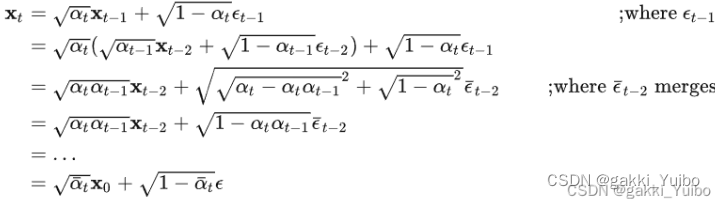传统机器学习(六)集成算法(1)—随机森林算法及案例详解
1、概述
集成学习(Ensemble Learning)就是通过某种策略将多个模型集成起来,通过群体决策来提高决策准确率。
集成学习首要的问题是选择什么样的学习器以及如何集成多个基学习器,即集成策略。
1.1 集成学习的分类
一个有效的集成除了要让各个基学习器的学习效果好之外,还需要各个基学习器的差异尽可能大(差异性:各个基学习器的预测结果不完全相同)。集成学习往往和方差大的模型组合时效果显著。
-
Bagging类方法中基学习器之间不存在强依赖关系,可并行执行。
-
Boosting类方法中基学习器之间存在强依赖关系,必须串行执行。
-
Stacking:聚合多个分类或回归模型(可以分阶段来做)。
Boosting和Bagging通常都是使用同一种基学习器(base learner),因此我们一般称之为同质集成方法。
Stacking通常都是基于多个不同的基学习器做的集成,因此我们称之为异质集成方法。
1.1.1 Bagging
Bagging类方法是通过随机构造训练样本、随机选择特征等方法来提高每个基模型的独立性。由于训练数据的不同,获得的学习器会存在差异性,但是若采样的每个子集都完全不同,则每个基学习器都只能训练一小部分数据,无法进行有效的学习。因此考虑使用相互交叠的采样子集。代表性方法有Bagging和随机森林等。
-
Bagging(Bootstrap Aggregating)是
通过不同模型的训练数据集的独立性来提高不同模型之间的独立性。我们在原始训练集上进行有放回的随机采样。可以采样T个含有m个样本的数据集并行训练得到T个模型,然后将这些基学习模型进行结合。对于基学习器的集成方法,Bagging通常对分类任务使用简单投票法,对回归任务使用平均法。若预测的结果中有含有相同票数的两个类,可以使用随机选择或者考察学习器投票的置信度来确定。 -
随机森林(Random Forest)是
在Bagging的基础上再引入了随机特征,进一步提高每个基模型之间的独立性。在随机森林中,每个基模型都是一棵决策树,与传统决策树不同的是,在RF中,对每个基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后从这个子集中选择一个最优属性由于划分,而传统的决策树是直接在当前节点的属性集合中选择一个最优属性来划分集合。
1.1.2 Boosting
Boosting类方法是按照一定的顺序来先后训练不同的基模型,每个模型都针对先前模型的错误进行专门训练。根据先前模型的结果,来调整训练样本的权重,从而增加不同基模型之间的差异性。Boosting的过程很类似于人类学习的过程,我们学习新知识的过程往往是迭代式的。第一遍学习的时候,我们会记住一部分知识,但往往也会犯一些错误,对于这些错误,我们的印象会很深。第二遍学习的时候,就会针对犯过错误的知识加强学习,以减少类似的错误发生。不断循环往复,直到犯错误的次数减少到很低的程度。
Boosting 类方法是一种非常强大的集成方法,只要基模型的准确率比随机猜测高,就可以通过集成方法来显著地提高集成模型的准确率。Boosting类方法的代表性方法有:AdaBoost,GBDT等。
1.1.3 Stacking
对于一个问题来说,我们可以采用不同类型的学习器来解决学习的问题,这些学习器通常能够学习到问题的一部分,但不能学习到问题的整个空间。Stacking的做法是首先构建多个不同类型的一级学习器,并使用他们来得到一级预测结果,然后基于这些一级预测结果,构建一个二级学习器,来得到最终的预测结果。
Stacking的动机可以描述为:如果某个一级学习器错误地学习了特征空间的某个区域,那么二级学习器通过结合其他一级学习器的学习行为,可以适当纠正这种错误。
1.2 随机森林原理
随机森林(Random Fores)是将决策树进行简单bagging的一种集成算法。它经过多次随机抽取样本训练多棵决策树,用多棵决策树集成决策。由于它拥有多棵树,且每棵树是随机的,所以称为随机森林。

1.2.1 模型表达式
y = 1 k [ t 1 ∗ p r o b ( x ) + [ t 2 ∗ p r o b ( x ) + . . . + [ t k ∗ p r o b ( x ) ] y = \frac{1}{k}[t_{1}*prob(x) + [t_{2}*prob(x) + ...+ [t_{k}*prob(x)] y=k1[t1∗prob(x)+[t2∗prob(x)+...+[tk∗prob(x)]
其中:
t(i) : 决策树
t(i).prob(x) : 第i棵树对x的预测,输出为各个类别的预测概率(行向量)
k : 森林规模数
即模型为多棵决策树组成,最后的预测概率为各棵树的概率预测均值。概率得分最大的一类,即为预测类别
1.2.2 模型训练
模型训练焦点在于如何训练出多棵不同的弱树。可以通过如下方式实现:每次随机选择部分样本,和部分变量训练一棵弱树,要使树是弱树,可将树的深度设置得较浅,总之,让树的预测不是很精确。
-- 1、训练流程如下
放回式抽取n个样本,每个样本抽到的次数,作为样本权重。
用加了权重的样本训练弱决策树(弱决策树即:最大分割特征:2),一直训练K棵树为止。
简单地说,就是生成k棵树,每棵树用的样本随机抽取。最后k棵树组合在一起就是森林。
-- 2、训练参数
(1) 变量最大个数m,m一般远小于总变量个数M,例如 根号M
(2) 森林规模(树的棵数k)
1.2.3 随机森林的泛化能力
袋外错误率
随机森林可用袋外错误率obb(out-of-bag) error评估泛化能力.
