文章目录
- 1 实体与值对象
- 1.1 实体对象
- 1.1.1 唯一标识(Identity)
- 1.1.2 可变性
- 贫血模型
- 充血模型
- 1.2 值对象
- 1.3 示例(识别实体和值对象)
- 1)识别实体对象
- 2)提取值对象
- 3)挖掘实体的关键行为
- 4)识别其他值对象
- 5)识别结果
- 1.4 总结实体和值对象的区别
- 2. 领域服务
- 2.1 概念
- 2.2 示例(提取领域服务)
- 3. 领域事件
- 3.1 概述
- 3.2 领域事件生命周期
- 3.2.1 简单订阅者
- 3.2.2 即时转发订阅者
- 3.2.3 事件存储订阅者
- 3.3 领域事件建模
- 3.3.1 概述
- 3.3.2 示例
- 1) 事件的发布与订阅
- 2) 时序图
- 3)时序图(包含存储)
- 4 聚合(Aggregate)
- 4.1 聚合
- 4.1.1 概述
- 4.1.2 示例
- 4.1.3 聚合和领域服务
- 4.2 聚合建模
- 4.2.1 有缺陷的思路
- 4.2.2 聚合建模的原则
- 1)聚合内部真正的不变条件
- 2)设计小聚合
- 3)通过唯一标识引用其他聚合
- 4.2.3 正确的建模思路
- 5. 资源库(Repository)
- 6 集成界限上下文
- 6.1 4种主流的集成模式
- 6.2 上下文集成实现
- 6.2.1 概述
- 6.2.2 防腐层示例
- 6.2.3 消息传递模式
- 6.2.4 Core+Discussion上下文集成时序图
- 7. 应用程序
- 7.1 用户界面
- 7.2 应用服务
- 7.2.1 应用服务的定位
- 7.2.2 应用服务和领域服务的区别
- 7.3 3.基础设施
- 8 案例技术设计
- 8.1 上下文领域模型
- 8.1.1 Core核心域
- 8.1.2 Discussion支撑域
- 8.1.3 UserCenter通用域
- 8.2 上下文集成
1 实体与值对象
1.1 实体对象
在面向对象开发过程中,任何事物都是对象。在领域驱动设计中,我们关注的是实体(Entity)对象而非数据本身。
实体应该具有两个基本特征:唯一标识和可变性。
1.1.1 唯一标识(Identity)
通用的策略:
- 用户提供初始唯一值
处理方式依赖于用户通过界面输入,系统根据用户输入判断是否重复,如果重复则不允许创建实体。
- 系统内部自动生成唯一标识
该方法被广泛应用于各种需要生成唯一标识的场景。常见的是根据时间、IP、对象标识、随机数、加密等多种手段混合生成。
- 系统依赖持久化存储生成唯一标识
- 延时标识
- 尽早标识
延时标识示例:
延迟标识可以使用数据库中类似自增主键的功能

当我们构建Project实体对象时,该对象并不具备唯一性标识,该唯一性标识需要进行持久化之后才能获取。
尽早标识示例:
当实体对象生成的同时,该对象就已具备唯一性标识

- 来自另一个上下文。
该种方式尽管可行,但从实现复杂度上讲我们也不推荐。
1.1.2 可变性
贫血模型

- 优点
层次结构清楚,各层之间单向依赖,领域对象几乎只作传输介质之用,不会影响到层次的划分。 - 缺点
领域对象只是作为保存状态或者传递状态使用并不包含任何业务逻辑,只有数据没有行为的对象不是真正的领域对象,在应用层里面处理所有的业务逻辑,对于细粒度的逻辑处理,通过增加一层Facade达到门面包装的效果,应用层比较庞大,边界不易控制,内部的各个模块之间的依赖关系不易管理。这些都与面向领域驱动设计中子域和界限上下文的划分及集成思想相违背,所以我们推荐的是充血模型。
充血模型
充血模型更加适合较复杂业务逻辑的设计开发

