摘要:
BEV+Transformer彻底终结了2D直视图+CNN时代,BEV+Transformer对智能驾驶硬件系统有着什么样的影响?背后的受益者又是谁?
图片来源:特斯拉
BEV+Transformer是目前智能驾驶领域最火热的话题,没有之一,这也是无人驾驶低迷期唯一的亮点,BEV+Transformer彻底终结了2D直视图+CNN时代,BEV+Transformer对智能驾驶硬件系统有着什么样的影响?背后的受益者又是谁?
先说结论。首先受益者是视觉系统厂家,车辆至少要增加4-6个摄像头,不过目前新兴造车企业都已经准备好了这些硬件基础,此外需要6-8个加串行芯片,2-3个解串行芯片,加串行与解串行的市场基本被德州仪器和ADI旗下的美信垄断,美信独占了中高端市场,这些芯片价格随着像素的上升也大幅度增加,数量也增加了,最终成本几乎与主SoC一样价格,让ADI业绩大涨。
其次是英伟达这样的强大数据训练系统厂家,Transformer就是暴力美学,参数量动辄十亿百亿千亿,万亿也不罕见,层数动辄上千层,根本不是老旧数据训练中心能支撑的,需要大量购买英伟达或AMD的上万美元级的训练芯片。以前做训练的RTX3090,现在只能做推理用了。毫无疑问这让研发成本暴增。
再次是存储系统,Transformer模型体积惊人,动辄GB起,这需要芯片上的L2缓存大增,实际就是消耗大量的SRAM,对数据训练中心和嵌入式系统来说就是芯片价格暴涨,如果用不起昂贵的SRAM,数据中心这一级也要用HBM。对推理的嵌入式系统来说,HBM的价格太高,消费级的汽车市场是无法接受的,只能退一步选择LPDDR5或GDDR5/6,容量要大幅度增加,至少32GB起,成本自然也大幅增加。
最后是数据搜集和标注,Transformer需要海量训练数据,越多越好,意味着智能驾驶厂家需要更多的数据采集车,数据采集设备,更多的数据处理人员,研发成本暴增。2D直视图+CNN时代厂家累积起来的研发成果化为乌有,很多事情都要从头做起,意味着以前的研发成果贬值严重。最终这一切都转换为消费者头上的成本,成本至少增加300%。
