目录
- 今日已完成任务列表
- 遇到的问题及解决方案
- 任务完成详细笔记
- 高性能算法
- 计算机算法的特征及内涵
- 科学计算算法的主要分类
- 高性能算法与传统算法的异同
- 稀疏矩阵向量乘法 SpMV 与稀疏矩阵存储结构
- 常见的稀疏矩阵传统存储与其SpMV算法
- 不同的稀疏矩阵传统存储结构存储效率与稀疏度
- 针对 SpMV 的矩阵存储优化格式-CSR-CIMD
- 高性能数学算法库的概念
- BLAS/LAPACK 的使用
- PETSc 的使用
- 对自己的表现是否满意
- 简述下次计划
- 其他反馈
今日已完成任务列表
4-3、高性能算法
遇到的问题及解决方案
PETSc的安装
主要参考:link
安装步骤:
这里假设在 ~/trainees/username 目录下操作,命令前没有写路径的表示没有路径要求 (应该)
- 拷贝安装包到用户目录
cp ~/software/petsc-3.18.1.tar ~/trainees/username
- 对安装包进行解压
trainees/username$: tar -xf petsc-3.18.1.tar
- 下载 petsc-pkg-fblaslapack.zip 包并上传 (download)
这里可以将其下载到本机,之后使用 mobaxterm 上传到 /username 文件夹下
- 对 petsc-pkg-fblaslapack.zip 包进行解压
trainees/username$: unzip petsc-pkg-fblaslapack.zip
- 移动 petsc-pkg-fblaslapack 到 petsc-3.18.1 下
mv ~/trainees/username/petsc-pkg-fblaslapack ~/trainees/username/petsc-3.18.1
- 获取 MPI
module avail | grep mpi-n
module load mpich/mpi-n-gcc9.3.0
- 查看 mpi 的路径
which mpif90
/thfs1/software/mpich/mpi-n-gcc9.3.0/bin/mpif90
- 对一些基本变量进行设置
trainees/username/petsc-3.18.1$: export PETSC_DIR=$PWD
trainees/username/petsc-3.18.1$: mkdir arch-linux-c-debug # 这里的文件夹命名随意, 自己记得就行
trainees/username/petsc-3.18.1$: export PETSC_ARCH=arch-linux-c-debug
- 对安装进行配置
trainees/username/petsc-3.18.1$: ./configure --prefix=~/trainees/username/petscinstall --with-mpi-dir=/thfs1/software/mpich/mpi-n-gcc9.3.0/ --download-fblaslapack=petsc-pkg-fblaslapack
其中 --prefix 指定将来安装的路径,按要求设置为 ~/trainees/username/petscinstall
- 安装
