【00】结构原理

微服务中的监控分根据作用领域分为三大类,Logging,Tracing,Metrics。
*
Logging - 用于记录离散的事件。
例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。比如我们说的ELK就是基于Logging。
*
Metrics - 用于记录可聚合的数据。
例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累。prometheus专注于Metrics领域。
*
Tracing - 用于记录请求范围内的信息。
例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。最常用的有Skywalking,ping-point,zipkin。
Prometheus:
Prometheus(中文名:普罗米修斯)是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB). Prometheus使用Go语言开发, 是Google BorgMon监控系统的开源版本。
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态, 任意组件只要提供对应的HTTP接口就可以接入监控. 不需要任何SDK或者其他的集成过程。
输出被监控组件信息的HTTP接口被叫做exporter,
目前开发常用的组件大部分都有exporter可以直接使用, 比如Nginx、MySQL、Linux系统信息、Mongo、ES等
exporter:
prometheus可以理解为一个数据库+数据抓取工具, 工具从各处抓来统一的数据, 放入prometheus这一个时间序列数据库中. 那如何保证各处的数据格式是统一的呢?就是通过这个exporter.
Exporter是一类数据采集组件的总称. Exporter负责从目标处搜集数据, 并将其转化为Prometheus支持的格式, 它开放了一个http接口(以便Prometheus来抓取数据). 与传统的数据采集组件不同的是,
Exporter并不向中央服务器发送数据, 而是等待中央服务器(如Prometheus等)主动前来抓取(即连接方式是prometheus连接各个exporter)。
https://github.com/prometheus 有很多写好的exporter,可以直接下载使用。
Grafana:
Grafana是一个图形化工具, 它可以从很多种数据源(例如Prometheus)中读取数据信息, 使用很漂亮的图表来展示数据, 并且有很多开源的dashborad可以使用,可以快速地搭建起一个非常精美的监控平台。
它与Prometheus的关系就类似于Kibana与ElasticSearch。
Dashboards | Grafana Labs 是对应exporter匹配的监控模板,也可以直接导入使用[数据源选择prometheus然后模糊搜索rabbitmq等复制模板id10863]。
数据模型:
metric名字和标签集合确定一个唯一的时间序列:
metric_name [
"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"] value [ timestamp ]
一条完整的数据:
# HELP http_requests_total The total number of HTTP requests.
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027 1395066363000
http_requests_total{method="post",code="400"} 3 1395066363000
数据类型:
Counter
