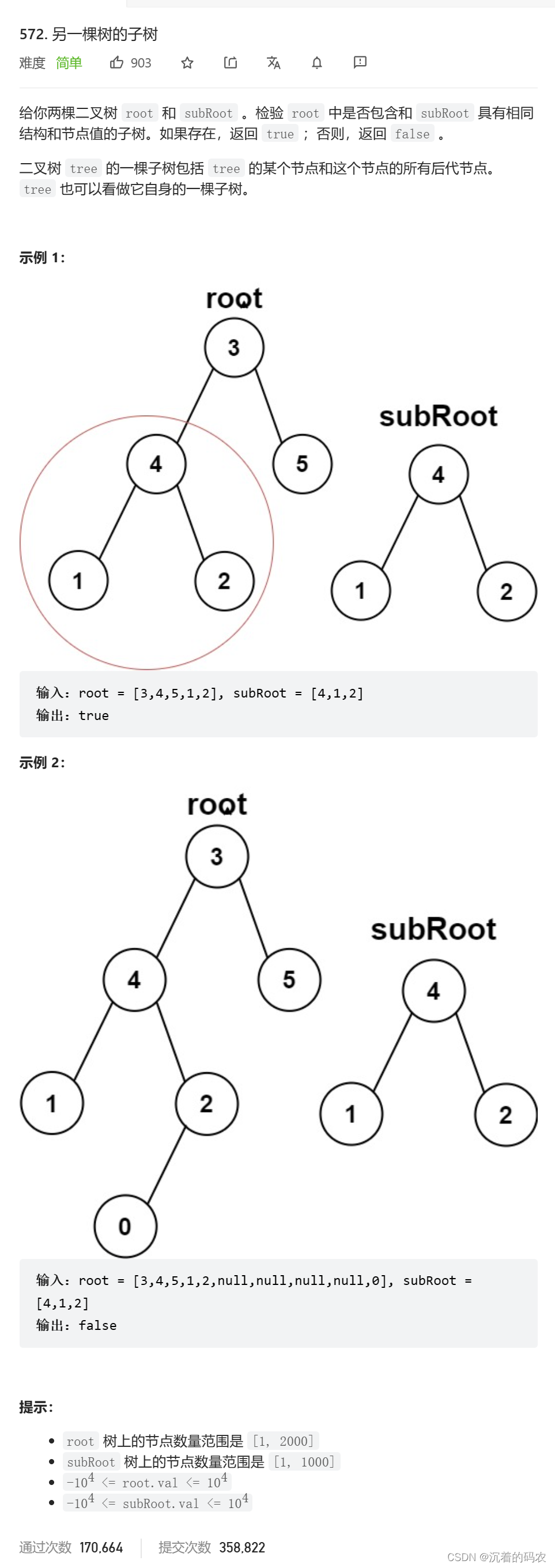
go–goc
goc采用的是插桩源码的形式,而不是待二进制执行时再去设置breakpoints。这就导致了当前go的测试覆盖率收集技术,一定是侵入式的,会修改目标程序源码。直接看案例
package main
import "fmt"
func main() {
test2(3)
fmt.Println("main")
test2(-3)
}
func test1() {
fmt.Println("hello")
fmt.Println("test1")
}
func test2(a int) {
if a > 0 {
fmt.Println(a)
test1()
} else {
fmt.Println("world")
}
fmt.Println("test2")
}
运行命令
go tool cover -mode=count -var=CoverageVariableName learn/cover/exp1/main.go >> learn/cover/exp1/main_gen.go
生成的代码如下
//line learn/cover/exp2/main.go:1
package main
import "fmt"
func main() {CoverageVariableName.Count[0]++;
test2(3)
fmt.Println("main")
test2(-3)
}
func test1() {CoverageVariableName.Count[1]++;
fmt.Println("hello")
fmt.Println("test1")
}
func test2(
a int) {CoverageVariableName.Cont[2]++;
if a > 0 {CoverageVariableName.Count[4]++;
fmt.Println(a)
test1 (
CoverageVariableName.Count[5]++
} else{ CoverageVariableName.Count[5]++;{
