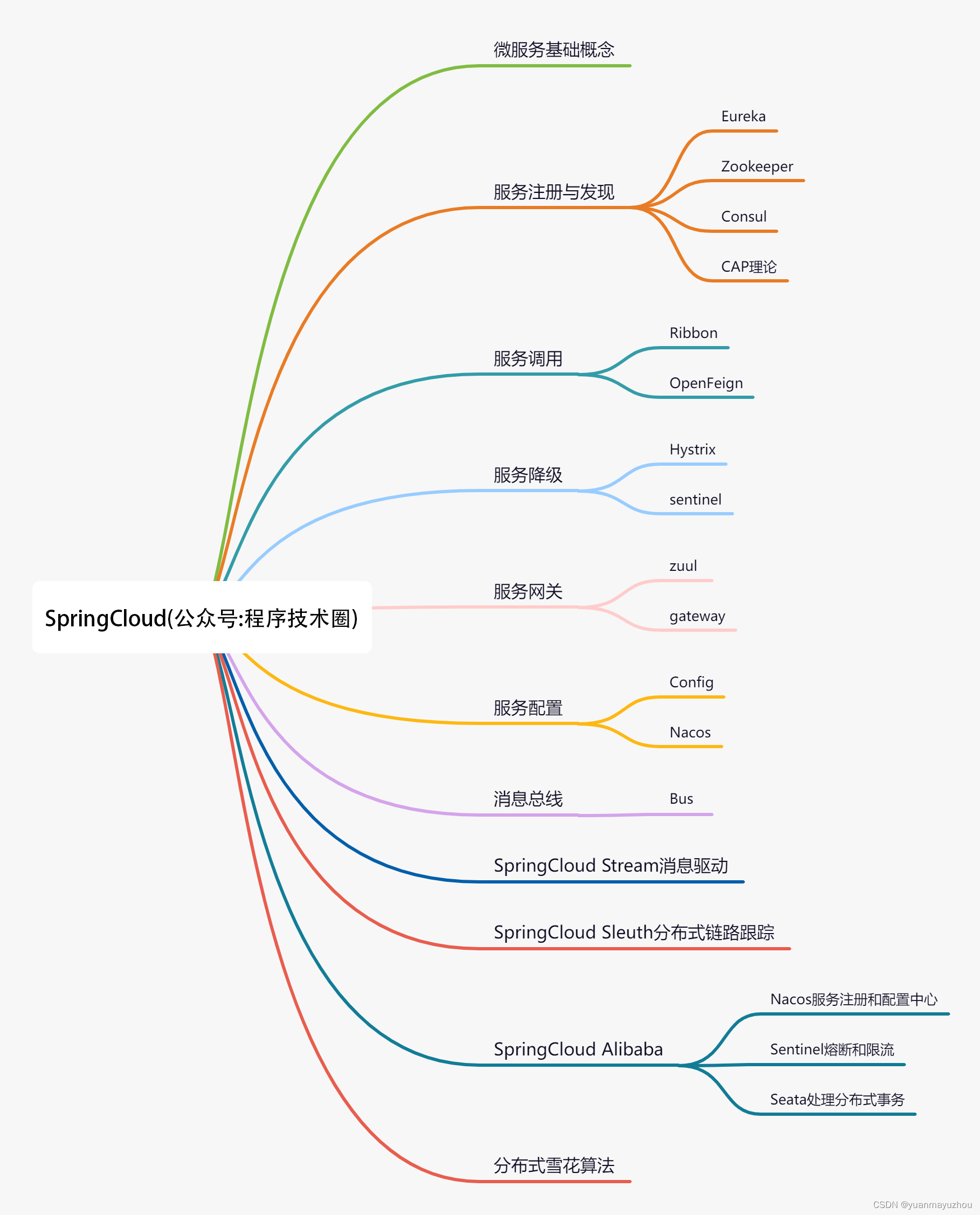
索引
- 前言
- 1. Spark部署
- 1.1 下载Spark
- 1.2 解压Spark
- 1.3 修改环境变量
- 1.4 修改主机Spark配置文件
- 1.4.1 slaves.template文件配置
- 1.4.2 spark-env.sh.template文件配置
- 1.5 分享主机Spark到从机
- 1.6 启动Spark集群(★重启后的操作)
- 1.7 通过jps查看是否启动成功
- 1.8 通过网页查看是否启动成功
- 2. Scala Maven项目访问Spark(local模式)100个随机数求最大值
- 2.1 下载Scala IDE
- 2.2 解压Scala IDE
- 2.3 下载Scala(主机+从机)
- 2.4 添加环境变量(主机+从机)
- 2.5 创建Scala项目
- 2.6 配置Scala项目
- 2.6.1 设置Maven
- 2.6.2 pom.xml添加依赖
- 2.6.3 设置Scala Complier
- 2.6.4 添加Spark的jar包
- 2.7 创建代码(Object)
- 2.7.1 Random
- 2.7.2 Max
- 2.8 运行程序
- 2.9 ★解决内存问题、其他问题
前言
直接进入正题吧。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下速通指南专栏。
1. Spark部署
有了前几次的经验这次就简单一点了。
1.1 下载Spark
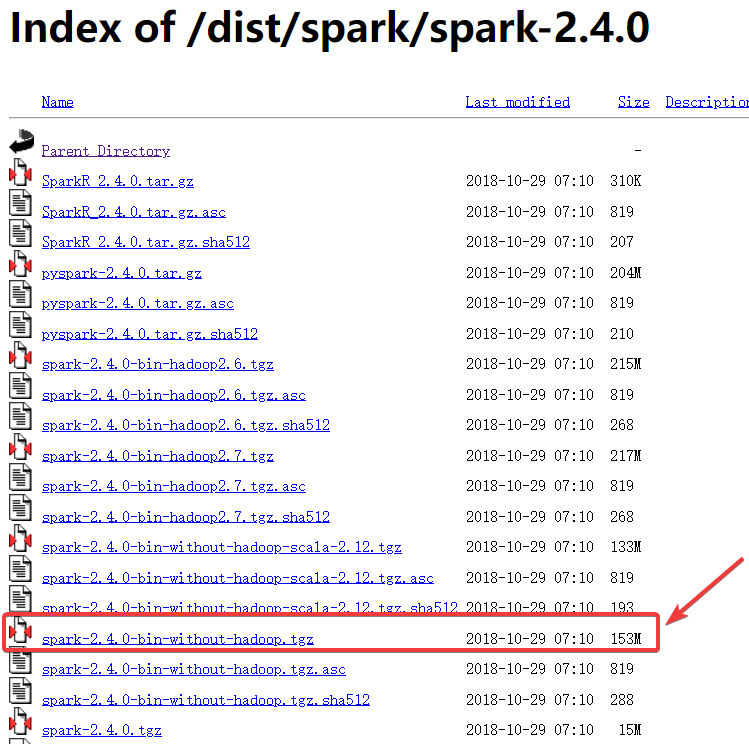
直接在官网下载的spark-2.4.0,注意是下载这个153M的压缩包。
1.2 解压Spark
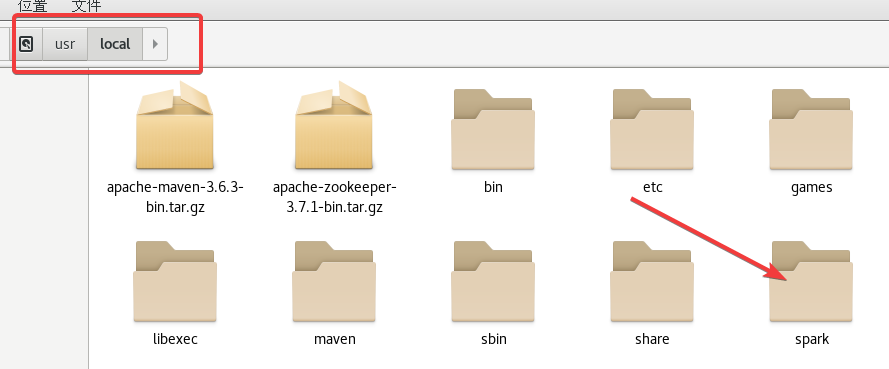
首先把压缩包放到/usr/local目录下
然后依次执行下面的指令(在哪里打开终端都行):
cd /usr/localtar -zxvf spark-2.4.0-bin-without-hadoop.tgzmv spark-2.4.0-bin-without-hadoop sparkchown -R root:root spark
此时你的/usr/local目录下就有spark目录了。
1.3 修改环境变量
首先vi /etc/profile,在文件的末尾加入以下内容:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export JAVA_LIBRARY_PATH=/user/hadoop/hadoop-3.3.1/lib/native
第三行是Hadoop路径/lib/native,根据自己的调整!
:wq保存后关闭,之后使用指令source /etc/profile刷新一下。
1.4 修改主机Spark配置文件
配置文件的路径是/usr/local/spark/conf。
1.4.1 slaves.template文件配置
cd /usr/local/spark/conf 进入配置文件目录
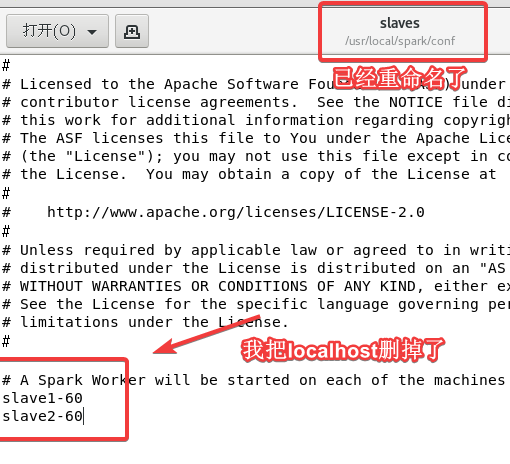
cp slaves.template slaves 将文件重命名为slaves
vi slaves 进入修改文件,后面添加上两个从机的主机名(根据自己的改!)
1.4.2 spark-env.sh.template文件配置
这里一定要仔细修改!大部分问题都出自这里。
cp spark-env.sh.template spark-env.sh 重命名为spark-env.sh
vi spark-env.sh 进入修改文件,在文件末尾添加以下内容:
export SPARK_DIST_CLASSPATH=$(/user/hadoop/hadoop-3.3.1/bin/hadoop classpath)
export HADOOP_CONF_DIR=/user/hadoop/hadoop-3.3.1/etc/hadoop
export SPARK_MASTER_IP= master60
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
export HADOOP_HOME=/user/hadoop/hadoop-3.3.1
export SPARK_WORKER_MEMORY=1024m
export SPARK_WORKER_CORES=1
其中第1、2、5行是修改Hadoop的路径;第3行修改主机的主机名;第4行是JDK的路径;第6、7行不需要改。
如果忘了在哪里可以看一下自己的~/.bashrc或者/etc/profile文件之前配置过的。
1.5 分享主机Spark到从机
在主机依次进行以下操作:
cd /usr/localtar -zcf spark.master.tar.gz sparkscp spark.master.tar.gz slave1-60:/usr/local/spark.master.tar.gz(修改为从机1的主机名)scp spark.master.tar.gz slave2-60:/usr/local/spark.master.tar.gz(修改为从机2的主机名)
在两个从机依次执行以下操作(两台从机都执行依次!):
cd /usr/localtar -zxf spark.master.tar.gzchown -R root /usr/local/spark
1.6 启动Spark集群(★重启后的操作)
在主机使用下面两个指令即可:
/user/hadoop/hadoop-3.3.1/sbin/start-all.sh(启动Hadoop)/usr/local/spark/sbin/start-all.sh(启动Spark)
注意路径!注意路径!注意路径!Hadoop路径可能与我的不同。
这里就会出现问题,Spark和Hadoop都有start-all.sh的指令并且都被写到了环境变量中,你直接使用start-all.sh大概率是会用Spark的指令。为了避免这种不必要的误会,之后再重启请使用完整的路径来start-all.sh。
并且这次实验与上一次没关系,不需要打开Zookeeper以及HBase。
1.7 通过jps查看是否启动成功
在主机上jps可以看到至少以下两个进程:

在从机上jps可以看到至少以下两个进程:

1.8 通过网页查看是否启动成功
浏览器打开主机的主机名或IP:8080。
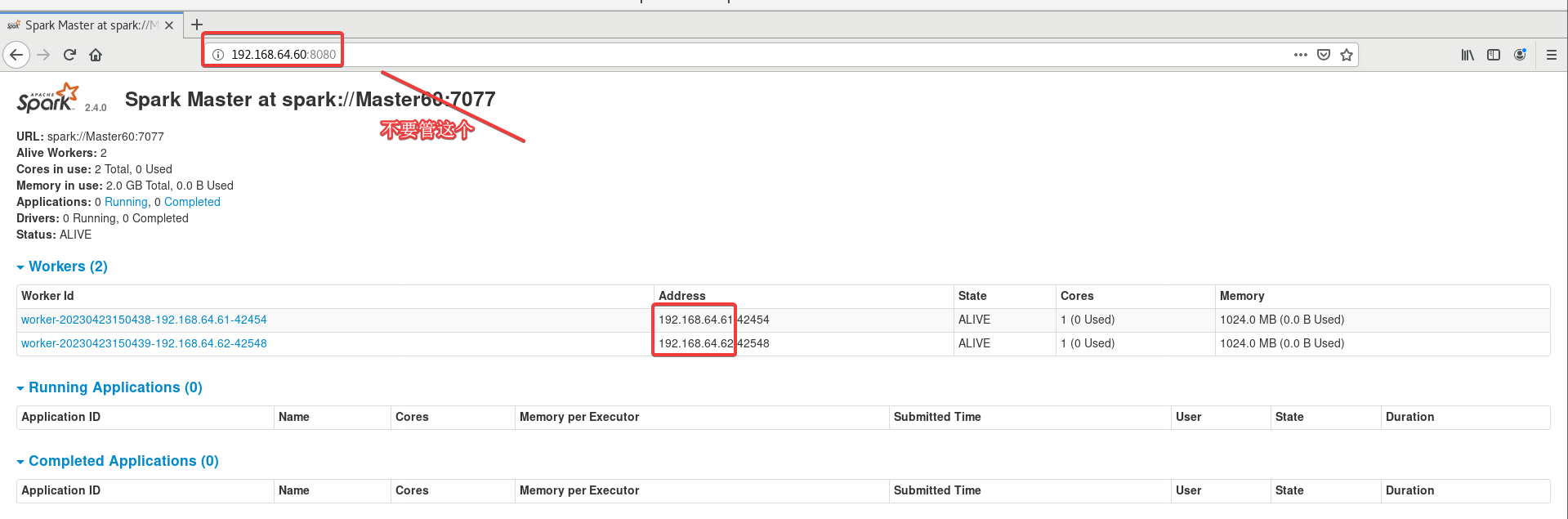
打不开就把三台虚拟机重启之后按照1.6操作一遍。
再查看一下spark-shell,退出的指令是:quit有:的!!!,如果不正常退出,之后再启动可能也打不开4040端口。
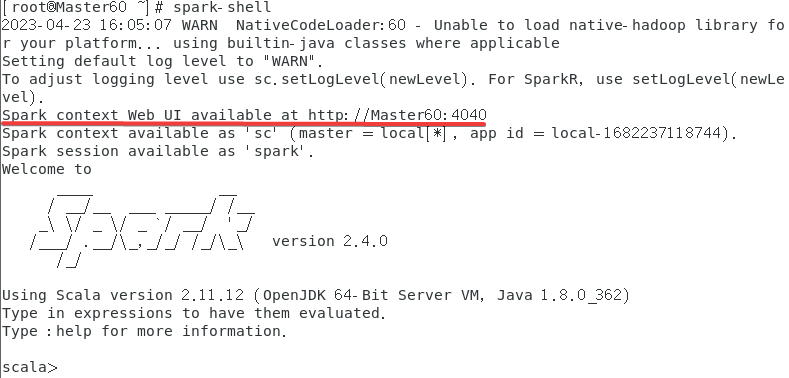
再看一下4040端口,注意需要运行spark-shell才能进入,上图也可以看的出来再使用了spark-shell之后才开启了这个端口。
连接失败是因为没开spark-shell。
一直加载打不开,可能是因为强制关闭了spark-shell,虚拟机重开再打开服务可以解决。
2. Scala Maven项目访问Spark(local模式)100个随机数求最大值
19级是单词计数,感兴趣可以看一下涛哥的博客。
2.1 下载Scala IDE
直接下载,点了之后就下载了。
2.2 解压Scala IDE
拖到usr/local。
终端通过指令解压一下:tar -zxvf scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz
解压出来的是一个eclipse目录,
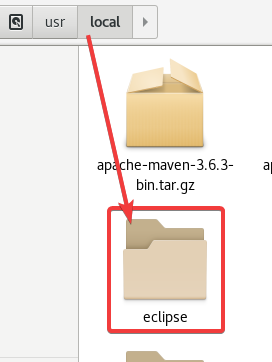
之后的编程是通过这个目录中的eclipse!不要用桌面上的!
2.3 下载Scala(主机+从机)
注意确保Spark版本是2.4.0(前面下载的就是)
直接依次执行以下操作:
cd /usr/localwget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgztar -zxvf scala-2.11.8.tgzmv scala-2.11.8 scala
2.4 添加环境变量(主机+从机)
vi /etc/profile 进入文件在末尾添加以下内容:
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
然后source /etc/profile刷新一下。
在终端输入scala看一下是否配置成功,:quit退出。
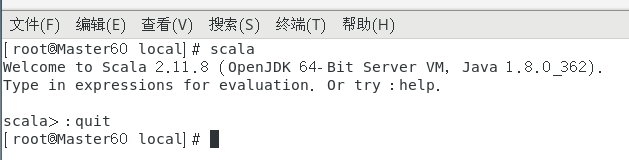
注意!Scala主机从机都需要下载,也就是2.3、2.4三台虚拟机都要操作。
2.5 创建Scala项目
打开Scala IDE,
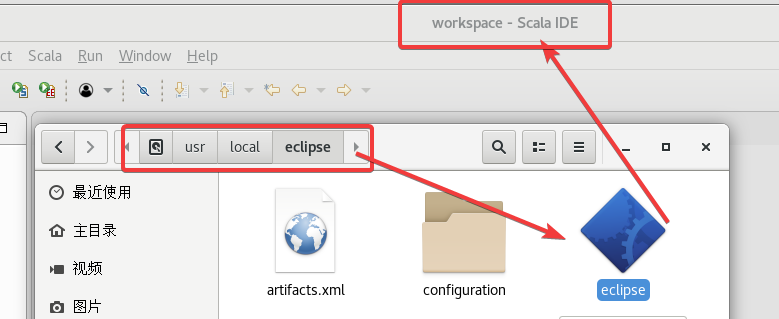
创建一个Scala项目,
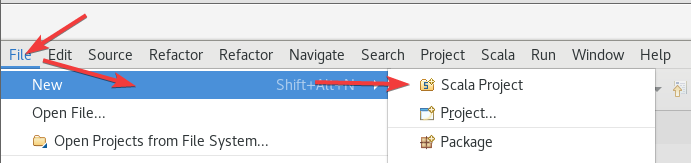
随便起了个名,无所谓的,
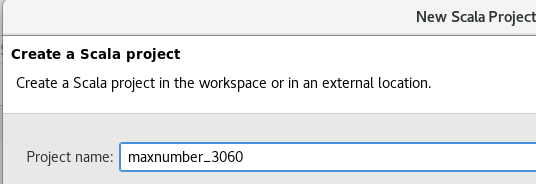
右键项目 ->Configure ->Convert to Maven Project,
没改直接下一步了,后面还可以在pom.xml里改,
