1.基本概念
生成对抗网络Generative Adversarial Networks(GAN)包含生成模型(generative model)和判别模型 (discriminative model) 两个模型。生成模型的任务是生成和原始数据相似的实例,判别模型的任务是判断给定的实例是真实的还是伪造的。
训练过程中,生成器在生成逼真图像方面能力逐渐变强,而判别器在辨别这些图像的能力上逐渐变强。当判别器不再能够区分真实图片和伪造图片时,训练过程达到平衡。

如上图所示,生成器充当“艺术家”,生成许多看起来像真实的猫的图像。判别器充当”艺术评论家”,评判生成器生成的图像是否是真实的。

一开始生成器生成的图像和真实图像差距较大,因此判别器很容易判别出这是假的图像。随着训练次数的增加,生成器不断接收判别器的反馈来修改生成数据的分布,直到生成器生成的图像和真实图像的数据分布一致且判别器也判别不出来到底是真的数据还是假的数据,此时,训练过程达到一个平衡状态。这就是GAN“对抗生成”的基本理念。看起来还是比较好理解的是把!
我们再来看一个比较形象的例子:警察和罪犯
•罪犯的目标:想出伪造货币的方法,让警察无法区分假币和真币。
•警察的目标:想出辨别货币的方法,能够区分假币和真币。
随着这个过程不断继续,警察会想出越来越复杂的技术来鉴别假币,罪犯也会想出越来越复杂的技术来伪造货币。这就是 GAN 中“对抗过程”的基本理念。
GAN 充分利用“对抗过程”训练两个神经网络,这两个网络会互相博弈直至达到一种理想的平衡状态,警察和罪犯就相当于这两个神经网络。其中一个神经网络叫做生成器网络G(Z), 使用输入随机噪声数据生成和已有数据集非常接近的数据;另一个神经网络叫鉴别器网络D(X), 以生成的数据作为输入,尝试鉴别出哪些是生成的数据,哪些是真实数据。鉴别器的核心是实现二元分类,输出的结果是输入数据来自真实数据集和合成数据的概率。
2.学习路线

本博客首先介绍了GAN的理论基础,在后续的博客中会分为几个阶段分别向大家介绍关于GAN的内容包括方法改进和场景应用,敬请期待!

判别方法学习得到的是一个判断数据是否属于某一类的模型,而生成方法则学习到数据的分布。


判别器训练
1.对生成器输入一段噪音,输出一个符合某一分布的假数据(如一组图片的分布);
2.从生成的分布中抽取一些数据,标记为0,从真实样本集中抽取一些数据,标记为1;
3.将数据喂给判别器进行训练,使判别器能够很好的分辨数据的真伪,判别器训练完成。
生成器训练
4.将生成器与判别器进行逻辑连接,生成器产生的假数据全部标记为1喂给判别器;
5.喂给网络的数据产生的误差,通过误差反向传播算法传递给训练器,修正生成器的参数(此处为GAN算法精妙之处,生成器与判别器是逻辑相连,误差仅仅修正生成器而不改变判别器的参数)
6.不断训练判别器和生成器,直到判别器无法分辨假数据和真实数据,即判别器输出结果的概率都是0.5。
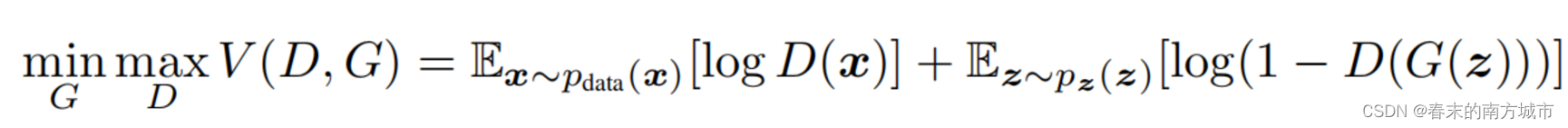
判别器输入真实数据,输出越大越好;生成器输入假数据时,输出越小越好。


训练K次判别器,训练1次生成器。训练期间最大化判别器价值函数,最小化生成器损失函数。对价值函数
3.实验效果

4.总结分析
优势:
1.只需用反向传播和梯度下降方式进行训练
2.不需要用前像素预测后像素,直接从端到端的以神经网络的方式来进行预测
3.生成器的训练是间接通过判别器的训练来进行的,有效防止了过拟合
4.GAN可以表示非常尖锐甚至恶化,退化的分布
劣势:
1.不能得到原始数据的真实分布
2.判别器和生成器必须同时训练,否则会导致模式崩溃(模型学习到真实样本的分布一部分,导致模型生成的样本非常单一,样本差异较小。)
5.未来展望
关于GAN的几个研究方向:
1.条件GAN:CGAN 告诉模型要生成什么样的类别,而不是通过判别器的训练来间接拟合噪声数据的分布。
2.预测输入图像的噪音,了解噪音具体代表的意义。比如头发颜色,眼睛大小等-StyleGAN
3.图像填充(Image inpainting)和超分辨率(Super resolution)
4.在标注比较少的情况下,可以利用判别器的特征来辅助分类
5.改进GAN的训练方式(损失函数,训练技巧,优化器,交替训练的方式)