- 优点
- 面向对象,应用层符合单一职责。(不像在贫血模型里面那样包含所有的业务逻辑而显得太过沉重。)
- 每一个领域模型对象一般都会具备自己的基础业务方法,满足充血模型的特征。
- 难点
如何划分业务逻辑。即如何把业务逻辑正确放在领域层和应用层中比较困难。
1.2 值对象
- 值对象特征:具备根据明确的约束条件,包括值对象是不变对象、值对象没有唯一标识、值对象具有较低的复杂性。
当我们把实体对象提取完毕,就需要进一步梳理实体中是否包含了潜在的值对象。
-
值对象提取:如下,我么可以认为是一个值对象:
- 一个对象满足自身是度量或描述领域中的一个部分
- 可以作为不变量
- 将不同的相关属性组合成一个概念整体
- 当度量或描述改变时可以用另一个值对象予以替换
- 可以和其他值对象进行相等性比较
- 不会对协作对象造成副作用等条件时
-
提取示例

我们发现:Customer对象中包含了客户的Address信息,而Address就是一个值对象,因为Address将Street、City、State等相关属性组合成一个概念整体;Address也可以作为不变量,当该Address改变时,可以用另一个Address值对象予以替换。
1.3 示例(识别实体和值对象)
说明:以UserCenter为例
1)识别实体对象
UserCenter上下文对User的通用语言包括:
- 必须对系统中的User进行认证
- User可以处理自己的个人信息,包含姓名、联系方式等
- User的安全密码等个人信息能被本人修改
如上可判断:User是一个实体对象而不是值对象
2)提取值对象
- User应该包含一个唯一标识 ===>
- User实体的唯一标识UserId可能只是一个数据库主键值或一个复杂的数据结构 ===>
- 我们将UserId提取成一个值对象。

3)挖掘实体的关键行为
考虑到用户可能离职等原因,User可以处于激活或锁定状态,对应的User实体应用具备激活(active)或锁定(deactive)相关的行为。

4)识别其他值对象
- User可以修改密码、姓名、联系方式等个人信息 ===》
- 我们可以从User中提取出
Person的概念
User实体中提取姓名、联系方式等信息,实际上构成了一个 Person 的概念,它是User的一部分。
- 虽然Person是一个实体,但联系方式(Contact Info)等信息倾向于分离成值对象

5)识别结果
通过以上分析我们得出:
- User和Person代表两个实体
- User中包含Person实现和UserId值对象
- Person中包含PersonId、Name和ContactInfo值对象
1.4 总结实体和值对象的区别
- 从标识的角度
- 实体有唯一标识
- 值对象没有唯一标识(不存在这个值对象或那个值对象的说法)
- 是否只读的角度
- 实体是可变的
- 值对象是只读的
- 从生命周期的角度
- 实体具有生命周期
- 值对象无生命周期可言(需要依附于某个具体实体)
2. 领域服务
2.1 概念
-
领域服务
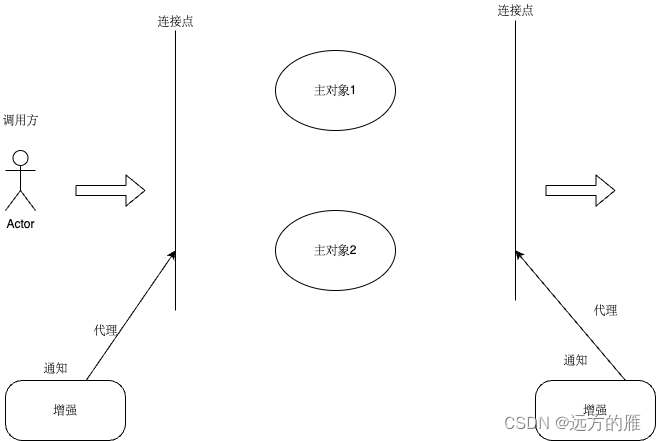
当领域中某个重要的过程或转换操作不属于实体或值对象的职责时,应该在模型中添加一个作为独立接口的操作,即领域服务。 -
与实体和值对象的区别
其执行的是一个显著的业务操作过程,并以多个领域对象作为输入进行计算,其结果往往产生一个值对象供应用层使用
示例:银行资金转账场景
考虑现实中银行资金转账场景,用户通过ATM(Automatic Teller Machine,自动取款机)输入银行账户和转账金额等转账相关基本信息,银行执行转账操作并发送手机短信。从架构分层上,应用层获取来自用户接口层的输入,发送消息给领域层并监听确认消息,根据操作结果决定是否使用基础设施层服务发送通知。如果需要发送通知,则基础设施层按照应用程序的指示发送手机短信。关键在于领域层需要执行资金转账操作。该服务需要与Account和Money等对象进行交互,执行相应地借入和贷出操作,并提供结果的确认。领域层中涉及多个领域对象协作的资金转账领域服务即是典型的领域服务。
2.2 示例(提取领域服务)
需求:UserCenter上下文中的User实体的一个需求是必须对用户密码进行加密,并且不能使用明文密码。
- 方案一(客户端加密)【不推荐】
- 操作:客户端处理密码的加密,然后将加密后的密码传给User
- 弊端:
- 客户端承载太多细节
- 不符合基本的安全设计原则
- 方案二(User内部加密)【不推荐】
- 操作:User内部使用加密算法进行加密
- 弊端:不符合单一原则(User对象只是代表一个用户信息,并不需要也不应该知道太多加密信息)
- 方案三 (提取领域服务)【推荐】
- 操作:将加密操作提取成领域服务,通过独立接口的方式暴露给领域对象使用
例如,我们可以抽象一个EncrytionService,然后采用MD5或其他加密算法实现该接口即可。
3. 领域事件
3.1 概述
- 领域事件:把领域中所发生的活动建模成一系列离散事件。
领域事件也是一种领域对象,是领域模型的组成部分。
- 领域事件生命周期
- 产生
- 存储
- 分发
- 使用
3.2 领域事件生命周期

