在快节奏的生活中,很难找到时间来学习新的技能。但有时候,我们会突然发现自己有一些空闲时间,而又不想虚度光阴。无聊的时候,我们可以选择学习一项新技能来充实自己。最近,我就因为有些无聊,决定重新学习Python编程。在这个过程中,我发现自己的基础知识还有很多缺陷,于是就开始查缺补漏。在这篇博文中,我将会以自己的学习经历为例,分享一些学习Python编程的心得,希望能够帮助到其他想要学习Python编程的读者。
字符串的编码
Python3直接支持Unicode,可以表示世界上任何书面语言的字符。Python3的字符默认就是16位Unicode编码,ASCII码是Unicode编码的子集。
汉字:从国标2312到国标18030
使用内置函数ord()可以把字符转换成对应的Unicode码;
使用内置函数chr()可以把十进制数字转换成对应的字符。
len()用于计算字符串含有多少字符
转义字符
我们可以使用+特殊字符,实现某些难以用字符表示的效果。比如:换行等。常见的转义字符有这些:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \b | 退格(Backspace) |
| \t | 横向制表符 |
| \r | 回车 |
不换行打印
我们前面调用print时,会自动打印一个换行符。有时,我们不想换行,不想自动添加换行符。我们可以自己通过参数end = “任意字符串”。实现末尾添加任何内容:
print("lty",end=' ')
print("lty",end='##')
从控制台读取字符串
我们可以使用input()从控制台读取键盘输入的内容。
myname = input("请输入名字:")
print("您的名字是:"+myname)