Counter用于累计值,例如记录请求次数、任务完成数、错误发生次数。一直增加,不会减少。重启进程后,会被重置。例如:http_response_total{method=”GET”,endpoint=”/api/tracks”} 100,10秒后抓取http_response_total{method=”GET”,endpoint=”/api/tracks”} 100。
Gauge
Gauge常规数值,例如 温度变化、内存使用变化。可变大,可变小。重启进程后,会被重置。例如: memory_usage_bytes{host=”master-01″} 100 < 抓取值、memory_usage_bytes{host=”master-01″} 30、memory_usage_bytes{host=”master-01″} 50、memory_usage_bytes{host=”master-01″} 80 < 抓取值。
Histogram
Histogram(直方图)可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供count和sum全部值的功能。例如:{小于10=5次,小于20=1次,小于30=2次},count=7次,sum=7次的求和值。
Summary
Summary和Histogram十分相似,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的功能。例如:count=7次,sum=7次的值求值。它提供一个quantiles的功能,可以按%比划分跟踪的结果。例如:quantile取值0.95,表示取采样值里面的95%数据。
【01】Prometheus
镜像:
docker pull prom/prometheus
配置文件:
注,后续需要链接的exporter都在这里配置。一些基本项:
global[全局配置]
alerting[告警配置]
rule_files[告警规则]
scrape_congigs[抓取数据源traget,每个traget用job_name命名,又分为静态配置和服务发现]
/root/prometheus/prometheus.yml:
global:
scrape_interval: 10s
evaluation_interval: 20s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['192.168.230.129:9090']
labels:
instance: prometheus
这里仅配置了抓取
prometheus自己状态[填写prometheus自己所在ip]的默认job_name。
容器:
#临时关闭selinux
setenforce 0
#启动容器
docker run -p 9090:9090 --name=prometheus --restart=always -v /root/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -d prom/prometheus
日志:

查看web:
http://192.168.230.129:9090/
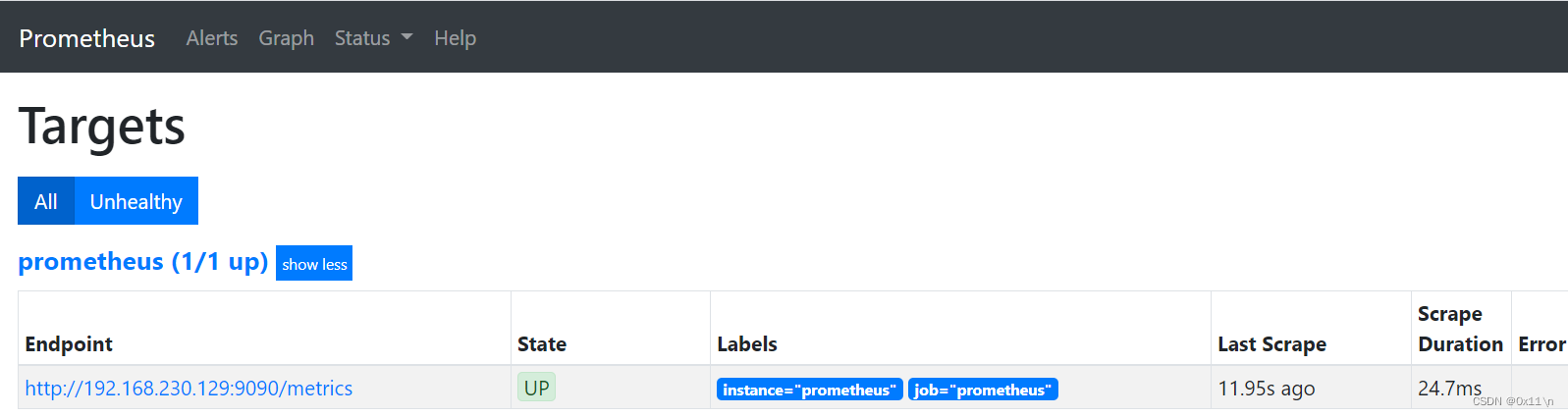
选择Status->Tragets查看抓取数据源:
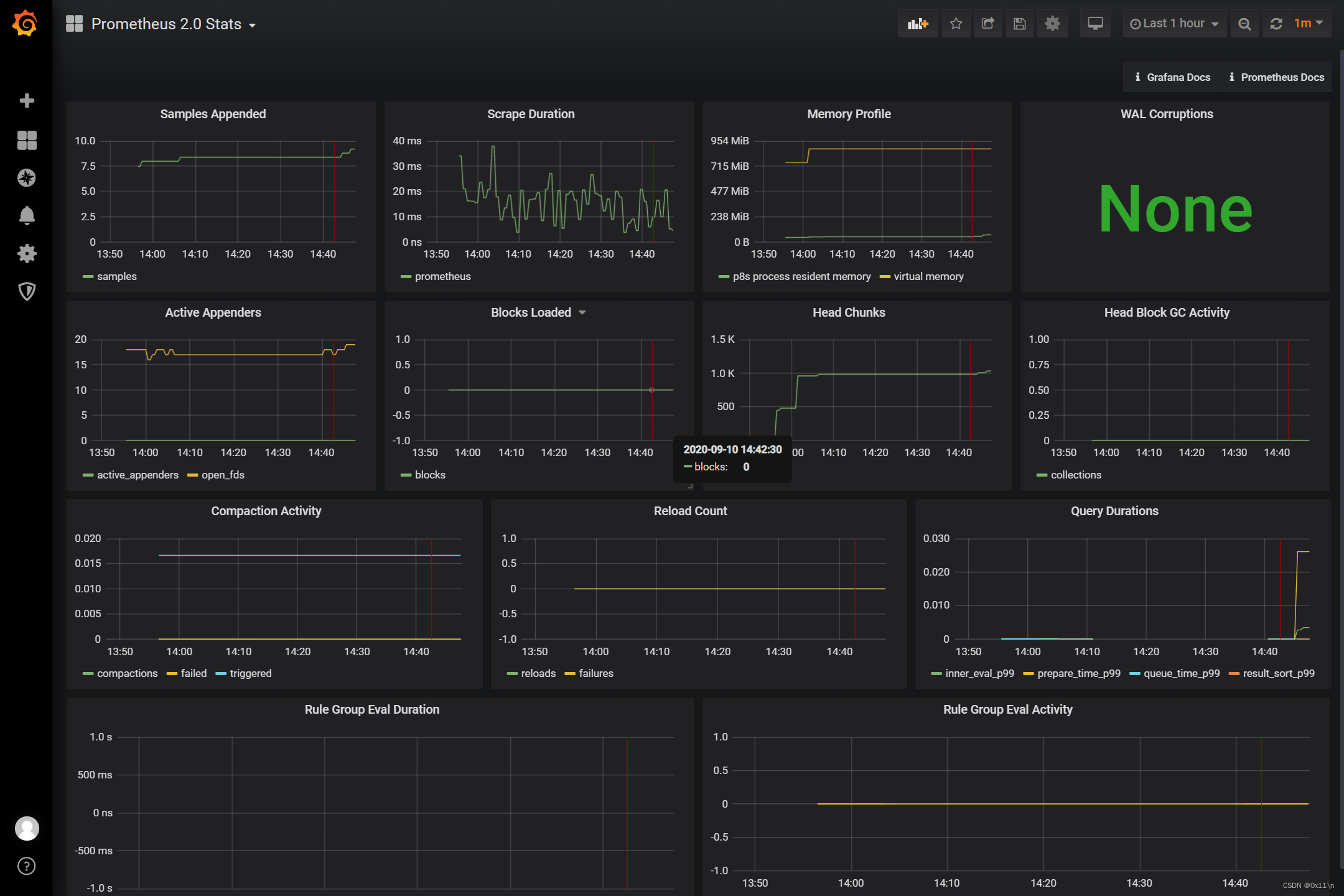
【02】Grafana
镜像:
GitHub - WangHL0927/grafana-chinese: grafana中文版本
一个可用的汉化版本,仅替换了前端资源。
docker pull w958660278/grafana-cn:latest-dev
容器:
docker run -d -p 3000:3000 --name=grafana w958660278/grafana-cn:latest-dev
前端:
http://192.168.230.129:3000/login
默认账户admin/admin,设置prometheus的地址即可。然后导入Prometheus Status仪表盘,就可以查看了。