激光雷达和传统AI芯片也将受到影响。首先是激光雷达,BEV+Transformer让纯视觉更加强大,接近以前激光雷达制造BEV的效果,厂家都一窝蜂地拥抱BEV+Transformer,冷落激光雷达。其次是推理用的AI芯片,之前的AI芯片大多是针对CNN的,对Transformer的适应性会比较差,毕竟Transformer是源自自然语言处理(NLP)的,数据的串行性很显著,并行性不佳,这需要AI芯片做出对应的改变,并且是硬件上的改变,这可能意味着推倒重来,或者用更强的Host来对数据整形,也就是标量运算即CPU要加强,Cortex-A55恐怕是无法胜任的。再有原本智能驾驶AI专用芯片都特别针对INT8精度,但Transformer简单量化为8位后性能显著下降,这主要是由于普通的激活函数量化策略无法覆盖全部的取值区间。参数越多,量化后的效果就越差。引入BF16非常有必要,而以前设计的AI芯片大多没考虑BF16。
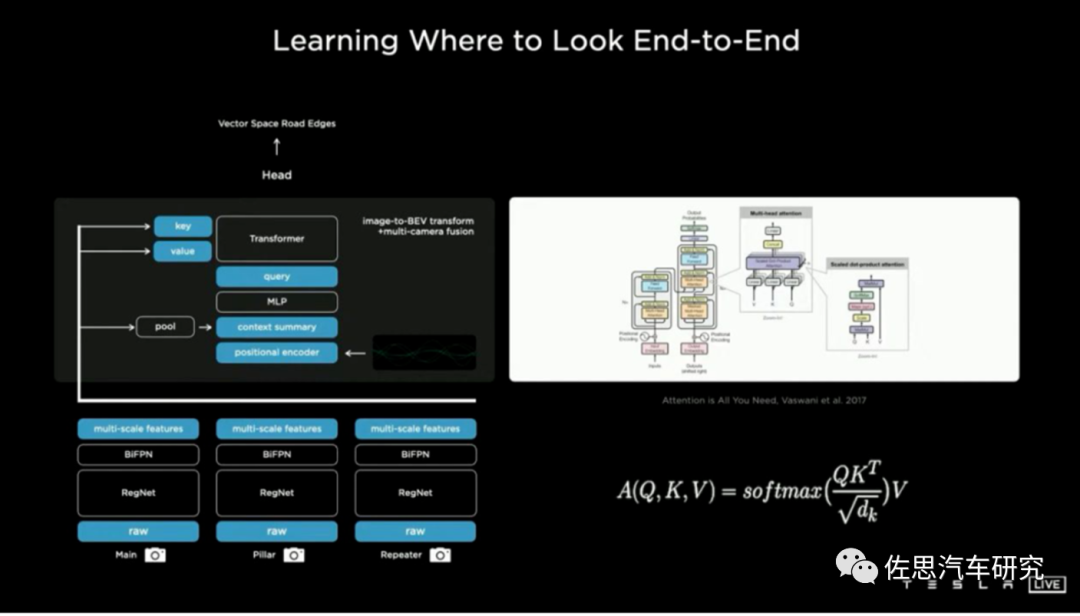
我们来简单了解一下BEV+Transformer,基于多视角摄像头的3D目标检测在鸟瞰图下的感知(Bird's-eye-view Perception, BEV Perception)吸引了越来越多的关注。一方面,将不同视角在BEV下统一表征是很自然的描述,方便后续规划控制模块任务;另一方面,BEV下的物体没有图像视角下的尺度(scale)和遮挡(occlusion)问题。
目前BEV+Transformer算法对比都是基于nuScenes数据集的,因为其训练数据最多,在小尺寸的Kitti上,Transformer表现不如CNN。
nuScenes与其他数据集的对比
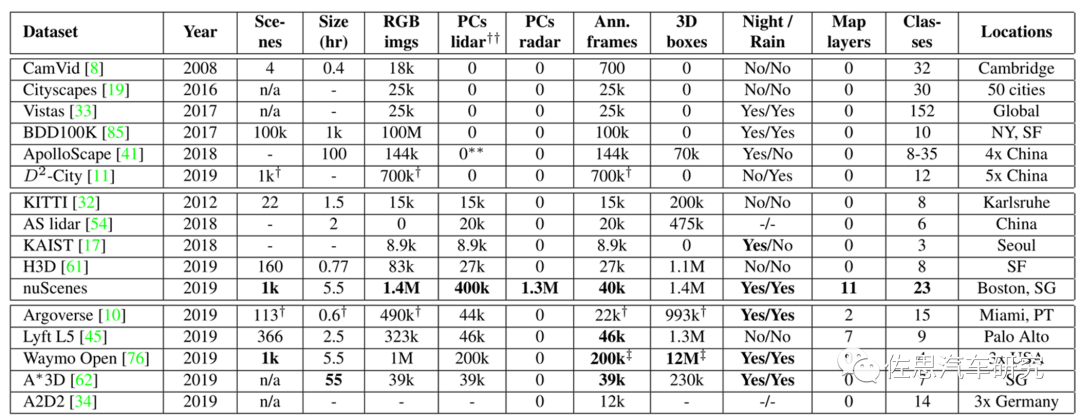
图片来源:《nuScenes: A multimodal dataset for autonomous driving》
nuScenes是唯一有毫米波雷达的数据集。论文名称《nuScenes: A multimodal dataset for autonomous driving》,这是智能驾驶领域最具影响力的数据集,完成于2019年3月,2020年7月推出nuScenes-lidarseg,nuTonomy提出的激光雷达点柱算法也是目前最常用的激光雷达算法。nuScenes-lidarseg则是激光雷达最完备的测试数据集,包含850个训练场景,150个测试场景,惊人的14亿标注点,4万点云帧,32级分类。nuScenes目前由安波福与现代汽车的合资公司Motional维护。