领域事件框架围绕领域事件生命周期给出了3种不同的处理方式,
3种事件订阅者可以进行组合形成对事件存储、分发和使用的完整处理过程。
3.2.1 简单订阅者
简单订阅者直接处理事件,表现为一个独立的事件处理程序,对应于事件的使用阶段。
3.2.2 即时转发订阅者
- 对应于事件的分发和使用阶段
- 作用:
- 具备简单订阅者的功能
- 可以把事件转为给其他订阅者
把事件转发到消息队列,以满足远程订阅者的需求
3.2.3 事件存储订阅者
- 对应于事件的存储和使用阶段
- 作用:
- 在处理事件的同时对事件进行持久化(如历史记录)
- 通过专门的事件转发器转发到消息队列
3.3 领域事件建模
3.3.1 概述
- 作用:
事件的识别有时候具有一定的隐秘性,当一个实体依赖于另外一个实体,但两者之间并不希望产生强耦合而又需要保证两者之间的一致性时,我们通常就可以提取事件。
示例:我们可以根据通用语言识别Discussion实体。而为了避免Disscussin上下文和Core上下文之间产生强耦合,当一个Discussion结束时,该上下文需更新项目的评估,并通知相关兴趣方。这个过程中我们就可以提取DiscussionClosed事件。
- 领域事件命名:一般使用过去时对事件进行命名(如上述的DiscussionClosed事件)
- 领域事件内容
- 唯一标识
- 产生时间
- 事件来源
- 其他元数据、业务数据
- 领域事件特性
- 严格意义上的不变性(因为事件代表的是一种瞬时状态。)
- 对领域事件的处理:发布-订阅风格。
3.3.2 示例
1) 事件的发布与订阅
DomainEventPublisher和DomainEventSubscriber分别代表发布者和订阅者,DomainEvent本身具备一定的类型,DomainEventSubscriber根据类型订阅某种特定的DomainEvent

2) 时序图
发布订阅风格中涉及的领域对象及交互时序图

- 应用层Application Service对某个实体对象进行操作会触发领域事件的生成
- 领域事件通过Domain Event Publisher进行发布
- DomainEventSubscriber则根据需要由Application Service创建并根据事件类型进行订阅和处理。
3)时序图(包含存储)
包含事件存储的发布订阅时序图

