文章目录
- 一、ElasticSearch基础概念铺垫
- 1.1 全文检索概念
- 1.2 正排索引与倒排索引
- 二、ElasticSearch简介
- 2.1 ElasticSearch简介
- 2.2 ElasticSearch生态圈-Elastic Stack
- 2.3 ElasticSearch与Solr搜索引擎对比
声明:以下内容均来自b站 ElasticSearch入门到精通教程,摘录了其中大部分内容,仅为自己学习使用。
一、ElasticSearch基础概念铺垫
学习ElasticSearch之前我们需要先了解以下什么是全文检索,下面就让我们简单看下它们的概念吧。
1.1 全文检索概念
数据分类:
1、结构化数据: 固定格式,有限长度,例如mysql存储的数据,字段是固定的。
2、非结构化数据: 不定长,无固定格式,例如邮件、word文档、日志。
3、半结构化数据: 结构化与非结构化数据的结合,例如xml、html。
搜索分类:
1、结构化数据搜索: 使用关系型数据库,例如mysql等。
2、非结构化数据搜索: 分为顺序扫描与全文检索。
(1)顺序扫描: 遍历所有的记录进行匹配,效率低,不符合我们的搜索期望。
(2)全文检索:通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置及出现的次数。用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置,出现的次数返回给客户。其搜索原理主要分为以下几步:
①内容爬取,停顿词过滤:例如一些无用的像"的"、"了"类的语气词与连接词;
②内容分词,提取关键词;
③根据关键词建立倒排索引;
④用户输入关键词进行搜索。
例如:如下进行的搜索便是类似的一个例子,过滤无效的字分词提取出来关键字,建立倒排索引进行搜索,将搜索结果展现给用户。
1.2 正排索引与倒排索引
正排索引: 主键对应数据。 例如下表,我们有文章ID、文章标题、文章内容。可以通过文章ID找到对应的文章内容,也可以根据文章标题找到文章内容,包括我们的关系型数据库也是如此。

倒排索引: 数据对应主键。倒排索引常使用在搜索引擎当中,是搜索引擎为文档内容建立索引,实现内容快速检索必不可少的数据结构。倒排索引是由单词的集合词典和倒排列表的集合倒排文件组成的。 例如我们有一堆英文句子,将其分词、去重、排序之后便有了一张索引ID、word、出现位置的对应表,可以快速查找到相应关键词在那一句中出现过。

二、ElasticSearch简介
