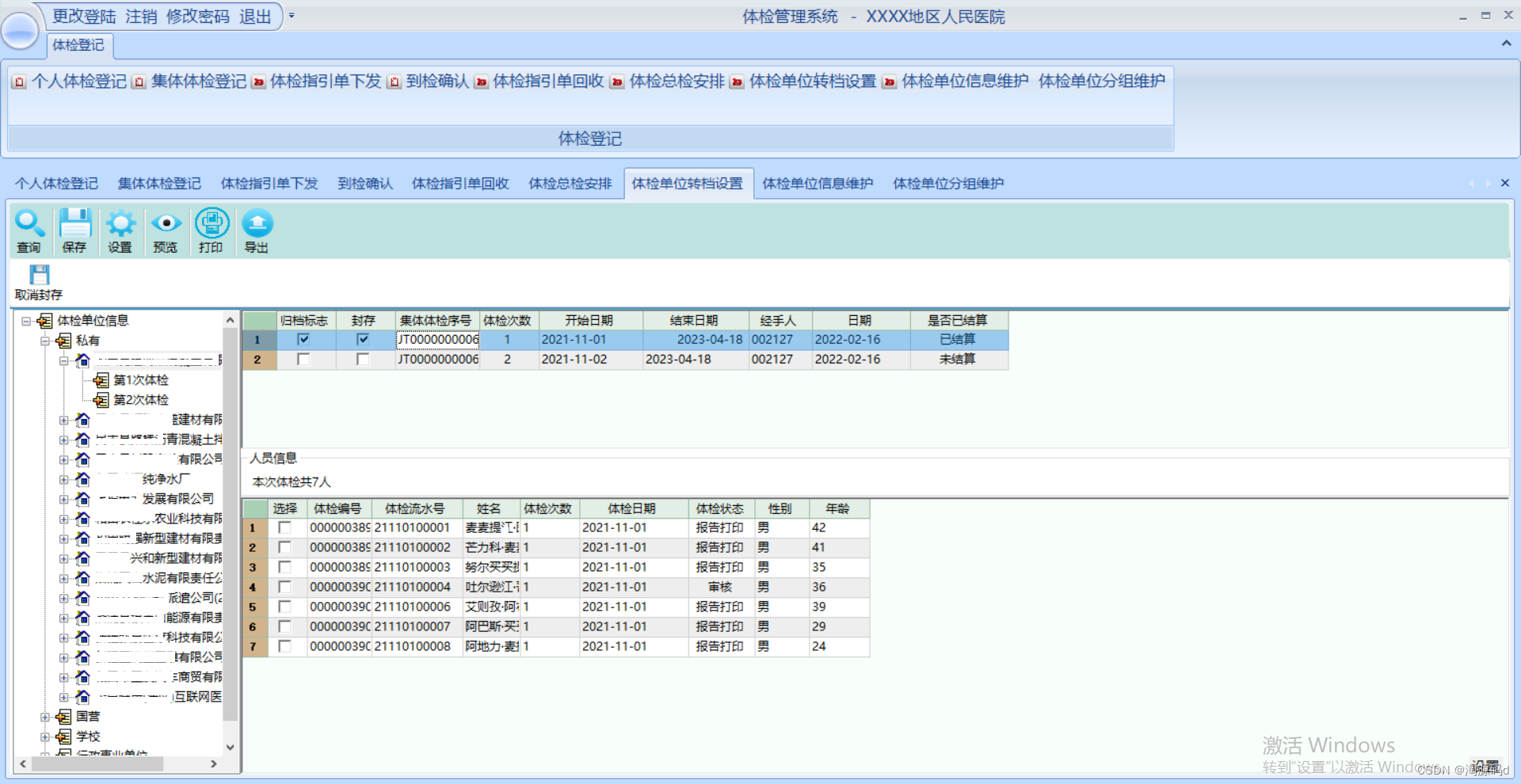
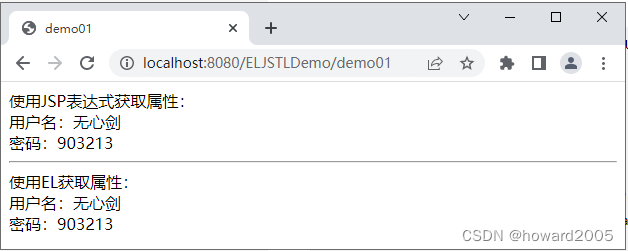
文章目录
- 引言
- JVM 内存模型简介
- 非 Heap 内存
- Heap 堆内存
- Kubernetes 内存管理
- JVM 和 Kubernetes
- 场景 1 — Java Out Of Memory 错误
- 场景 2 — Pod 超出内存 limit 限制
- 场景 3 — Pod 超出节点的可用内存
- 场景 4 — 参数配置良好,应用程序运行良好
- 结语
引言
如何结合使用 JVM Heap 堆和 Kubernetes 内存的 requests 和 limits 并远离麻烦。
在容器环境中运行 Java 应用程序需要了解两者 —— JVM 内存机制和 Kubernetes 内存管理。这两个环境一起工作会产生一个稳定的应用程序,但是,错误配置最多可能导致基础设施超支,最坏情况下可能会导致应用程序不稳定或崩溃。我们将首先仔细研究 JVM 内存的工作原理,然后我们将转向 Kubernetes,最后,我们将把这两个概念放在一起。
JVM 内存模型简介
JVM 内存管理是一种高度复杂的机制,多年来通过连续发布不断改进,是 JVM 平台的优势之一。对于本文,我们将只介绍对本主题有用的基础知识。在较高的层次上,JVM 内存由两个空间组成 —— Heap 和 Metaspace。
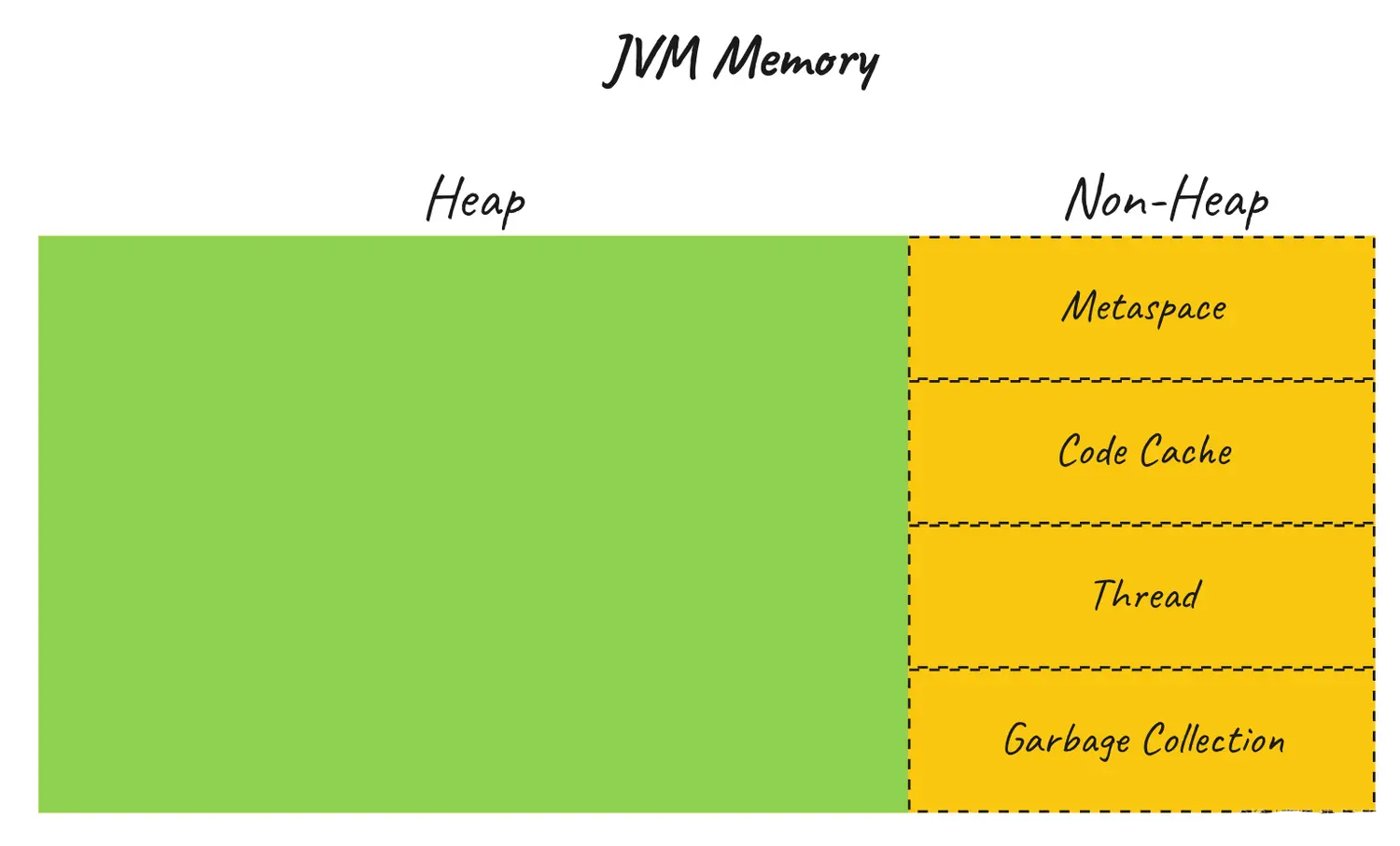
非 Heap 内存
JVM 使用许多内存区域。最值得注意的是 Metaspace。Metaspace 有几个功能。它主要用作方法区,其中存储应用程序的类结构和方法定义,包括标准库。内存池和常量池用于不可变对象,例如字符串,以及类常量。堆栈区域是用于线程执行的后进先出结构,存储原语和对传递给函数的对象的引用。根据 JVM 实现和版本,此空间用途的一些细节可能会有所不同。
我喜欢将 Metaspace 空间视为一个管理区域。这个空间的大小可以从几 MB 到几百 MB 不等,具体取决于代码库及其依赖项的大小,并且在应用程序的整个生命周期中几乎保持不变。默认情况下,此空间未绑定并会根据应用程序需要进行扩展。
Metaspace 是在 Java 8 中引入的,取代了 Permanent Generation,后者存在垃圾回收问题。
其他一些值得一提的非堆内存区域是代码缓存、线程、垃圾回收。
Heap 堆内存
如果 Metaspace 是管理空间,那么 Heap 就是操作空间。这里存放着所有的实例对象,并且垃圾回收机制在这里最为活跃。该内存的大小因应用程序而异,取决于工作负载的大小 —— 应用程序需要满足单个请求和流量特征所需的内存。大型应用程序通常具有以GB为单位的堆大小。
我们将使用一个示例应用程序用于探索内存机制。
这个演示应用程序模拟了一个真实世界的场景,在该场景中,为传入请求提供服务的系统会在堆上累积对象,并在请求完成后成为垃圾回收的候选对象。该程序的核心是一个无限循环,通过将大型对象添加到列表并定期清除列表来创建堆上的大型对象。
