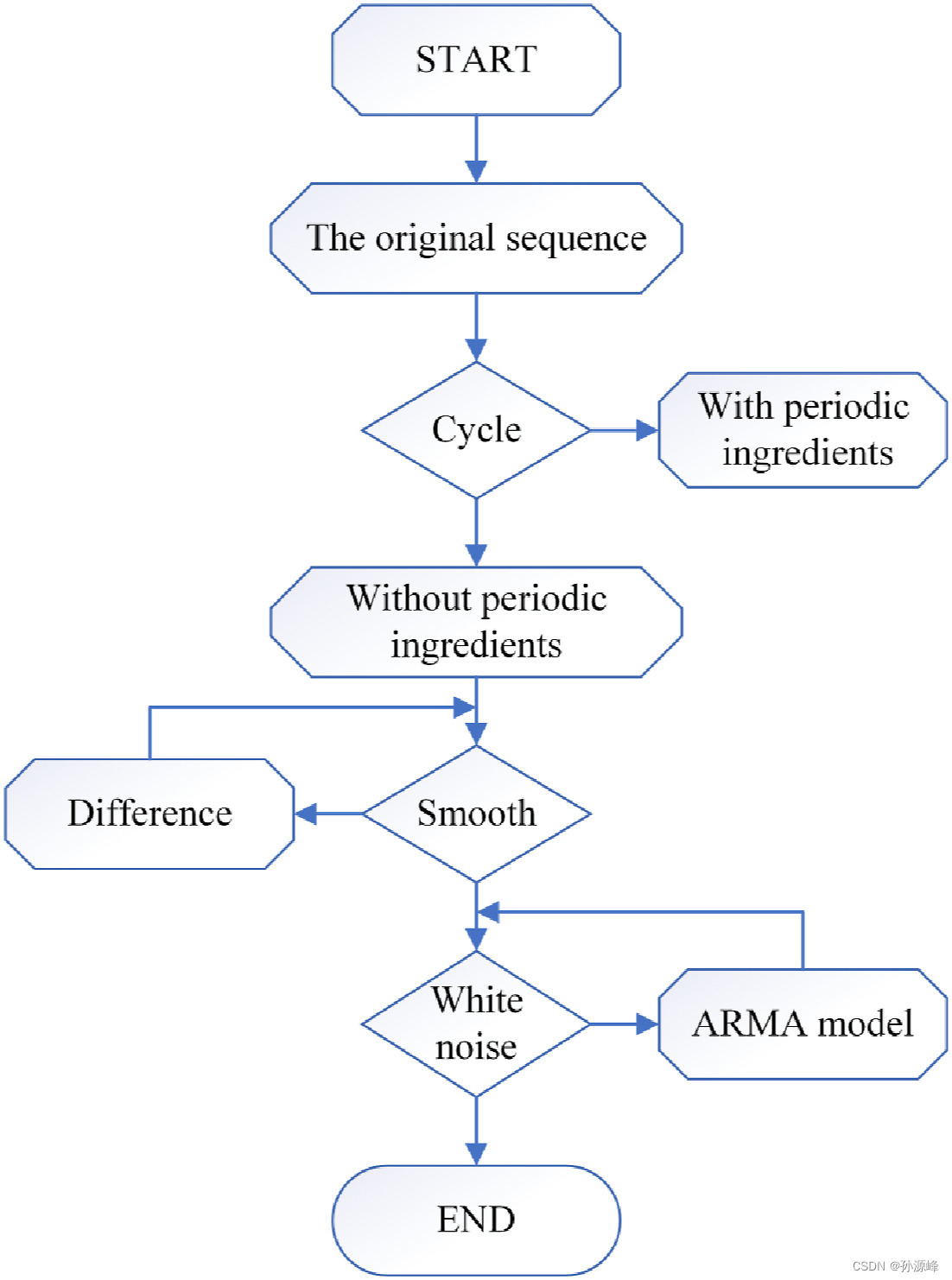
ARIMA由三个主要组成部分组成,分别是自回归模型、移动平均模型和微分项。等式(7)是ARIMA的公式,包括三个主要参数,分别是p、d和q.p和q分别对应于三个分量中的自回归和移动平均项。使用 ARIMA 模型的流程如图 1 所示。对于ARIMA模型,需要判断数据是否平滑,如果数据不平滑,则需要对数据进行不同阶数的差分才能使数据平滑,差分的阶数为d。p和q的选择通常由相关函数决定,但使用相关函数来确定参数,人为的主观因素可能很容易影响参数的选择。通常,BIC(贝叶斯信息准则)或AIC(赤池信息准则)用于确定p和q的值。公式(8)是计算BIC的公式。
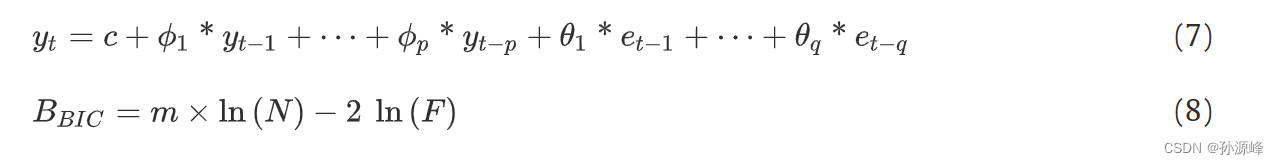

鲸鱼优化算法
WOA由提出,旨在解决传统优化算法在处理复杂问题方面的局限性。WOA主要包括:包围猎物,泡网攻击方法,搜索猎物三步。
在包围猎物阶段,WOA算法将一个人设置为最佳解决方案,其他个体根据最优解更新其位置。此行为由公式 (9) 和公式 (10) 表示。