领域事件既可以由本地界限上下文消费,也可以由远程的界限上下文消费。远程界限上下文发布领域事件需要考虑消息的最终一致性、同步和异步及领域事件存储等问题。尤其针对远程交互本身存在的网络稳定性等各种不可控原因,一般都会对事件进行存储以便发生问题时进行跟踪和重试。支持不同事件类型、支持领域事件和存储事件之间的转换、检索由领域模型所产生的所有结果的历史记录、使用事件存储中的数据进行业务预测和分析是常见的事件存储需求。事件可以通过Domain Event Publisher进行集中式的存储,也可以分别保存在各个Domain Event Subscriber中。通过Domain Event Subscriber构建Event Store进行事件存储。
4 聚合(Aggregate)
4.1 聚合
4.1.1 概述
-
聚合:一组相关对象的组合,是数据修改的最小单元。
也就是意味着对对象组合的修改只能通过聚合中的根实体进行,而不是对于组合中的所有实体都能进行直接修改。
-
聚合的核心思想:将关联减至最少,有助于简化对象之间的遍历,使用一个抽象来封装模型中的引用。
-
聚合的组成
- 根(Root)实体,是聚合中的某一个特定实体
- 描述一个边界,定义聚合内部都有什么
-
聚合固定规则
- 根实体具有全局标识
- 外部系统只能看到根实体
- 只有根实体才能直接通过数据进行查询获取,其他对象必须通过聚合内部关联的遍历才能找到
- 删除操作必须一次删除聚合之内的所有对象
4.1.2 示例
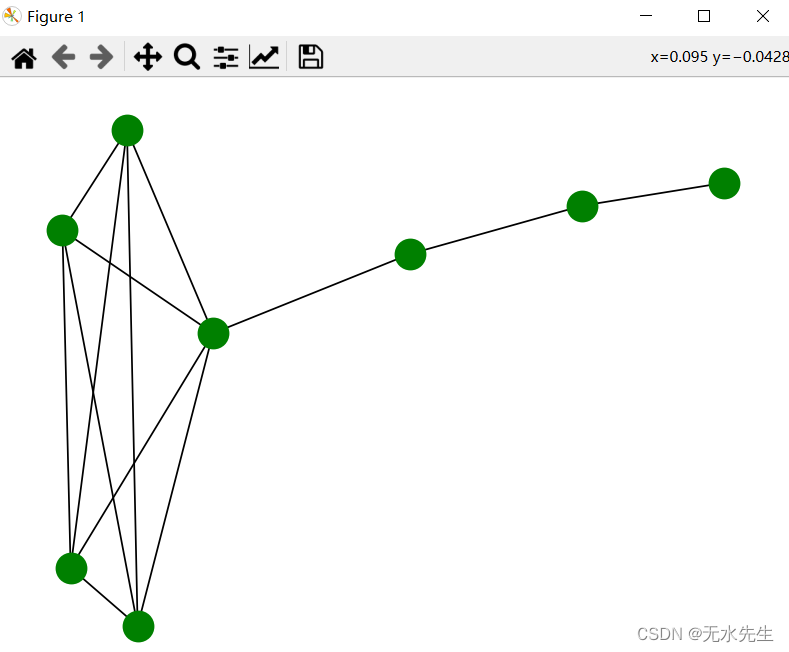
- 没有采用聚合概念的对象遍历图(图左半部分)
- 任何对象都能两两进行交互,所以对象都处于同一个边界中
- 采用聚合概念的对象遍历图(图右半部分)
- 通过聚合思想把系统划分成3个边界
- 每个边界里面包含一个聚合
- 与外部边界直接关联的就是聚合中的根对象
- 只有根对象之间才能进行直接交互,其他对象只能与该聚合中的根对象进行直接交互
通过聚合可以把最多28-1次对象直接交互减少的23-1次

4.1.3 聚合和领域服务
回顾领域服务,使用领域服务实际上就是执行跨聚合的操作,领域服务的输入对象即是各个聚合的根实体对象。
4.2 聚合建模
4.2.1 有缺陷的思路
- 思路一(基于聚合的建模)
- 把Project、Task、Plan归为实体对象
- 把Project上升到聚合的根对象
即:外部系统只能通过Project对象访问Plan和Task对象,而Project中包含着对Plan和Task的直接引用。

- 思路二(划分为三个聚合)
- Project、Plan、Task划分为3个不同的聚合。
- 把Project的唯一标识提取成一个值对象Project Id
- Project通过Project Id与Plan和Task对象进行关联