袋外错误率的思路是通过未参与训练样本(袋外样本)的准确率来检验森林的泛化能力,由于每个样本都只被部分树用于训练,可以只用森林中该样本不参与的子森林来预测样本,袋外错误率就是用该方法对所有样本进行预测的准确率。
袋外类别预测
袋外的类别预测,是指用该样本未参与训练的树对其进行概率预测,汇总所有树对该样本的预测结果(概率之和归一化后的值),最后哪个类别的概率大,就认为袋外预测类别是哪个。

所有样本的袋外预测准确率,即为袋外评分(obb_socre),袋外错误率 则为:obb_error = 1 - obb_socre
1.2.4 特征权重
特征权重是每个特征对随机森林贡献度的占比,特征权重越高,说明特征对森林的构成越重要,对决策结果影响越大。
只要将森林的每棵树的评分求均值,并作归一化,就是森林的特征评分。
s
=
n
o
r
m
(
1
k
∑
i
=
1
n
s
i
)
s = norm(\frac{1}{k}\sum\limits_{i=1}^ns_{i})
s=norm(k1i=1∑nsi)
其中,s(i)为向量,是第 i 棵树对各个特征的评分。
1.2.5 随机森林的优缺点
1、随机森林算法优点
-
由于采用了集成算法,本身精度比大多数单个算法要好,所以准确性高
-
在测试集上表现良好,由于两个随机性的引入,使得随机森林不容易陷入过拟合(样本随机,特征随机)
-
在工业上,由于两个随机性的引入,使得随机森林具有一定的抗噪声能力,对比其他算法具有一定优势
-
由于树的组合,使得随机森林可以处理非线性数据,本身属于非线性分类(拟合)模型
-
它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
-
训练速度快,可以运用在大规模数据集上
-
可以处理缺省值(单独作为一类),不用额外处理
-
由于有袋外数据(OOB),可以在模型生成过程中取得真实误差的无偏估计,且不损失训练数据量
-
在训练过程中,能够检测到feature间的互相影响,且可以得出feature的重要性,具有一定参考意义
-
由于每棵树可以独立、同时生成,容易做成并行化方法
-
由于实现简单、精度高、抗过拟合能力强,当面对非线性数据时,适于作为基准模型
2、随机森林算法缺点
-
当随机森林中的决策树个数很多时,训练时需要的空间和时间会比较大
-
随机森林中还有许多不好解释的地方,有点算是黑盒模型
-
在某些噪音比较大的样本集上,RF的模型容易陷入过拟合
2、手动实现随机森林
from sklearn.datasets import load_iris
import numpy as np
from sklearn.base import clone
from sklearn.tree import DecisionTreeClassifier
np.random.seed(888)
# ==================== 加载数据=====================================================
iris = load_iris()
X = iris.data
Y = iris.target
n_samples = X.shape[0] # 样本个数
n_samples_bootstrap = X.shape[0] # 抽样个数
c_n = np.unique(Y).shape[0] # 类别数
tree_num = 100 # 森林决策树个数
trees = [] # 初始化树列表
p_oob = np.zeros((n_samples, c_n)) # oob投票结果
random_state = np.random.mtrand._rand # 随机状态
max_features = 2 # 每棵树分割最大特征数(至少有一个分割点,若一个都没有,则无视该条件)
# 建立树模板
base_estimator = DecisionTreeClassifier()
base_estimator.set_params(**{'criterion': 'gini',
'min_samples_split': 2,
'min_samples_leaf': 1,
'min_weight_fraction_leaf': 0.0,
'max_features': max_features,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'random_state': None,
'ccp_alpha': 0.0
})
# 逐树训练
random_state_list = [random_state.randint(np.iinfo(np.int32).max) for i in range(tree_num)] # 初始化树随机状态
for i in range(tree_num):
sample_indices = np.random.RandomState(random_state_list[i]).randint(0, n_samples, n_samples_bootstrap) # 抽样
sample_counts = np.bincount(sample_indices, minlength=n_samples) # 抽样分布
curr_sample_weight = np.ones((n_samples,), dtype=np.float64) * sample_counts # 样本权重
cur_tree = clone(base_estimator) # 初始化树
cur_tree.set_params(**{'random_state': random_state_list[i]}) # 设置当前树随机状态
cur_tree.fit(X, Y, sample_weight=curr_sample_weight, check_input=False) # 训练树
trees.append(cur_tree) # 将本次训练好的树, 添加到树列表
# 计算obb得分
un_select = ~ np.isin(range(n_samples), sample_indices) # 未选中的数据
cur_p_oob = cur_tree.predict_proba(X[un_select, :]) # 将当前未选中数据的预测结果
p_oob[un_select, :] += cur_p_oob # 投票到汇总结果
