ArrayList、LinkedList查找数据哪个快
这里有几种不同情况
1、是不是有序的?
2、说的查找是什么意思?是调用get(1),还是调用的contains(o)方法?
根据上面的问题,我们可以分开讨论:
1、数据是有序的
指定下标查询:
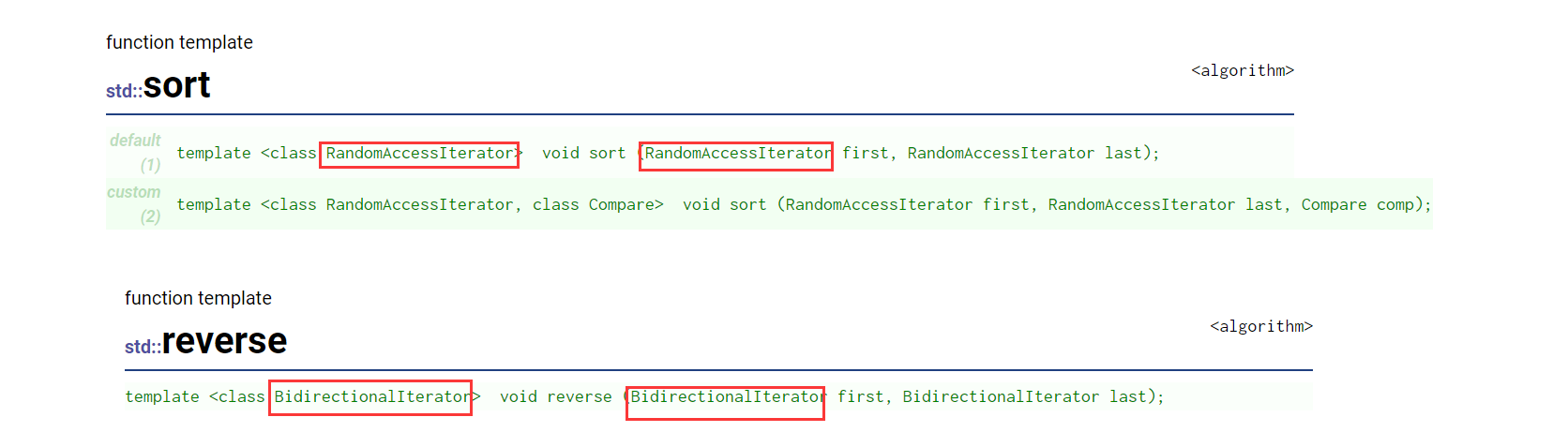
ArrayList 因为是基于数组实现,所以可以随机访问,时间复杂度是O(1);
LinkedList 因为是基于链表实现,所以只能从头到尾遍历,时间复杂度是O(n);
查找元素:
ArrayList 在有序的集合上,可以进行二分查找,时间复杂度是O(logn);
LinkedList 只能从头遍历,时间复杂度是O(n);
所以:ArrayList 比LinkedList 快
2、数据是无序的
指定下标查询:同上
查找元素:
ArrayList 因为无序,只能从头遍历查找,时间复杂度最坏是O(n);
LinkedList 只能从头遍历,时间复杂度最坏是O(n);
从理论上看是一样快,但是你可能忽略了一点,这也是我为什么写这篇博客的原因,我想这种级别的题目,面试官怎么还好意思问,可能并没有我想的这么简单。
猜测:数组中的元素在内存中是连续存储的,而链表中的元素是分散存储在内存中的,必须通过遍历链表来查找特定元素。
面试官是不是想让我回答这个?
于是我去测试了一下:
import java.util.ArrayList;
import java.util.LinkedList;
/**
* @author yangbin
* @since 2023-04-22
*/
public class SearchPerformanceTest {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
LinkedList<Integer> linkedList = new LinkedList<>();
// 将100000个随机整数添加到列表中
for (int i = 0; i < 100000; i++) {
int randomNum = (int) (Math.random() * 100000);
arrayList.add(randomNum);
linkedList.add(randomNum);
}
// 在ArrayList中查找一个存在的元素,并记录时间
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
arrayList.contains(50000);
}
long end = System.currentTimeMillis();
System.out.println("ArrayList 查找耗时:" + (end - start) + " 毫秒");
// 在LinkedList中查找一个存在的元素,并记录时间
start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
linkedList.contains(50000);
}
end = System.currentTimeMillis();
System.out.println("LinkedList 查找耗时:" + (end - start) + " 毫秒");
}
}
结果如下:
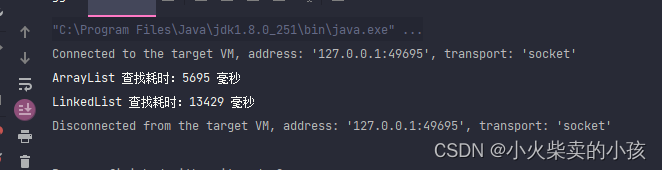
总结:相同时间复杂度的情况下,ArrayList仍然比LinkedList快1倍左右,主要有内存的存储结构的优势。
那为什么连续内存遍历就更快呢?为什么?为什么?
这是因为计算机在读取内存时,通常是按照连续的内存地址一块一块地读取数据的,这个过程被称为"连续访问"。这样可以利用计算机缓存(cache)的特性,提高内存读取速度。而对于分散存储在内存中的链表节点,由于它们的内存地址是不连续的,因此在查找特定元素时需要一个一个地遍历链表节点,这被称为"随机访问"。相比较而言,随机访问的速度较慢,因为每次查找都需要从内存中读取不同的数据块,而这些数据块可能不在缓存中,需要从主存中读取,从而导致了效率的下降。
而对于ArrayList来说,因为其中的元素是连续存储的,因此可以通过索引直接访问特定的元素,这被称为"顺序访问"。相比较而言,顺序访问比随机访问更快,因为在顺序访问的过程中,计算机可以预先将下一个数据块加载到缓存中,提高读取速度。
因此,当我们需要频繁地访问某些元素时,内存连续的ArrayList会更快,而当我们需要频繁地进行插入、删除等操作时,分散存储在内存中的LinkedList会更适合,因为它们在插入、删除操作时的性能较好。
连续访问为什么可以利用缓存(cache)的特性?为什么?为什么?
计算机中的缓存(cache)是一个小而快速的内存区域,用于存储最近访问的数据。当计算机需要读取内存中的数据时,它首先会检查缓存中是否已经存在这个数据,如果存在,则可以直接从缓存中读取,否则需要从内存中读取数据。由于缓存是比内存快的,因此从缓存中读取数据的速度比从内存中读取数据的速度快得多。
当计算机读取一块内存中的数据时,通常会一次读取多个连续的数据块并将它们存储在缓存中。这样,如果后续需要访问这些数据块,计算机可以直接从缓存中读取,而不需要再次从内存中读取。这就是连续访问的优势,因为连续访问的数据通常是存储在相邻的内存地址中的,计算机可以一次性读取多个数据块并将它们存储在缓存中,从而利用缓存的特性提高读取速度。
相比之下,随机访问的数据通常是分散存储在内存中的,因此计算机需要多次从内存中读取数据块,这会导致缓存中的数据被频繁替换,从而降低缓存的效率。这就是为什么连续访问比随机访问更能够利用缓存的特性的原因。
看到这里,你应该都明白了吧
再扩展一点
为什么计算机读取内存时是按数据块读取?不能只读我这个地址的数据吗? 这里有一个内存页概念:
在计算机中,内存通常被划分为许多固定大小的块,这些块被称为内存页(memory page),一般大小为4KB或8KB。当计算机读取内存中的数据时,它并不是按照单个地址读取数据,而是按照内存页的大小一块一块地读取数据。
这种按照内存页大小读取数据的方式是由计算机的硬件实现的,它有以下几个原因:
提高读取速度: 由于内存页是固定大小的,因此计算机可以预先将多个内存页加载到缓存中,这样可以提高内存读取速度,因为如果下一个需要读取的数据在缓存中已经存在,计算机就可以直接从缓存中读取,而不需要再次访问内存。
简化地址转换: 当计算机执行指令时,需要将逻辑地址(logical address)转换成物理地址(physical address),这个过程是由内存管理单元(memory management unit)完成的。按照内存页的方式读取数据可以简化地址转换的过程,因为内存页的大小是固定的,计算机可以直接将逻辑地址映射到物理地址。
提高内存利用率: 按照内存页的方式读取数据可以避免浪费内存空间。如果计算机只按照单个地址读取数据,那么一些内存页可能只有部分被使用,而其他部分则没有被使用,这会导致内存利用率的降低。
总之,按照内存页的方式读取数据可以提高读取速度、简化地址转换和提高内存利用率,这是计算机系统设计中的一项重要技术。