fmt.Println("world")
}}
CoverageVariableName.Count[3]++;fmt.Println("test2")
}
var CorageVariableName = struct {
Count [6]uint32 //数组中每个元素代表相应基本块(basic block)被执行到的次数
Pos [3 * 6]uint32 // 代表的各个基本块在源码文件中的位置,三个为一组。比如这里的`21`代表该基本块的起始行数,`23`代表结束行数,`0x2000d`比较有趣,其前16位代表结束列数,后16位代表起始列数。通过行和列能唯一确定一个点,而通过起始点和结束点,就能精确表达某基本块在源码文件中的物理范围
NumStmt [6]uint16 // 代表相应基本块范围内有多少语句(statement)
} {
Pos: [3 * 6]uint32{
5, 9, 0x2000d, // [0]
11, 14, 0x2000e, // [1]
16, 17, 0xb0013, // [2]
23, 23, 0x160002, // [3]
17, 20, 0x3000b, // [4]
20, 22, 0x30008, // [5]
},
NumStmt: [6]uint16{
3, // 0
2, // 1
1, // 2
1, // 3
2, // 4
1, // 5
},
}
java-jacoco
jacoco是一个开源的代码覆盖率工具,针对java语言,其使用方法很灵活,可以嵌入到Ant、Maven中;可以作为Eclipse插件,可以使用其JavaAgent技术监控Java程序等等。
java 代码运行原理
java代码是运行在java虚拟机(JVM)上的,JVM相当于一个虚拟的计算机,符合约定的指令均可在上面执行。java编译后的class文件就是一种符合JVM的字节码指令集合,所以可以在JVM上执行。所以JVM其实指的不是运行java代码的虚拟机,它并不关心字节码是由哪种语言编译而来的,而是只要符合该虚拟机指令的文件均可在上面执行,如Kotlin、Groovy、JRuby、Jython、Scala等编译后也可以在JVM上执行。所以java代码在JVM里运行的时候,实际运行的是编译后的class文件字节码指令流,如果想要改变类的行为,分析类的信息等,只需要修改对应的字节码即可
jacoco原理
jacoco即是通过修改class文件的字节码来进行代码覆盖率统计的。即,在原有class字节码中的指定位置插入探针字节码,形成新的字节码指令流。jacoco使用的是ASM字节码框架对字节码进行修改的。jacoco的探针实际是一个布尔值,当代码执行到探针位置时,将其置为true,该探针前面的代码会被认为执行过,然后对该部分代码对应的html文件中的css样式进行染色(红色表示未覆盖,绿色表示已覆盖,黄色表示部分覆盖),形成最终的覆盖率报告
jacoco插庄模式(插入探针)
-
offline模式:编译时插桩,在测试前先对文件进行插桩,然后生成插过桩的class或jar包,测试插过桩 的class和jar包后,会生成动态覆盖信息到文件,最后统一对覆盖信息进行处理,并生成报告。
-
on-the-fly模式:运行时插桩,JVM中通过-javaagent参数指定特定的jar文件启动Instrumentation的代理程序,启动jvm实例会调用程序里面的premain方法,通过Class Loader装载一个class前判断是否转换修改class文件,将统计代码插入class,测试覆盖率分析可以在JVM执行测试代码的过程中完成。addTransformer 方法并没有指明要转换哪个类,转换发生在 premain 函数执行之后,main 函数执行之前(转换发生在JVM定义类之前),这时每装载一个类,transform 方法就会执行一次,看看是否需要转换。
插庄对比
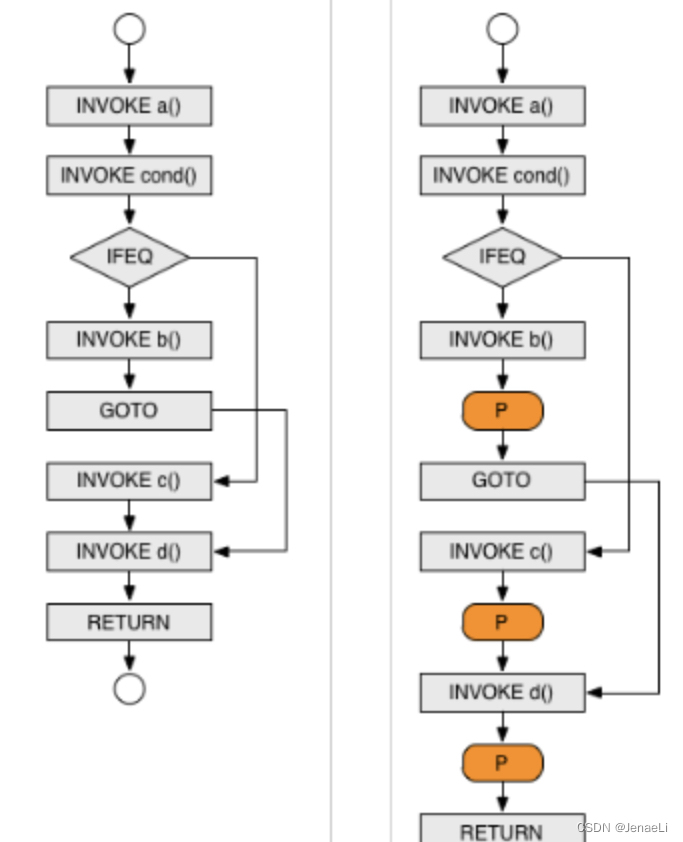
C+±gcov
gcov是gcc内置的一个代码覆盖率工具,配合GCC共同实现对C/C++文件的语句覆盖、功能函数覆盖和分支覆盖测试,通常需要结合lcov生成可视化报告。
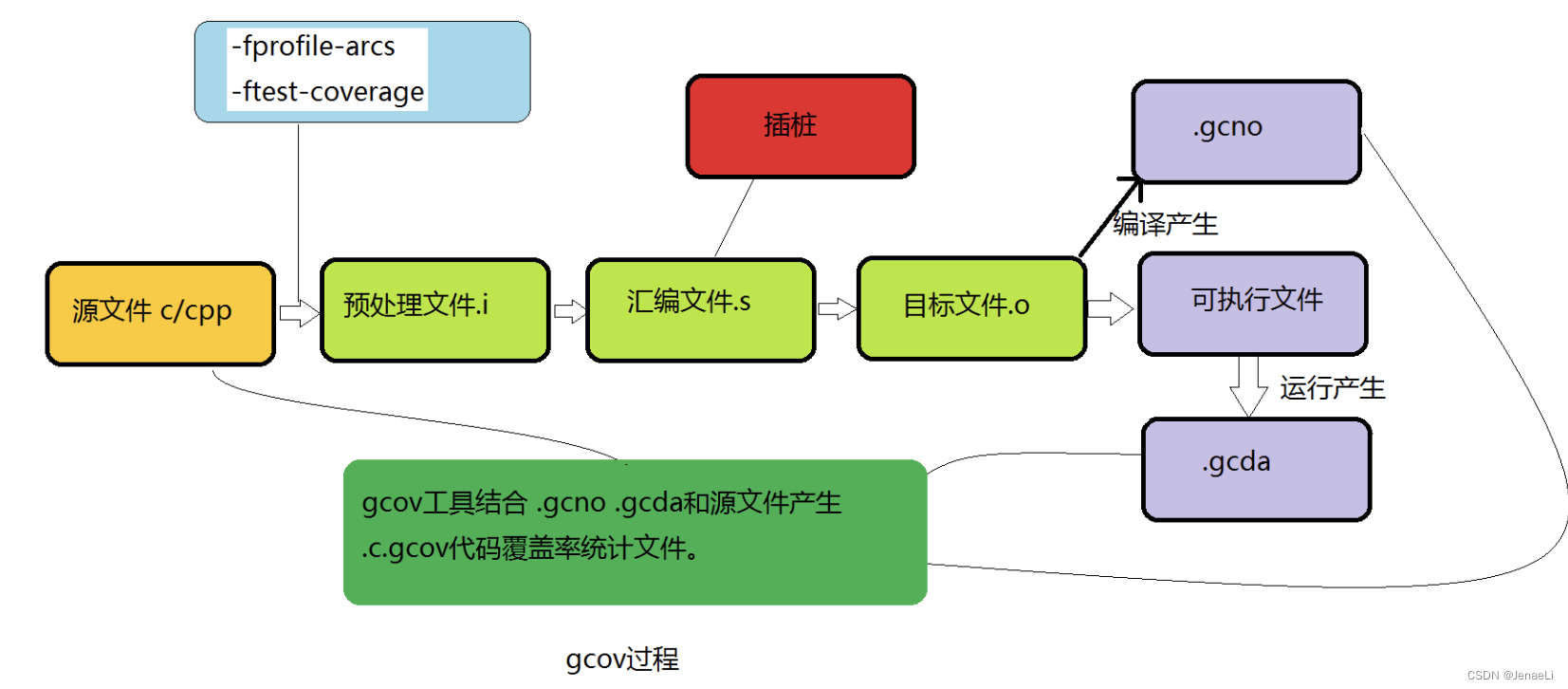