# =============== 模型指标统计 ===================================
oob_score = np.mean(Y == np.argmax(p_oob, axis=1), axis=0) # obb样本正确率即为obb得分
# 计算特征得分
all_importances = [getattr(tree, 'feature_importances_') for tree in trees if tree.tree_.node_count > 1] # 获取每棵树中各特征评估
all_importances = np.mean(all_importances, axis=0, dtype=np.float64) # 求均值
feature_importances = all_importances / np.sum(all_importances) # 归一化
# =============== 模型预测 ===================================
sim_p = np.zeros((X.shape[0], c_n), dtype=np.float64) # 初始化投票得分
for i in range(len(trees)): # 逐树投票
sim_p += trees[i].predict_proba(X) / len(trees) # 投票
sim_c = np.argmax(sim_p, axis=1) # 得分最高者作为投票结果
# =================打印结果==========================
print("\n----前5条预测结果:----")
print(sim_p[0:5]) # 打印结果
print("\n----袋外准确率oob_score:----")
print(oob_score) # 打印oob得分
print("\n----特征得分:----")
print(feature_importances)
----前5条预测结果:----
[[1. 0. 0. ]
[0.99 0.01 0. ]
[1. 0. 0. ]
[1. 0. 0. ]
[1. 0. 0. ]]
----袋外准确率oob_score:----
0.9533333333333334
----特征得分:----
[0.08186032 0.02758341 0.44209899 0.44845728]
3、sklearn中的bagging和随机森林
3.1 bagging
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)
'''
Bagging策略:
首先对训练数据集进行多次采样,保证每次得到的采样数据都是不同的;
分别训练多个模型,例如树模型;
预测时需得到所有模型结果再进行集成。
'''
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
X, y = make_moons(n_samples=500,noise=0.25,random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)

'''
1、传统决策树
'''
from sklearn import tree
from sklearn.metrics import accuracy_score
tree_clf = tree.DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train,y_train)
y_pred = tree_clf.predict(X_test)
print('传统决策树精确率为:',accuracy_score(y_test,y_pred))
# 传统决策树精确率为: 0.936
'''
2、Bagging
'''
from sklearn.ensemble import BaggingClassifier
bag_clf = BaggingClassifier(
tree.DecisionTreeClassifier(), # 拟合数据集的随机子集的基学习器
n_estimators=500, # 基学习器数目
max_samples=100, # 每个学习器抽样的最大样本数
bootstrap=True, # 样本是否放回
n_jobs=-1,
oob_score=True,
random_state=42
)
bag_clf.fit(X_train,y_train)
y_pred = bag_clf.predict(X_test)
print('Bagging精确率为:',accuracy_score(y_test,y_pred))
# Bagging精确率为: 0.952
'''
3、决策边界对比
'''
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,X,y,axes=[-1.5,2.5,-1,1.5],alpha=0.5,contour =True):
x1s=np.linspace(axes[0],axes[1],100)
x2s=np.linspace(axes[2],axes[3],100)
x1,x2 = np.meshgrid(x1s,x2s)
X_new = np.c_[x1.ravel(),x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1,x2,y_pred,cmap = custom_cmap,alpha=0.3)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap = custom_cmap2,alpha=0.8)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)
plt.axis(axes)
plt.xlabel('x1')
plt.xlabel('x2')
plt.figure(figsize = (12,5))
plt.subplot(121)
plot_decision_boundary(tree_clf,X,y)
plt.title('Decision Tree')
plt.subplot(122)
plot_decision_boundary(bag_clf,X,y)
plt.title('Decision Tree With Bagging')
plt.show()