执行结果:
请输入名字:lty 您的名字是:lty
使用[]提取字符
字符串的本质就是字符序列,我们可以通过在字符串后面添加[],在[]里面指定偏移量,可以提取该位置的单个字符。
-
正向搜索:
最左侧第一个字符,偏移量是0,第二个偏移量是1,以此类推。直到
len(str)-1为止。 -
反向搜索:
最右侧第一个字符,偏移量是-1,倒数第二个偏移量是-2,以此类推,直到
-len(str)为止。
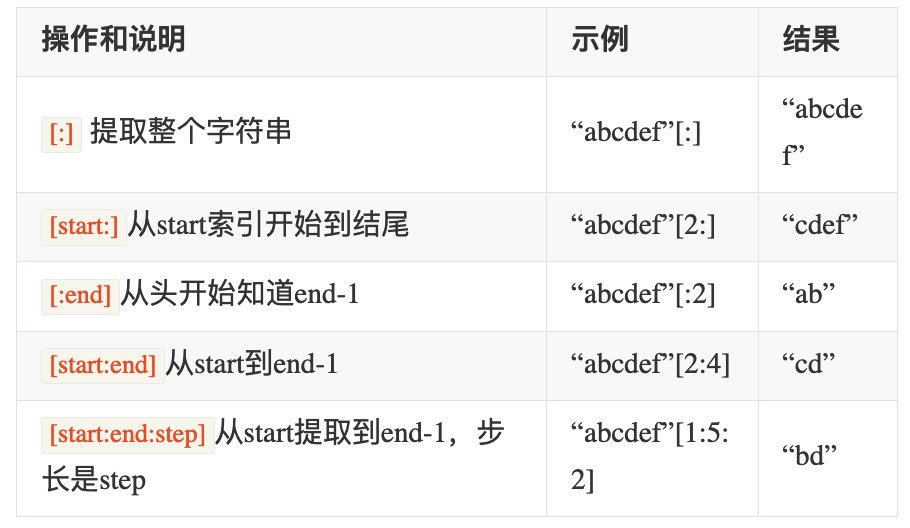
字符串切片slice操作
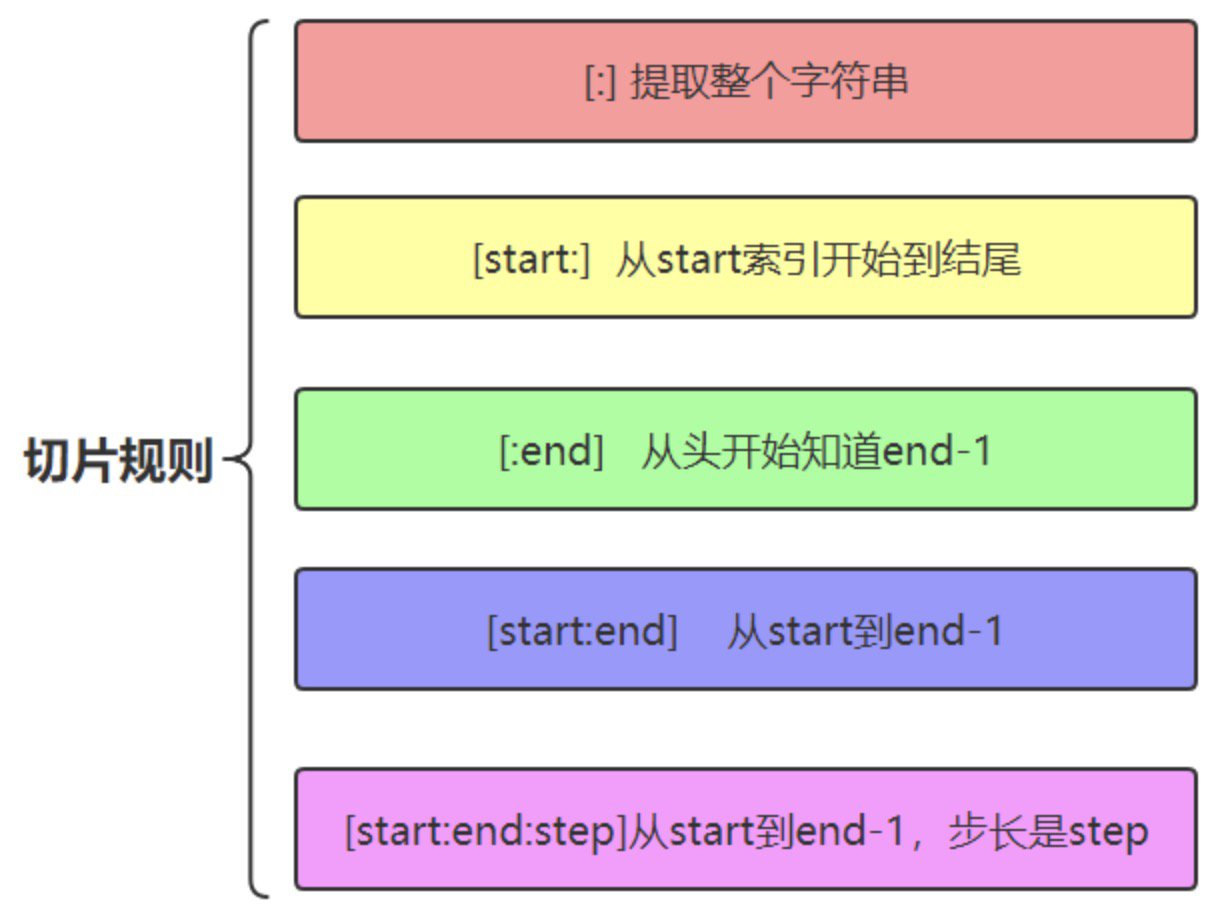
切片slice操作可以让我们快速的提取子字符串。标准格式为:
[起始偏移量start:终止偏移量end:步长step]
典型操作(三个量为正数的情况)如下:
其他操作(三个量为负数)的情况:

切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始偏移量小于0则会当做0,终止偏移量大于“长度-1”会被当成-1。例如:
>>>"abcdefg"[3:50]
'defg'
正常输出了结果,没有报错。
split()分割和join()合并
split()可以基于指定分隔符将字符串分隔成多个子字符串(存储到列表中)。如果不指定分隔符,则默认使用空白字符(换行符/空格/制表符)。示例代码如下:
>>> a = "to be or not to be"
>>> a.split()
['to', 'be', 'or', 'not', 'to', 'be']
>>> a.split('be')
['to ', ' or not to ', '']