val list = mutableListOf<ByteArray>()
generateSequence(0) { it + 1 }.forEach {
if (it % (HEAP_TO_FILL / INCREMENTS_IN_MB) == 0) list.clear()
list.add(ByteArray(INCREMENTS_IN_MB * BYTES_TO_MB))
}
以下是应用程序的输出。在预设间隔(本例中为350MB堆大小)内,状态会被清除。重要的是要理解,清除状态并不会清空堆 - 这是垃圾收集器内部实现的决定何时将对象从内存中驱逐出去。让我们使用几个堆设置来运行此应用程序,以查看它们对JVM行为的影响。
首先,我们将使用 4 GB 的最大堆大小(由 -Xmx 标志控制)。
~ java -jar -Xmx4G app/build/libs/app.jar
INFO Used Free Total
INFO 14.00 MB 36.00 MB 50.00 MB
INFO 66.00 MB 16.00 MB 82.00 MB
INFO 118.00 MB 436.00 MB 554.00 MB
INFO 171.00 MB 383.00 MB 554.00 MB
INFO 223.00 MB 331.00 MB 554.00 MB
INFO 274.00 MB 280.00 MB 554.00 MB
INFO 326.00 MB 228.00 MB 554.00 MB
INFO State cleared at ~ 350 MB.
INFO Used Free Total
INFO 378.00 MB 176.00 MB 554.00 MB
INFO 430.00 MB 208.00 MB 638.00 MB
INFO 482.00 MB 156.00 MB 638.00 MB
INFO 534.00 MB 104.00 MB 638.00 MB
INFO 586.00 MB 52.00 MB 638.00 MB
INFO 638.00 MB 16.00 MB 654.00 MB
INFO 690.00 MB 16.00 MB 706.00 MB
INFO State cleared at ~ 350 MB.
INFO Used Free Total
INFO 742.00 MB 16.00 MB 758.00 MB
INFO 794.00 MB 16.00 MB 810.00 MB
INFO 846.00 MB 16.00 MB 862.00 MB
INFO 899.00 MB 15.00 MB 914.00 MB
INFO 951.00 MB 15.00 MB 966.00 MB
INFO 1003.00 MB 15.00 MB 1018.00 MB
INFO 1055.00 MB 15.00 MB 1070.00 MB
...
...