# 随机森林可用袋外错误率obb(out-of-bag) error评估泛化能力.
# obb_error = 1 - obb_socre
obb_error = 1 - bag_clf.oob_score_
obb_error
# 0.06399999999999995
3.2 随机森林
"""
sklearn的随机森林Demo
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import numpy as np
np.random.seed(55)
# ==================== 加载数据 =================
iris = load_iris()
X = iris.data
y = iris.target
# ========================= 模型训练 =============
clf = RandomForestClassifier(
n_jobs=1,
oob_score=True,
max_features=2,
n_estimators=100
)
clf.fit(X, y)
# =============================== 模型预测 ========
pred_prob = clf.predict_proba(X)
pred_c = clf.predict(X)
preds = iris.target_names[pred_c]
#=================打印结果==========================
print("\n----前5条预测结果:----")
print(pred_prob[0:5])
print("\n----袋外准确率oob_score:----")
print(clf.oob_score_)
print("\n----特征得分:----")
print(clf.feature_importances_)
----前5条预测结果:----
[[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]]
----袋外准确率oob_score:----
0.9533333333333334
----特征得分:----
[0.09910252 0.0317905 0.48356935 0.38553764]
4、随机森林案例
4.1 随机森林预测宽带客户离网
数据集链接:https://pan.baidu.com/s/1vmjldkWZtQWlFopWlFLX9w 提取码:ad1h
集成学习与神经网络一样,都属于解释性较差的黑盒模型,所以我们无需过分探究数据集中每个变量的具体含义,只需关注最后一个变量broadband即可,争取通过如年龄,使用时长,支付情况以及流量和通话情况等变量对宽带客户是否会续费做出一个较准确的预测。
1、数据探索
import pandas as pd
import numpy as np
df = pd.read_csv('../data/broadband.csv') # 宽带客户数据
# 列名全部换成小写
df.rename(str.lower, axis='columns', inplace=True)
# 只需关注参数,broadband:0-离开,1-留存
df.head()
| cust_id | gender | age | tenure | channel | autopay | arpb_3m | call_party_cnt | day_mou | afternoon_mou | night_mou | avg_call_length | broadband | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 34 | 27 | 2 | 0 | 203 | 0 | 0.0 | 0.0 | 0.0 | 3.04 | 1 |
| 1 | 64 | 0 | 62 | 58 | 1 | 0 | 360 | 0 | 0.0 | 1910.0 | 0.0 | 3.30 | 1 |
| 2 | 65 | 1 | 39 | 55 | 3 | 0 | 304 | 0 | 437.2 | 200.3 | 0.0 | 4.92 | 0 |
| 3 | 66 | 1 | 39 | 55 | 3 | 0 | 304 | 0 | 437.2 | 182.8 | 0.0 | 4.92 | 0 |
| 4 | 67 | 1 | 39 | 55 | 3 | 0 | 304 | 0 | 437.2 | 214.5 | 0.0 | 4.92 | 0 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1114 entries, 0 to 1113
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cust_id 1114 non-null int64
1 gender 1114 non-null int64
2 age 1114 non-null int64
3 tenure 1114 non-null int64
4 channel 1114 non-null int64
5 autopay 1114 non-null int64
6 arpb_3m 1114 non-null int64
7 call_party_cnt 1114 non-null int64
8 day_mou 1114 non-null float64
9 afternoon_mou 1114 non-null float64
10 night_mou 1114 non-null float64
11 avg_call_length 1114 non-null float64
12 broadband 1114 non-null int64
dtypes: float64(4), int64(9)
memory usage: 113.3 KB
from collections import Counter
# 查看broadband分布情况,随机森林擅长处理数据集不平衡
print('broadband',Counter(df['broadband']))
broadband Counter({0: 908, 1: 206})
2、拆分测试集及训练集
# 客户id没有用,故丢弃cust_id这一列
X = df.iloc[:,1:-1]
y = df['broadband']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(
X,y,test_size=0.3,random_state=888
)
3、决策树建模
from sklearn import tree
# 直接使用交叉网格搜索来优化决策树模型
from sklearn.model_selection import GridSearchCV
# 网格搜索的参数:正常决策树建模中的参数 - 评估指标,树的深度,最小拆分的叶子样本数
# 通常来说,十几层的树已经是比较深了
param_grid = {
'max_depth': [2, 3, 4, 5, 6, 7, 8],
'min_samples_split': [4, 8, 12, 16, 20, 24, 28]
}
clf_cv = GridSearchCV(
estimator=tree.DecisionTreeClassifier(),
param_grid=param_grid,
scoring='roc_auc',
cv=5
)
clf_cv.fit(X_train,y_train)
pred_y_test = clf_cv.predict(X_test)
import sklearn.metrics as metrics
print("决策树 AUC:")
fpr_test, tpr_test, th_test = metrics.roc_curve(y_test, pred_y_test)
print('AUC = %.4f' % metrics.auc(fpr_test, tpr_test))
决策树 AUC:
AUC = 0.7763
4、随机森林建模
# 一样是直接使用网格搜索
param_grid = {
'max_depth':[5, 6, 7, 8], # 深度:这里是森林中每棵决策树的深度
'n_estimators':[11,13,15], # 决策树个数-随机森林特有参数
'max_features':[0.3,0.4,0.5], # 每棵决策树使用的变量占比-随机森林特有参数(结合原理)
'min_samples_split':[4,8,12,16] # 叶子的最小拆分样本量
}
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc_cv = GridSearchCV(estimator=rfc,
param_grid=param_grid,
scoring='roc_auc',
cv=5)
rfc_cv.fit(X_train, y_train)
# 使用随机森林对测试集进行预测
test_est = rfc_cv.predict(X_test)
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(test_est, y_test) # 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
随机森林 AUC...