2.1 ElasticSearch简介
ElasticSearch(简称ES): 是一个分布式、可水平扩展的搜索和数据分析引擎,底层为Lucene,是用java开发并且是当前最流行的开源的企业级搜索引擎,能够达到实时搜索,并且设计了友好的Restful-API使得开发者无需关注底层机制,直接开箱即用;还拥有分片、副本机制解决了集群下性能与高可用问题。 稳定、可靠、快速、安装使用方便,客户端还支持java、C#、PHP、Python、Ruby等多种语言。
应用场景: 在国内,阿里巴巴、腾讯、滴滴、今日头条、饿了么、360安全、小米,vivo 等诸多知名公司都在使用Elasticsearch,主要用于日志搜集分析、用于APP综合搜索、订单系统搜索、企业级网站搜索等方面。除此之外还可以帮助探索海量数据结构化、非结构化数据,按需创建可视化报表、对健康数据设置报警阈值,甚至通过使用机器学习技术自动识别异常状况。
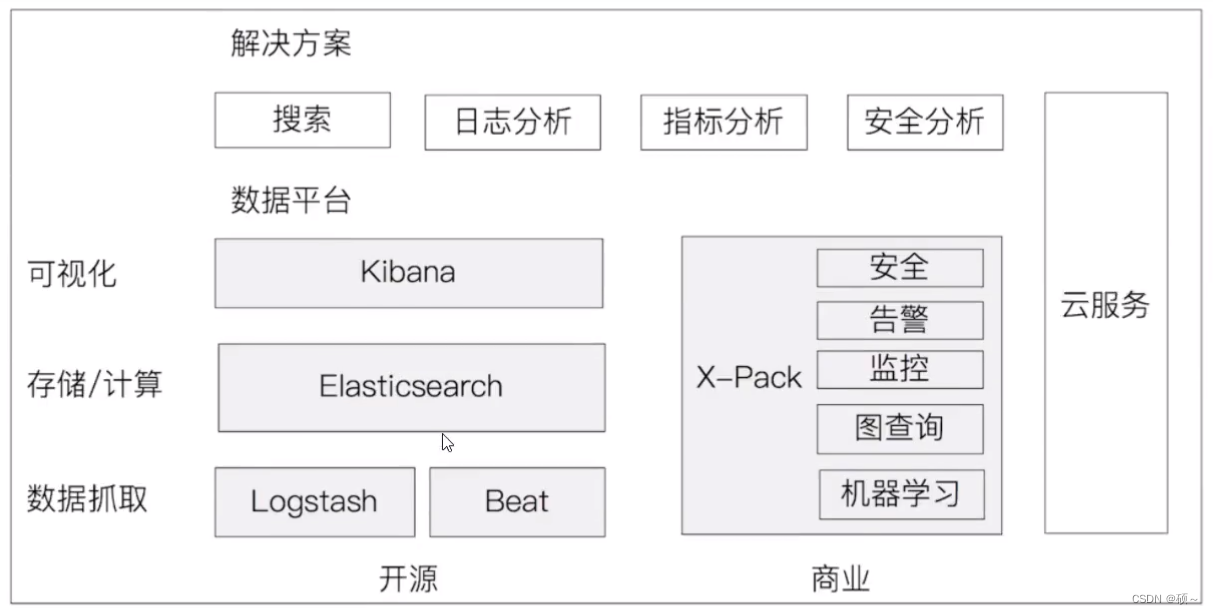
2.2 ElasticSearch生态圈-Elastic Stack
Elastic Stack: 我们先来了解一下什么是ELK,ELK即ElasticSearch(数据存储和搜索)、Logsstash(数据采集)、Kibana(提供给用户可视化及操作的界面)这三款软件在一起时的简称。在发展过程中又有了Beats(数据采集)的加入,便形成了Elastic Stack。
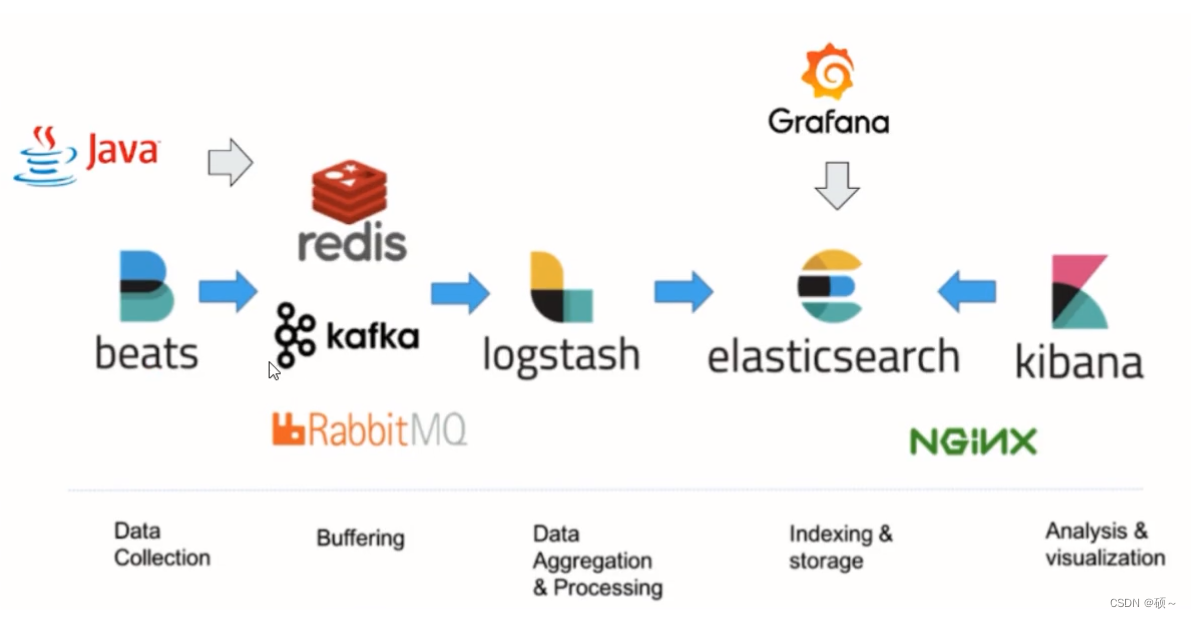
例如:我们想对Java的日志进行分析,可以先通过beats进行日志采集,采集到redis或者MQ中。完成后利用logstash进行数据过滤,以json格式存储到elasticsearch中,最终利用kibana提供给用户可视化界面查看。
2.3 ElasticSearch与Solr搜索引擎对比
ElasticSearch与Solr搜索引擎对比:
1、Solr 利用 Zookeeper 进行分布式管理;而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV;而 Elasticsearch 仅支持json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch;但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案;但 Elasticsearch更适用于新兴的实时搜索应用。