有趣的是,尽管状态已被清除并准备好进行垃圾回收,但可以看到使用的内存(第一列)仍在增长。为什么会这样呢?由于堆有足够的空间可以扩展,JVM 延迟了通常需要大量 CPU 资源的垃圾回收,并优化为服务主线程。让我们看看不同堆大小如何影响此行为。
~ java -jar -Xmx380M app/build/libs/app.jar
INFO Used Free Total
INFO 19.00 MB 357.00 MB 376.00 MB
INFO 70.00 MB 306.00 MB 376.00 MB
INFO 121.00 MB 255.00 MB 376.00 MB
INFO 172.00 MB 204.00 MB 376.00 MB
INFO 208.00 MB 168.00 MB 376.00 MB
INFO 259.00 MB 117.00 MB 376.00 MB
INFO 310.00 MB 66.00 MB 376.00 MB
INFO State cleared at ~ 350 MB.
INFO Used Free Total
INFO 55.00 MB 321.00 MB 376.00 MB
INFO 106.00 MB 270.00 MB 376.00 MB
INFO 157.00 MB 219.00 MB 376.00 MB
INFO 208.00 MB 168.00 MB 376.00 MB
INFO 259.00 MB 117.00 MB 376.00 MB
INFO 310.00 MB 66.00 MB 376.00 MB
INFO 361.00 MB 15.00 MB 376.00 MB
INFO State cleared at ~ 350 MB.
INFO Used Free Total
INFO 55.00 MB 321.00 MB 376.00 MB
INFO 106.00 MB 270.00 MB 376.00 MB
INFO 157.00 MB 219.00 MB 376.00 MB
INFO 208.00 MB 168.00 MB 376.00 MB
INFO 259.00 MB 117.00 MB 376.00 MB
INFO 310.00 MB 66.00 MB 376.00 MB
INFO 361.00 MB 15.00 MB 376.00 MB
INFO State cleared at ~ 350 MB.
INFO Used Free Total
INFO 55.00 MB 321.00 MB 376.00 MB
INFO 106.00 MB 270.00 MB 376.00 MB
INFO 157.00 MB 219.00 MB 376.00 MB
INFO 208.00 MB 168.00 MB 376.00 MB
...
...
在这种情况下,我们分配了刚好足够的堆大小(380 MB)来处理请求。我们可以看到,在这些限制条件下,GC立即启动以避免可怕的内存不足错误。这是 JVM 的承诺 - 它将始终在由于内存不足而失败之前尝试进行垃圾回收。为了完整起见,让我们看一下它的实际效果:
~ java -jar -Xmx150M app/build/libs/app.jar
INFO Used Free Total
INFO 19.00 MB 133.00 MB 152.00 MB
INFO 70.00 MB 82.00 MB 152.00 MB
INFO 106.00 MB 46.00 MB 152.00 MB
Exception in thread "main"
...
...
Caused by: java.lang.OutOfMemoryError: Java heap space
at com.dansiwiec.HeapDestroyerKt.blowHeap(HeapDestroyer.kt:28)
at com.dansiwiec.HeapDestroyerKt.main(HeapDestroyer.kt:18)
... 8 more
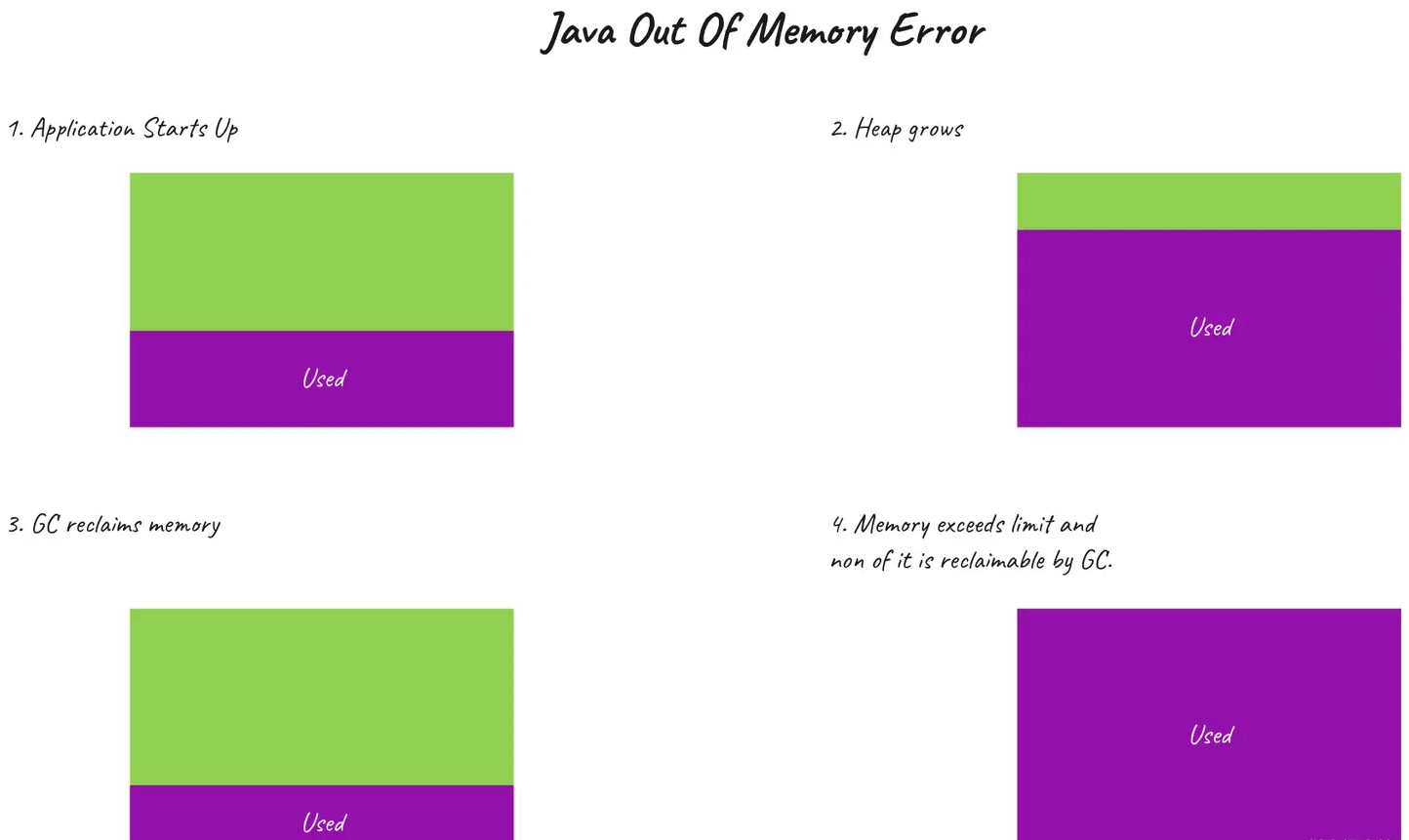
对于 150 MB 的最大堆大小,进程无法处理 350MB 的工作负载,并且在堆被填满时失败,但在垃圾收集器尝试挽救这种情况之前不会失败。
我们也来看看 Metaspace 的大小。为此,我们将使用 jstat(为简洁起见省略了输出)
~ jstat -gc 35118
MU
4731.0
输出表明 Metaspace 利用率约为 5 MB。记住 Metaspace 负责存储类定义,作为实验,让我们将流行的 Spring Boot 框架添加到我们的应用程序中。
~ jstat -gc 34643
MU
28198.6
Metaspace 跃升至近 30 MB,因为类加载器占用的空间要大得多。对于较大的应用程序,此空间占用超过 100 MB 的情况并不罕见。接下来让我们进入 Kubernetes 领域。