搜索超参数
在为 LSTM 搜索最佳超参数时,首先将超参数空间定义为一个总体,每个个体都是一组超参数组合。然后使用鲸鱼优化算法初始化超参数空间,评估每个超参数组合的适应度,并更新种群。具体步骤如下:
- 1.定义 LSTM 模型的超参数空间,在本文中是学习率、批量大小、神经元数量。
- 2.使用鲸鱼优化算法初始化一组随机的超参数组合。
- 3.LSTM 模型使用总体中超参数的可能组合进行训练,并计算这组超参数的适应度。在本文中,我们使用RMSE作为适应度函数。
- 4.使用鲸鱼优化算法更新种群,选择具有最佳适应度的超参数组合,同时生成新的超参数组合。
- 5.重复步骤 3 和 4,直到适应达到收敛,或者直到达到代码限制的最大迭代次数。
- 6.输出具有最优自适应的超参数组合作为LSTM模型的最佳超参数组合。
CEEMDAN

结论
高效稳定地预测空气中不同污染物具有重要的现实意义,可以有效提高大气污染问题管理的效率。因此,本文基于ARIMA-WOA-LSTM模型实现了对空气中每种污染物的准确稳定预测,利用ARIMA提取数据的线性部分进行预测并输出非线性部分,然后利用WOA-LSTM模型预测数据的非线性部分,其中采用鲸鱼算法搜索隐藏层中神经元数共3个参数的LSTM部分, 学习率和批量长度。与其他<>种模型相比,ARIMA-WOA-LSTM模型在污染物预测精度、模型预测精度和预测稳定性<>个方面表现最好,与其他模型相比性能提升巨大;此外,从评价指标来看,组合模型在污染物预测准确率、模型预测准确率、预测稳定性三个方面比单一模型具有巨大优势,随着ARIMA-WOA-LSTM模型在大气污染物预测方面的表现较好,为提前安排大气污染治理方案提供了更有效的参考。空气污染预报的准确性仍有提升空间。如图<>所示,污染物表现出明显的季节性特征,因此在模型中包括季节性特征可能是有益的。
LSTM-Kriging
主要目标
使用LSTM替换克里金插值过程中的半方差函数拟合方法,得到LSTM-Kriging模型
理论猜想
问1:克里金插值中的半方差函数拟合方法是什么?
克里金插值中的半方差函数是模型的关键部分之一,它用来描述空间变异性的特征。而半方差函数的拟合方法则是用来寻找最优的半方差函数模型。
在克里金插值中,通常采用普通最小二乘法(OLS)或最大似然估计法(MLE)来拟合半方差函数。其中,OLS方法是通过最小化样本点与模型预测值之间的平方误差来估算半方差函数的参数,而MLE方法则是基于概率统计原理来估算半方差函数的参数。
具体来说,OLS方法会假设半方差函数的形式,并根据已知采样点的半方差值和空间距离来确定半方差函数的参数。而MLE方法则尝试寻找最有可能产生观测数据集的参数值,从而得到更准确的半方差函数模型。
当然,除了OLS和MLE方法外,还有其他一些拟合半方差函数的方法,如非参数方法、回归方法等,不同的方法适用于不同的情况。总之,在实际应用中,选择合适的半方差函数拟合方法对克里金插值的精度和效果都有着重要的影响。
问2:可以用LSTM来替换克里金插值中的半方差函数拟合嘛?
可以尝试使用LSTM来替换克里金插值中的半方差函数拟合,但两者的原理和应用场景不同,需要根据具体情况进行选择。
克里金插值中的半方差函数是一种空间变异性模型,它的主要作用是描述采样点之间的空间相关性以及空间自相关性。在实际应用中,半方差函数经常被用来揭示地球表面的变化规律,进而预测未知位置的属性值。
而LSTM(Long Short-Term Memory)是一种适用于序列数据的深度学习模型,它可以处理时间序列上的长期依赖关系,并在训练过程中自动学习特征表示。LSTM广泛应用于自然语言处理、语音识别、物体检测、时序预测等领域。
虽然LSTM和克里金插值的原理不同,但在某些情况下,可以使用LSTM来替代半方差函数拟合,例如在气象预测中,使用LSTM对历史气象数据进行训练,得到一个可以预测未来气象变化的模型。但这并不意味着LSTM可以完全取代克里金插值,因为它们各自有着独特的优缺点,需要根据具体应用场景进行选择。
问3:那应该怎么做?
大致的思路和步骤:
-
收集数据:首先需要收集环境数据、气象数据等相关数据,以便后续进行建模。
-
数据预处理:对收集到的数据进行预处理,包括数据清洗、去噪、缺失值填充等。
-
特征工程:通过对收集到的数据进行特征提取和特征工程,得到适合机器学习模型使用的特征向量。
-
模型选择:根据具体情况选择合适的机器学习模型,如LSTM、Kriging等。
-
训练模型:使用已经预处理好的数据和选定的机器学习模型进行训练,得到一个可以预测未知位置属性值的模型。
-
模型评估:对训练好的模型进行评估,包括误差分析、精度评估等指标。
-
预测应用:将训练好的模型应用于实际场景中,进行未知位置属性值的预测。同时,可能还需要对预测结果进行可视化展示、分析和解释。
需要注意的是,具体的实现细节和步骤可能因为不同的场景而有所不同,上述步骤仅供参考。
总结
目前对于克里金插值这个概念来说,算是基本理解了。目前的难点就是如何将LSTM和克里金插值结合起来。我下周将继续讨论这个问题。