AUC = 0.8181
# 查看最佳参数,看是否在决策边界上,还需重新设置网格搜索参数
rfc_cv.best_params_
{'max_depth': 7,
'max_features': 0.3,
'min_samples_split': 4,
'n_estimators': 15}
# 调整决策边界,这里只是做示范
param_grid = {
'max_depth':[7, 8, 10, 12],
'n_estimators':[11, 13, 15, 17, 19], # 决策树个数-随机森林特有参数
'max_features':[0.2,0.3,0.4, 0.5, 0.6, 0.7], # 每棵决策树使用的变量占比-随机森林特有参数
'min_samples_split':[2, 3, 4, 8, 12, 16] # 叶子的最小拆分样本量
}
# 重复上述步骤,可写成函数供快捷调用
rfc_cv = GridSearchCV(estimator=rfc,
param_grid=param_grid,
scoring='roc_auc',
n_jobs=-1,
cv=5)
rfc_cv.fit(X_train, y_train)
# 使用随机森林对测试集进行预测
test_est = rfc_cv.predict(X_test)
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(test_est, y_test) # 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
# 这里的 auc 只提升了很多
随机森林 AUC...
AUC = 0.8765
4.2 随机森林分析酒店预定取消率影响的因素
数据集下载地址:https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand
该数据集依据两家酒店为主体,分别是一家度假酒店与一家城市酒店,这两家均位于葡萄牙(Portugal),度假酒店(Resort hotel)在阿尔加维(Algarve),城市酒店(City hotel)则位于葡萄牙首都里斯本(Lisbon),两个酒店在地理位置上跨度较大,数据之间相互干扰的影响较小。
1、数据探索
import pandas as pd
import matplotlib.pyplot as plt
#显示设置
pd.set_option("display.max_columns", None) #设置显示全部列
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
# 加载数据
data_origin = pd.read_csv("../data/hotel_bookings.csv")
#数据备份
data=data_origin.copy()
print(data.shape)
data.head()
| hotel | is_canceled | lead_time | arrival_date_year | arrival_date_month | arrival_date_week_number | arrival_date_day_of_month | stays_in_weekend_nights | stays_in_week_nights | adults | children | babies | meal | country | market_segment | distribution_channel | is_repeated_guest | previous_cancellations | previous_bookings_not_canceled | reserved_room_type | assigned_room_type | booking_changes | deposit_type | agent | company | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | reservation_status | reservation_status_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Resort Hotel | 0 | 342 | 2015 | July | 27 | 1 | 0 | 0 | 2 | 0.0 | 0 | BB | PRT | Direct | Direct | 0 | 0 | 0 | C | C | 3 | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 1 | Resort Hotel | 0 | 737 | 2015 | July | 27 | 1 | 0 | 0 | 2 | 0.0 | 0 | BB | PRT | Direct | Direct | 0 | 0 | 0 | C | C | 4 | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 2 | Resort Hotel | 0 | 7 | 2015 | July | 27 | 1 | 0 | 1 | 1 | 0.0 | 0 | BB | GBR | Direct | Direct | 0 | 0 | 0 | A | C | 0 | No Deposit | NaN | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 3 | Resort Hotel | 0 | 13 | 2015 | July | 27 | 1 | 0 | 1 | 1 | 0.0 | 0 | BB | GBR | Corporate | Corporate | 0 | 0 | 0 | A | A | 0 | No Deposit | 304.0 | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 4 | Resort Hotel | 0 | 14 | 2015 | July | 27 | 1 | 0 | 2 | 2 | 0.0 | 0 | BB | GBR | Online TA | TA/TO | 0 | 0 | 0 | A | A | 0 | No Deposit | 240.0 | NaN | 0 | Transient | 98.0 | 0 | 1 | Check-Out | 2015-07-03 |
# hotel 酒店类型
# is_canceled 预订是否取消(0,1)
# lead_time 提前预订天数
# arrival_date_year 入住年份
# arrival_date_month 入住月份
# arrival_date_week_number 入住周数
# arrival_date_day_of_month 入住日期
# stays_in_weekend_nights 周末过夜数
# stays_in_week_nights 工作日过夜数
# adults 成人人数
# children 儿童人数
# babies 婴儿人数
# meal 餐食类型(BB早餐,HB午餐,FB晚餐,Undefined/SC无餐)
# country 客户来源国家
# market_segment 市场细分
# distribution_channel 订单渠道
# is_repeated_guest 是否是老客户
# previous_cancellations 历史取消预订的次数
# previous_bookings_not_canceled 历史未取消预订的次数
# reserved_room_type 预定房间类型
# assigned_room_type 实际房间类型
# booking_changes 预定更改次数
# deposit_type 押金类型(No Deposit,Non Refund,Refundable)
# agent 预订旅行社ID
# company 预订公司/实体ID
# days_in_waiting_list 等待天数
# customer_type 客户类型
# adr 客房日均价
# required_car_parking_spaces 车位需求数
# total_of_special_requests 特殊需求数
# reservation_status 预订最终状态(Canceled,Check-out,No-show)
# reservation_status_date 预订最终状态更新日期
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119390 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 119390 non-null object