Kubernetes 内存管理
Kubernetes 内存控制在操作系统级别运行,与管理分配给它的内存的 JVM 形成对比。K8s 内存管理机制的目标是确保工作负载被调度到资源充足的节点上,并将它们保持在一定的限制范围内。
在定义工作负载时,用户有两个参数可以操作 — requests 和 limits。这些是在容器级别定义的,但是,为了简单起见,我们将根据 pod 参数来考虑它,这些参数只是容器设置的总和。
当请求 pod 时,kube-scheduler(控制平面的一个组件)查看资源请求并选择一个具有足够资源的节点来容纳 pod。一旦调度,允许 pod 超过其内存requests(只要节点有空闲内存)但禁止超过其limits。
Kubelet(节点上的容器运行时)监视 pod 的内存利用率,如果超过内存限制,它将重新启动 pod 或在节点资源不足时将其完全从节点中逐出(有关更多详细信息,请参阅有关此主题的官方文档。这会导致臭名昭著的 OOMKilled(内存不足)的 pod 状态。
当 pod 保持在其限制范围内,但超出了节点的可用内存时,会出现一个有趣的场景。这是可能的,因为调度程序会查看 pod 的请求(而不是限制)以将其调度到节点上。在这种情况下,kubelet 会执行一个称为节点压力驱逐的过程。简而言之,这意味着 pod 正在终止,以便回收节点上的资源。根据节点上的资源状况有多糟糕,驱逐可能是软的(允许 pod 优雅地终止)或硬的。此场景如下图所示。
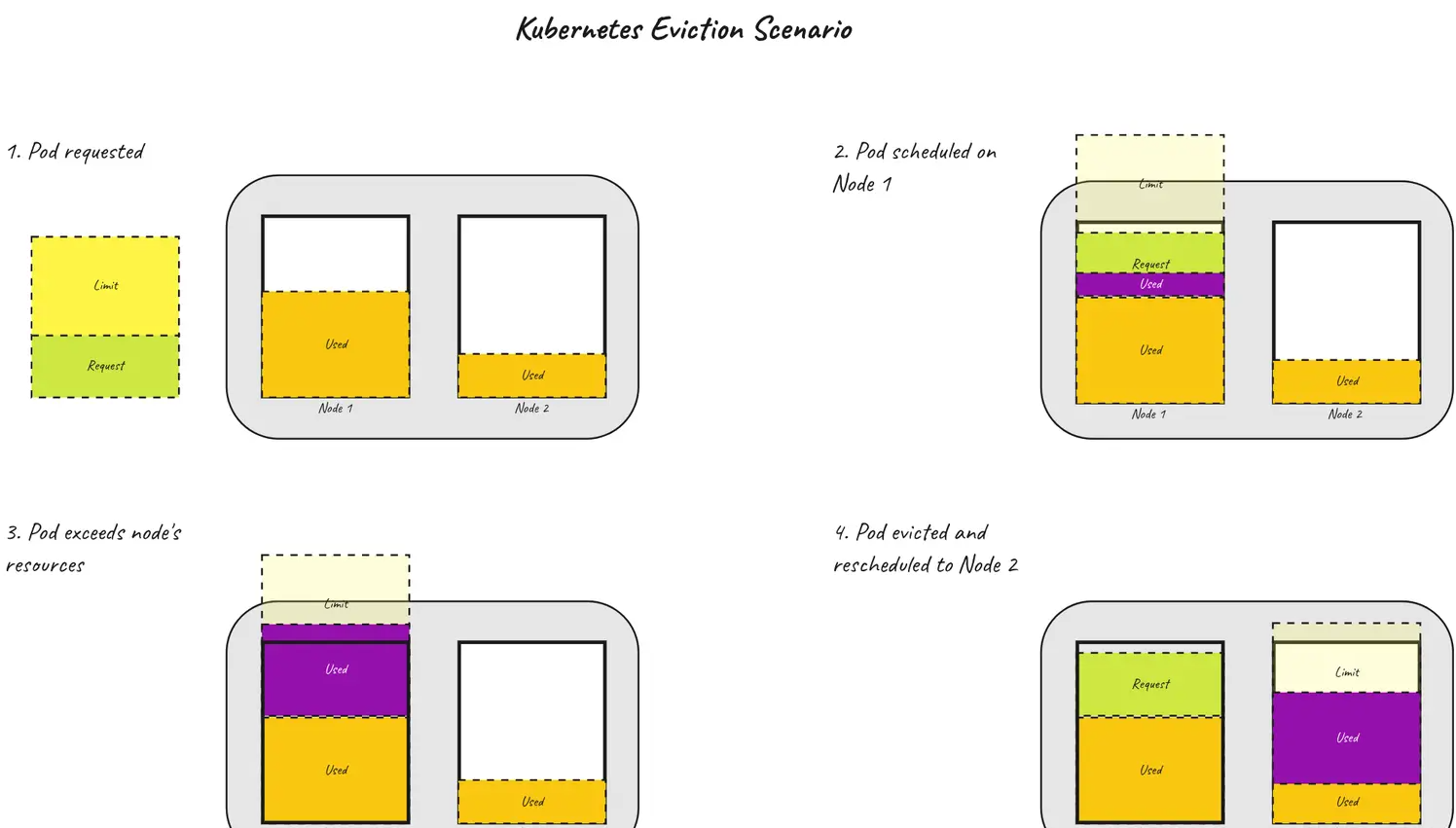
关于驱逐的内部运作,肯定还有很多东西需要了解。有关此复杂过程的更多信息,请点击此处。对于这个故事,我们就此打住,现在看看这两种机制 —— JVM 内存管理和 Kubernetes 是如何协同工作的。
JVM 和 Kubernetes
Java 10 引入了一个新的 JVM 标志 —— -XX:+UseContainerSupport(默认设置为 true),如果 JVM 在资源有限的容器环境中运行,它允许 JVM 检测可用内存和 CPU。该标志与 -XX:MaxRAMPercentage 一起使用,让我们根据总可用内存的百分比设置最大堆大小。在 Kubernetes 的情况下,容器上的 limits 设置被用作此计算的基础。例如 —— 如果 pod 具有 2GB 的限制,并且将 MaxRAMPercentage 标志设置为 75%,则结果将是 1500MB 的最大堆大小。
这需要一些技巧,因为正如我们之前看到的,Java 应用程序的总体内存占用量高于堆(还有 Metaspace 、线程、垃圾回收、APM 代理等)。这意味着,需要在最大堆空间、非堆内存使用量和 pod 限制之间取得平衡。具体来说,前两个的总和不能超过最后一个,因为它会导致 OOMKilled(参见上一节)。
为了观察这两种机制的作用,我们将使用相同的示例项目,但这次我们将把它部署在(本地)Kubernetes 集群上。为了在 Kubernetes 上部署应用程序,我们将其打包为一个 Pod:
apiVersion: v1
kind: Pod
metadata:
name: heapkiller
spec:
containers:
- name: heapkiller
image: heapkiller
imagePullPolicy: Never
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "500Mi"
cpu: "500m"
env:
- name: JAVA_TOOL_OPTIONS
value: '-XX:MaxRAMPercentage=70.0'
快速复习第一部分 —— 我们确定应用程序需要至少 380MB的堆内存才能正常运行。
场景 1 — Java Out Of Memory 错误
让我们首先了解我们可以操作的参数。它们是 — pod 内存的 requests 和 limits,以及 Java 的最大堆大小,在我们的例子中由 MaxRAMPercentage 标志控制。
在第一种情况下,我们将总内存的 70% 分配给堆。pod 请求和限制都设置为 500MB,这导致最大堆为 350MB(500MB 的 70%)。
我们执行 kubectl apply -f pod.yaml 部署 pod ,然后用 kubectl get logs -f pod/heapkiller 观察日志。应用程序启动后不久,我们会看到以下输出:
INFO Started HeapDestroyerKt in 5.599 seconds (JVM running for 6.912)
INFO Used Free Total
INFO 17.00 MB 5.00 MB 22.00 MB
...
INFO 260.00 MB 78.00 MB 338.00 MB
...
Exception in thread "main" java.lang.reflect.InvocationTargetException
Caused by: java.lang.OutOfMemoryError: Java heap space
如果我们执行 kubectl describe pod/heapkiller 拉出 pod 详细信息,我们将找到以下信息:
Containers:
heapkiller:
....
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Warning BackOff 7s (x7 over 89s) kubelet Back-off restarting failed container
复制代码
简而言之,这意味着 pod 以状态码 1 退出(Java Out Of Memory 的退出码),Kubernetes 将继续使用标准退避策略重新启动它(以指数方式增加重新启动之间的暂停时间)。下图描述了这种情况。
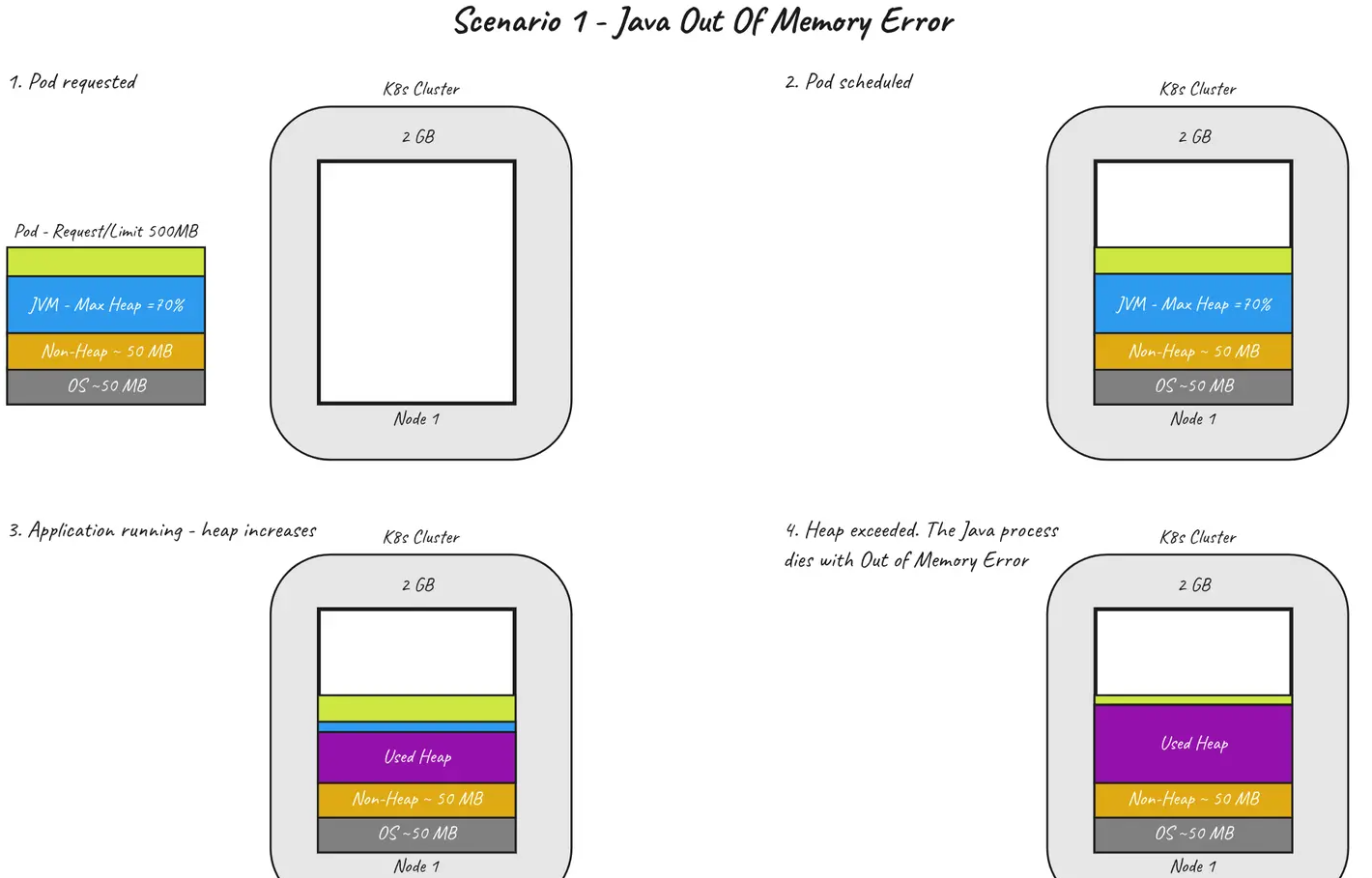
这种情况下的关键要点是 —— 如果 Java 因 OutOfMemory 错误而失败,您将在 pod 日志中看到它👌。
场景 2 — Pod 超出内存 limit 限制
为了实现这个场景,我们的 Java 应用程序需要更多内存。我们将 MaxRAMPercentage 从 70% 增加到 90%,看看会发生什么。我们按照与之前相同的步骤并查看日志。该应用程序运行良好了一段时间:
...
...
INFO 323.00 MB 83.00 MB 406.00 MB
INFO 333.00 MB 73.00 MB 406.00 MB
然后 …… 噗。没有更多的日志。我们运行与之前相同的 describe 命令以获取有关 pod 状态的详细信息。
Containers:
heapkiller:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Events:
Type Reason Age From Message
---- ------ ---- ---- ------
...
...
Warning BackOff 6s (x7 over 107s) kubelet Back-off restarting failed container
乍看之下,这与之前的场景类似 —— pod crash,现在处于 CrashLoopBackOff(Kubernetes 一直在重启),但实际上却大不相同。之前,pod 中的进程退出(JVM 因内存不足错误而崩溃),在这种情况下,是 Kubernetes 杀死了 pod。该 OOMKill 状态表示 Kubernetes 已停止 pod,因为它已超出其分配的内存限制。这怎么可能?
通过将 90% 的可用内存分配给堆,我们假设其他所有内容都适合剩余的 10% (50MB),而对于我们的应用程序,情况并非如此,这导致内存占用超过 500MB 限制。下图展示了超出 pod 内存限制的场景。
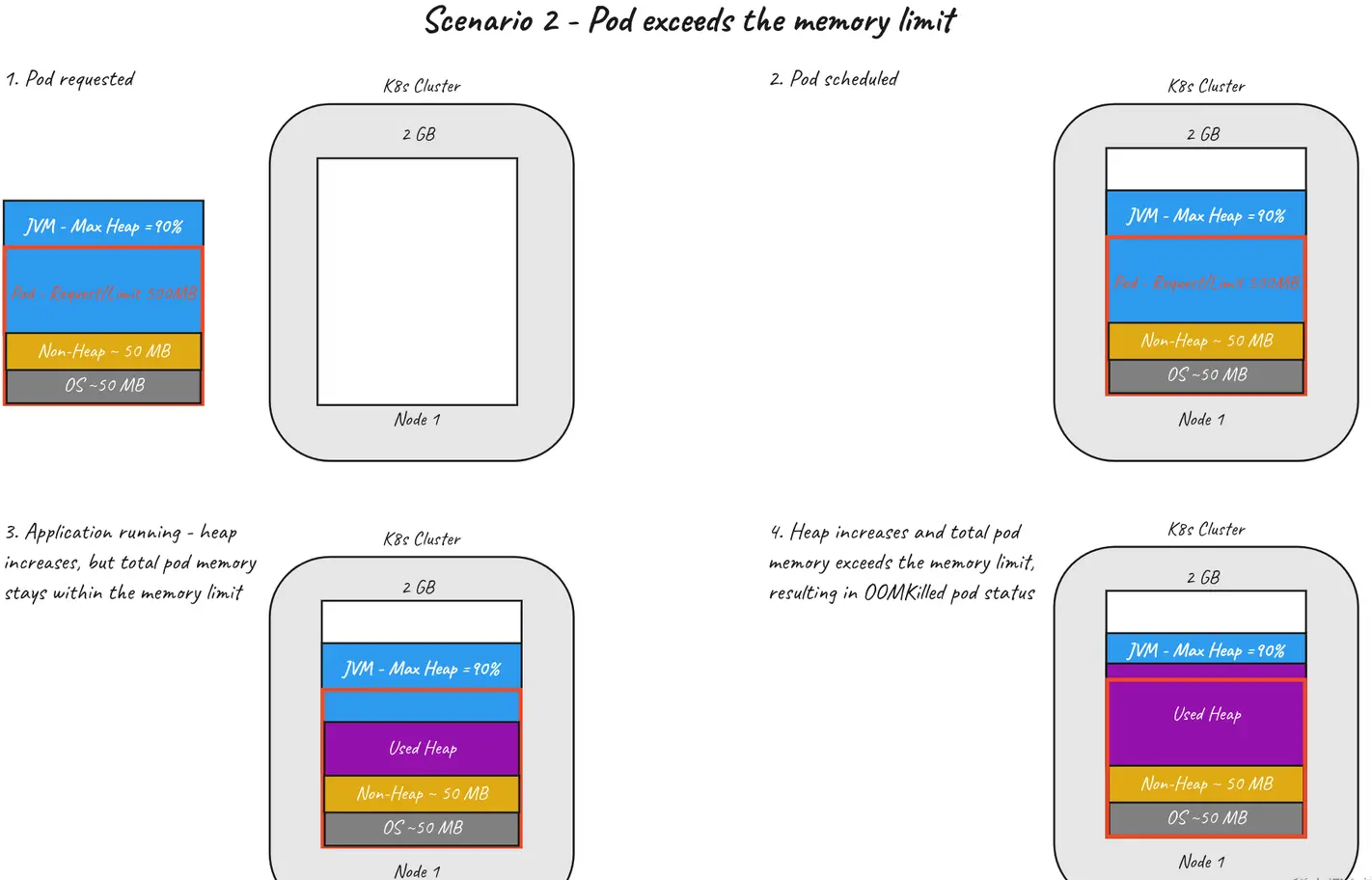
要点 —— OOMKilled 在 pod 的状态中查找。
场景 3 — Pod 超出节点的可用内存
最后一种不太常见的故障情况是 pod 驱逐。在这种情况下 — 内存request和limit是不同的。Kubernetes 根据request参数而不是limit参数在节点上调度 pod。如果一个节点满足请求,kube-scheduler将选择它,而不管节点满足限制的能力如何。在我们将 pod 调度到节点上之前,让我们先看一下该节点的一些详细信息:
~ kubectl describe node/docker-desktop
Allocatable:
cpu: 4
memory: 1933496Ki
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 850m (21%) 0 (0%)
memory 240Mi (12%) 340Mi (18%)
我们可以看到该节点有大约 2GB 的可分配内存,并且已经占用了大约 240MB(由kube-system pod,例如etcd和coredns)。
对于这种情况,我们调整了 pod 的参数 —— request: 500Mi(未更改),limit: 2500Mi 我们重新配置应用程序以将堆填充到 2500MB(之前为 350MB)。当 pod 被调度到节点上时,我们可以在节点描述中看到这种分配:
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1350m (33%) 500m (12%)
memory 740Mi (39%) 2840Mi (150%)
当 pod 到达节点的可用内存时,它会被杀死,我们会在 pod 的描述中看到以下详细信息:
~ kubectl describe pod/heapkiller
Status: Failed
Reason: Evicted
Message: The node was low on resource: memory.
Containers:
heapkiller:
State: Terminated
Reason: ContainerStatusUnknown
Message: The container could not be located when the pod was terminated
Exit Code: 137
Reason: OOMKilled
这表明由于节点内存不足,pod 被逐出。我们可以在节点描述中看到更多细节:
~ kubectl describe node/docker-desktop
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning SystemOOM 1s kubelet System OOM encountered, victim process: java, pid: 67144
此时,CrashBackoffLoop 开始,pod 不断重启。下图描述了这种情况。
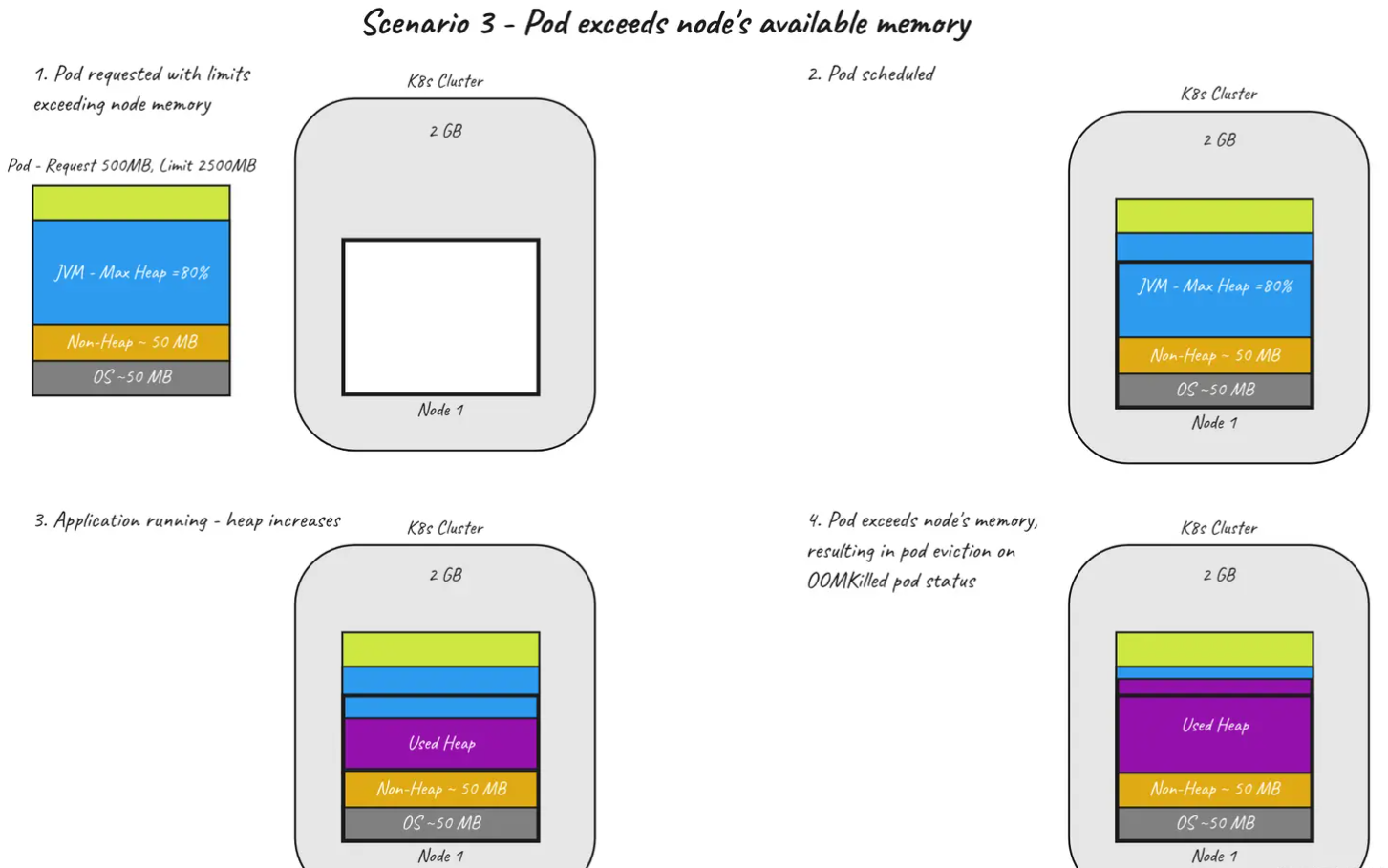
关键要点 —— 在 pod 的状态中查找 Evicted 以及通知节点内存不足的事件。
场景 4 — 参数配置良好,应用程序运行良好
最后一个场景显示应用程序在正确调整的参数下正常运行。为此,我们将pod 的request和 limit 都设置为 500MB,将 -XX:MaxRAMPercentage 设置为 80%。
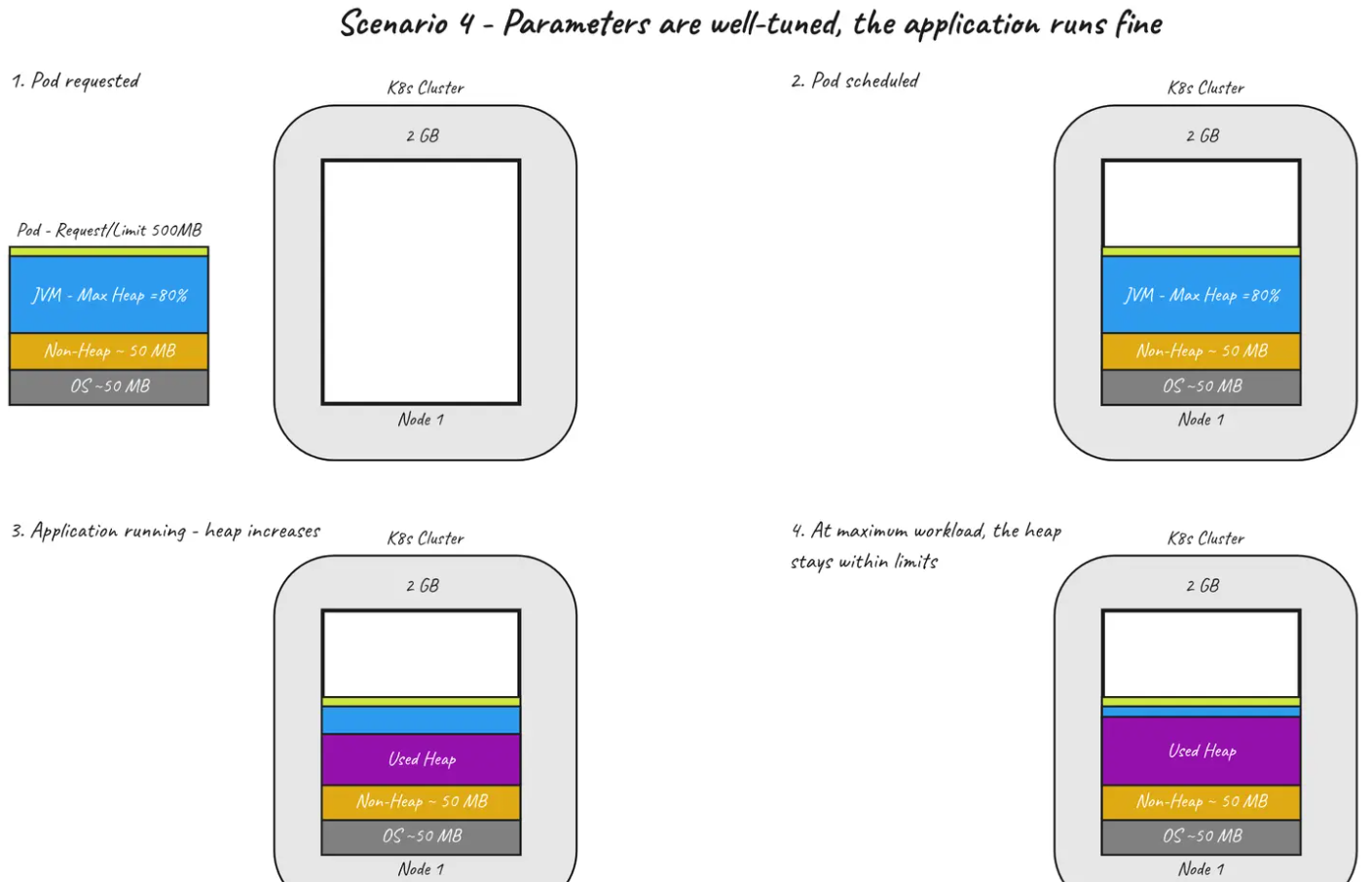
让我们收集一些统计数据,以了解节点级别和更深层次的 Pod 中正在发生的情况。
~ kubectl describe node/docker-desktop
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1350m (33%) 500m (12%)
memory 740Mi (39%) 840Mi (44%)
节点看起来很健康,有空闲资源👌。让我们看看 pod 的内部。
# Run from within the container
~ cat /sys/fs/cgroup/memory.current
523747328
这显示了容器的当前内存使用情况。那是 499MB,就在边缘。让我们看看是什么占用了这段内存:
# Run from within the container
~ ps -o pid,rss,command ax
PID RSS COMMAND
1 501652 java -XX:NativeMemoryTracking=summary -jar /app.jar
36 472 /bin/sh
55 1348 ps -o pid,rss,command ax
RSS,*Resident Set Size,*是对正在占用的内存进程的一个很好的估计。上面显示 490MB(501652 bytes)被 Java 进程占用。让我们再剥离一层,看看 JVM 的内存分配。我们传递给 Java 进程的标志 -XX:NativeMemoryTracking 允许我们收集有关 Java 内存空间的详细运行时统计信息。
~ jcmd 1 VM.native_memory summary
Total: reserved=1824336KB, committed=480300KB
- Java Heap (reserved=409600KB, committed=409600KB)
(mmap: reserved=409600KB, committed=409600KB)
- Class (reserved=1049289KB, committed=4297KB)
(classes #6760)
( instance classes #6258, array classes #502)
(malloc=713KB #15321)
(mmap: reserved=1048576KB, committed=3584KB)
( Metadata: )
( reserved=32768KB, committed=24896KB)
( used=24681KB)
( waste=215KB =0.86%)
( Class space:)
( reserved=1048576KB, committed=3584KB)
( used=3457KB)
( waste=127KB =3.55%)
- Thread (reserved=59475KB, committed=2571KB)
(thread #29)
(stack: reserved=59392KB, committed=2488KB)
(malloc=51KB #178)