join()的作用和split()作用刚好相反,用于将一系列子字符串连接起来。示例代码如下:
>>> a = ['lty','lty100','lty200']
>>> '*'.join(a)
'lty*lty100*lty200'
拼接字符串要点:
使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串。推荐使用join函数,因为join函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
成员操作符判断子字符串
in not in 关键字,判断某个字符(子字符串)是否存在于字符串中。
"ab" in "abcdefg" #true
字符串常用方法汇总
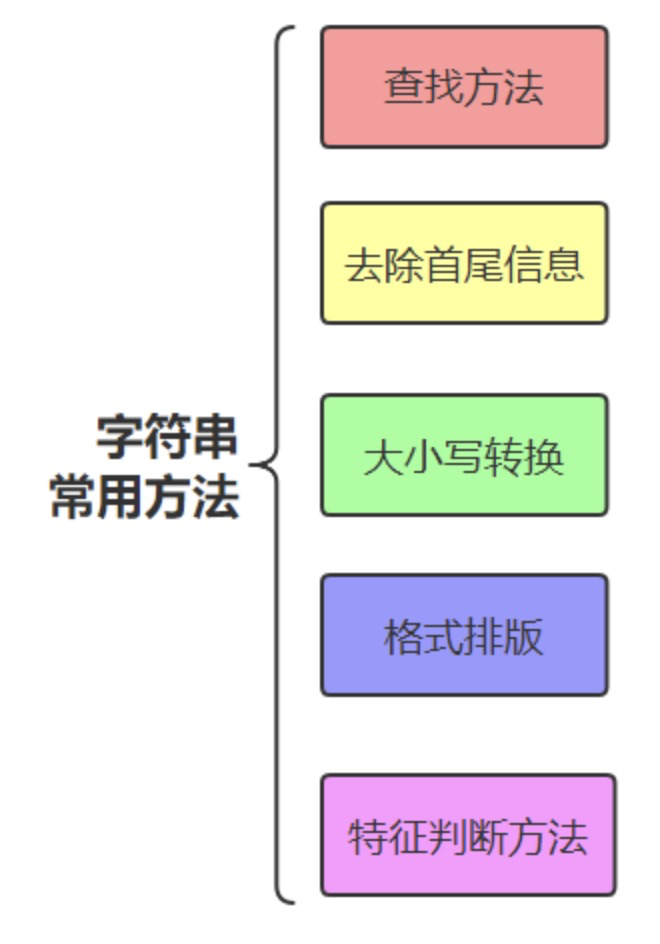
常用查找方法
| 方法 | 说明 |
|---|---|
len(a) | 字符串长度 |
a.startswith('xxx') | 以指定字符串开头 |
a.endswith('xxx') | 以指定字符串结尾 |
a.find('xxx') | 第一次出现指定字符串的位置 |
a.rfind('xxx') | 最后一次出现指定字符串的位置 |
a.count("xxx") | 指定字符串出现了几次 |
a.isalnum() | 所有字符全是字母或数字 |
去除首尾信息
我们可以通过strip()去除字符串首尾指定信息。通过lstrip()去除字符串左边指定信息,rstrip()去除字符串右边指定信息。
格式排版
center()、ljust()、rjust()这三个函数用于对字符串实现排版。
字符串的格式化