1 is_canceled 119390 non-null int64
2 lead_time 119390 non-null int64
3 arrival_date_year 119390 non-null int64
4 arrival_date_month 119390 non-null object
5 arrival_date_week_number 119390 non-null int64
6 arrival_date_day_of_month 119390 non-null int64
7 stays_in_weekend_nights 119390 non-null int64
8 stays_in_week_nights 119390 non-null int64
9 adults 119390 non-null int64
10 children 119386 non-null float64
11 babies 119390 non-null int64
12 meal 119390 non-null object
13 country 118902 non-null object
14 market_segment 119390 non-null object
15 distribution_channel 119390 non-null object
16 is_repeated_guest 119390 non-null int64
17 previous_cancellations 119390 non-null int64
18 previous_bookings_not_canceled 119390 non-null int64
19 reserved_room_type 119390 non-null object
20 assigned_room_type 119390 non-null object
21 booking_changes 119390 non-null int64
22 deposit_type 119390 non-null object
23 agent 103050 non-null float64
24 company 6797 non-null float64
25 days_in_waiting_list 119390 non-null int64
26 customer_type 119390 non-null object
27 adr 119390 non-null float64
28 required_car_parking_spaces 119390 non-null int64
29 total_of_special_requests 119390 non-null int64
30 reservation_status 119390 non-null object
31 reservation_status_date 119390 non-null object
dtypes: float64(4), int64(16), object(12)
memory usage: 29.1+ MB
data.describe()
| is_canceled | lead_time | arrival_date_year | arrival_date_week_number | arrival_date_day_of_month | stays_in_weekend_nights | stays_in_week_nights | adults | children | babies | is_repeated_guest | previous_cancellations | previous_bookings_not_canceled | booking_changes | agent | company | days_in_waiting_list | adr | required_car_parking_spaces | total_of_special_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119386.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 103050.000000 | 6797.000000 | 119390.000000 | 119390.000000 | 119390.000000 | 119390.000000 |
| mean | 0.370416 | 104.011416 | 2016.156554 | 27.165173 | 15.798241 | 0.927599 | 2.500302 | 1.856403 | 0.103890 | 0.007949 | 0.031912 | 0.087118 | 0.137097 | 0.221124 | 86.693382 | 189.266735 | 2.321149 | 101.831122 | 0.062518 | 0.571363 |
| std | 0.482918 | 106.863097 | 0.707476 | 13.605138 | 8.780829 | 0.998613 | 1.908286 | 0.579261 | 0.398561 | 0.097436 | 0.175767 | 0.844336 | 1.497437 | 0.652306 | 110.774548 | 131.655015 | 17.594721 | 50.535790 | 0.245291 | 0.792798 |
| min | 0.000000 | 0.000000 | 2015.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 6.000000 | 0.000000 | -6.380000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 18.000000 | 2016.000000 | 16.000000 | 8.000000 | 0.000000 | 1.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 9.000000 | 62.000000 | 0.000000 | 69.290000 | 0.000000 | 0.000000 |
| 50% | 0.000000 | 69.000000 | 2016.000000 | 28.000000 | 16.000000 | 1.000000 | 2.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 14.000000 | 179.000000 | 0.000000 | 94.575000 | 0.000000 | 0.000000 |
| 75% | 1.000000 | 160.000000 | 2017.000000 | 38.000000 | 23.000000 | 2.000000 | 3.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 229.000000 | 270.000000 | 0.000000 | 126.000000 | 0.000000 | 1.000000 |
| max | 1.000000 | 737.000000 | 2017.000000 | 53.000000 | 31.000000 | 19.000000 | 50.000000 | 55.000000 | 10.000000 | 10.000000 | 1.000000 | 26.000000 | 72.000000 | 21.000000 | 535.000000 | 543.000000 | 391.000000 | 5400.000000 | 8.000000 | 5.000000 |
# 通过观察数据,发现1个异常点:客房日均价(adr)不为负,应剔除adr为负的异常值,
# adr最大值为5400,显然远远大于均值+3倍标准差。
# 用箱形图看下异常值:
import seaborn as sns
plt.figure(figsize=(12, 1))
sns.boxplot(x=list(data["adr"]))
plt.show()

#查看缺失值
missing=data.isnull().sum()
missing[missing != 0]
children 4
country 488
agent 16340
company 112593
dtype: int64
2、数据清洗
1)缺失值填充
① country缺失的,无法补充,缺失值用unknown进行区分 ;
② children缺失的,可理解为没有儿童入住,故订单登记中未填,缺失值用0填充;
③ agent缺失的,可理解为非旅行社预订,故订单登记中未填,缺失值用0填充;
④ company缺失的,可理解为非公司预订,故订单登记中未填,缺失值用0填充;
data_fill = data.fillna(
{
"country":"unknown",
"children":0,
"agent":0,
"company":0
}
)
missing=data_fill.isnull().sum()
missing[missing != 0]
Series([], dtype: int64)
2)异常值处理
(1)adults与children入住人数之和为0;
(2)客房日均价为负,客房日均价高于1000元;
(3)meal中undefined与sc均表示无餐。
# 2)异常值处理
# 1、adults与children入住人数之和为0
drop_a = data_fill[data_fill[["adults","children"]].sum(axis=1) == 0]
# 2、客房日均价为负,客房日均价高于1000元
drop_b = data_fill[(data_fill["adr"]<0) | (data_fill["adr"]>1000)]
data_fill.drop(drop_a.index,inplace=True)
data_done=data_fill[(data_fill["adr"]>=0) & (data_fill["adr"] <1000)]
# 3、meal中undefined与sc均表示无餐
data_done["meal"].replace({"Undefined":"SC"},inplace=True)
data_done.shape # 数据清洗完以后,还剩下119208条记录
(119208, 32)
3、数值型特征归一化,类别特征数值化(one-hot编码)
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler,OneHotEncoder
# 1、数值型特征进行归一化
num_features = ["lead_time",
"arrival_date_week_number",
"arrival_date_day_of_month",
"stays_in_weekend_nights",
"stays_in_week_nights",
"adults",
"children",
"babies",
"is_repeated_guest",
"previous_cancellations",
"previous_bookings_not_canceled",
"agent",
"company",
"required_car_parking_spaces",
"total_of_special_requests",
"adr"]
num_transformer = Pipeline(
steps=[
('imputer', SimpleImputer(strategy='constant',fill_value=0)), # 将空值填充为自定义的值
('scaler', StandardScaler()) # 数据归一化
]
)
# 2、类别特征标准化(one-hot)
cat_features = ["hotel",
"arrival_date_month",
"meal",
"market_segment",
"distribution_channel",
"reserved_room_type",
"deposit_type",
"customer_type"]
cat_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="constant", fill_value="Unknown")),
("onehot", OneHotEncoder(handle_unknown='ignore'))
]
)
features = num_features + cat_features
from sklearn.compose import ColumnTransformer
'''
SimpleImputer类可用于替换缺少的值,MinMaxScaler类可用于缩放数值,而OneHotEncoder可用于编码分类变量。
ColumnTransformer()在Python的机器学习库scikit-learn中,可以选择地进行数据转换。
要使用ColumnTransformer,必须指定一个转换器列表。
每个转换器是一个三元素元组,用于定义转换器的名称,要应用的转换以及要应用于其的列索引,例如:(名称,对象,列)
'''
preprocessor = ColumnTransformer(
transformers=[
('num', num_transformer, num_features),
('cat', cat_transformer, cat_features)
]
)
4、选用随机森林建模,挑选最佳参数
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold, cross_val_score,train_test_split,GridSearchCV
X = data_done.drop("is_canceled",axis=1)
y = data_done["is_canceled"]
# 初步调参n_estimators
# scorel = []
# for i in range(0,200,10):
# rfc_model = RandomForestClassifier(n_estimators=i+1,
# n_jobs=-1,
# random_state=0)
# rfc = Pipeline(
# steps=[
# ('preprocessor', preprocessor),
# ('model',rfc_model)
# ]
# )
# split = KFold(n_splits=10, shuffle=True, random_state=42)
# rfc_t_s = cross_val_score(rfc,
# X,
# y,
# cv=split,
# scoring="accuracy",
# n_jobs=-1
# ).mean()
# print('step',rfc_t_s)
# scorel.append(rfc_t_s)
# print(max(scorel),(scorel.index(max(scorel))*10) + 1)
# plt.figure(figsize=[20,5])
# plt.plot(range(1,201,10),scorel)
# plt.show()
# 再次调参n_estimators,注意数据集训练比较慢
scorel = []
