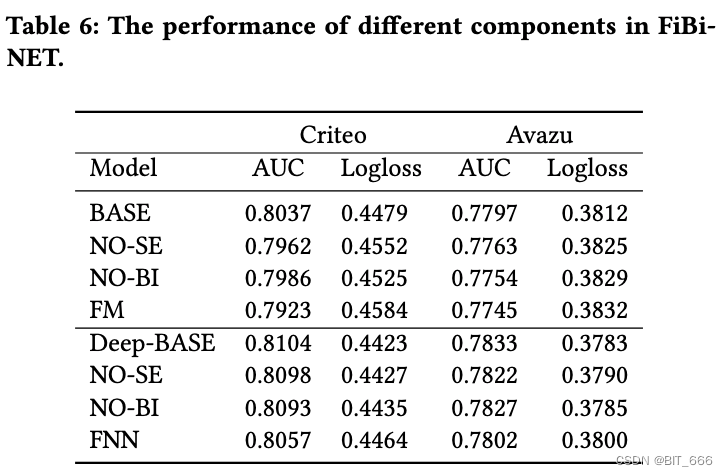
以mnist图像生成样本为例,详细解释diffusion的每个步骤和过程
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process),如下图所示。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可以用来生成数据,这里我们将通过变分推断来进行建模和求解。
另外要指出的是,扩散过程往往是固定的,即采用一个预先定义好的variance schedule,比如DDPM就采用一个线性的variance schedule。
扩散过程的一个重要特性是我们可以直接基于原始数据对于任意步长的xt进行采样
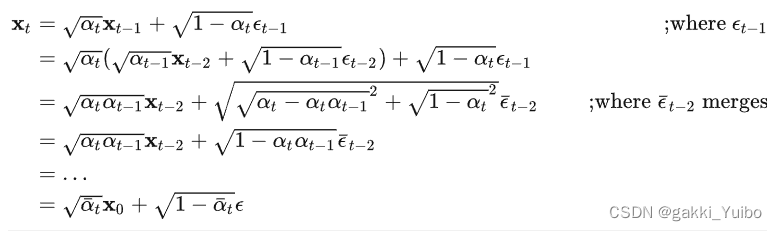
记住这个公式,这个公式很重要,因为它可以直接从原图片推断出,经过t次加噪声之后的图像。
反向过程
扩散是将数据噪声化,那么反向的过程就是一个逐步去噪的过程,如果我们知道反向过程每一步的真实的噪声分布,那么从一个随机噪声开始就能生成一个真实的样本,所以反向过程就是生成数据的过程,我们可以用神经网络来估计这些噪声的分布。
推导公式的过程比较麻烦,我这里直接把bubbliiiing大佬结论放在这里

也就是说,我们加噪声的时候,可以一步到位直接从原始图像知道迭代了N步以后的噪声,但是图像还原的时候,要迭代着一步步计算之前的噪声,去噪,然后一步步把图片还原出来
这里我们先实现一个用于预测噪声图像的unet的网络结构
我们模型会有两个输入,一个是时间的步长,表示噪声加了多少步了,第二个是原图,但是时间的步长它是一个数值,比如0,1,2等,它是一个整数,这里我们需要把0,1,2等整数步长转化为离散类型的矩阵tensor才能跟模型的特征图做累加。
把整数转化为矩阵tensor的过程叫做embedding,在更复杂的任务里面它也可以是把文字,词组等转化为矩阵
这个实现,我们手动来实现一个embedding层,(其实就是把步长1,2,3等转化为矩阵)
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.datasets import MNIST
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
class EmbedFC(nn.Module):
def __init__(self, input_dim, emb_dim):
super(EmbedFC, self).__init__()
'''
generic one layer FC NN for embedding things
'''
self.input_dim = input_dim
layers = [
nn.Linear(input_dim, emb_dim),
nn.GELU(),
nn.Linear(emb_dim, emb_dim),
]
self.model = nn.Sequential(*layers)
def forward(self, x):
x = x.view(-1, self.input_dim)
return self.model(x)
## 对于我们的embedding层进行测试一下看看功能
if __name__ == "__main__":
#当前步长为80,总步长为400
N = 80
total_T = 400
x1 = torch.tensor([N/total_T])
# 把1维的输入转化为128维的矩阵
model1 = EmbedFC(1,128)
y1 = model1(x1)
print(y1.shape)
上面的输出为
torch.Size([1, 128])
接下来我们要实现unet的部分;Unet是一个对称结构的网络,很多博客都有,详情看看bubbliiiing大佬的博客,最早用于图像分割领域,这里我们用于预测我们的噪声图:
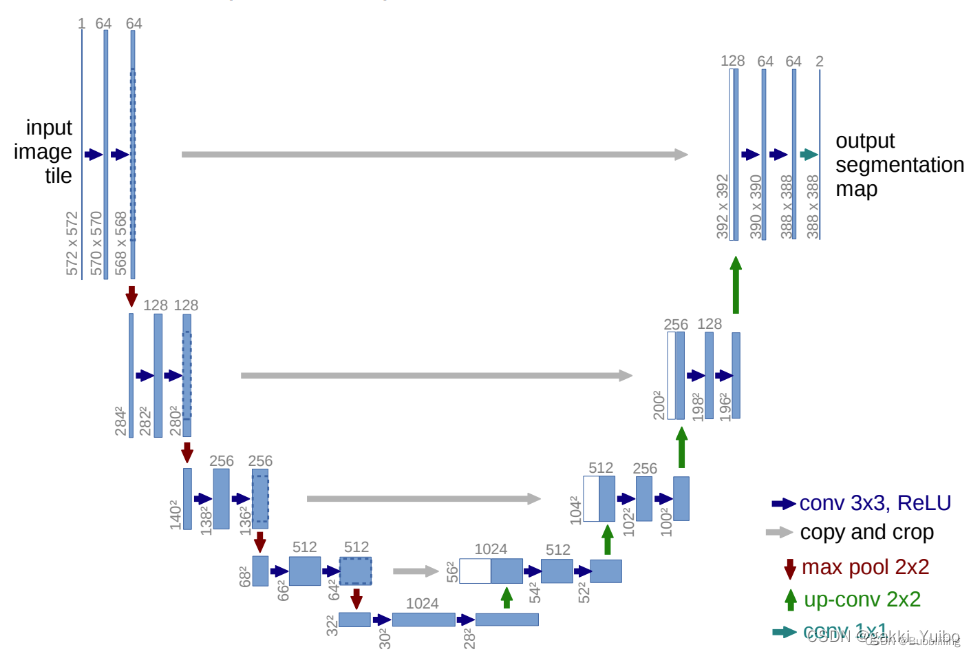
可以直接拉取别人的改一改也行:
class ResidualConvBlock(nn.Module):
def __init__(
self, in_channels: int, out_channels: int, is_res: bool = False
) -> None:
super().__init__()
'''
standard ResNet style convolutional block
'''
self.same_channels = in_channels==out_channels
self.is_res = is_res
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.BatchNorm2d(out_channels),
nn.GELU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.BatchNorm2d(out_channels),
nn.GELU(),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.is_res:
x1 = self.conv1(x)
x2 = self.conv2(x1)
# this adds on correct residual in case channels have increased
if self.same_channels:
out = x + x2
else:
out = x1 + x2
return out / 1.414
else:
x1 = self.conv1(x)
x2 = self.conv2(x1)
return x2
class UnetDown(nn.Module):
def __init__(self, in_channels, out_channels):
super(UnetDown, self).__init__()
'''
process and downscale the image feature maps
'''
layers = [ResidualConvBlock(in_channels, out_channels), nn.MaxPool2d(2)]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UnetUp(nn.Module):
def __init__(self, in_channels, out_channels):
super(UnetUp, self).__init__()
'''
process and upscale the image feature maps
'''
layers = [
nn.ConvTranspose2d(in_channels, out_channels, 2, 2),
ResidualConvBlock(out_channels, out_channels),
ResidualConvBlock(out_channels, out_channels),
]
self.model = nn.Sequential(*layers)
def forward(self, x, skip):
x = torch.cat((x, skip), 1)
x = self.model(x)
return x
class Unet(nn.Module):
def __init__(self, in_channels, n_feat = 256, n_classes=10):
super(Unet, self).__init__()
self.in_channels = in_channels
self.n_feat = n_feat
self.n_classes = n_classes
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
self.down1 = UnetDown(n_feat, n_feat)
self.down2 = UnetDown(n_feat, 2 * n_feat)