4.2.2 聚合建模的原则
1)聚合内部真正的不变条件
- 原则
业务规则应该总是保持一致,即在一个事务中只修改一个聚合实例如果一个事务内需要修改的所有内容处于不同聚合中,我们就要重新考虑聚合划分的有效性。聚合内部保持强一致性的同时,聚合之间需要保持最终一致性。
- 示例
思路二中,Project和Plan的更新处于同一个事务中(即,更新Project的同时也应该同时更新Plan),所以把Plan放到以Project为根实体的聚合中更加符合聚合建模的这一条原则。
2)设计小聚合
-
原则
倾向于使用小聚合 -
原因诠释
- 从性能角度讲
聚合内部复杂的对象管理和深层次的对象遍历会降低系统的性能 - 扩展性
- 系统的变化对于大粒度聚合的影响显然大于小聚合
- 考虑到实体具备生命周期和状态变化,聚合建模也推荐优先使用值对象以降低聚合内部复杂性。
- 从性能角度讲
3)通过唯一标识引用其他聚合
- 原则:
- 通过标识而非对象引用使多个聚合协同工作
- 聚合中的根实体应该具备唯一标识
- 示例
思路二中引入值对象Project Id作为Project的唯一标识,并通过该值对象与其他聚合中的根实体进行交互就是这条原则的具体体现。如果Task业务作为一个根实体的话,一般也会提取一个值对象Task Id作为其唯一标识。
4.2.3 正确的建模思路
综合运用3条聚合建模的原则之后,我们可以得到聚合建模思路三,这是我们对上述场景进行聚合建模的最终结果。

5. 资源库(Repository)
-
资源库
在领域驱动设计中,资源库实际上就是对象的提供方,能够实现对象的持久化 -
资源库的实现过程中有几个注意点:
- 每一个聚合类型对应一个资源库(因为对聚合的操作需要维持在一个事务中)。
- 获取聚合时,我们从聚合根实体开始导航对象以控制聚合界限。
- 充血模型对数据对象的要求:防止数据驱动、避免实体和值对象成为单纯的数据容器是。
- 通过资源库屏蔽数据访问的技术复杂性
-
领域驱动设计中引入资源库模式的目的:
- 为客户提供一个简单模型,可以获取持久化对象
- 使应用程序和领域设计与持久化技术解耦,体现有关对象访问的设计决策

- 资源库可以分成两个部分:
- 资源库的定义
- 表现为一个抽象接口
- 位于领域层
- 资源库的实现
- 依赖于具体的持久化媒介
- 位于基础设施层
- 资源库的定义
6 集成界限上下文
6.1 4种主流的集成模式

- 包括文件传输(File Transfer)
- 缺点:在于如何进行文件的更新和同步
- 共享数据库(Shared Database)
- 缺点:在于如何确保数据库模式统一
- 远程过程调用(RPC):
- 缺点:容易产生瓶颈节点
- 而消息传递
- 缺点:提供松耦合的同时也加大了系统的复杂性
6.2 上下文集成实现
6.2.1 概述
- 在面向领域的策略设计中,我们提到上下文集成的基本模式有两种:
- 防腐层
- 统一协议
- 统一协议模式(为系统所提供的服务)定义一套(包含标准化数据结构在内的)协议
- 开发该协议以使其他需要集成的系统能够使用,同时在有新的集成需求时对协议进行改进和扩展
- HTTP方法及所代表的资源就是一种统一协议
- RESTful风格的集成实现机制如下表:
| URL | HTTP方法 | 描述 |
|---|---|---|
| http://www.liubei.com/users | GET | 获取User对象列表 |
| http://www.liubei.com/users | PUT | 更新一组User对象 |
| http://www.liubei.com/users | POST | 新增一组User对象 |
| http://www.liubei.com/users | DELETE | 删除所有User对象 |
| http://www.liubei.com/users/guanyu | GET | 根据用户名guanyu获取User对象列表 |
| http://www.liubei.com/users/guanyu | PUT | 根据用户名guanyu更新User对象 |
| http://www.liubei.com/users/guanyu | POST | 添加用户名为guanyu的User对象 |
| http://www.liubei.com/users/guanyu | DELETE | 根据用户名guanyu删除User对象 |
6.2.2 防腐层示例
- 前提条件:
在案例的UserCenter上下文中,参加Discussion的用户需要通过UserCenter进行用户身份验证。这个过程就涉及二者的上下文之间的集成 - 集成方案
- 在UserCenter上下文中提供基于RESTful风格的UserResource
- Discussion上下文通过基本的HTTP请求就可以访问该UserResource以实现用户身份认证
- 两个上下文之间添加了一层包含UserAdapter和UserTranslator组件的防腐层(降低系统耦合)

