鲁迅先生1923年在北师大发表了著名的演讲《娜拉走后怎样》,其中的提问与思考方式振聋发聩,直到今天也依旧有效。面对很多产业现象、技术趋势,我们也不妨多问几个“之后怎样”。
比如说,自ChatGPT爆火之后,中国各个互联网、科技公司竞相推出了自己的大语言模型及相关应用。其实,关于中国能否有ChatGPT我们从未担心过,而问题的关键在于“之后怎样”。
层出不穷的大语言模型,让人眼花缭乱。但如此多的大模型,差异化和竞争力从何而来?能否顺利、低成本实现产业落地?能否有效支持模型的快速迭代?
发布大模型并不是终点,而是一场新长跑的起点。如果不能有效回答这些问题,那么大模型也最终会像其他技术风口一样,倏忽而来,倏忽而去。

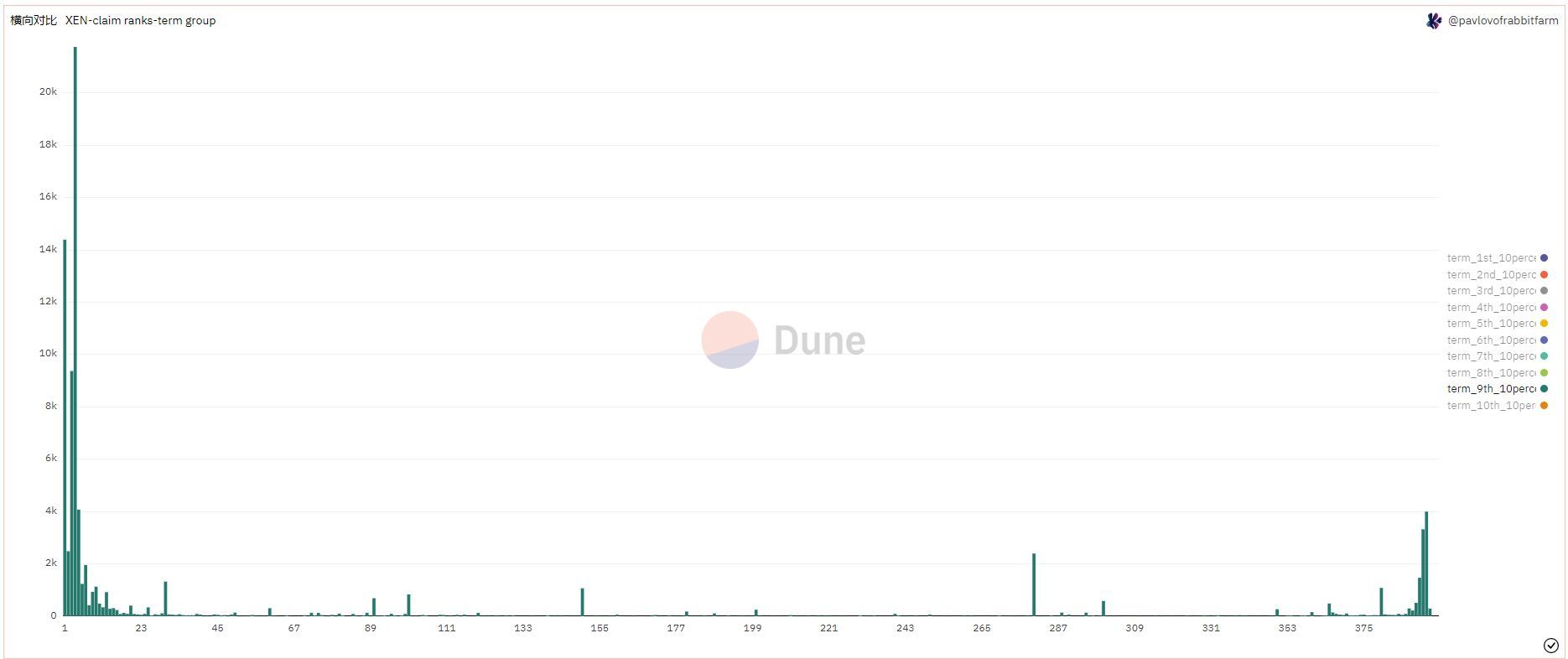
慢慢地,“大模型之后怎样”这个问题,也开始有了答案。4月23日,我们看到一份百度文心一言内部流出的会议纪要。其中显示,从3月开始,文心一言启动邀测后的一个多月内,其模型已经迭代了4次,最近一次带来的推理效果提升了达到123%。
到底是什么支持文心一言完成了这种超越常规的迭代速度?
这个“秘密”或许正是中国大模型走向未来所需要的动力,也是“大模型之后怎样”的某种答案。
内部会议纪要
透露出文心一言的奔跑速度
根据内部纪要内容显示,文心一言在开启邀测后用户数与同时在线人数都极速增长,面临这种情况,文心一言需要及时获得更快的响应速度。我们知道,机器学习类模型的应用逻辑包含数据准备—模型训练—模型推理几个步骤。文心一言面临的响应挑战,就是需要及时强化模型的推理能力。