工作流
- 编译前,在编译器中加入编译器参数-fprofile-arcs -ftest-coverage;
- 源码经过编译预处理,然后编译成汇编文件,在生成汇编文件的同时完成插桩。插桩是在生成汇编文件的阶段完成的,因此插桩是汇编时候的插桩,每个桩点插入3~4条汇编语句,直接插入生成的*.s文件中,最后汇编文件汇编生成目标文件,生成可执行文件;并且生成关联BB和ARC的.gcno文件;
- 执行可执行文件,在运行过程中之前插入桩点负责收集程序的执行信息。所谓桩点,其实就是一个变量,内存中的一个格子,对应的代码执行一次,则其值增加一次;
- 生成.gcda文件,其中有BB和ARC的执行统计次数等,由此经过加工可得到覆盖率。
配置使用
gcc -fprofile-arcs -ftest-coverage -o test test.c
-ftest-coverage:在编译时产生.gcno文件,它包含了重建基本块图和相应的块的源码的行号信息*
-fprofile-arcs :在运行编译过的程序,会产生.gcda文件,包含基本块弧跳变的次数信息
Gcc在编译阶段指定 –ftest-coverage 等覆盖率测试选项后,GCC会:
1、 在输出目标文件中留出一段存储区保存统计数据;
2、 在源代码中每行可执行语句生成的代码之后附加一段更新覆盖率统计结果的代码,也就是插桩(后面详细介绍);
3、 Gcc编译,会生成*.gcno文件,它包含重建基本块图和相应块的源码的行号信息;
4、 在最终可执行文件中,进入main函数之前调用gcov_init内部函数初始化统计数据区,并将gcov_init内部函数注册为exit_handers,用户代码调用exit正常结束时,gcov_exit函数得到调用,并继续调用__gcov_flush输出统计数据到*.gcda文件
插庄
gcov是使用 基本块BB 和 跳转ARC 计数,结合程序流图来实现代码覆盖率统计的
基本块BB:如果一段程序的第一条语句被执行过一次,这段程序中的每一个都要执行一次,称为基本块。一个BB中的所有语句的执行次数一定是相同的。一般由多个顺序执行语句后边跟一个跳转语句组成。所以一般情况下BB的最后一条语句一定是一个跳转语句,跳转的目的地是另外一个BB的第一条语句,如果跳转时有条件的,就产生了分支,该BB就有两个BB作为目的地。
跳转ARC:从一个BB到另外一个BB的跳转叫做一个arc,要想知道程序中的每个语句和分支的执行次数,就必须知道每个BB和ARC的执行次数。
如果把BB作为一个节点,这样一个函数中的所有BB就构成了一个有向图。要想知道程序中的每个语句和分支的执行次数,就必须知道每个BB和ARC的执行次数。根据图论可以知道有向图中BB的入度和出度是相同的,所以只要知道了部分的BB或者ARC大小,就可以推断所有的大小。
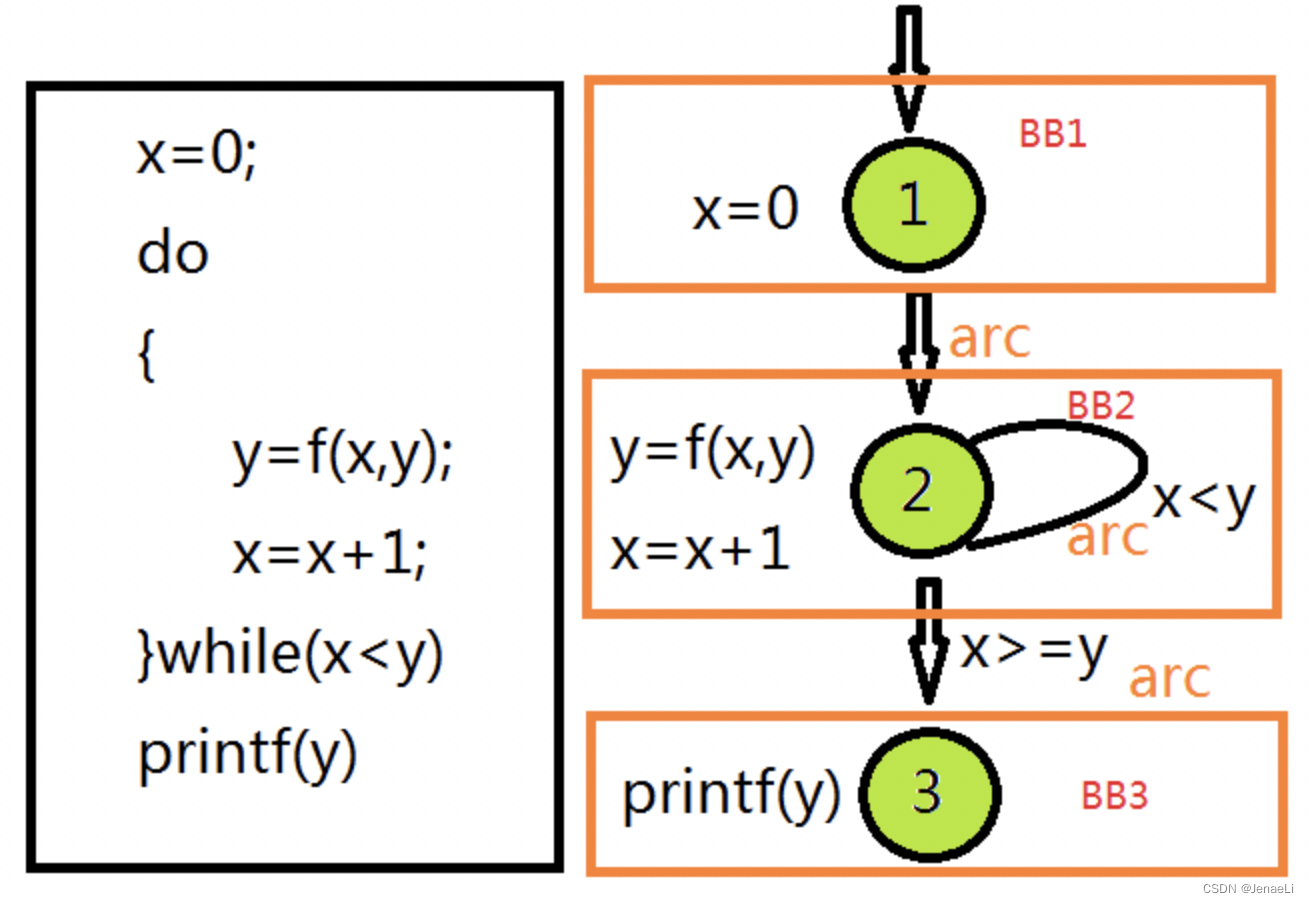
由ARC的执行次数来推断BB的执行次数。所以对部分 ARC插桩,只要满足可以统计出来所有的BB和ARC的执行次数即可。
记录BB块和ARB的数据结构为:
struct bb
{
long zero_word; //是否被插入到链表中
const char *file_name; //当前被测试文件名
long *count;//指向bx2的指针
long ncounts;//桩点个数
struct bb *next;//下一个文件的BX2信息
};
1、GCC在插桩的过程中会向源文件的末尾插入一个静态数组,BX2.,数组的大小就是这个源文件中桩点的个数。BX2+0代表第0个桩点的位置,BX2+n代表第n个桩点的位置,数组的值就是桩点的执行次数。
2、每个桩点插入汇编语句:
*按照我的理解,汇编语句是inc$(BX2+n).
3、 BX2数组链表:
为了便于统计,gcc还将各个源文件中的BX2数组链接成一个链表,这个链表结构是在测试main函数之前就产生了,在调用main之前会有一个类似构造函数的函数,进行构建链表。这个函数会在退出时调用exit函数计算执行次数生成.gcda文件






![[Netty] Netty自带的心跳机制 (十五)](https://img-blog.csdnimg.cn/6862de769e004f6f923fd30c003fbb3c.png)