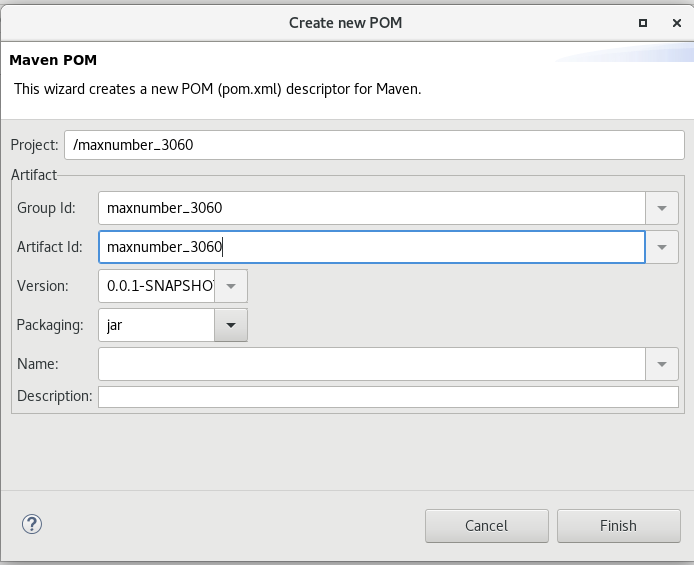
2.6 配置Scala项目
如果找不到类什么的错误可以重新创建一个项目,从2.6.2继续即可。2.6.1配置之后不会自动变化了。
2.6.1 设置Maven
两个地方要改。
点击Window -> Preferences -> Maven -> Installations。
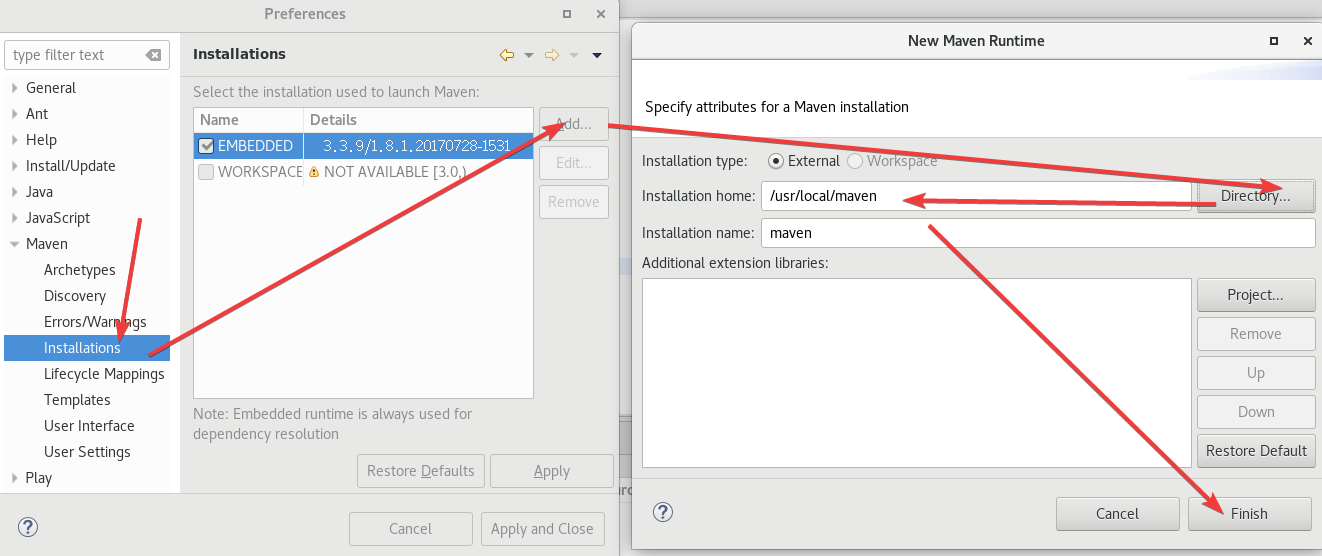
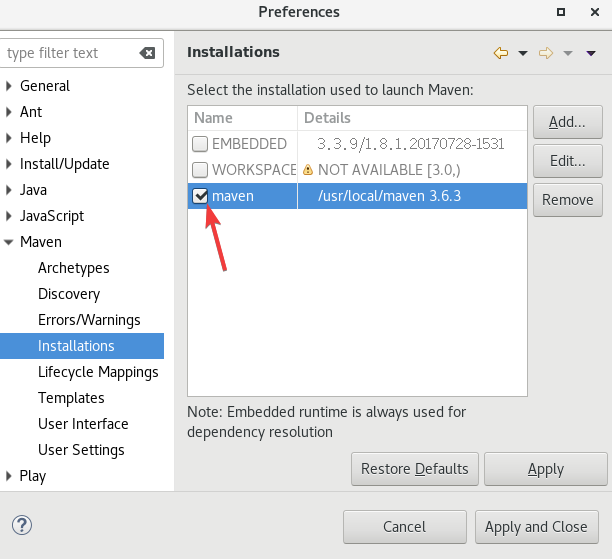
添加了以后记得选上,
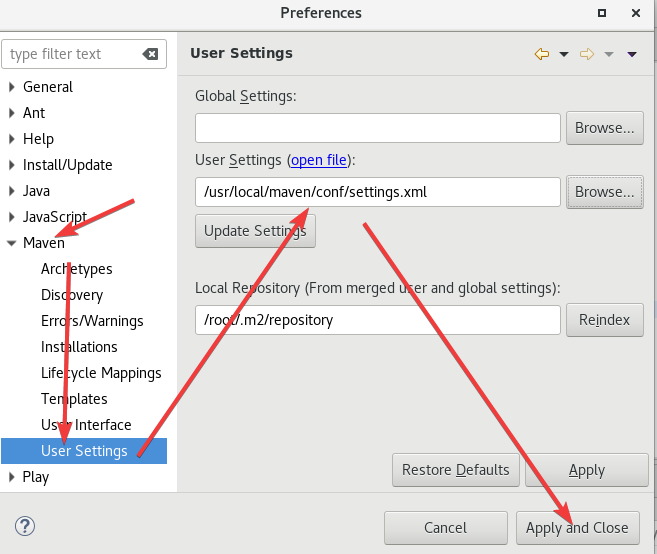
点击Window -> Preferences -> Maven -> User Settings。
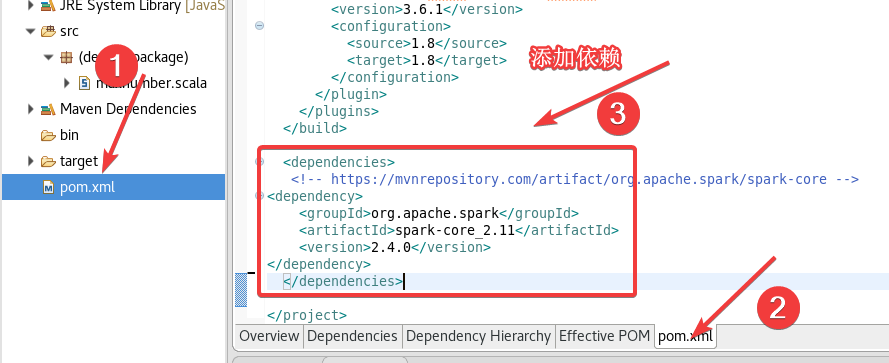
2.6.2 pom.xml添加依赖
打开pom.xml,添加以下内容:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
2.6.3 设置Scala Complier
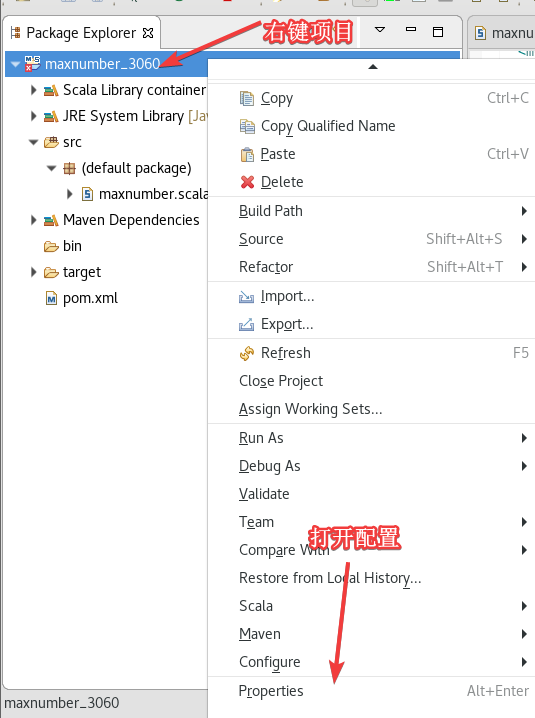
右键项目,打开Properties,
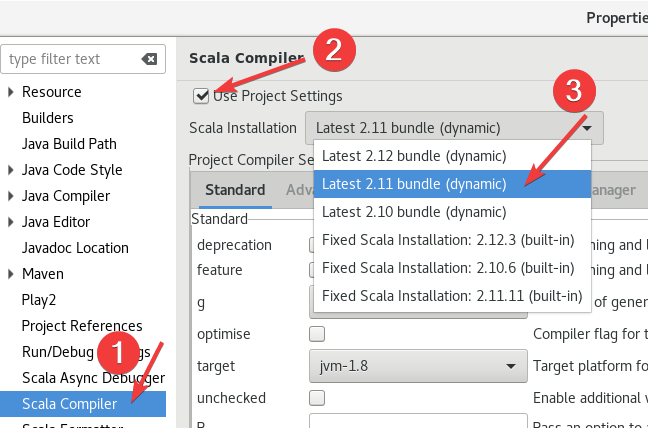
按照下图选择Scala Compiler然后确认,
2.6.4 添加Spark的jar包
右键项目 ->Build Path ->Configure Build Path。

上次做过这个,直接添加就行了,
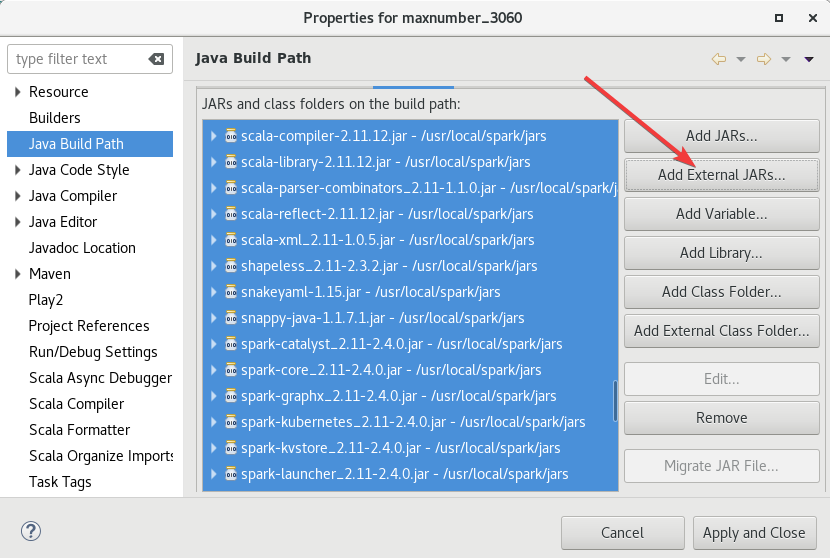
添加的路径是/usr/local/spark/jars,直接ctrl+A全选添加就可以。
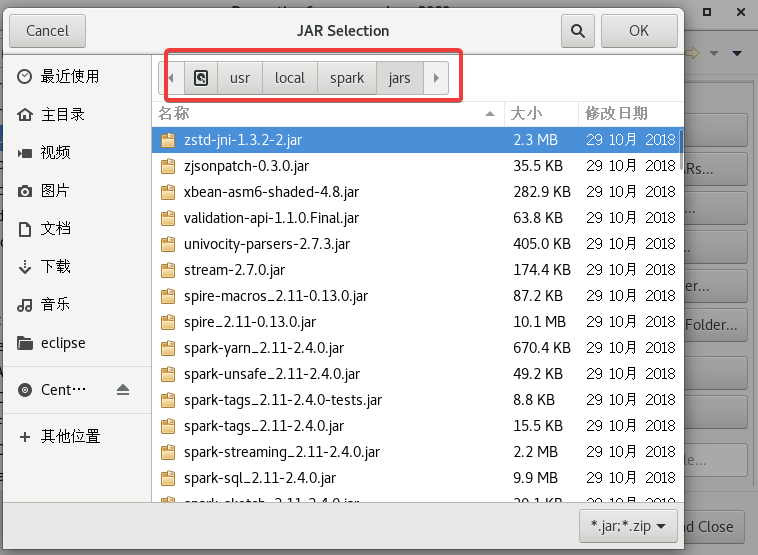
2.7 创建代码(Object)
右键src -> new ->Scala Object,名字随便起。两个代码一个Random一个Max。
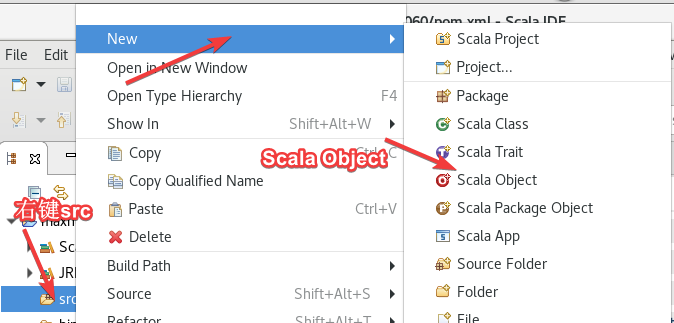
2.7.1 Random
把主机名全改了!
Random代码如下,这个是生成50个1到10000之间随机数,并保存到HDFS下面的/tmp/maxnumber/word_060.txt(根据自己学号改)
import org.apache.spark.{SparkConf, SparkContext}
object Random{
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Random").setMaster("local")
val sc = new SparkContext(conf)
val randoms = sc.parallelize(Seq.fill(100)(scala.util.Random.nextInt()))