为了实现这个目标,百度对文心一言进行了模型层与框架层的联合优化,从而在一个月内迭代了4次,实现了模型推理能力的极大提升。
是什么让文心一言获得了这样的奔跑速度?这就要提到百度飞桨“提前”做好的准备。作为深度学习开发平台,飞桨可以支持AI模型从训练到推理的全流程落地。其中,飞桨模型推理服务就可以有效支持大模型升级,这一服务在4月19日刚刚再次迭代,已迭代至3.5版本,它的特点是在业内首创了支持动态插入的分布式推理引擎,从而可以更有效完成庞大数据规模的AI模型进行推理部署。
至此我们可以从这份内部纪要中知道,文心一言能够快速持续迭代,并且低成本落地应用的关键,就藏在这里——飞桨与文心一言联合优化。
从结果上看,联合优化带来的价值非常显著。飞桨帮助文心一言实现了模型推理效率提升10倍,模型推理性能提升50%,模型算力利用率提升1倍。其中,模型推理效率提升10倍,意味着推理成本降低为原来1/10,或者可以为10倍数量的用户提供服务;模型推理性能提升50%,意味着飞桨可以帮助文心一言工艺更精密,模型的学习效果与鲁棒性更强;模型算力利用率提升1倍,是由于飞桨向下兼容到芯片,实现全栈联合优化,从而可以极大降低文心一言的算力开销。
从这几个方向可以看出,飞桨为文心一言带来的价值,是持续性且多方面的,其中最重要的是,飞桨让文心一言可以持续性、低成本向前奔跑,不断进化。
这也恰好解释了这个问题:大模型,路在何方?
飞桨
让大模型节奏飞起的AI引擎
在ChatGPT全球化爆火,各家厂商、投资人,都在不遗余力地挤上大模型赛道。这种情况当然可以理解,但也必须看到,这条赛道不仅门槛高、入局难,在入局之后构建持续竞争力同样很难。
大模型意味着庞大的算力开支、数据开支,以及更为恐怖的模型迭代成本。入局大模型之后,必须根据用户反馈快速迭代,高效率升级,否则一不小心就会掉队,在第一轮风口过去后陷入行业洗牌,紧跟行业趋势,不断推动模型升级,又会面临巨大的工作量与模型推理成本。
这个两难选择并不遥远,很快就会成为困扰大量新玩家的头疼问题。
而多年部署AI基础设施与基础技术的百度,其优势就在这时显示了出来。飞桨与文心一言的联合优化,让文心一言在训练和推理过程中效率大幅提升,实现了真正的人家起跑,我已经几轮加速,节奏快到飞起。
大模型与AI开发平台,是相辅相成、互为表里的关系。比如有分析人士解读认为,“大模型就仿佛汽车的发动机,光账面上的动力强,参数大是没有用的,要压榨出发动机瞬时最大爆发力(QPS)以及最优的性能表现。深度学习框架就像是生产发动机和变速箱的,可以让发动机整体部件组合更精密、动力更强。自研产品彼此适配度更高,协同会更高效,这可能是效率提升的最根本原因。”依托风口入局大模型,终归会有一种空中楼阁的隐忧,至少难以将全面的技术栈掌握在自己手中,实现更高效、可控的模型升级。

由此可见,大模型走向成功,除了算力、数据的基础之外,深度学习框架同样扮演着关键角色。面对纷繁而出的大模型,百度文心系列大模型的差异化优势,也就在百度十年搭建的飞桨平台中展露了出来。
而当我们把大模型与飞桨的联动关系,放到科技自立自强的战略高度来审视。又会发现一些别样的答案:飞桨既是百度的AI护城河,也是中国大模型的动力引擎。
中国AI
胜负系于工程化
最近,我们能看到很多大语言模型的发布会,差不多每一家都会说,我们目前确实不如ChatGPT,以后继续努力。
那么问题来了,怎么努力?
事实上,努力不是说说就行了,而是要找到方式和方法。ChatGPT代表的算法优势、人才优势、算力优势都是短期很难抹平的,至少看不到可以快速超车的战略空间。中国AI想要走通大模型这条路,就只能扬长避短,而中国AI的优势在哪呢?从百度流出的内部会议纪要中其实已经告诉了我们答案:工程化。
通过飞桨长期坚持的AI工程化路径的掌握与打磨,我们可以看到百度发展大模型的独特优势,同时也可以看到中国AI整体性的战略机遇。
首先,对于百度内部来说,通过飞桨牢牢把控工程化能力,可以提升文心一言的迭代速度,降低算力、人工、数据等开销,从而让文心一言能够在同等成本下服务的用户更多,适配产品的效率更高。这就像同样从一处名叫“大模型”的深海油井取得原油,飞桨就像一艘轮船,船速更快,运量还大,而其他人在用帆船运输。效率意味着成本,成本意味着商业化可能性,这就是飞桨的价值,也是AI工程化能力的魅力。
从百度向外看,飞桨带来的工程化能力,意味着文心系列大模型的推理成本更低,继而导致其在各行业、各场景中的落地成本更低。这对于文心大模型融入行业,通过产业智能化产生价值是个重大利好。大模型走向千行百业,是今天每家公司都在喊的口号,但这个过程中,一定不能把模型落地成本全部转嫁给行业用户。消解这一成本的关键,也在于飞桨代表的工程化路径。

最后,当大模型已经上升为国家战略,我们必须看到AI框架在科技自立自强进程中扮演的角色。如果事关国计民生,每天与无数国人进行问答的大模型,建立在其他国家的框架上,那么其危险系数可想而知。当大模型愈发重要,关注并持续解决深度学习框架卡脖子的隐忧就更加重要。
而从另一个角度看,AI框架与AI开发平台代表的AI工程化能力,是中国AI技术最亮眼、最特殊的部分。这一部分下接芯片,上达应用,通向千行百业的AI开发需求,恰好是AI技术中的战略要冲所在。中国AI能否扬长避短,实现超车,极大概率就系于工程化能力的建设与发挥,系于AI框架与产业智能化的连接中。
中国大模型,就是行业大模型,就是强工程化、强落地性的大模型,只有走通这条路,中国AI才有未来。