trainees/username/petsc-3.18.1$: make PETSC_DIR=~/trainees/username/petsc-3.18.1 PETSC_ARCH=arch-linux-c-debug all
完成之后执行
trainees/username/petsc-3.18.1$: make PETSC_DIR=~/trainees/username/petsc-3.18.1 PETSC_ARCH=arch-linux-c-debug install
之后就会发现 /username/petscinstall 文件夹下有 include、lib了
- 拷贝 ex1.c 到用户目录
cp ~/trainees/username/petsc-3.18.1/src/ksp/ksp/tutorials/ex1.c ~/trainees/username
- 将 lib 加到系统环境变量
export LD_LIBRARY_PATH=~/trainees/username/petscinstall/lib
- 动态编译 ex1
trainees/username$: mpicc -o ex1 ex1.c -I ~/trainees/username/petscinstall/include -L ~/trainees/username/petscinstall/lib -l petsc
- 使用天河运行
trainees/username$: yhrun -n 1 -N 1 -p thcp1 ./ex1
任务完成详细笔记
高性能算法
计算机算法的特征及内涵
计算机算法包含:[输入]、计算、输出三部分,可以没有输入
计算机算法五大特征:
- 有穷性:一个算法必须是执行有限步之后结束
- 确切性:每一步都有确切的意义
- 可行性:算法中的所有操作都可以通过已经实现的基本操作运算执行有限次来实现
- 输入:一个或零个输入,刻画运行时对象的基本信息
- 输出:一个算法有一个或多个输出,没有输出的算法没有意义
科学计算算法的主要分类
计算机应用算法分类:
- 稠密线性系统:BLAS,GEMM
- 稀疏线性系统:SPMV,HPCG
- 谱方法:FFT
- 多体方法:快速多极子算法
- 结构化网络:速度快,精度高
- 非结构化网络:适应复杂模型
- MapReduce:MC (Monte Carlo)
- 组合逻辑:AES、DES等加密算法
- 图遍历:Graph500,搜索算法
- 动态规划
- 分支限界
- 图模型
- 有限状态机
计算原语:逻辑运算
高性能算法与传统算法的异同
程序 = 数据结构 + 算法
高性能程序 = 数据结构 + 算法 + 体系结构
- 传统概念上程序只需关注基本的数据结构及算法流程,只是我们默认有支撑程序运行的软硬件环境
- 高性能程序需要关注与体系架构相适应的数据结构,与体系架构相适应的高效算法
- 并且需要兼顾多体系结构平台的可移植性与高效性
稀疏矩阵向量乘法 SpMV 与稀疏矩阵存储结构

稀疏矩阵:矩阵中,大量的元素值是 0 的矩阵,30% 甚至更多的 0 元素
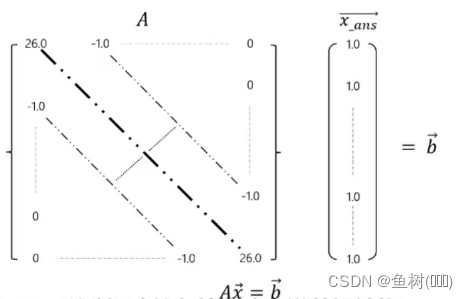
SpMV算法:
for(i=0; i<m; i++)
{
for(j=row[i]; j<row[i+1]; j++)
{
y[i] += data[j]*x[col[j]];
}
}
稀疏矩阵的存储方法:压缩存储
- 存储矩阵的一般方法是采用二维数组,其优点是可以随机地访问每一个元素,因而能够容易实现矩阵的各种运算
- 但对于稀疏矩阵,通常具有很大的维度,有时候甚至大到整个矩阵 (零元素) 占用了绝大部分内存,采用二维数组的存储方法既浪费大量的存储单元来存放零元素,有要在运算中浪费大量的时间来进行零元素的无效运算。因此对稀疏矩阵进行压缩存储 (只存储非零元素)
常见的稀疏矩阵传统存储与其SpMV算法
COO (Coordinate Matrix) 坐标存储格式
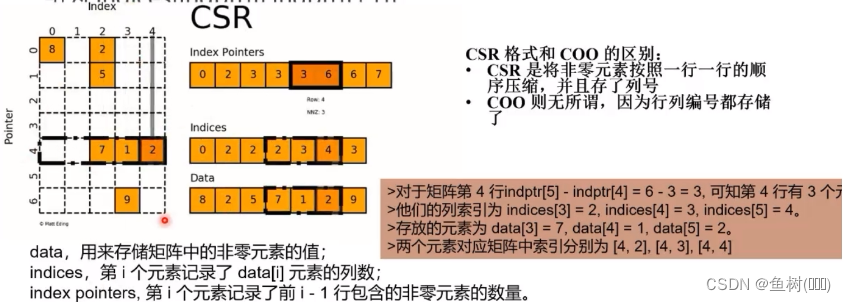
CSR (Compressed Spare Row Matrix) 压缩稀疏行格式
CSC (Compressed Sparse Column Matrix) 压缩稀疏列矩阵
BSR (Block Spare Row Matrix) 分块压缩稀疏行格式
DIA (Diagonla Matrix) 对角存储格式
- 稀疏矩阵的COO格式
采用三元组 (row,col,data) 的形式来存储矩阵中非零元素的信息,三个数组row、col和data分别保存非零元素的行下标、列下标与值 (一般长度相同),故 coo[row[k]][col[k]] = data[k],即矩阵的第row[k] 行、第 col[k] 列的值为 data[k]
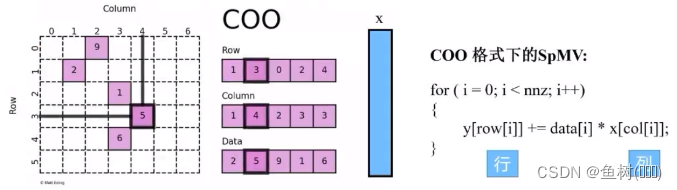
- CSR 存储格式
csr_matrix 是按行对矩阵进行压缩的,通过 inidices,indptr,data 来确定矩阵。data 表示矩阵中的非零数据,对于第 i 行而言,该行中非零元素的列索引为 indices[indptr[i]:indices[i+1]]
- DIA 存储格式
最适合对角矩阵的存储方式,dia_matrix通过两个数组确定:data 和 offsets,data:对角线元素的值,offsets:第 i 个 offsets 是当前第 i 个对角线和主对角线的距离,data[k:] 存储了 offsets[k] 对应的对角线的全部元素

不同的稀疏矩阵传统存储结构存储效率与稀疏度

通常情况下 CSR 存储效率较高

针对 SpMV 的矩阵存储优化格式-CSR-CIMD
SpMV 优化的重点在于改良稀疏矩阵的存储结构,提升稀疏矩阵向量乘时的 Cache 命中率,并充分利用 CPU 内部硬件特性,或者多核平台来改善效率
- 改良稀疏矩阵的存储结构,提升 Cache 命中率
提出新的稀疏矩阵存储格式
自动选择最优存储方式 - 充分利用CPU内部硬件特性
向量化技术(SIMD)
流水线技术(Pipeline)
预取技术(Prefetch) - 多核平台来改善效率
启发式搜索最优划分块大小
多线程下自动给出划分块大小
SpMV 优化举例:CSR 存储格式下的优化 —— CSR-SIMD
该存储格式在 CSR 的基础上,将非零元进一步压缩为可变长的具有来连续地址的非零元段,以段的方式对矩阵进行存储。通过这种方式,CSR-SIMD 中的每个非零元段都可以进行完全的向量化计算,同时增强了稀疏矩阵 A 以及向量 x 的数据局部性,以此达到性能加速效果
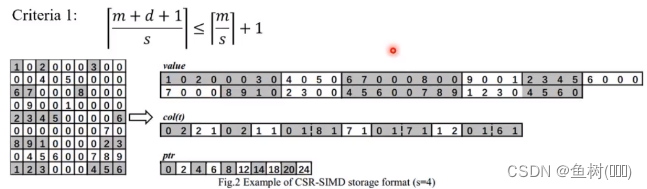
按照上图中的方式,每段包含4个元素,每次计算 4 个元素,理论上可以将性能提高 4 倍
高性能数学算法库的概念
算法库:是计算领域的基础软件库,是发挥硬件算力的基石
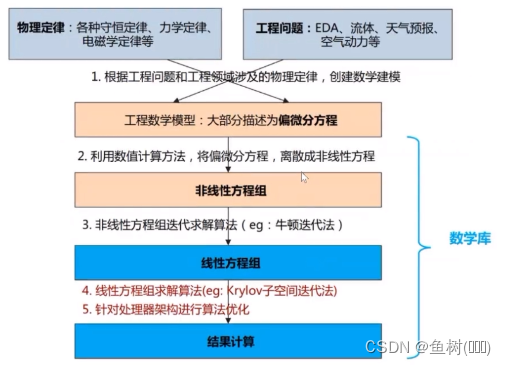
主流硬件厂商会为自身硬件提供优化的算法库
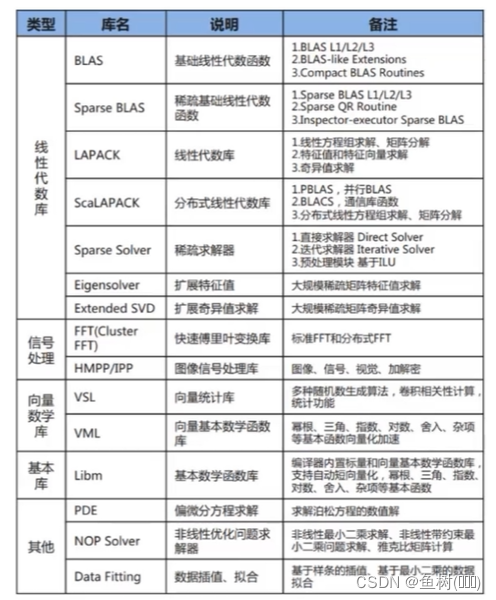
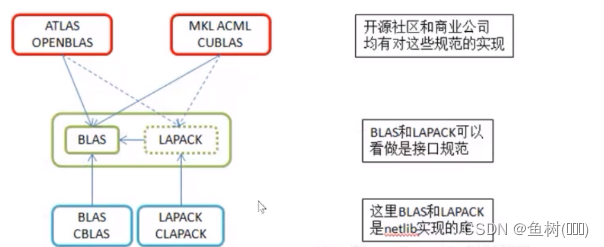
BLAS/LAPACK 的使用
BLAS (Basic Linear Algebra Subprograms) 基础线性代数子程序。定义了一组应用接口标准,是一系列初级操作的规范,如向量之间的乘法、矩阵之间的乘法等
Level1:矢量-矢量运算:矢量/向量加
- cblas_scopy、cblas_sscal
Level2:矩阵-矢量运算:矩阵向量乘
- cblas_sgemv
Level3:矩阵-矩阵运算:矩阵矩阵乘
- cblas_sgemm
LAPACK (linear algebra package) 著名的线性代数库。底层是 BLAS ,在此基础上定义了很多矩阵和高级向量高级运算的函数,如矩阵分解、求逆和求奇异值等,该库运行效率高于 BLAS
静态库:libxxxx.a
编译时库里面的代码会被编译进可执行程序里面
动态库:libxxxx.so
编译时只链接库文件中的程序接口,只有在真正运行时才会调用库中的接口
静态库文件大小大于动态库文件
静态库编译出的可执行文件无法在各平台间进行移植
动态库在编译之前要确保将其路径加到系统环境变量 LD_LIBRAY_PATH 里
填空练习
假设/home/blas/include下包含blas库的头文件,/home/blas/lib下包含blas的静态库文件libblas.so,对于一个用fortran语言编写的使用了blas接口的源程序mycode.f90,则编译命令为:
gfortran –O2 mycode.f90 -o mycode -I /home/blas/include -L /home/blas/lib -l blas
PETSc 的使用
PETSC
- PETSc (Protable, Extensible Toolkit for Scientific Computation),主要用于高性能求解偏微分方程组及相关问题。目前 PETSc 所有消息传递均采用 MPI (集群间分布式并行通信) 标准实现
- PETSc 用 c 语言开发,遵循面向对象设计的基本特征,用户可以基于 PETSc 对象灵活开发应用程序。目前 PETSc 支持 Fortran 77/90、C 和 C++编写的串行和并行代码


PC (预处理)
为什么需要预处理?
1、如果 A 的性质不那么好,是病态的,或者主对角线上的元素很小,或者特征值很小,那么收敛起来就会非常慢
2、将一个矩阵经过预处理后划分为多个类似结构的矩阵,实现天生并行化
PETSc 基本对象
- 向量
- 矩阵
- 索引集
PETSc并行原理
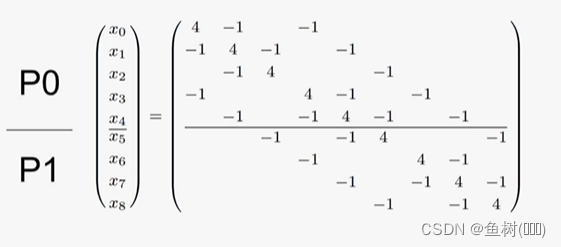
基于块划分的方式,例如:如果有两个进程,会把一个向量的上半部分划给 P0,下半部分划给 P1,同样将矩阵的上半部分划给 P0,下半部分划给 P1,中间需要进行信息交换处会由 PETSc 自动进行管理。
对自己的表现是否满意
今天对高性能计算有了初步的了解,同时了解到了几种矩阵的存储格式,花了大量时间安装 PETSc,最后终于弄好 〒▽〒
简述下次计划
程序性能分析、传统性能优化
其他反馈
无