使用GPT2预测福彩3D项目
个人总结彩票数据是随机的,可以预测到1-2个数字,但是有一两位总是随机的
该项目紧做模型学习用,通过该项目熟练模型训练调用生成过程.
福彩3D数据下载
https://www.17500.cn/getData/3d.TXT
data数据格式 处理后数据格式 每行
2023 03 08 9 7 3
训练输入格式
一期 12个token,一次20期 ,240个token
[年][SEP][月][SEP][日][SEP][开奖号码1][SEP][开奖号码2][SEP][开奖号码3][CLS]
2023 03 16 5 7 3
d2= [‘2023’, ‘[SEP]’, ‘0’, ‘3’, ‘[SEP]’, ‘16’, ‘[SEP]’, ‘5’, ‘[SEP]’, ‘7’, ‘[SEP]’, ‘3’, ‘[CLS]’]
l1= [2023, 2083, 0, 3, 2083, 16, 2083, 5, 2083, 7, 2083, 3, 2085]
2023 03 17 1 9 8
d2= [‘2023’, ‘[SEP]’, ‘0’, ‘3’, ‘[SEP]’, ‘17’, ‘[SEP]’, ‘1’, ‘[SEP]’, ‘9’, ‘[SEP]’, ‘8’, ‘[CLS]’]
l1= [2023, 2083, 0, 3, 2083, 17, 2083, 1, 2083, 9, 2083, 8, 2085]
模型生成预测输入,生成 2023-04-15预测结果
[[‘2023’, ‘[SEP]’, ‘04’, ‘[SEP]’, ‘16’, ‘[SEP]’]]
vocab 词汇表
[UNK]
[SEP]
[PAD]
[CLS]
[MASK]
[EOS]
[BOS]
0
1
2
3
4
5
6
7
8
9
01
02
03
04
05
06
07
08
09
10
11
…
2080
2081
config 配置文件
{
“activation_function”: “gelu_new”,
“architectures”: [
“GPT2LMHeadModel”
],
“attn_pdrop”: 0.1,
“bos_token_id”: 2089,
“embd_pdrop”: 0.1,
“eos_token_id”: 2089,
“initializer_range”: 0.02,
“layer_norm_epsilon”: 1e-05,
“model_type”: “gpt2”,
“n_ctx”: 240,
“n_embd”: 768,
“n_head”: 12,
“n_layer”: 12,
“n_positions”: 240,
“resid_pdrop”: 0.1,
“summary_activation”: null,
“summary_first_dropout”: 0.1,
“summary_proj_to_labels”: true,
“summary_type”: “cls_index”,
“summary_use_proj”: true,
“task_specific_params”: {
“text-generation”: {
“do_sample”: true,
“max_length”: 50
}
},
“vocab_size”: 2099
}
生成效果
单期预测
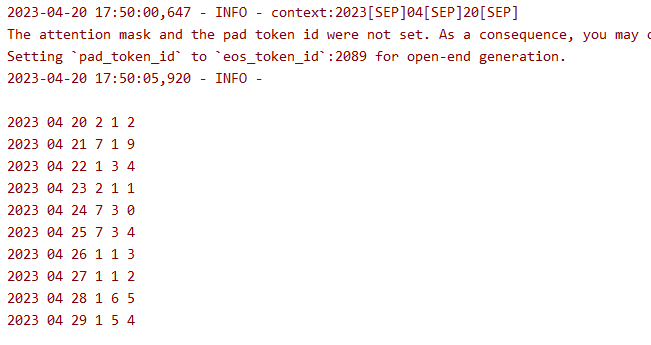
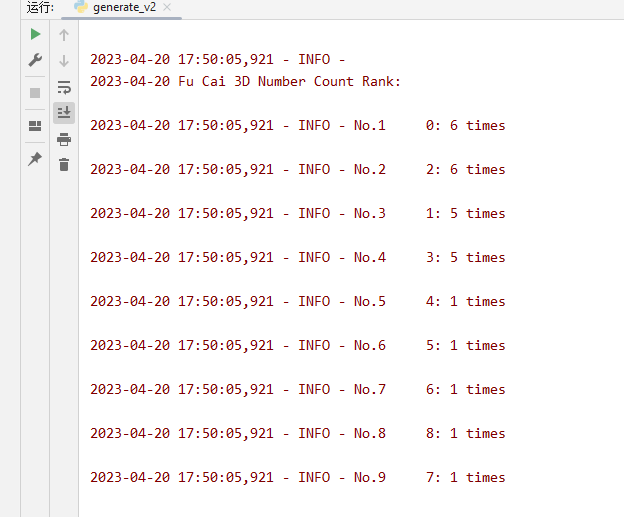
通过预测4.20号的10期统计分析 出现的数字
propare_data.py
import argparse # 导入 argparse 库,用于处理命令行参数
import os # 导入 os 模块,用于文件操作
from vocab import vocab
# 获取当前文件的绝对路径
current_path = os.path.abspath(__file__)
dataset_path = os.path.join('data', '福彩3d.TXT')
# 设置命令行参数
parser = argparse.ArgumentParser() # 创建 ArgumentParser 对象
parser.add_argument('--vocab_file', default='./vocab/chinese_vocab.model', type=str, required=False,
help='词表路径') # 添加词表路径参数
parser.add_argument('--log_path', default='./log/preprocess.log', type=str, required=False,
help='日志存放位置') # 添加日志存放路径参数
parser.add_argument('--data_path', default='./data/zuowen', type=str, required=False,
help='数据集存放位置') # 添加数据集存放路径参数
parser.add_argument('--save_path', default='./data/train.pkl', type=str, required=False,
help='对训练数据集进行tokenize之后的数据存放位置') # 添加序列化后的数据存放路径参数
parser.add_argument('--win_size', default=240, type=int, required=False,
help='滑动窗口的大小,相当于每条数据的最大长度') # 添加滑动窗口大小参数
parser.add_argument('--step', default=240, type=int, required=False, help='滑动窗口的滑动步幅') # 添加滑动步幅参数
args = parser.parse_args() # 解析命令行参数
vocab = vocab("vocab/vocab_v2.txt")
article=''
count=0
# 打开文件
with open(dataset_path, 'r', encoding="utf8") as f:
# 读取每一行数据
for line in f:
# 使用 split() 函数将每行数据分割成列表
data_list = line.split()
# 如果列表长度大于等于6,说明包含了年月日和日后面的三位数
if len(data_list) >= 6:
year, month, day = data_list[1][:4], data_list[1][5:7], data_list[1][8:]
num1 = data_list[2]
num2 = data_list[3]
num3= data_list[4]
print(year, month, day, num1,num2,num3)
s='[SEP]'
c='[CLS]'
#[年][SEP][月][SEP][日][SEP][开奖号码1][SEP][开奖号码2][SEP][开奖号码3][CLS]
d = year + s + month + s + day + s + num1 + s + num2 + s + num3 + c
d2 = vocab.cut(d)
print('d2= ',d2)
l1 = vocab.encode_tokens_strToint(d2)
print('l1= ',l1)
article+=d
str_list = [str(num) for num in l1]
str2 =' '.join(str_list)
print(str2)
with open(args.save_path, "a", encoding="utf8") as f:
f.write(str2 +' ')
else:
print("No match found") # 如果数据不完整,输出提示信息
count+=1
if count>=10:
with open(args.save_path, "a", encoding="utf8") as f:
f.write('\n')
article=''
count=0
# 读取测试 查看是否处理正确
train_list=[]
with open(args.save_path, "r", encoding="utf8") as f:
file_content = f.read()
line = file_content.split('\n')
for i in line:
i= i.strip()
digit_strings = i.split(' ')
digit_list = [int(d) for d in digit_strings]
print('i=',i,',value= ',vocab.decode_tokens_intTostr(digit_list))
train_list.append(digit_list)
train_v3.py
import argparse
import time
import torch
import torch.nn.functional as F
from datetime import datetime
import os
from torch.utils.data import DataLoader
from os.path import join
import transformers
from utils import set_logger, set_random_seed
from data_parallel import BalancedDataParallel
from transformers import GPT2LMHeadModel, GPT2Config, CpmTokenizer
import torch.nn.utils.rnn as rnn_utils
from dataset import CPMDataset
def set_args():
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行训练')
parser.add_argument('--vocab_path', default='vocab/chinese_vocab.model', type=str, required=False,
help='sp模型路径')
parser.add_argument('--model_config', default='config/cpm-small.json', type=str, required=False,
help='需要从头训练一个模型时,模型参数的配置文件')
parser.add_argument('--train_path', default='data/train.pkl', type=str, required=False, help='经过预处理之后的数据存放路径')
parser.add_argument('--max_len', default=240, type=int, required=False, help='训练时,输入数据的最大长度')
parser.add_argument('--log_path', default='log/train.log', type=str, required=False, help='训练日志存放位置')
parser.add_argument('--ignore_index', default=-100, type=int, required=False, help='对于ignore_index的label token不计算梯度')
parser.add_argument('--epochs', default=100, type=int, required=False, help='训练的最大轮次')
parser.add_argument('--batch_size', default=20, type=int, required=False, help='训练的batch size')
parser.add_argument('--gpu0_bsz', default=6, type=int, required=False, help='0号卡的batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')
parser.add_argument('--eps', default=1.0e-09, type=float, required=False, help='AdamW优化器的衰减率')
parser.add_argument('--log_step', default=1, type=int, required=False, help='多少步汇报一次loss')
parser.add_argument('--gradient_accumulation_steps', default=6, type=int, required=False, help='梯度积累的步数')
parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)
parser.add_argument('--save_model_path', default='model', type=str, required=False,help='模型输出路径')
parser.add_argument('--pretrained_model', default='model/epoch100', type=str, required=False, help='预训练的模型的路径')
parser.add_argument('--seed', type=int, default=1234, help='设置随机种子')
parser.add_argument('--num_workers', type=int, default=0, help="dataloader加载数据时使用的线程数量")
# parser.add_argument('--patience', type=int, default=0, help="用于early stopping,设为0时,不进行early stopping.early stop得到的模型的生成效果不一定会更好。")
parser.add_argument('--warmup_steps', type=int, default=4000, help='warm up步数')
# parser.add_argument('--label_smoothing', default=True, action='store_true', help='是否进行标签平滑')
args = parser.parse_args()
return args
def collate_fn(batch):
input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=5)
labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100)
return input_ids, labels
def print_list_data(my_list):
'''
print_list_data函数接受一个列表作为参数 my_list,然后执行上面讲到的操作,获取前10个、中间10个和后10个元素,
最后使用 print 函数输出结果。
'''
# 获取前10条数据
first_10 = my_list[:10] if len(my_list) >= 10 else my_list
# 获取后10条数据
last_10 = my_list[-10:] if len(my_list) >= 10 else my_list
# 获取中间10条数据
middle_start_index = len(my_list)//2 - 5 if len(my_list) >= 10 else 0
middle_end_index = len(my_list)//2 + 5 if len(my_list) >= 10 else len(my_list)
middle_10 = my_list[middle_start_index:middle_end_index]
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") # 创建 CpmTokenizer 对象,指定词表路径
# 输出前10条数据
print("前10条数据:")
for line in first_10:
int_list = [int(x) for x in line]
str_list = tokenizer.decode(int_list)
print(str_list)
# 输出中间10条数据
print("中间10条数据:")
for line in middle_10:
int_list = [int(x) for x in line]
str_list = tokenizer.decode(int_list)
print(str_list)
# 输出后10条数据
print("后10条数据:")
for line in last_10:
int_list = [int(x) for x in line]
str_list =tokenizer.decode(int_list)
print(str_list)
def load_dataset(logger, args):
"""
加载训练集
"""
logger.info("loading training dataset")
train_path = args.train_path
train_list=[]
with open(train_path, "r", encoding="utf8") as f:
file_content = f.read()
line = file_content.split('\n')
for i in line:
i = i.strip()
digit_strings = i.split(' ')
digit_list = [int(d) for d in digit_strings]
train_list.append(digit_list)
# test
#train_list = train_list[:-24]
train_dataset = CPMDataset(train_list, args.max_len)
return train_dataset
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,
epoch, args):
model.train()
device = args.device
ignore_index = args.ignore_index
epoch_start_time = datetime.now()
total_loss = 0 # 记录下整个epoch的loss的总和
epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量
epoch_total_num = 0 # 每个epoch中,预测的word的总数量
train_count_yhy =0
elapsed_minutes = 30 #训练时长 (单位分钟), 每过 20 分钟后 就会休息 3.5分钟.
rest_minutes =5 #休息时长 (单位分钟)
start_time = datetime.now()
for batch_idx, (input_ids, labels) in enumerate(train_dataloader):
train_count_yhy+=1
if(train_count_yhy>=1000):
train_count_yhy=0
# model_to_save = model.module if hasattr(model, 'module') else model
# model_to_save.save_pretrained(args.save_model_path)
# logger.info('model_to_save')
# 检测是否已经过去了指定分钟数 每过 20 分钟后 就会休息 3.5分钟.
elapsed_time = datetime.now() - start_time
if elapsed_time.total_seconds() >= elapsed_minutes * 60:
start_time = datetime.now()
logger.info('为防止GPU过热损坏 ,每过 20 分钟后 就会休息 3.5分钟.休息中...')
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(args.save_model_path)
logger.info('model_to_save')
time.sleep(rest_minutes * 60)
# 捕获cuda out of memory exception
try:
input_ids = input_ids.to(device)
labels = labels.to(device)
outputs = model.forward(input_ids, labels=labels)
logits = outputs.logits
loss = outputs.loss
loss = loss.mean()
# 统计该batch的预测token的正确数与总数
batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)
# 统计该epoch的预测token的正确数与总数
epoch_correct_num += batch_correct_num
epoch_total_num += batch_total_num
# 计算该batch的accuracy
batch_acc = batch_correct_num / batch_total_num
total_loss += loss.item()
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
# 进行一定step的梯度累计之后,更新参数
if (batch_idx + 1) % args.gradient_accumulation_steps == 0:
# 更新参数
optimizer.step()
# 更新学习率
scheduler.step()
# 清空梯度信息
optimizer.zero_grad()
if (batch_idx + 1) % args.log_step == 0:
logger.info(
"batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(
batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))
del input_ids, outputs
except RuntimeError as exception:
if "out of memory" in str(exception):
logger.info("WARNING: ran out of memory")
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
else:
logger.info(str(exception))
raise exception
# 记录当前epoch的平均loss与accuracy
epoch_mean_loss = total_loss / len(train_dataloader)
epoch_mean_acc = epoch_correct_num / epoch_total_num
logger.info(
"epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))
# save model
logger.info('saving model for epoch {}'.format(epoch + 1))
model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))
if not os.path.exists(model_path):
os.mkdir(model_path)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(model_path)
logger.info('epoch {} finished'.format(epoch + 1))
epoch_finish_time = datetime.now()
logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))
return epoch_mean_loss
def train(model, logger, train_dataset, args):
# 构建训练数据的DataLoader
train_dataloader = DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn,
drop_last=True
)
# 计算总的训练步数
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs
# 构建AdamW优化器
optimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps)
# 构建学习率调度器
scheduler = transformers.get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
logger.info('开始训练')
train_losses = [] # 记录每个epoch的平均loss
# ========== 开始训练 ========== #
for epoch in range(args.epochs):
# 训练一个epoch
train_loss = train_epoch(
model=model, train_dataloader=train_dataloader,
optimizer=optimizer, scheduler=scheduler,
logger=logger, epoch=epoch, args=args)
# 记录当前epoch的平均loss
train_losses.append(round(train_loss, 4))
logger.info("训练损失列表:{}".format(train_losses))
logger.info('训练完成')
logger.info("训练损失列表:{}".format(train_losses))
def caculate_loss(logit, target, pad_idx, smoothing=True):
if smoothing:
logit = logit[..., :-1, :].contiguous().view(-1, logit.size(2))
target = target[..., 1:].contiguous().view(-1)
eps = 0.1
n_class = logit.size(-1)
one_hot = torch.zeros_like(logit).scatter(1, target.view(-1, 1), 1)
one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)
log_prb = F.log_softmax(logit, dim=1)
non_pad_mask = target.ne(pad_idx)
loss = -(one_hot * log_prb).sum(dim=1)
loss = loss.masked_select(non_pad_mask).mean() # average later
else:
# loss = F.cross_entropy(predict_logit, target, ignore_index=pad_idx)
logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))
labels = target[..., 1:].contiguous().view(-1)
loss = F.cross_entropy(logit, labels, ignore_index=pad_idx)
return loss
def calculate_acc(logit, labels, ignore_index=-100):
logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))
labels = labels[..., 1:].contiguous().view(-1)
_, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index
# 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1
non_pad_mask = labels.ne(ignore_index)
n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item()
n_word = non_pad_mask.sum().item()
return n_correct, n_word
def main():
# 初始化参数
args = set_args()
# 设置使用哪些显卡进行训练
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
args.cuda = not args.no_cuda
# if args.batch_size < 2048 and args.warmup_steps <= 4000:
# print('[Warning] The warmup steps may be not enough.\n' \
# '(sz_b, warmup) = (2048, 4000) is the official setting.\n' \
# 'Using smaller batch w/o longer warmup may cause ' \
# 'the warmup stage ends with only little data trained.')
# 创建日志对象
logger = set_logger(args.log_path)
# 当用户使用GPU,并且GPU可用时
args.cuda = torch.cuda.is_available() and not args.no_cuda
device = 'cuda:0' if args.cuda else 'cpu'
args.device = device
logger.info('using device:{}'.format(device))
# 设置随机种子
set_random_seed(args.seed, args.cuda)
# 初始化tokenizer
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")
args.eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
args.pad_id = tokenizer.pad_token_id
# 创建模型的输出目录
if not os.path.exists(args.save_model_path):
os.mkdir(args.save_model_path)
# 创建模型
if False: # 加载预训练模型
model = GPT2LMHeadModel.from_pretrained(args.pretrained_model)
else: # 初始化模型
model_config = GPT2Config.from_json_file(args.model_config)
model = GPT2LMHeadModel(config=model_config)
model = model.to(device)
logger.info('model config:\n{}'.format(model.config.to_json_string()))
# assert model.config.vocab_size == tokenizer.vocab_size
# 多卡并行训练模型
if args.cuda and torch.cuda.device_count() > 1:
# model = DataParallel(model).cuda()
model = BalancedDataParallel(args.gpu0_bsz, model, dim=0).cuda()
logger.info("use GPU {} to train".format(args.device))
# 计算模型参数数量
num_parameters = 0
parameters = model.parameters()
for parameter in parameters:
num_parameters += parameter.numel()
logger.info('number of model parameters: {}'.format(num_parameters))
# 记录参数设置
logger.info("args:{}".format(args))
# 加载训练集和验证集
# ========= Loading Dataset ========= #
train_dataset = load_dataset(logger, args)
train(model, logger, train_dataset, args)
if __name__ == '__main__':
main()
generate_v2.py
from collections import Counter
import torch
import torch.nn.functional as F
import os
import argparse
from transformers import GPT2LMHeadModel
from transformers.models.cpm.tokenization_cpm import CpmTokenizer
from utils import top_k_top_p_filtering, set_logger
# 使用单个字分词
from tokenizations import tokenization_bert
from vocab import vocab
from datetime import datetime, timedelta
def generate_next_token(input_ids):
"""
对于给定的上文,生成下一个单词
"""
outputs = model(input_ids=input_ids)
logits = outputs.logits
# next_token_logits表示最后一个token的hidden_state对应的prediction_scores,也就是模型要预测的下一个token的概率
next_token_logits = logits[0, -1, :]
next_token_logits = next_token_logits / args.temperature
# 对于<unk>的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token
next_token_logits[unk_id] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.topk, top_p=args.topp)
# torch.multinomial表示从候选集合中选出无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标
next_token_id = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)
return next_token_id
def count_numbers_result(result, target_date,logger):
date_format = "%Y-%m-%d"
date_obj = datetime.strptime(target_date, date_format)
# with open(r'C:\Users\Administrator\PycharmProjects\pythonProject1\log\generate.log', "r", encoding="utf8") as f:
# file_content = f.read()
lines = result.split('\n')
new_lines = []
for item in lines:
l = len(item.split(' '))
try:
if l == 6:
t = item.split(' ')
y = int(item.split(' ')[0])
m = int(item.split(' ')[1])
d = int(item.split(' ')[2])
n1 = int(item.split(' ')[3])
n2 = int(item.split(' ')[4])
n3 = int(item.split(' ')[5])
curr_date = datetime(y, m, d)
if curr_date == date_obj:
new_lines.append((curr_date, n1, n2, n3))
except:
continue
# 定义用于存储所有数字的列表
all_numbers = []
# 遍历 new_lines 列表,将 n1、n2 和 n3 中的数字添加到 all_numbers 列表中
for item in new_lines:
all_numbers.extend(item[1:4])
# 使用 Counter 统计数字出现的次数
number_counts = Counter(all_numbers)
# 对数字出现次数进行排序,得到排名
number_ranking = number_counts.most_common()
# 打印数字出现次数排名
logger.info('\n'+target_date+' Fu Cai 3D Number Count Rank:\n')
for i, (number, count) in enumerate(number_ranking):
logger.info(f"No.{i + 1} {number}: {count} times\n")
def get_last_10_days(date_str):
date_format = "%Y-%m-%d"
date_obj = datetime.strptime(date_str, date_format)
result = []
for i in range(9, -1, -1): # 从10到1遍历日期
delta = timedelta(days=i)
new_date = (date_obj - delta).strftime("%Y[SEP]%m[SEP]%d[SEP]")
result.append(new_date)
return result
def genera(target_date = '2023-04-19'):
# 参数设置
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0', type=str, required=False, help='生成设备')
parser.add_argument('--temperature', default=1, type=float, required=False, help='生成温度')
parser.add_argument('--topk', default=0, type=int, required=False, help='最高几选一')
parser.add_argument('--topp', default=0.85, type=float, required=False, help='最高积累概率')
parser.add_argument('--repetition_penalty', default=1.0, type=float, required=False, help='重复惩罚参数')
parser.add_argument('--context_len', default=800, type=int, required=False, help='每一步生成时,参考的上文的长度')
parser.add_argument('--max_len', default=3500, type=int, required=False, help='生成的最长长度')
parser.add_argument('--log_path', default='log/generate.log', type=str, required=False, help='日志存放位置')
parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行预测')
parser.add_argument('--model_path', type=str, default='model/epoch100', help='模型存放位置')
parser.add_argument('--context', type=str, default='2023[SEP]04[SEP]15[SEP]', help='日期')
args = parser.parse_args()
os.environ["CUDA_VISIBLE_DEVICES"] = args.device # 此处设置程序使用哪些显卡
args.cuda = torch.cuda.is_available() and not args.no_cuda # 当用户使用GPU,并且GPU可用时
device = 'cuda:0' if args.cuda else 'cpu'
# device = 'cpu'
print(device)
# 创建日志对象
logger = set_logger(args.log_path)
# 初始化tokenizer
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")
eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
sep_id = tokenizer.sep_token_id
unk_id = tokenizer.unk_token_id
# 加载模型
model = GPT2LMHeadModel.from_pretrained(args.model_path)
model.eval()
model = model.to(device)
result1 = ''
dataList = get_last_10_days(target_date)
for i in dataList:
logger.info("context:{}".format(i))
vocab1 = vocab(r'C:\Users\Administrator\PycharmProjects\pythonProject1\vocab\vocab_v2.txt')
tokenizer = tokenization_bert.BertTokenizer(r'C:\Users\Administrator\PycharmProjects\pythonProject1\vocab\vocab_v2.txt')
l1 = vocab1.cut(i)
context_ids = vocab1.encode_tokens_strToint(l1)
#print(l1,'\n',context_ids)
input_ids = [context_ids]
cur_len = len(input_ids)
# 将列表对象转换为张量对象
input_tensor = torch.tensor(input_ids, device=device)
#print(input_tensor)
# 使用转换后的张量对象作为输入生成模型的输出
output = model.generate(input_tensor,
max_length=240, # 生成的最大长度
min_length=234,
temperature=0,
use_cache=False, # 是否使用缓存
)
output_list = output.tolist()[0]
a = vocab1.decode_tokens_intTostr( output_list)
count =0
result=''
result +='\n'
for item in a:
if item == '[SEP]':
result += ' '
elif item == '[CLS]':
result += '\n'
else:
count+=1
if count>=61:
break
else:
result += item
logger.info('\n' + result)
result1+=result
count_numbers_result(result1, target_date,logger)
if __name__ == '__main__':
genera(target_date='2023-04-20')
vocab.py
'''
from vocab import vocab
# 创建一个词汇表对象
vocab1 = vocab('vocab.txt')
# 对输入文本进行分词
text = '我爱自然语言处理'
tokens = vocab1.cut(text)
print(tokens) # ['我', '爱', '[UNK]', '[UNK]']
# 将单词列表编码成单词索引列表
token_ids = vocab1.encode_tokens_strToint(tokens)
print(token_ids) # [143, 54, 0, 0]
# 将单词索引列表解码成单词列表
decoded_tokens = vocab1.decode_tokens_intTostr(token_ids)
print(decoded_tokens) # ['我', '爱', '[UNK]', '[UNK]']
'''
class vocab:
def __init__(self, vocab_file):
"""
从给定的词汇表文件中构建一个词汇表对象,并将每个单词与其对应的索引建立映射关系。
Args:
vocab_file (str): 词汇表文件路径。
"""
self.token2id = {} # 词汇表中每个单词与其索引之间的映射(字典)
self.id2token = {} # 词汇表中每个索引与其对应的单词之间的映射(字典)
# 读取词汇表文件,将每个单词映射到其索引
with open(vocab_file, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
token = line.strip() # 移除行尾的换行符并得到单词
self.token2id[token] = i # 将单词映射到其索引
self.id2token[i] = token # 将索引映射到其对应的单词
self.num_tokens = len(self.token2id) # 词汇表中单词的数量
self.unknown_token = '[UNK]' # 特殊的未知标记
self.pad_token = '[PAD]' # 用于填充序列的特殊标记(在这里仅用于编码)
self.pad_token_id = self.token2id.get(self.pad_token, -1) # 填充标记的索引
def cut(self, input_str):
"""
中文语句分词的算法 用python代码 cut函数 参数 词汇表文件 和 语句str
词汇表文件 每行一个词语,
1.词汇表字典的键为词汇,值为该词汇在词汇表中的行号-1,也即该词汇在词汇表中的索引位置。
3.输入的中文语句,从左到右依次遍历每一个字符,以当前字符为起点尝试匹配一个词汇。具体匹配方式如下:
a. 从当前字符开始,依次向后匹配,直到找到一个最长的词汇。如果该词汇存在于词典中,就将其作为一个分词结果,并将指针移动到该词汇的后面一个字符。如果该词汇不存在于词典中,则将当前字符作为一个单独的未知标记,同样将其作为一个分词结果,并将指针移动到下一个字符。
b. 如果从当前字符开始,没有找到任何词汇,则将当前字符作为一个单独的未知标记,同样将其作为一个分词结果,并将指针移动到下一个字符。
重复上述过程,直到遍历完整个输入的中文语句,得到所有的分词结果列表。
"""
result = []
i = 0
while i < len(input_str):
longest_word = input_str[i]
for j in range(i + 1, len(input_str) + 1):
if input_str[i:j] in self.token2id:
longest_word = input_str[i:j]
result.append(longest_word)
i += len(longest_word)
return result
def encode_tokens_strToint(self, tokens):
"""
将给定的单词列表编码成对应的单词索引列表。
如果一个单词在词汇表中没有出现,则将其替换为特殊的未知标记。
Args:
tokens (list): 待编码的单词列表。
Returns:
token_ids (list): 编码后的单词索引列表。
"""
return [self.token2id.get(token, self.token2id[self.unknown_token]) for token in tokens]
def decode_tokens_intTostr(self, token_ids):
"""
将给定的单词索引列表解码成对应的单词列表。
如果一个索引在词汇表中没有对应的单词,则将其替换为特殊的未知标记。
Args:
token_ids (list): 待解码的单词索引列表。
Returns:
tokens (list): 解码后的单词列表。
"""
return [self.id2token.get(token_id, self.unknown_token) for token_id in token_ids]
其他代码引用代码
https://github.com/yangjianxin1/CPM