self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.up0 = nn.Sequential(
# nn.ConvTranspose2d(6 * n_feat, 2 * n_feat, 7, 7), # when concat temb and cemb end up w 6*n_feat
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, 7, 7), # otherwise just have 2*n_feat
nn.GroupNorm(8, 2 * n_feat),
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1),
nn.GroupNorm(8, n_feat),
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1),
)
def forward(self, x,t):
x = self.init_conv(x)
down1 = self.down1(x)
down2 = self.down2(down1)
hiddenvec = self.to_vec(down2)
print(t)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
up1 = self.up0(hiddenvec)
# up2 = self.up1(up1, down2) # if want to avoid add and multiply embeddings
up2 = self.up1(up1+ temb1, down2) # add and multiply embeddings
up3 = self.up2(up2+ temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
if __name__ == "__main__":
x = torch.rand(1,1,28,28)
t = torch.tensor([80/400])
model = Unet(in_channels=1,n_feat=128)
y = model(x,t)
print(y.shape)
输出为:torch.Size([1, 1, 28, 28])
这里我们已经把EbedFC的代码加入UNet中用于对特征图中叠加我们的时间步长信息,这样子在我们在训练的过程中就有了随着时间波动的噪声图。到这里网络已经搭建完毕了。接下来我们要训练我们的加噪和去噪的过程。
第一步就是结合上面的公式,从原图直接推导出第N次加噪后的图像。
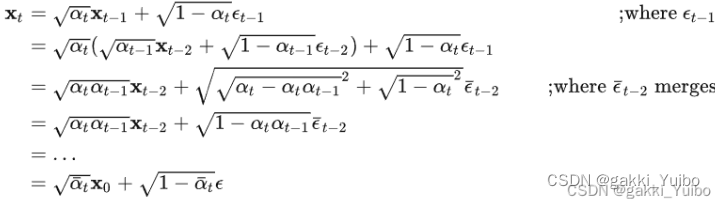
也就是这里:
实现代码为:
#先随机选取一个步长N,代表了加噪N次后的原图和噪声叠加的图像
n_T = 400 #加噪的总步长
#随机加噪声的步长
_ts = torch.randint(1, n_T+1, (x.shape[0],))
#噪声图
noise = torch.randn_like(x) # eps ~ N(0, 1),这就是公式中的eps
sqrtab = torch.sqrt(alphabar_t)
sqrtmab = torch.sqrt(1 - alphabar_t)
x_t = (
sqrtab[_ts, None, None, None] * x
+ sqrtmab[_ts, None, None, None] * noise
)
## x_t就是经过了_ts步加噪以后的有x生成的噪声图
这里我们就推断出了经过N次加噪以后的合成图,我们的Unet的输入是利用加噪后的图像和步长信息反推出上一步的噪声图,但是上一步的噪声图其实就是服从标准正太分布N(0,1)的噪声图
所以我们利用这两个信息来计算一下loss
loss = nn.MSELoss(noise, uNet(x_t, _ts / self.n_T))
loss的计算就算是搞明白了,接下来我们开始计算恢复的过程
由于恢复图像