6.2.3 消息传递模式
- 发布/订阅模式
- 点对点模式

6.2.4 Core+Discussion上下文集成时序图
- 需求:
Core上下文创建Project,而项目的时间计划由Discussion上下文计算得出
- 时序图

- 时序图说明:
- Core上下文可以通过创建ProjectCreated领域事件并通过消息传递系统进行发布。
- Discussion上下文订阅并处理该事件
- Discussion将项目的时间计划通过DiscussionFinished事件反向发送给Core上下文处理
7. 应用程序
7.1 用户界面
-
用户界面并不是领域驱动设计的重点
-
需要明确的问题
- 如何将领域对象渲染到用户界面中
- 如何将用户操作反映到领域模型上
-
用户界面与领域模型解耦模式
- 数据传输对象(DTO)模式
- 业务对象(Business Object)为传输对象填充数据的业务服务,相当于领域对象
- 传输对象(Transfer Object)也被称为数值对象,只有设置和获取属性的方法
- 客户端(Client)则可以发送请求或者发送传输对象到业务对象
- 门面(Façade)模式
- 为子系统中的一组接口提供一个一致的界面,使得子系统更加易用
- 实现上用户界面不与系统耦合,而外观类与系统耦合
- 在层次化结构中,可以使用Façade模式定义系统中每一层的入口
- 数据传输对象(DTO)模式

在领域驱动设计中,我们使用应用服务实现类似DTO和Façade的功能。
7.2 应用服务
7.2.1 应用服务的定位
- 是领域模型的直接客户
- 负责业务流程的协调
- 控制事务使用资源库并解耦服务输出

7.2.2 应用服务和领域服务的区别
应用服务通常不包含业务,表现为类似Façade的很薄的一个层次。
7.3 3.基础设施
- 资源库的定义属于领域模型的一部分
- 基础设施的一大功能就是提供各种资源库的实现
- 应用服务依赖于领域模型中的资源库定义,并使用基础设施中提供的资源库实现。
- 使用依赖注入完成资源库实现在应用服务中的动态注入

8 案例技术设计
8.1 上下文领域模型
8.1.1 Core核心域
-
其通用语言:
- 一个项目具有优先级
- 一个项目具有很多Task
- 项目的任务就是完成任务的分解及项目的计划
-
其上下文对应的领域模型如图

Project和Task两个聚合根实体是Core核心域中的主要领域模型,围绕着项目的创建、任务的分解和状态更新以及最终计划的制定系统生成相应的领域事件,而应用服务和资源库都与两个聚合采用通用的命名结构
8.1.2 Discussion支撑域
-
其通用语言包括
- 通过Discussion中的会议得出Plan
- 参加Discussion的成员必须是系统的合法成员
-
该上下文对应的领域模型如图

该支撑域中的主要实体就是Discussion,同时作为集成上下文中UserCenter的上游,Discussion支撑域采用防腐层策略进行集成解耦。
8.1.3 UserCenter通用域
-
其通用语言
- 提供服务供外部系统进行用户注册和认证
- 支持修改用户的联系方式、密码等基本信息
-
该上下文对应的领域模型如图

UserCenter通用域涉及User聚合根、Person实体及一系列表述实体属性的值对象。User的注册、修改密码和联系方式等操作都被抽象成领域事件,而User的验证、密码的修改因为涉及多个对象的交互被单独提取成领域服务。作为Discussion支撑域的下游,UserCenter通用域采用统一协议策略暴露User验证的入口
8.2 上下文集成
- 使用统一协议和防腐层集成模式实现3个上下文之间的集成
- 左半部分代表集成模式
- 右半部分是集成模式所对应的实现方案

采用上述集成模式和实现手段之后,3个上下文之间交互的时序图: