您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2.网上优质的Python题库很少,这里给大家推荐一款非常棒的Python题库,从入门到大厂面试题👉点击跳转刷题网站进行注册学习
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 6. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
- 1. 简介
- 2. 数据准备&索引优化说明
- 2.1. 左连接说明
- 2.1.1. 没有索引的情况下
- 2.1.2. 给左表添加索引
- 2.1.3. 给右表添加索引
- 2.2. 内连接说明
- 3. JOIN的原理
- 3.1. Simple Nested-Loop Join (简单嵌套循环连接)
- 3.2. Index Nested-Loop Join(索引嵌套循环连接)
- 3.3. Block Nested-Loop Join(块嵌套循环连接)
- 4.总结
- 5. 送书活动
- 第一类【MySQL数据库进阶实战】:共4本
- 1. 评论本文获得
- 2. 参与社区活动获得
1. 简介
上一篇文章我们介绍了
【MySQL从入门到精通】【高级篇】(二十六)建了索引就能用么?我看未必。来看看几种索引失效的情况吧 上篇文章我们将来学习索引失效的几种情况。有时候并不是说加了索引,就一定能用上索引,还是要具体情况具体分析。本文将介绍一下MySQL优化器如何对外连接和内连接进行查询优化的以及介绍Join语句的底层原理。
2. 数据准备&索引优化说明
下面准备了两张数据表,分别是分类表category和图书表book,然后分别在category表和book表中插入17条数据。
-- 分类表
CREATE TABLE IF NOT EXISTS category(
id INT NOT NULL AUTO_INCREMENT,
card INT NOT NULL,
PRIMARY KEY(id)
) ENGINE=INNODB;
-- 图书表
CREATE TABLE IF NOT EXISTS book(
bookid INT NOT NULL AUTO_INCREMENT,
card INT NOT NULL,
PRIMARY KEY(bookid)
) ENGINE=INNODB;
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO category(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
在MySQL中的连接分为外连接和内连接。外连接又分为左连接和右连接。
内连接就是取两个表的交集数据。
左连接以左表为准,取左表的全部关联数据
右连接以右表为准,取右表的全部关联数据
2.1. 左连接说明
2.1.1. 没有索引的情况下
EXPLAIN SELECT SQL_NO_CACHE * FROM category LEFT JOIN book ON category.card=book.card;
没有索引的情况下,直接关联两个数据表查看执行计划可以看出两个表的type都是ALL。

2.1.2. 给左表添加索引
在左连接中,左表作为驱动表,如果给左表添加索引的话,则左表可以使用到索引,这里需要注意的是左表和右表的关联字段的类型要一致呢!
ALTER TABLE category ADD INDEX idx_category_card(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM category LEFT JOIN book ON category.card=book.card;

2.1.3. 给右表添加索引
给右表添加索引也是同理,添加完索引之后,右表作为被驱动表也是可以使用到该索引的,从而避免全表扫描。
ALTER TABLE book ADD INDEX idx_book_card(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM category LEFT JOIN book
ON category.card=book.card;

从上图可以看出,在左连接中左表都是作为驱动表,右表作为被驱动表。
2.2. 内连接说明
EXPLAIN SELECT SQL_NO_CACHE * FROM category INNER JOIN book ON category.card=book.card;

对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现。虽然两个表都有索引,虽然category表在前面,但是最终查询优化器决定将book表作为驱动表。
下面我们试下删除category表中的索引,接着看下效果如何:
EXPLAIN SELECT SQL_NO_CACHE * FROM category INNER JOIN book ON category.card=book.card;
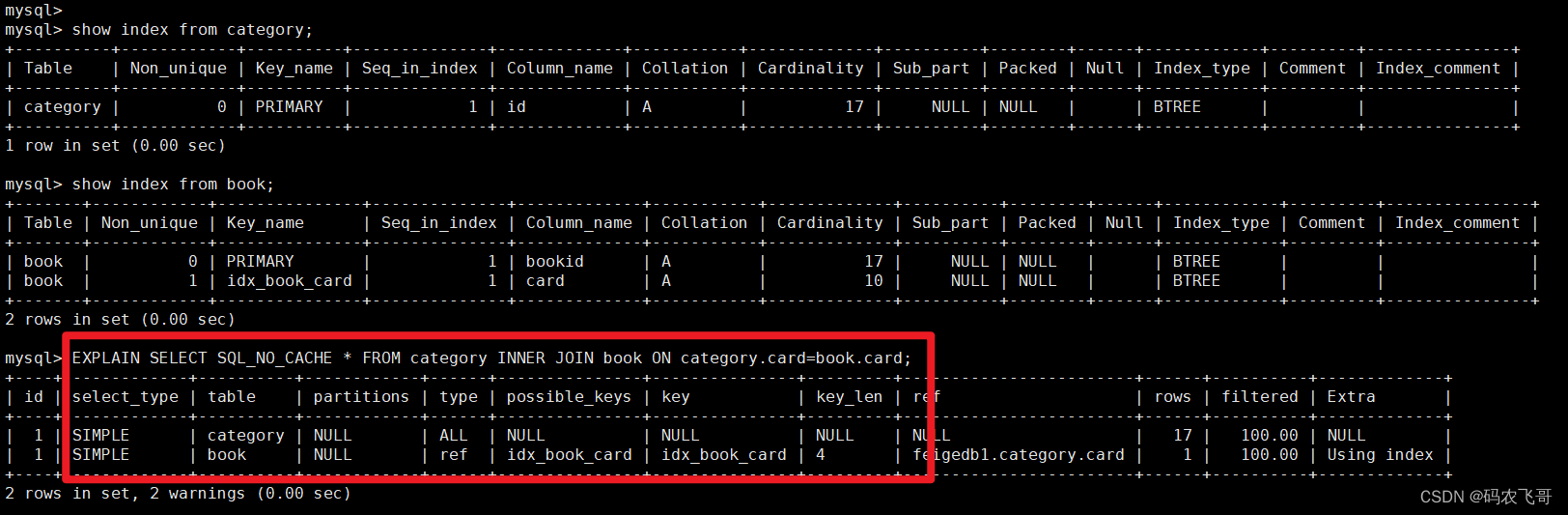
我们可以看出对于内连接来讲,如果表的连接条件中只有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现的。
3. JOIN的原理
join方式连接多个表,本质上就是各个表之间的循环匹配。MySQL5.5 版本之前,MySQL只支持一种表之间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据很大,则join关联的执行时间会非常长,在MySQL5.5 以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
- 驱动表和被驱动表
驱动表就是主表,被驱动表就是从表,非驱动表。
3.1. Simple Nested-Loop Join (简单嵌套循环连接)
算法相当简单,从表A中取出一条数据1,遍历表B,将匹配到的数据放在result,以此类推,驱动表A中的每一条记录与被驱动表B的记录进行判断:
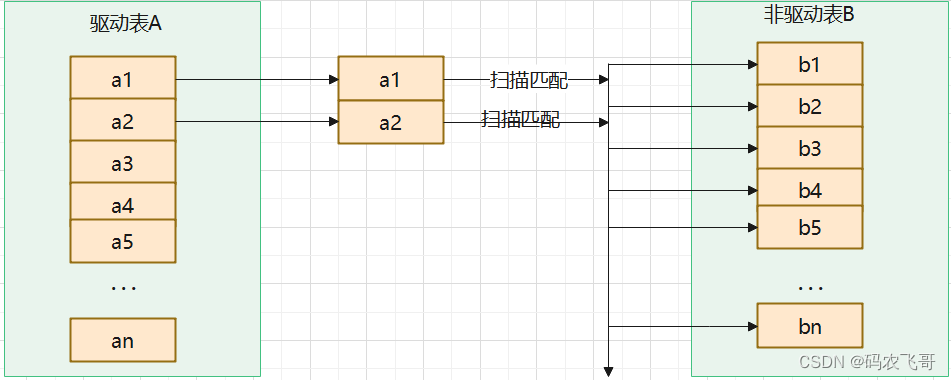
可以看到这种方式效率是非常低效的,以上述表A数据100条,表B数据1000条计算,则A*B=10万次,开销统计如下:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数 | 1 |
| 内表扫描次数 | A |
| 读取记录数 | A+B*A |
| JOIN比较次数 | B*A |
| 回表读取记录次数 | 0 |
| 当然mysql肯定不会那么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join优化算法。 |
3.2. Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路主要是为了减少内层表数据的匹配次数,所以要求被驱动表上必须有索引才行。通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
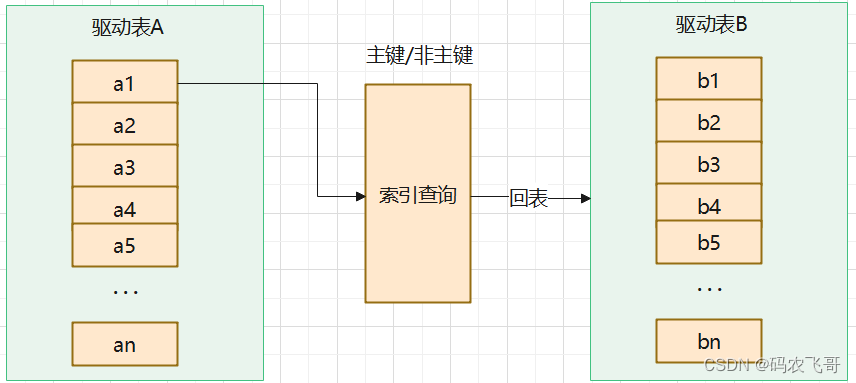
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向驱动表中的每条记录通过被驱动表的索引来进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表进行驱动表(外表)。
| 开销统计 | SNLJ | INLJ |
|---|---|---|
| 外表扫描次数 | 1 | 1 |
| 内表扫描次数 | A | 0 |
| 读取记录数 | A+B*A | A+B(match) |
| JOIN比较次数 | B*A | A*index(Height) |
| 回表读取记录次数 | 0 | B(match)(if possible) |
| 如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,还得进行一次回表查询,所以,如果被驱动表的索引是主键索引,效率会更高。 |
3.3. Block Nested-Loop Join(块嵌套循环连接)
如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表扫描的次数太多了,每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录在加载的记录再加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
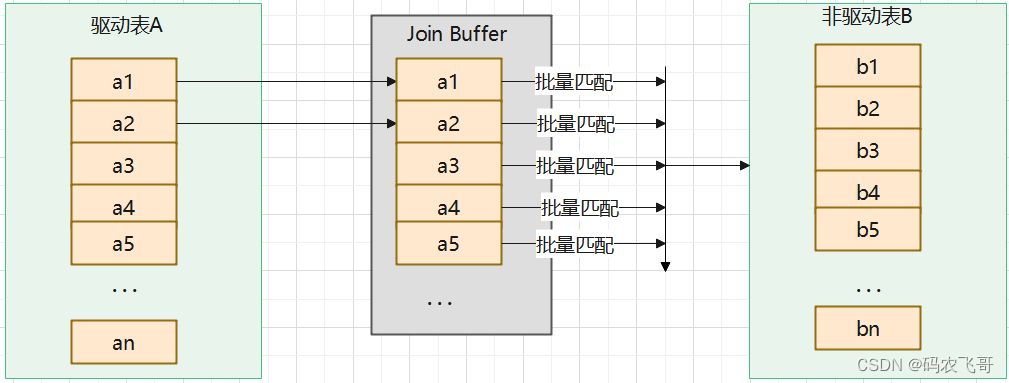
不再是逐条获取驱动表的数据,而是一块一块的获取,引入join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中多次比较合并成一次,降低了被驱动表的访问频率。
注意:
这里缓存的不只是关联表的列,select后面的列也会缓存起来。
在一个有N个join关联的sql中分配N-1个join buffer,所以查询的时候尽量减少不必要的字段,可以让 join buffer中可以存放更多的列。
| 开销统计 | SNLJ | INLJ | BNLJ |
|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 |
| 内表扫描次数 | A | 0 | A*used_column_size/join_buffer_size+1 |
| 读取记录数 | A+B*A | A+B(match) | A+B(A*used_column_size/join_buffer_size) |
| JOIN比较次数 | B*A | A*index(Height) | B*A |
| 回表读取记录次数 | 0 | B(match)(if possible) | 0 |
参数设置:
- block_nested_loop
通过show variables like '%optimizer_switch%'查看block_neseted_loop状态。默认是开启的。 - join_buffer_size
驱动表能不能一次性加载完,要看join buffer 能不能存储所有的数据,默认情况下join_buffer_size=256k。
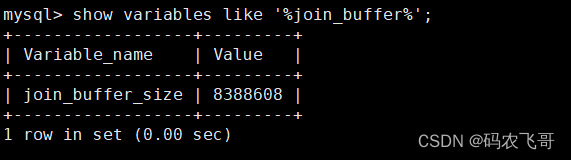
join_buffer_size的最大值在32位系统可以申请4G,而在64位操作系统中可以申请大于4G的Join Buffer空间(64位)
4.总结
- 整体效率比较:INLJ>BNLJ>SNLJ
- 永远用小结果集驱动大结果集(其本质是减少外层循环的数据数量)(这里的小结果集并不一定指数据量少的表,而是值通过筛选条件得到的 表行数*每行大小)
SELECT SQL_NO_CACHE * FROM category INNER JOIN book ON category.card=book.card WHERE book.bookid<100; //推荐
SELECT SQL_NO_CACHE * FROM category INNER JOIN book ON category.card=book.card WHERE category.id<100; //不推荐
- 为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)
- 增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫描次数就越少)
- 减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
5. 送书活动
为了回馈广大粉丝们长期以来的厚爱,本博主决定给小伙伴们送出2类共4本图书。在此特别感谢 机械工业出版社有限公司的赞助,所有图书均包邮包邮包邮!!!!
第一类【MySQL数据库进阶实战】:共4本
《MySQL数据库进阶实战》,本书是作者基于多年的教学与实践进行的总结,重点介绍了MySQL数据库的核心原理与体系架构,涉及开发、运维、管理与架构等知识。全书共12章,包括MySQL数据库基础、详解 InnoDB存储引擎、MySQL用户管理与访问控制、管理MySQL的数据库对象、MySQL应用程序开发、MySQL的事务与锁、MySQL备份与恢复、MySQL的主从复制与主主复制、MySQL的高可用架构、MySQL性能优化与运维管理、MySQL数据库的监控和使用MySQL数据库的中间件。读者根据本书中的实战步骤进行操作,可以在实际项目的生产环境中快速应用并实施MySQL。

1. 评论本文获得
- 本文优质评论两条,且该评论点赞数是最高的,分别获得《MySQL数据库进阶实战》一本!点赞数一样的以提交时间为准,提前时间靠前的优先。
2. 参与社区活动获得
- 参与社区活动,精选优质提交者两人,每人赠送一本《MySQL数据库进阶实战》!
参与的方式是: - 在1024活动帖评论区,回复:“我要报名” 👉 点击跳转到活动贴参与活动吧
- 提交在 👉 “1024 程序员节|用代码,改变世界” 主题征文活动 👈 投稿后,同步提交链接至本社区活动帖的任务区。
统计截止时间:2022/10/30 20:00:00
![[面试宝典] Linux常见命令及面试题](https://img-blog.csdnimg.cn/5d02d759bc10415ab050412889cda58a.png)