(arena=32KB #56)
- Code (reserved=248531KB, committed=14327KB)
(malloc=800KB #4785)
(mmap: reserved=247688KB, committed=13484KB)
(arena=43KB #45)
- GC (reserved=1365KB, committed=1365KB)
(malloc=25KB #83)
(mmap: reserved=1340KB, committed=1340KB)
- Compiler (reserved=204KB, committed=204KB)
(malloc=39KB #316)
(arena=165KB #5)
- Internal (reserved=283KB, committed=283KB)
(malloc=247KB #5209)
(mmap: reserved=36KB, committed=36KB)
- Other (reserved=26KB, committed=26KB)
(malloc=26KB #3)
- Symbol (reserved=6918KB, committed=6918KB)
(malloc=6206KB #163986)
(arena=712KB #1)
- Native Memory Tracking (reserved=3018KB, committed=3018KB)
(malloc=6KB #92)
(tracking overhead=3012KB)
- Shared class space (reserved=12288KB, committed=12224KB)
(mmap: reserved=12288KB, committed=12224KB)
- Arena Chunk (reserved=176KB, committed=176KB)
(malloc=176KB)
- Logging (reserved=5KB, committed=5KB)
(malloc=5KB #219)
- Arguments (reserved=1KB, committed=1KB)
(malloc=1KB #53)
- Module (reserved=229KB, committed=229KB)
(malloc=229KB #1710)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)
- Synchronization (reserved=48KB, committed=48KB)
(malloc=48KB #574)
- Serviceability (reserved=1KB, committed=1KB)
(malloc=1KB #14)
- Metaspace (reserved=32870KB, committed=24998KB)
(malloc=102KB #52)
(mmap: reserved=32768KB, committed=24896KB)
- String Deduplication (reserved=1KB, committed=1KB)
(malloc=1KB #8)
这可能是不言而喻的 —— 这个场景仅用于说明目的。在现实生活中的应用程序中,我不建议使用如此少的资源进行操作。您所感到舒适的程度将取决于您可观察性实践的成熟程度(换句话说——您多快注意到有问题),工作负载的重要性以及其他因素,例如故障转移。
结语
感谢您坚持阅读这篇长文章!我想提供一些建议,帮助您远离麻烦:
- 设置内存的 request 和 limit 一样,这样你就可以避免由于节点资源不足而导致 pod 被驱逐(缺点就是会导致节点资源利用率降低)。
- 仅在出现 Java OutOfMemory 错误时增加 pod 的内存限制。如果发生 OOMKilled 崩溃,请将更多内存留给非堆使用。
- 将最大和初始堆大小设置为相同的值。这样,您将在堆分配增加的情况下防止性能损失,并且如果堆百分比/非堆内存/pod 限制错误,您将“快速失败”。有关此建议的更多信息,请点击此处。
Kubernetes 资源管理和 JVM 内存区域的主题很深,本文只是浅尝辄止。以下是另外一些参考资料:
- learnk8s.io/setting-cpu…
- srvaroa.github.io/jvm/kuberne…
- home.robusta.dev/blog/kubern…
- forums.oracle.com/ords/r/apex…
- 文本翻译自: https://danoncoding.com/tricky-kubernetes-memory-management-f…