如何重构过大类
Hi,我是阿昌,今天学习记录的是关于如何重构过大类的内容。
在过去的代码里一定会遇到一种典型的代码坏味道,那就是“过大类”。
在产品迭代的过程中,由于缺少规范和守护,单个类很容易急剧膨胀,有的甚至达到几万行的规模。过大的类会导致发散式的修改问题,只要需求有变化,这个类就得做相应修改。
所以才有了有时候的“不得已而为之”的做法:为了不让修改引起新的问题,通过复制黏贴来扩展功能。
一、“过大类”的典型问题
“过大类”最常见的情况就是将所有的业务逻辑都写在同一个界面之中。
来看看后面这段示例代码。
public class LoginActivity extends AppCompatActivity {
//省略相关代码... ...
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
loginButton.setOnClickListener(v -> {
String username = usernameEditText.getText().toString();
String password = passwordEditText.getText().toString();
//用户登录
LogUtils.log("login...", username);
try {
//验证账号及密码
if (isValid(username) || isValid(password)) {
callBack.filed("invalid");
return;
}
//通过服务器判断账户及密码的有效性x
boolean result = checkFromServer(username, password);
if (result) {
UserController.isLogin = true;
UserController.currentUserInfo = new UserInfo();
UserController.currentUserInfo.username = username;
//登录成功保持本地的信息
SharedPreferencesUtils.put(this, username, password);
} else {
Log.d("login failed");
}
} catch (NetworkErrorException networkErrorException) {
Log.d("networkErrorException");
}
});
}
private static boolean isValid(String str) {
if (str == null || TextUtils.isEmpty(str)) {
return false;
}
return true;
}
private boolean checkFromServer(String username, String password) {
//通过网络请求服务数据
String result = httpUtil.post(username, password);
//解析Json对象
try {
JSONObject jsonObject = new JSONObject(result);
return jsonObject.getBoolean("result");
} catch (JSONException e) {
e.printStackTrace();
}
return false;
}
public static final String FILE_NAME = "share_data";
public static void put(Context context, String key, Object object) {
SharedPreferences sp = context.getSharedPreferences(FILE_NAME,
Context.MODE_PRIVATE);
SharedPreferences.Editor editor = sp.edit();
//... ...
editor.apply();
}
//省略相关代码... ...
}
从上面的示例代码中可以看出,创建页面时初始化数据后,当用户点击了登录按钮触发数据的校验后,通过网络请求校验数据的正确性,最后进行本地的持续化数据存储。
登录页面不仅仅承载了 UI 控件的初始化和管理,还需要负责登录网络请求、数据校验及结果处理、数据的持久化存储等功能。
假如现在有这么几个产品的需求要增加,应该如何修改代码进行功能扩展呢?
UI 上要做一些优化,当登录失败时要弹出提示框提醒用户。- 需要对数据存储进行升级,所有
数据要存储到数据库中。 - 用户名的规则升级为仅支持电话和邮箱格式,需要在
本地做校验。
可以看出基于这样的设计,不管是 UI 还是校验规则上有需求变化,抑或是数据持久化或网络框架有变化,都需要对登录页面进行修改。
当大量的逻辑耦合在一起时,如果没有任何自动化测试守护,那么就会大大增加修改代码的风险。而且,要是基于这个代码再持续不断地添加新功能 ,就会陷入代码越来越差、但又越来越不敢修改代码的死循环之中。