for i in range(150,170):
rfc_model = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=0)
rfc = Pipeline(
steps=[
('preprocessor', preprocessor),
('model',rfc_model)
]
)
split = KFold(n_splits=10, shuffle=True, random_state=42)
rfc_t_s = cross_val_score(rfc,
X,
y,
cv=split,
scoring="accuracy",
n_jobs=-1
).mean()
print('step:',i,',score=',rfc_t_s)
scorel.append(rfc_t_s)
# 从图像可以看出来,n_estimators应该为161
print(max(scorel),([*range(150,170)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(150,170),scorel)
plt.show()
param_grid = {
"model__max_depth":[*range(1,40,10)],
'model__min_samples_leaf':[*range(1,50,10)]
}
rfc_model_t = RandomForestClassifier(n_estimators=161,
criterion="gini",
max_features=0.4,
n_jobs=-1,
random_state=0)
rfc_t = Pipeline(
steps=[
('preprocessor', preprocessor),
('model',rfc_model_t)
]
)
split_t = KFold(n_splits=10, shuffle=True, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
GS = GridSearchCV(rfc_t, param_grid, cv=split_t)
GS.fit(X_train, y_train)
GS.best_params_
#
5、选用最佳参数训练模型
#训练模型,评估模型
rfc_model = RandomForestClassifier(n_estimators=161
,criterion="gini"
,max_depth=31
,min_samples_leaf=1
,max_features=0.4
,n_jobs=-1
,random_state=0)
rfc = Pipeline(steps=[
('preprocessor', preprocessor),
('model',rfc_model)
])
rfc = rfc.fit(X_train, y_train)
score_=rfc.score(X_test, y_test)
score_
0.8683835248720745
#交叉检验
split = KFold(n_splits=10, shuffle=True, random_state=42)
rfc_s = cross_val_score( rfc,
X,
y,
cv=split,
scoring="accuracy",
n_jobs=-1)
plt.plot(range(1,11),rfc_s,label = "RandomForest")

6、特征重要性
#特征重要性
import eli5
onehot_columns = list(rfc.named_steps['preprocessor'].
named_transformers_['cat'].
named_steps['onehot'].
get_feature_names_out(input_features=cat_features))
feat_imp_list = num_features + onehot_columns
#按重要排序的前10个重要特征及其系数
feat_imp_df = eli5.formatters.as_dataframe.explain_weights_df(
rfc.named_steps['model'],
feature_names=feat_imp_list)
feat_imp_df.head(10)
| feature | weight | std | |
|---|---|---|---|
| 0 | deposit_type_Non Refund | 0.144919 | 0.108617 |
| 1 | lead_time | 0.140804 | 0.016317 |
| 2 | adr | 0.093004 | 0.003363 |
| 3 | deposit_type_No Deposit | 0.075658 | 0.103332 |
| 4 | arrival_date_day_of_month | 0.066274 | 0.002718 |
| 5 | arrival_date_week_number | 0.053368 | 0.002609 |
| 6 | total_of_special_requests | 0.052200 | 0.011193 |
| 7 | agent | 0.043441 | 0.005135 |
| 8 | previous_cancellations | 0.041885 | 0.014677 |
| 9 | stays_in_week_nights | 0.039749 | 0.002220 |
7、对权重大于10%的影响因素(提前预订时间以及保证金类型)进行进一步分析
# 1、预定取消与提前预定时间的关系
plt.figure(figsize=(12, 8))
lead_cancel_data = data_done.groupby("lead_time")["is_canceled"].describe()
sns.scatterplot(x=lead_cancel_data.index, y=lead_cancel_data["mean"].values * 100,color='olive')
plt.title("提前预定时间对预订取消率的影响", fontsize=16)
plt.xlabel("提前预订时间", fontsize=16)
plt.ylabel("预订取消的概率", fontsize=16)
plt.show()
提前预订时间越长,预订取消率越高。酒店应当结合具体经营成本考虑是否限定提前预订的最长时间,以避免资源的占用。
#预定取消与保证金类型的关系
plt.figure(figsize=(12, 8))
deposit_cancel_data = data_done.groupby("deposit_type")["is_canceled"].describe()
sns.barplot(x=deposit_cancel_data.index, y=deposit_cancel_data["mean"] * 100,palette="Blues")
plt.title("Effect of deposit_type on cancelation", fontsize=16)
plt.xlabel("Deposit type", fontsize=16)
plt.ylabel("Cancelations [%]", fontsize=16)
plt.show()
押金不退还的预订取消率在所有押金类型中最高,这种现象与观念中的消费者心理有些背离,需要再一步分析。
事实上,各个市场细分渠道中,
线下旅行社代理预订以及团体预订的取消率最高,
而在押金类型中,无押金的预订量主要集中在在线预订,
而不退押金的预订量主要集中在线下旅行社代理预订以及团体预订,导致不退押金的预订取消率较高。
酒店可以尝试设计问卷,对线下旅行社以及团体进行访问,探寻原因及解决方法。