println(s"The maximum number is: $max")
randoms.collect().foreach(println)
val outputPath = "hdfs://192.168.64.60:9000/tmp/maxnumber"
randoms.saveAsTextFile(outputPath + "/word_060.txt")
sc.stop()
}
}
2.7.2 Max
Max代码如下,这个是读取word_060.txt文件然后找最大值输出到/tmp/maxnumber/max(无所谓自己改)
import org.apache.spark.{SparkConf, SparkContext}
object Max{
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Max").setMaster("local")
val sc = new SparkContext(conf)
val filePath = "hdfs://192.168.64.60:9000/tmp/maxnumber/word_060.txt"
val max = sc.textFile(filePath)
.map(_.toInt)
.cache()
.max()
println(s"The maximum number is: $max")
val outputPath = "hdfs://192.168.64.60:9000/tmp/maxnumber/max"
sc.parallelize(Seq(max)).saveAsTextFile(outputPath)
sc.stop()
}
}
2.8 运行程序
……卡的要命,我又多分配了点运存之后才好一点。
Run As ->Scala Application。
先运行Random生成随机数输出到控制台,并且保存。
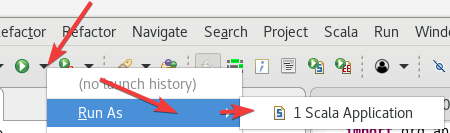
运行成功之后,再运行第二个Max程序。
打开9870端口的网页,打开HDFS的目录

进去以后打开tmp文件,
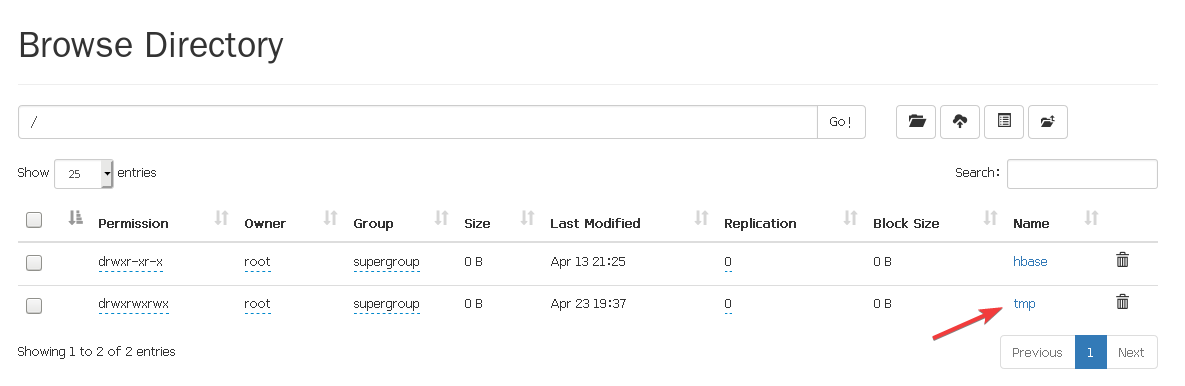
进入到tmp/maxnumber看一下,
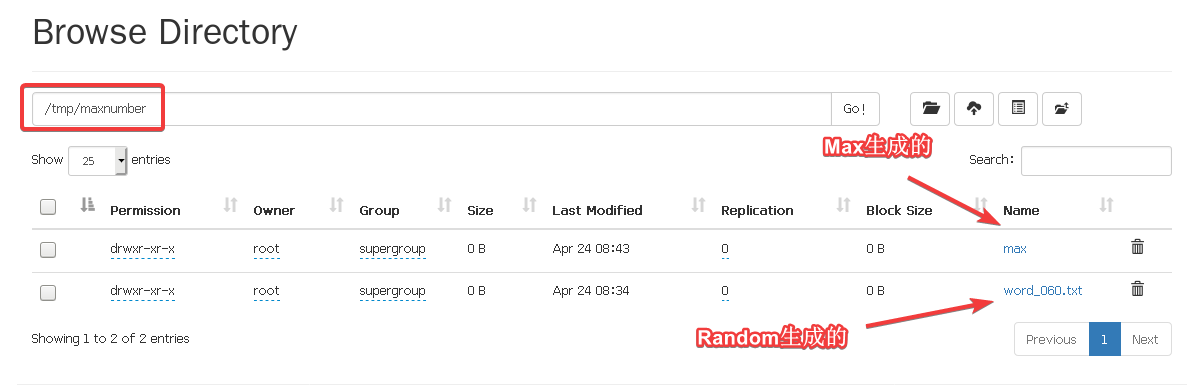
具体怎么看用max演示一下,
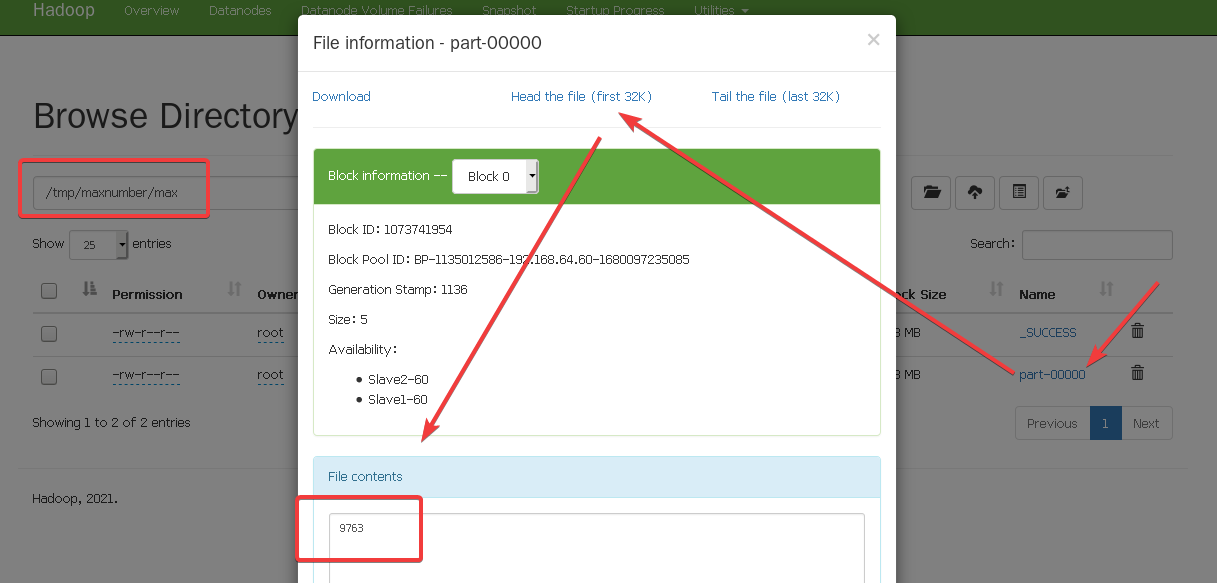
OK!到此结束。
2.9 ★解决内存问题、其他问题
如果运行报错内存什么什么玩意,
在Run Configurations的Arguments的VM arguments里添加一句:
-Xmx512m。
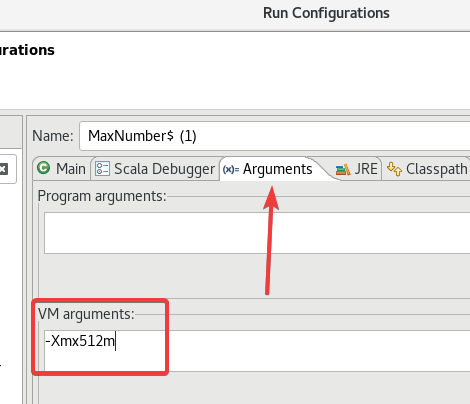
或者是给虚拟机多分配点内存……大概。
其他问题一般重启虚拟机然后重开Hadoop以及Spark就行了。