二、重构策略
随着业务需求和代码规模的不断膨胀,针对过大类的重构策略就是分而治之。
通过分层将不同维度的变化控制在独立的边界中,使之能够独立的演化,从而减少修改代码时彼此之间产生的影响。
从前面的例子可以识别出典型的 3 个不同维度的变化场景:
- 第一个是 UI 上的变化;
- UI 上的变化,如主题或排版的设计,不会对数据业务产生影响,此时如果有
独立的 UI 层,在扩展、修改时就能减少对其他逻辑代码的影响。一般在常见的分层架构模式下,会有独立的 View 层来承载独立的 UI 变化。
- UI 上的变化,如主题或排版的设计,不会对数据业务产生影响,此时如果有
- 第二个是业务数据逻辑的变化;
- 业务数据逻辑的变化也一样,一些数据的校验、计算、组装规则也都是容易发生变化的维度。同样在常见的分层架构中也有
独立的业务逻辑处理层。
- 业务数据逻辑的变化也一样,一些数据的校验、计算、组装规则也都是容易发生变化的维度。同样在常见的分层架构中也有
- 第三个维度是基础设施框架的变化。
- 基础设施框架,比如持久化的框架,可能会从前期轻量的配置存储需求演化为数据库的存储;网络请求框架则可能会随着技术栈的升级替换为新的框架。如果此时所有对于基础设施的调用都散落在各个 UI 的入口上,那么修改变更的成本就会非常高。
下面以 MVP(Model-View-Presenter)这种分层架构为例,来看看 MVP 的架构是如何进行分层设计和交互的。
在 MVP 模式中,模型层提供数据,视图层负责显示,表现层负责逻辑的处理。
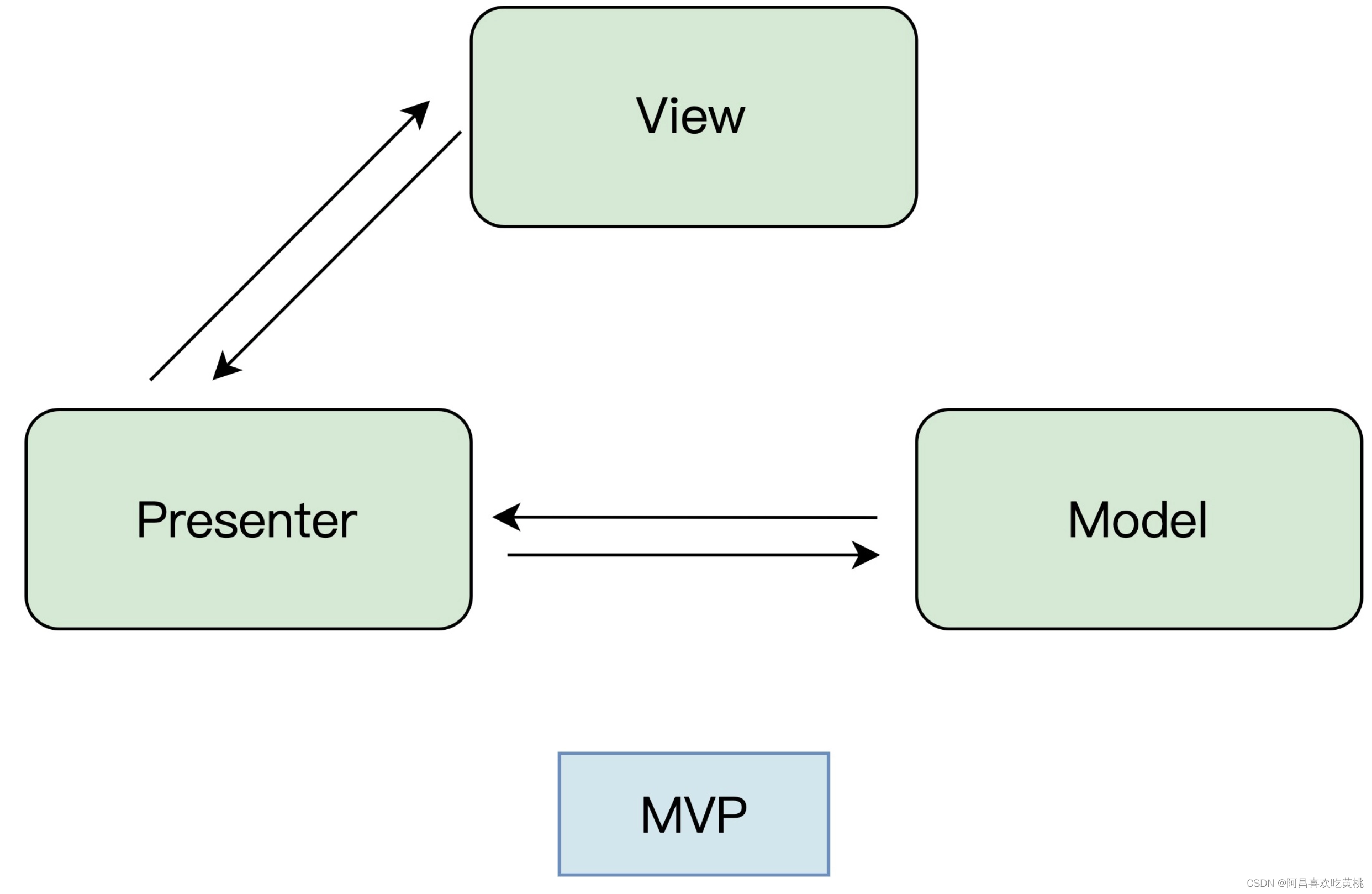
MVP 架构在视图层与表现层的交互过程中都会定义对应的接口,以使彼此之间的依赖更加稳定。
由于模型与视图完全分离,可以在修改视图时不影响模型。
同时也可以将一个表现层用于多个视图,且不需要改变表现层的逻辑。这个特点非常有用,因为视图的变化总是比模型的变化更加频繁。
另外,使用接口依赖能更好地提高代码的可测试性,例如在对表现层进行分层测试时,只需要验证视图层的接口有没有正常被调用即可。
相比对几百行的方法进行测试,职责更加单一的分层能让编写自动化测试的工作变得更简单。
以上面那个新增需求为例,进行重构后的代码扩展方式, 可以参考这张表格。
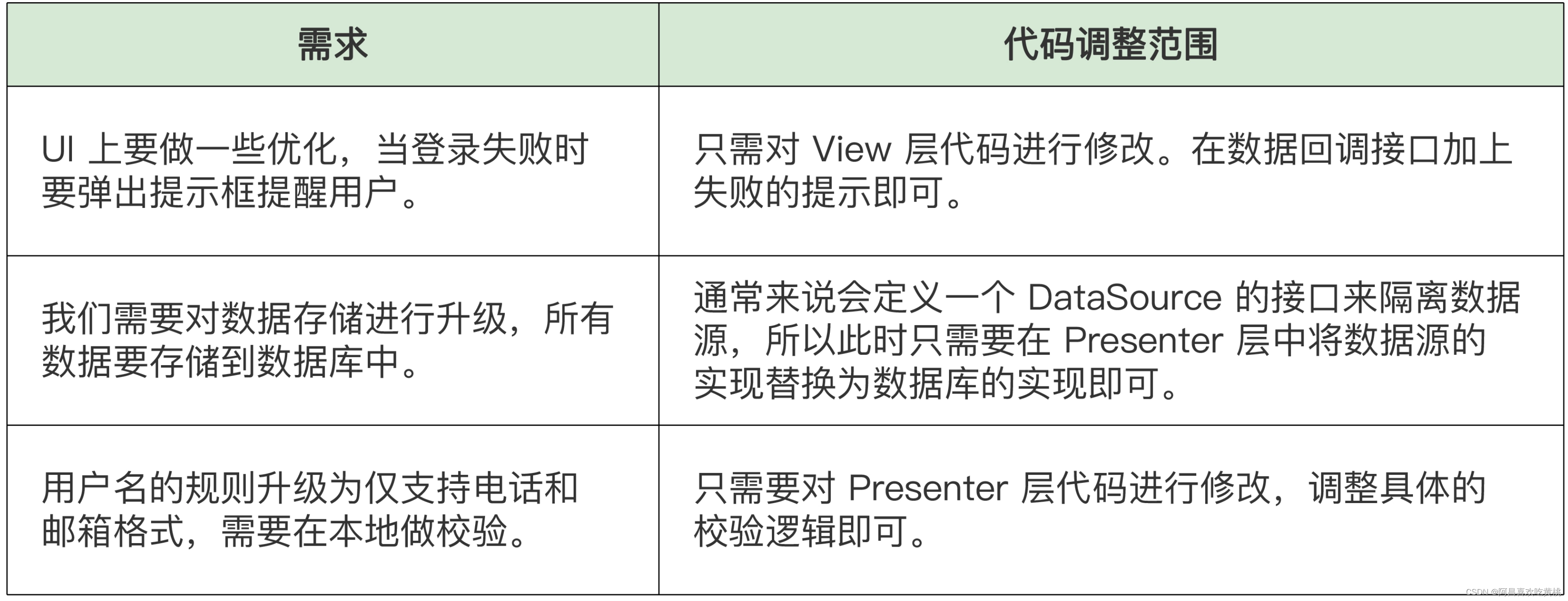
可以看出,分而治之的策略将需求变化隔离在了不同的分层之中,这样需求变化就只在一个可控的边界里,可以减少相互影响。
三、重构流程
回到一开始提出的问题,如何更高效、更高质量地完成组件内分层架构的重构?
将组件内分层架构的重构流程按 3 个维度分为了 7 个步骤。
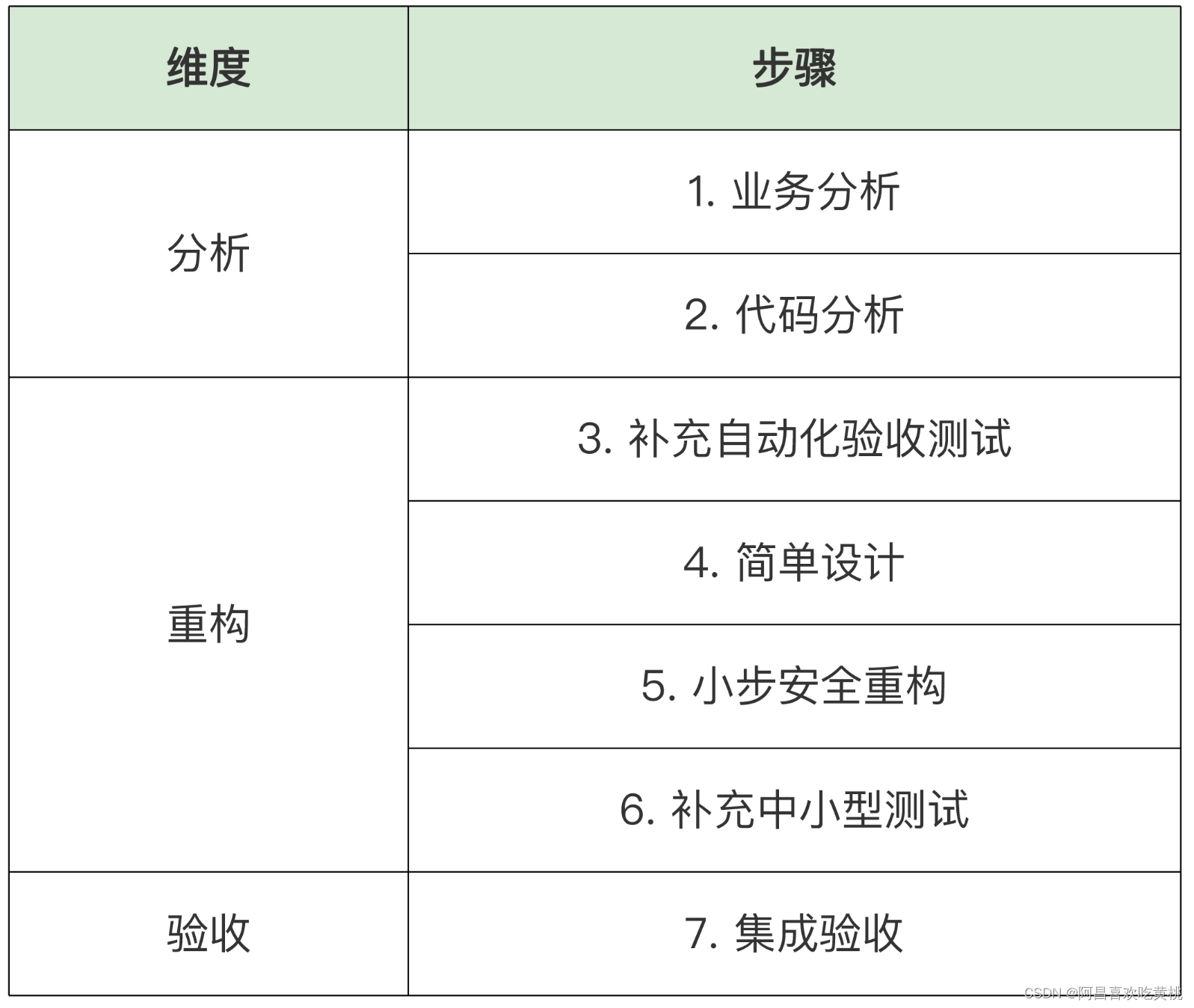
1、业务分析
对于遗留系统来说,比较常见的问题就是需求的上下文中容易存在断层,所以第一步就是尽可能地了解、分析原有的业务需求。
只有更清楚地挖掘原有的需求设计,才不会因为理解上的差异出现错误的代码调整。
参考 3 种常用的方式来理解需求。
- 第一种方式就是找人:通过与相关干系人(如与产品经理、设计人员、测试人员)
沟通,对需求进行确认和答疑,这是最直接有效的方式。 - 第二种方式就是看文档但有时候你会发现如果人员流动大的话,可能相关干系人也不清楚原有的设计,这时可以参考看文档的方法。可以通过查看相关的文档(如查看原有的需求文档、设计文档、测试用例、设计稿),帮助更好地去理解原有的需求。当然这里也有可能存在没有文档或者文档的内容已经过时的问题,
- 第三种方法——看代码。代码肯定反映了最新的代码需求,如果有自动化测试代码,还可以通过测试用例的输入和输出来辅助理解需求。一般可以从最上层的 UI 页面代码看起,逐步根据代码的调用栈查看相关的逻辑。通常来说,业务分析这一步有两个重要的场景要梳理清楚:
- 第一个是用户正常的使用场景;
- 第二个是用户异常的使用场景。这些场景都将是后面补充自动化验收测试的重要输入。还是以前面登陆的代码为例,用户正常的使用场景应该包括:
- 输入正确的账号密码,点击登录正常验证。
- 输入错误的账号密码,点击登录提示失败。
- .……
- 异常的使用场景应该包括:
- 当用户点击登录后,但因为手机出现网络异常,需要提示网络异常。
- 当用户点击登录后,但服务器返回异常的错误时,需要提示相应的错误码。
- ……
2、代码分析
业务分析之后就是代码分析,通过这一步,一方面是要了解原有的业务,另外一方面要去诊断现有代码中有哪些优化点。
通常除了像“过大类”这种明显的问题,可能也会存在代码规范、方法复杂度、循环依赖、代码潜在漏洞等问题。
需要尽可能将这些问题都识别出来,作为后续重构的输入。
推荐几个常用的类检查工具。
-
第一个是 Lint。Lint 是 Android Studio 自带的代码扫描分析工具,它可以帮助我们发现代码结构或质量问题。Lint 发现的每个问题都有描述信息和等级,我们可以很方便地定位问题,同时按照严重程度来解决。
-
第二个是 Sonar。Sonar 也提供了 SonarLint 作为 IDE 的插件。通过该插件可以帮助我们识别代码中的基础坏味道、代码复杂度以及潜在的缺陷等问题。关于 Lint 的使用,你只需要在你的项目中选择 Code->Inspect Code 菜单后运行检查,就可以在 Problems 窗口中查看具体的问题列表了。
关于 SonarLint 插件,你需要先从 IDE 中搜索安装该插件。安装成功后右击鼠标选择菜单栏中的 “Analyze with SonarLint” 可以触发扫描。
具体的问题列表可以在 SonarLint 窗口中查看。
在这一步,建议至少将工具检查出来的 Error 级别问题也纳入重构修改,特别是一些圈复杂度高的类和方法,都可以重点记录下来,这些都是后续做重构需要重点关注的内容。
3、补充自动化验收测试
经过前面的业务分析和代码分析后,来看第三步,这是为第一步业务分析梳理出来的用户场景补充自动化验收测试。
为什么需要先补充自动化验收测试呢?
因为只有有了测试的覆盖,后面第五步在进行小步安全重构时,才能频繁借助这些测试来验证重构有没有破坏原有的业务逻辑,这样能更好地发现和减少因为重构修改代码而引起新的问题。
这一步通常是覆盖中大型的自动化测试,可以借助 Espresso 或 Robolectric 框架。
例如前面那个登录的例子,我将梳理出来的用户场景,变成自动化的验收测试用例。
public class LoginActivityTest{
public void should_login_sucees_when_input_correct_username_and_password(){//... ...}
public void should_login_failed_when_input_error_username_and_password(){//... ...}
public void should_show_network_error_tip_when_current_network_is_exception(){//... ...}
public void should_show_error_code_when_server_is_error(){//... ...}
//... ...
}
注意,这一步需要将前面第一步的业务分析场景全部覆盖,并且所有的用例需要执行通过。
4、简单设计
补充好自动化验收测试后,接下来就是进行“简单设计”了。
这一步让我们在开始动手重构前,想清楚重构后的代码将会是什么样子,以终为始才能让我们的目标更加清晰,让过程更加可度量。
经常听到一句半开玩笑的话,就是“代码重构以后又变成另外一个遗留系统”,其实,这很可能就是因为我们没有先进行设计,缺乏清晰的重构目标。
那么这一步怎么来做呢?
可以根据选择的架构模式,定义出核心的类、接口和数据模型,这些关键的要素能支撑起整个架构的模式。
以登录这个例子来讲,假设希望重构为 MVP 架构,那么首先是整体的核心类的设计。
//View
public class LoginActivity implement LoginContract.LoginView
//Presenter
public class LoginPresenter
//Model
public class UserInfo
其次是核心的交互接口。
//interface
public interface LoginContract {
interface LoginView {
success(UserInfo userInfo);
failed(String errorMessage);
}
}
通过简单设计这一步,要定义出支持未来架构的核心的类、接口和数据模型。
5、小步安全重构
接下来是小步安全重构。
在重构的过程中,要最大限度运用五类遗留系统典型的代码坏味道的安全重构手法,减少人工直接修改代码的频率,尽可能做到小步提交,并借助测试进行频繁地验证,逐步将代码修改为新设计的架构模式。
这样既能提高重构的效率,通过自动化又能有效避免手工挪动代码带来的潜在错误。
在执行这个步骤中,有 3 个关键要点需要特别注意。
- 第一个是
小步,将整个重构分解为小的步骤,例如通过一次重构将业务逻辑移动到 Presenter 类或是将原有的 View 实现替换为接口回调的形式。每一次小的重构后可以通过版本管理工具进行保存,这样方便我们及时将代码进行回滚。 - 第二个是
频繁运行测试。每当有一次小的重构完成后都需要频繁执行测试,如果这个时候测试有异常,就证明我们的重构破坏了原有的功能,需要进行排查。通过这样的反馈,我们可以在更早期发现问题并及时处理。 - 第三个是
使用 IDE 的安全重构功能。使用自动化重构可以有效减少人为修改代码带来的风险,并且效率也会更高。这一步需要将所有的代码按照第四步中的设计,完成所有的代码重构,并且要保证编写的自动化验收测试全部运行通过。
6、补充中小型测试
当重构完成后,此时的代码可测性更高,是补充中小型测试的最佳时机。
通过补充用例可以固化重构后的代码逻辑,避免后续代码逻辑被破坏。
此外,中小型自动化测试的执行时间更快,更能提前反馈问题。
通常来说,在这一步要给重构后新增的类补充测试。还是以前面登录为例,重构后新增了一个 LoginPresenter 的类,那么就要对里面的 login 方法进行更细粒度的测试,覆盖方法内部更细的分支条件和异常条件。
就像后面代码演示的这样,要补充验证 username、password 的校验和模拟 Exception 的小型测试。
class LoginPresenter{
boolean boolean(String username,String password){
if(isValid(username)|| isValid(password)){
return false;
}
try{
XXX.login(username,password);
}catch(NetWorkException e)
{
//... ...
}
}
}
这一步可以借助测试覆盖率工具,来检查重构后代码的核心业务逻辑是否有覆盖测试。
当然这里我们不一定要求 100% 的覆盖率,具体要结合业务和代码来进行评估。
7、集成验收
是最后检查整个重构的结果,只有集成了才算是真的完成了重构。
这一步,不仅要保证重构后的代码独立编译调试通过,还要保证所有的自动化测试和集成验收测试也能运行通过。
通常来说,如果前面的 6 个步骤做到位,那么最后的集成阶段应该不会有太多的问题。
这也是经常说的“质量内建”,虽然前面增加了投入,但能有效减少后期的返工。
在实际的过程中,要注意避免出现长生命周期的重构分支,否则可能会在最后集成时出现大量的代码冲突。
此外,中大型的重构也应该合理拆分任务,让每一个小步的重构都能满足集成的条件。
如果过程质量做得好,其实我觉得更好的方式就是直接基于主干重构,避免拉长期的重构分支。
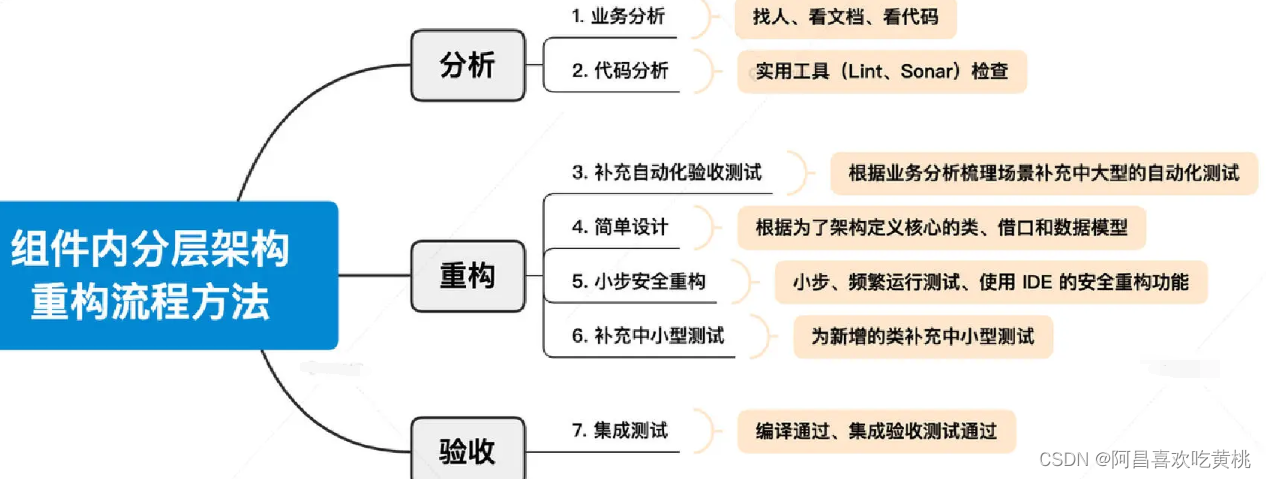
四、总结
重构的流程和关键的要点都总结到了下面这张图中。
-
分析阶段的两个步骤让以始为终,深入了解需求和代码现状;
-
重构阶段的四个步骤让能更加安全、高效地完成代码调整;
-
验收阶段则提醒我们,只有集成才是真正地完成了重构工作。
“Talk is cheap, show me the code”