BEV+Transformer基本概念
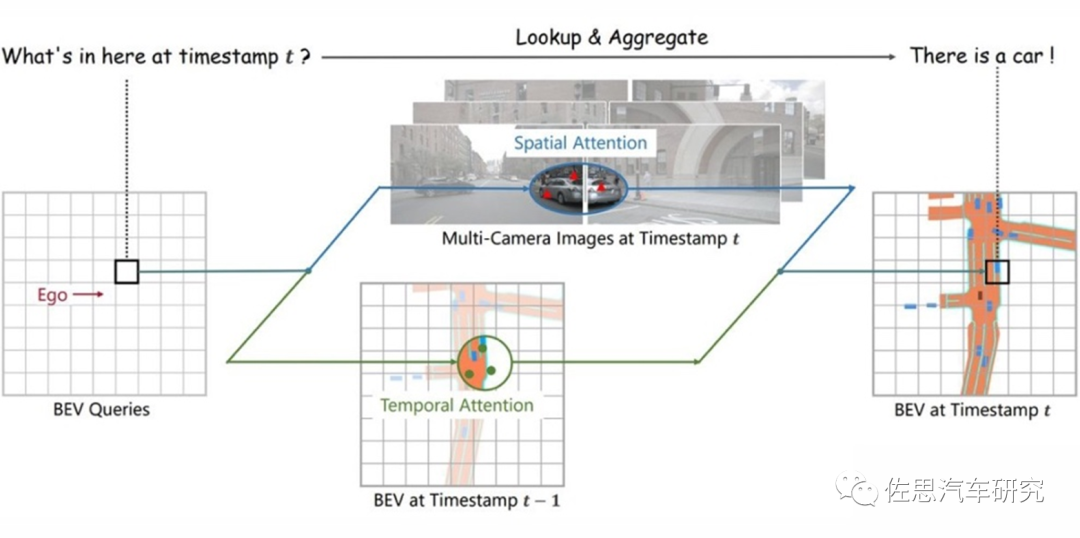
图片来源:《BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers》
CNN时代,完全抛弃了时间序列,智能驾驶检测的是图片而非视频,因此在静止目标识别方面要差很多,也很难定位目标的具体位置,因为移动目标位置是变换的,需要加入时间序列变量。光流加入了时间序列变量,但是单目光流法效果很差,因为光流都是基于立体双目或激光雷达发展而来的,特别是立体双目,做光流尤其合适,奔驰是这方面的顶尖高手,开发了所谓6D视觉,其中光流就是另外3D的构成,不仅能检测目标的速度,还能推断目标的时间序列位置。
Transformer与CNN最大不同就是加入了时序信息,而BEV是一个空间概念,BEV+Transformer就是时空融合,时序信息对于自动驾驶感知任务十分重要,但现阶段基于视觉的3D目标检测方法并没有很好地利用上这一非常重要的信息。时序信息一方面可以作为空间信息的补充,来更好地检测当前时刻被遮挡的物体或者为定位物体的位置提供更多参考信息。另一方面就是对静止目标的处理更加快速高效。
对于每一个位于(x,y)位置的BEV特征,我们可以计算其对应现实世界的坐标 x',y'。然后我们将BEV query进行lift操作,获取在z轴上的多个3D points。有了3D points,就能够通过相机内外参获取3D points在view平面上的投影点。受到相机参数的限制,每个BEV query一般只会在1-2个view上有有效的投影点。基于Deformable Attention,我们以这些投影点作为参考点,在周围进行特征采样,BEV query使用加权的采样特征进行更新,从而完成了spatial空间的特征聚合。将BEV特征视为类似能够传递序列信息的memory。每一时刻生成的BEV特征都从上一时刻的BEV特征获取了所需的时序信息,这样保证能够动态获取所需的时序特征,而非像堆叠不同时刻BEV特征那样只能获取定长的时序信息。
Transformer会疯狂消耗内存,内存容量与输入序列长度的平方成正比,与批大小成线性比例。一个vocab Embedding 的shape是(50304, 5120)。而对于每个parameter来说,其需要存储:来自于FP32的weight以及Adam的(Embedding也是Adam更新),来自于前向时FP16的weight。注意,此处没有grad的计算,因为Embedding layer的grad通常占用的很小,不像MatMul一样。最终结果是3.6GB,每一层Transformer Encoder Model States消耗约6GB,Activation的batch_size每增加1消耗约1GB,Vocab Embedding Layer模型权重约消耗3.6GB。这是理论值,实际值比这大得多。
对于深度学习或者说人工智能运算,瓶颈就在存储器,最简单的解决办法就是用HBM3内存,HBM就是高宽带。
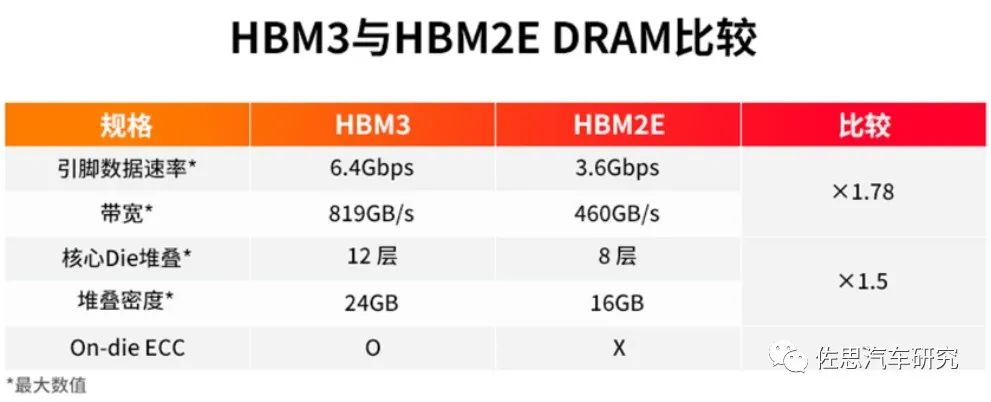
图片来源:SK Hynix
高性能AI芯片必用HBM,而HBM有三个缺点,一是价格昂贵,每GB成本大约20-40美元,至少8GB起售;二是必须使用2.5D封装,成本进一步增加;三是功耗增加不少。
HBM的成本还不是最高的,最高的成本是SRAM,也就是L2缓存,无论是训练还是推理,都要用到,容量越大越好,它的速度比HBM要高许多,成本要高更多。AI芯片当然要用先进工艺,台积电N4即4纳米工艺,这种工艺如果做SRAM并不会提高密度,4N工艺下每MB的SRAM成本大约40-50美元,也有人估计是近100美元。
现在我们来构建一套BEV+Transformer,首选至少需要新增6个摄像头,为什么不能用360环视的摄像头,很简单,360环视用的都是鱼眼镜头,水平FOV一般是195度,其有效距离一般不超过5米,大部分都是在3米甚至2米内。做BEV至少需要20米的侧向有效距离。此外,360环视摄像头的安装高度偏低,做BEV,高度越高越好,最好是车顶。
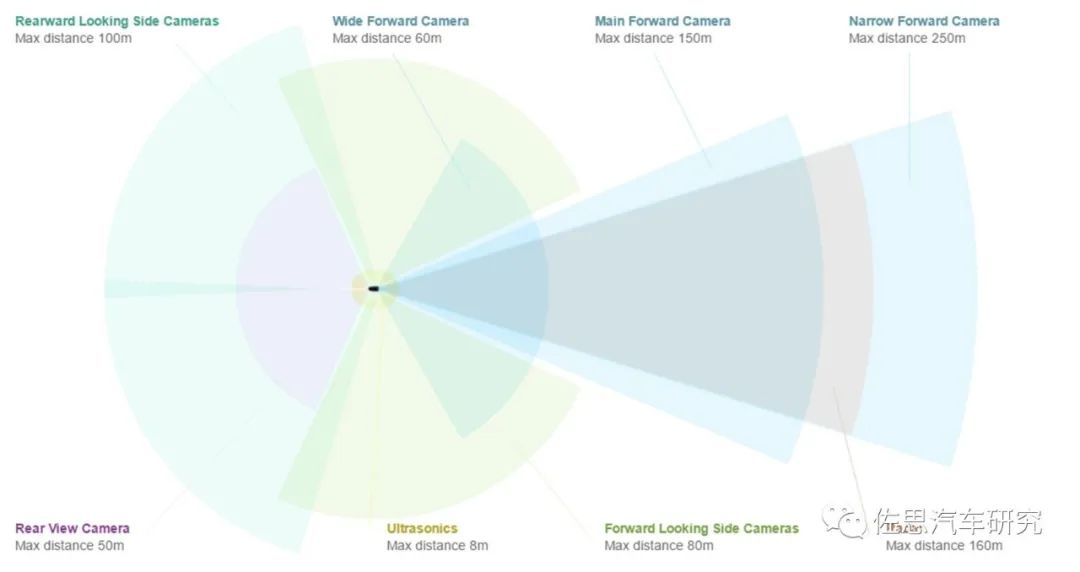
图片来源:特斯拉
特斯拉是8个摄像头,前面3个,FOV分别是35度、50度、120度,侧方A柱和B柱各2个,前侧摄像头的FOV据说是90度,后侧摄像头的FOV推测是80度,后摄像头FOV推测是130度,像素都是130万像素。2023或2024年的HW4.0是7个,前面从三个变成两个,35度FOV的摄像头取消,50度FOV的摄像头像素增加到536万,就是索尼的IMX490做传感器,其余6个摄像头升级为200万像素。
摄像头的有效距离与像素数、安装高度成正比,与水平FOV成反比。中国车特别是新兴造车势力一贯采用800万像素。因此800万像素摄像头6个,像素比较高,FOV就可以宽一点,侧向和后向都用120度,前向还是45度或50度。这需要8个加串行芯片,一般是MAX9295,4个解串行芯片,一般是MAX9296或MAX96712,MAX96712目前非常火爆,2倍甚至3倍高价都拿不到货。光这12个解串行芯片估计就要近150美元,差不多1000人民币。
处理器系统,运算量巨大,非4个顶配Orin莫属,仅此一项大约1200美元。理论上算力足够了,但实际瓶颈在存储,需要强大的存储器,GDDR6或LPDDR5是首选。
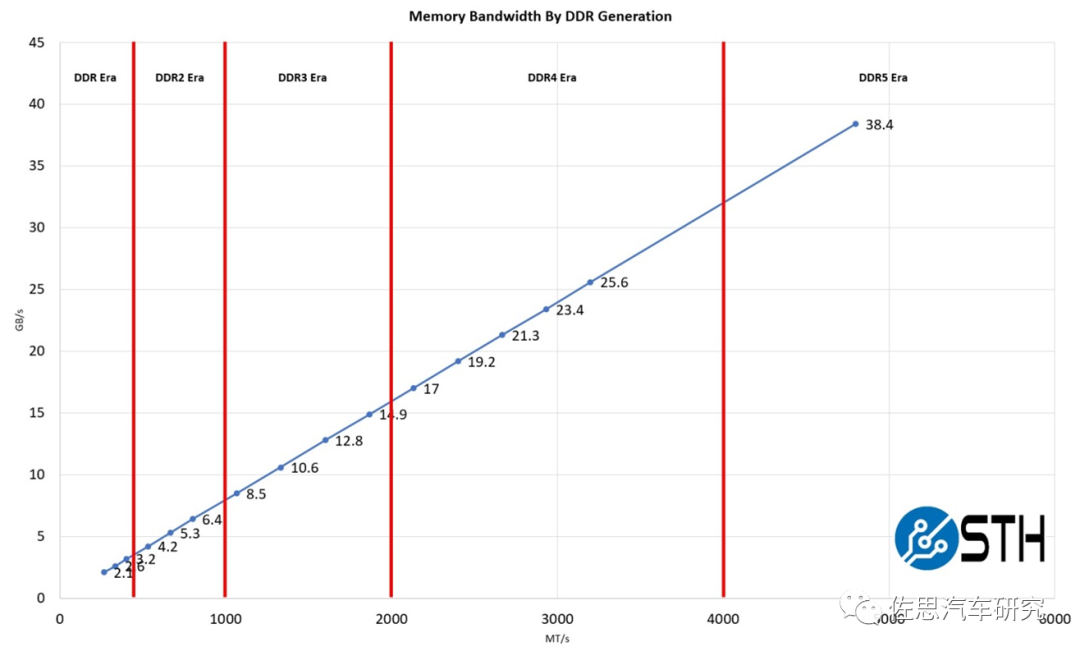
图片来源:STH
DDR5性能提升不少,如上图,英伟达顶配Orin推荐的是64GB的256bit LPDDR5,带宽有204.8GB/s。4个Orin需要256GB LPDDR5,目前48GB LPDDR4报价是35美元,256GB LPDDR5估计要200美元。GDDR6价格会更高,估计要300美元。
BEV+Transformer的根源是特斯拉,特斯拉自然是不用激光雷达的。迄今为止,研究BEV+Transformer的绝大部分都是纯视觉,Waymo、地平线和国内的毫末智行加入了激光雷达。与摄像头比,线数再高的激光雷达都是稀疏点云数据,两者的query特征差别较大,虽然说BEV更适合传感器前融合,但激光雷达的作用明显弱化,核心还是摄像头,纯视觉与加了激光雷达的传感器高级融合,实际差别不大,这与激光雷达领域大量使用点柱算法也有关系,激光雷达的深度信息完全没有发挥,等于是一个能在黑夜工作的加强版的摄像头。反倒是那些8线或16线甚至4线的激光雷达效果更好。
再来看AI芯片,目前智能驾驶领域的AI芯片都是以CNN为核心的,基本都是设计针对INT8即整数8位精度的,在Transformer时代很难有所作为,需要重新设计,且重要性下降,与GPU比差距拉大了。最关键一点,时间序列是矢量,Transformer是浮点矢量矩阵乘法累加运算,浮点运算与整数运算差异巨大,GPU最初就是专门为浮点运算而生的。AI推理专用芯片几乎都不考虑浮点运算。AI芯片做浮点运算时,效率会直线下降。
Swin Transformer的模型结构
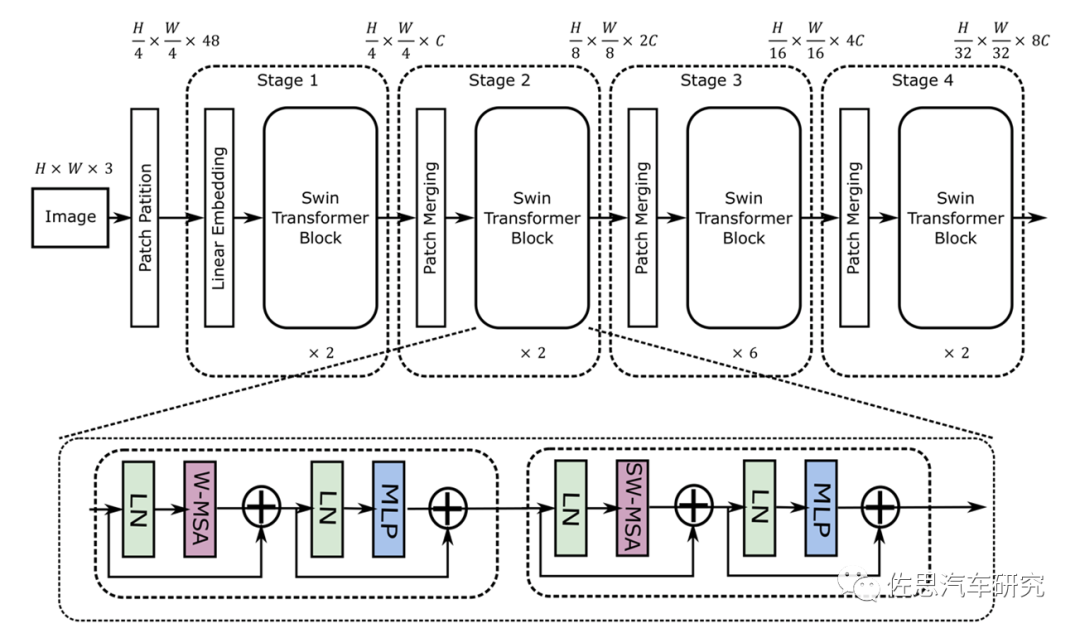
图片来源:《MaxViT: Multi-Axis Vision Transformer》
从图上就能看出其采用了4*4卷积矩阵,而CNN是3*3,这就意味着目前的AI芯片有至少33%的效率下降。再者就是其是矢量与矩阵的乘法,这会带来一定的浮点矢量运算。假设高和宽都为112,窗口大小为7,C为128,那么未优化的浮点计算是:
4*112*112*128*128+2*112*112*112*112*128=41GFLOP/s。大部分AI芯片如特斯拉的FSD和谷歌的TPU,未考虑这种浮点运算。不过华为和高通都考虑到了,英伟达就更不用说了,GPU天生就是针对浮点运算的。
英伟达在新一代GPU中特别增加了Transformer引擎,Transformer引擎的秘诀在于它能够在训练神经网络的每个步骤中动态选择神经网络中每一层所需的精度。最不精确的单元,即8位浮点,可以加快计算速度,但如果这是下一层所需的精度,则可以为下一层生成16位或32位和。不过,Hopper更进一步。它的8浮点单元可以使用两种形式的8位数字中的任何一种进行矩阵数学运算。标准的16位浮点格式(IEEE 754-2008)需要5位指数和10位尾数以及符号位。为了减少数据存储要求和加速机器学习,英伟达和谷歌更喜欢bfloat-16,它用三位尾数换取一个附加指数,使其范围与32位数字相同。bf16是最适合Transformer的格式。英伟达的Transformer引擎可以协调动态范围和准确度,比如浮点8位,大动态范围可以使用5位指数和2位尾数(E5M2),或者当精度是关键时,可以使用4位指数和3位尾数(E4M3)。
CNN的权重模型通常不超过20MB,而Transformer则轻松超过1000MB也就是1GB。以前CNN时代,AI芯片还可以勉强放下权重模型,而Transformer时代则绝无可能,存储器的重要性进一步上升,AI芯片的地位下降,GPU的优势更加明显。
不仅是智能驾驶,所谓AI的发展方向就是,就像劣币驱逐良币一样,这样硬件会不断迭代,成本也会越来越高。
来源 | 佐思汽车研究