format()基本用法
基本语法是通过 {} 和:来代替以前的 % 。
format() 函数可以接受不限个数的参数,位置可以不按顺序。
我们通过示例进行格式化的学习。
>>> a = "名字是:{0},年龄是:{1}"
>>> a.format("天天",18)
'名字是:天天,年龄是:18'
>>> a.format("旺旺",6)
'名字是:旺旺,年龄是:6'
>>> b = "名字是:{0},年龄是{1}。{0}是个好女孩"
>>> b.format("天天",18)
'名字是:天天,年龄是18。天天是个好女孩'
>>> c = "名字是{name},年龄是{age}"
>>> c.format(age=19,name='旺旺')
'名字是旺旺,年龄是19'
可以通过{索引}/{参数名},直接映射参数值,实现对字符串的格式化,非常方便。
填充与对齐
-
填充常跟对齐一起使用
-
^、<、>分别是居中、左对齐、右对齐,后面带宽度 -
:号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
>>> "{:*>8}".format("245")
'*****245'
>>> "我是{0},我喜欢数字{1:*^8}".format("天天","666")
'我是天天,我喜欢数字**666***'
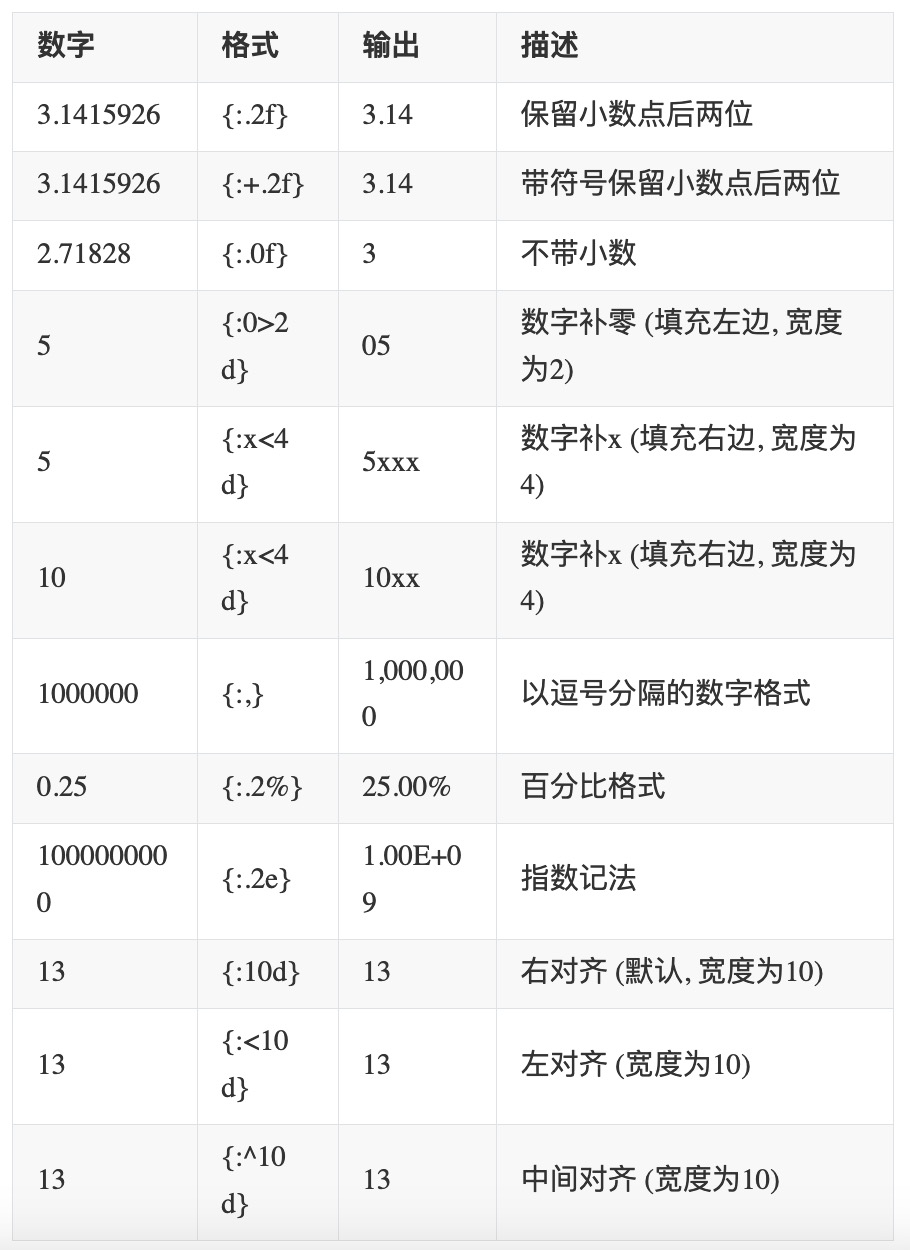
数字格式化
浮点数通过f,整数通过d进行需要的格式化。案例如下:
>>> a = "我是{0},我的存款有{1:.2f}"
>>> a.format("天天",3888.234342)
'我是天天,我的存款有3888.23'
其他格式,供大家参考: