5.1、阻塞/非阻塞、同步/异步(网络IO)
- 1.阻塞/非阻塞、同步/异步(网络IO)
- ①典型的一次IO的两个阶段是什么?
- 2.日志系统
- ①基础知识
- ②整体概述
- ③本文内容
- ④单例模式
- 1.经典的线程安全懒汉模式
- 2.局部静态变量之线程安全懒汉模式
- ⑤饿汉模式
- ⑥条件变量与生产者-消费者模型
- 1.生产者-消费者模型
- 2.自定义队列
- ⑦基础API
- 1.fputs
- 2.可变参数宏__VA_ARGS__
- 3.fflush
- ⑧日志系统
- 1.流程图
- 2.代码实现
- .h头文件
- .cpp文件
1.阻塞/非阻塞、同步/异步(网络IO)
①典型的一次IO的两个阶段是什么?
- 数据就绪:根据系统
IO操作的就绪状态- 阻塞
- 非阻塞
- 数据读写:根据应用程序和内核的交互方式
- 同步
- 异步
- 陈硕:在处理
IO的时候,阻塞和非阻塞都是同步IO,只有使用了特殊的API才是异步IO。
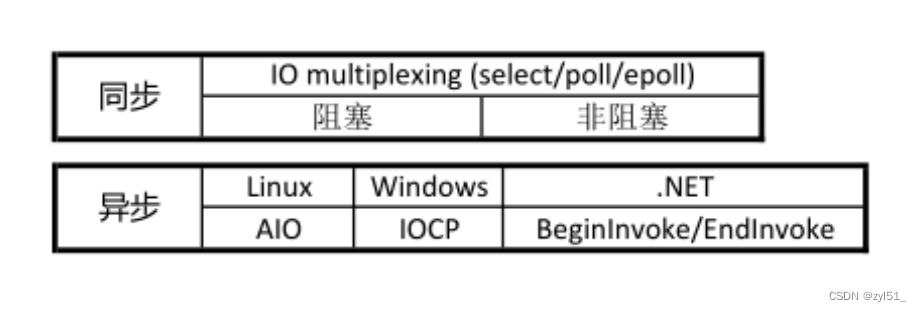
一个典型的网络
IO接口调用,分为两个阶段,分别是“数据就绪” 和 “数据读写”,数据就绪阶段分为阻塞和非阻塞,表现得结果就是,阻塞当前线程或是直接返回。
同步表示A向B请求调用一个网络IO接口时(或者调用某个业务逻辑API接口时),数据的读写都是由请求方A自己来完成的(不管是阻塞还是非阻塞);异步表示A向B请求调用一个网络IO接口时(或者调用某个业务逻辑API接口时),向B传入请求的事件以及事件发生时通知的方式,A就可以处理其它逻辑了,当B监听到事件处理完成后,会用事先约定好的通知方式,通知A处理结果。
- 同步阻塞
- 同步非阻塞
- 异步阻塞
- 异步非阻塞

2.日志系统
①基础知识
-
日志,由服务器自动创建,并记录运行状态,错误信息,访问数据的文件。 -
同步日志,日志写入函数与工作线程串行执行,由于涉及到I/O操作,当单条日志比较大的时候,同步模式会阻塞整个处理流程,服务器所能处理的并发能力将有所下降,尤其是在峰值的时候,写日志可能成为系统的瓶颈。 -
生产者-消费者模型,并发编程中的经典模型。以多线程为例,为了实现线程间数据同步,生产者线程与消费者线程共享一个缓冲区,其中生产者线程往缓冲区中push消息,消费者线程从缓冲区中pop消息。 -
阻塞队列,将生产者-消费者模型进行封装,使用循环数组实现队列,作为两者共享的缓冲区。 -
异步日志,将所写的日志内容先存入阻塞队列,写线程从阻塞队列中取出内容,写入日志。 -
单例模式,最简单也是被问到最多的设计模式之一,保证一个类只创建一个实例,同时提供全局访问的方法。
②整体概述
本项目中,使用单例模式创建日志系统,对服务器运行状态、错误信息和访问数据进行记录,该系统可以实现按天分类,超行分类功能,可以根据实际情况分别使用同步和异步写入两种方式。
其中异步写入方式,将生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的内容push进队列,写线程从队列中取出内容,写入日志文件。
日志系统大致可以分成两部分,其一是单例模式与阻塞队列的定义,其二是日志类的定义与使用。
③本文内容
本篇将介绍单例模式与阻塞队列的定义,具体的涉及到单例模式、生产者-消费者模型,阻塞队列的代码实现。
单例模式,描述懒汉与饿汉两种单例模式,并结合线程安全进行讨论。
生产者-消费者模型,描述条件变量,基于该同步机制实现简单的生产者-消费者模型。
代码实现,结合代码对阻塞队列的设计进行详解。
④单例模式
单例模式作为最常用的设计模式之一,保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。
实现思路:私有化它的构造函数,以防止外界创建单例类的对象;使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法获取该实例。
单例模式有两种实现方法,分别是懒汉和饿汉模式。顾名思义,懒汉模式,即非常懒,不用的时候不去初始化,所以在第一次被使用时才进行初始化;饿汉模式,即迫不及待,在程序运行时立即初始化。
1.经典的线程安全懒汉模式
class single{
private:
//私有静态指针变量指向唯一实例
static single *p;
//静态锁,是由于静态函数只能访问静态成员
static pthread_mutex_t lock;
//私有化构造函数
single(){
pthread_mutex_init(&lock, NULL);
}
~single(){}
public:
//公有静态方法获取实例
static single* getinstance();
};
pthread_mutex_t single::lock;
single* single::p = NULL;
single* single::getinstance(){
if (NULL == p){
pthread_mutex_lock(&lock);
if (NULL == p){
p = new single;
}
pthread_mutex_unlock(&lock);
}
return p;
}
2.局部静态变量之线程安全懒汉模式
- 前面的双检测锁模式,写起来不太优雅,《Effective C++》(Item 04)中的提出另一种更优雅的单例模式实现,使用函数内的局部静态对象,这种方法不用加锁和解锁操作。
class single{
private:
single(){}
~single(){}
public:
static single* getinstance();
};
single* single::getinstance(){
static single obj;
return &obj;
}
⑤饿汉模式
- 饿汉模式不需要用锁,就可以实现线程安全。原因在于,在程序运行时就定义了对象,并对其初始化。之后,不管哪个线程调用成员函数
getinstance(),都只不过是返回一个对象的指针而已。所以是线程安全的,不需要在获取实例的成员函数中加锁。
class single{
private:
static single* p;
single(){}
~single(){}
public:
static single* getinstance();
};
single* single::p = new single();
single* single::getinstance(){
return p;
}
//测试方法
int main(){
single *p1 = single::getinstance();
single *p2 = single::getinstance();
if (p1 == p2)
cout << "same" << endl;
system("pause");
return 0;
}
⑥条件变量与生产者-消费者模型
1.生产者-消费者模型
- 生产者和消费者是互斥关系,两者对缓冲区访问互斥,同时生产者和消费者又是一个相互协作与同步的关系,只有生产者生产之后,消费者才能消费。
#include <pthread.h>
struct msg {
struct msg *m_next;
/* value...*/
};
struct msg* workq;
pthread_cond_t qready = PTHREAD_COND_INITIALIZER;
pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;
void
process_msg() {
struct msg* mp;
for (;;) {
pthread_mutex_lock(&qlock);
//这里需要用while,而不是if
while (workq == NULL) {
pthread_cond_wait(&qread, &qlock);
}
mq = workq;
workq = mp->m_next;
pthread_mutex_unlock(&qlock);
/* now process the message mp */
}
}
void
enqueue_msg(struct msg* mp) {
pthread_mutex_lock(&qlock);
mp->m_next = workq;
workq = mp;
pthread_mutex_unlock(&qlock);
/** 此时另外一个线程在signal之前,执行了process_msg,刚好把mp元素拿走*/
pthread_cond_signal(&qready);
/** 此时执行signal, 在pthread_cond_wait等待的线程被唤醒,
但是mp元素已经被另外一个线程拿走,所以,workq还是NULL ,因此需要继续等待*/
}
2.自定义队列
-
当队列为空时,从队列中获取元素的线程将会被挂起;当队列是满时,往队列里添加元素的线程将会挂起。
-
阻塞队列类中,有些代码比较简单,这里仅对
push和pop成员进行详解。
class block_queue
{
public:
//初始化私有成员
block_queue(int max_size = 1000)
{
if (max_size <= 0)
{
exit(-1);
}
//构造函数创建循环数组
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
//创建互斥锁和条件变量
m_mutex = new pthread_mutex_t;
m_cond = new pthread_cond_t;
pthread_mutex_init(m_mutex, NULL);
pthread_cond_init(m_cond, NULL);
}
//往队列添加元素,需要将所有使用队列的线程先唤醒
//当有元素push进队列,相当于生产者生产了一个元素
//若当前没有线程等待条件变量,则唤醒无意义
bool push(const T &item)
{
pthread_mutex_lock(m_mutex);
if (m_size >= m_max_size)
{
pthread_cond_broadcast(m_cond);
pthread_mutex_unlock(m_mutex);
return false;
}
//将新增数据放在循环数组的对应位置
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
pthread_cond_broadcast(m_cond);
pthread_mutex_unlock(m_mutex);
return true;
}
//pop时,如果当前队列没有元素,将会等待条件变量
bool pop(T &item)
{
pthread_mutex_lock(m_mutex);
//多个消费者的时候,这里要是用while而不是if
while (m_size <= 0)
{
//当重新抢到互斥锁,pthread_cond_wait返回为0
if (0 != pthread_cond_wait(m_cond, m_mutex))
{
pthread_mutex_unlock(m_mutex);
return false;
}
}
//取出队列首的元素,这里需要理解一下,使用循环数组模拟的队列
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
pthread_mutex_unlock(m_mutex);
return true;
}
//增加了超时处理,在项目中没有使用到
//在pthread_cond_wait基础上增加了等待的时间,只指定时间内能抢到互斥锁即可
//其他逻辑不变
bool pop(T &item, int ms_timeout)
{
struct timespec t = {0, 0};
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
pthread_mutex_lock(m_mutex);
if (m_size <= 0)
{
t.tv_sec = now.tv_sec + ms_timeout / 1000;
t.tv_nsec = (ms_timeout % 1000) * 1000;
if (0 != pthread_cond_timedwait(m_cond, m_mutex, &t))
{
pthread_mutex_unlock(m_mutex);
return false;
}
}
if (m_size <= 0)
{
pthread_mutex_unlock(m_mutex);
return false;
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
pthread_mutex_unlock(m_mutex);
return true;
}
};
⑦基础API
1.fputs
#include <stdio.h>
int fputs(const char *str, FILE *stream);
-
str,一个数组,包含了要写入的以空字符终止的字符序列。 -
stream,指向FILE对象的指针,该FILE对象标识了要被写入字符串的流。
2.可变参数宏__VA_ARGS__
__VA_ARGS__是一个可变参数的宏,定义时宏定义中参数列表的最后一个参数为省略号,在实际使用时会发现有时会加##,有时又不加。__VA_ARGS__宏前面加上##的作用在于,当可变参数的个数为0时,这里printf参数列表中的的##会把前面多余的","去掉,否则会编译出错,建议使用后面这种,使得程序更加健壮。
//最简单的定义
#define my_print1(...) printf(__VA_ARGS__)
//搭配va_list的format使用
#define my_print2(format, ...) printf(format, __VA_ARGS__)
#define my_print3(format, ...) printf(format, ##__VA_ARGS__)
3.fflush
#include <stdio.h>
int fflush(FILE *stream);
-
fflush()会强迫将缓冲区内的数据写回参数stream指定的文件中,如果参数stream为NULL,fflush()会将所有打开的文件数据更新。 -
在使用多个输出函数连续进行多次输出到控制台时,有可能下一个数据再上一个数据还没输出完毕,还在输出缓冲区中时,下一个
printf就把另一个数据加入输出缓冲区,结果冲掉了原来的数据,出现输出错误。 -
在
prinf()后加上fflush(stdout); 强制马上输出到控制台,可以避免出现上述错误。
⑧日志系统
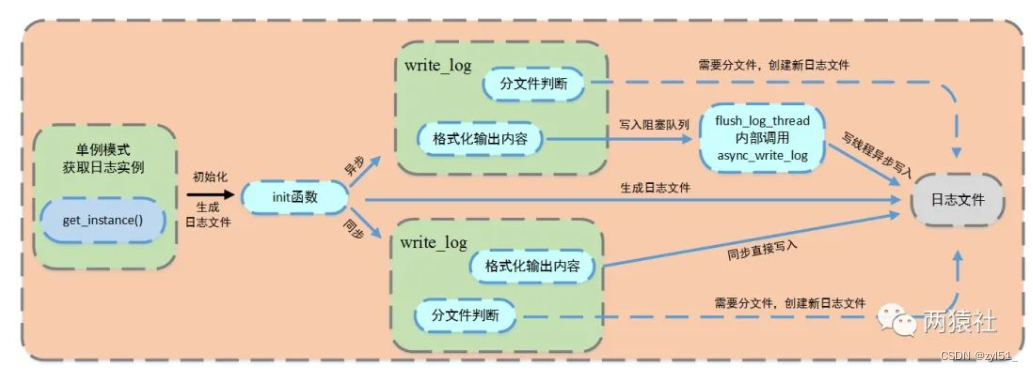
1.流程图
-
日志文件
-
局部变量的懒汉模式获取实例
-
生成日志文件,并判断同步和异步写入方式
-
-
同步
-
判断是否分文件
-
直接格式化输出内容,将信息写入日志文件
-
-
异步
-
判断是否分文件
-
格式化输出内容,将内容写入阻塞队列,创建一个写线程,从阻塞队列取出内容写入日志文件
-
2.代码实现
.h头文件
class Log
{
public:
//C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
{
static Log instance;
return &instance;
}
//可选择的参数有日志文件、日志缓冲区大小、最大行数以及最长日志条队列
bool init(const char *file_name, int log_buf_size = 8192, int split_lines = 5000000, int max_queue_size = 0);
//异步写日志公有方法,调用私有方法async_write_log
static void *flush_log_thread(void *args)
{
Log::get_instance()->async_write_log();
}
//将输出内容按照标准格式整理
void write_log(int level, const char *format, ...);
//强制刷新缓冲区
void flush(void);
private:
Log();
virtual ~Log();
//异步写日志方法
void *async_write_log()
{
string single_log;
//从阻塞队列中取出一条日志内容,写入文件
while (m_log_queue->pop(single_log))
{
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
private:
char dir_name[128]; //路径名
char log_name[128]; //log文件名
int m_split_lines; //日志最大行数
int m_log_buf_size; //日志缓冲区大小
long long m_count; //日志行数记录
int m_today; //按天分文件,记录当前时间是那一天
FILE *m_fp; //打开log的文件指针
char *m_buf; //要输出的内容
block_queue<string> *m_log_queue; //阻塞队列
bool m_is_async; //是否同步标志位
locker m_mutex; //同步类
};
//这四个宏定义在其他文件中使用,主要用于不同类型的日志输出
#define LOG_DEBUG(format, ...) Log::get_instance()->write_log(0, format, __VA_ARGS__)
#define LOG_INFO(format, ...) Log::get_instance()->write_log(1, format, __VA_ARGS__)
#define LOG_WARN(format, ...) Log::get_instance()->write_log(2, format, __VA_ARGS__)
#define LOG_ERROR(format, ...) Log::get_instance()->write_log(3, format, __VA_ARGS__)
.cpp文件
//异步需要设置阻塞队列的长度,同步不需要设置
bool Log::init(const char *file_name, int log_buf_size, int split_lines, int max_queue_size)
{
//如果设置了max_queue_size,则设置为异步
if (max_queue_size >= 1)
{
//设置写入方式flag
m_is_async = true;
//创建并设置阻塞队列长度
m_log_queue = new block_queue<string>(max_queue_size);
pthread_t tid;
//flush_log_thread为回调函数,这里表示创建线程异步写日志
pthread_create(&tid, NULL, flush_log_thread, NULL);
}
//输出内容的长度
m_log_buf_size = log_buf_size;
m_buf = new char[m_log_buf_size];
memset(m_buf, '\0', sizeof(m_buf));
//日志的最大行数
m_split_lines = split_lines;
time_t t = time(NULL);
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
//从后往前找到第一个/的位置
const char *p = strrchr(file_name, '/');
char log_full_name[256] = {0};
//相当于自定义日志名
//若输入的文件名没有/,则直接将时间+文件名作为日志名
if (p == NULL)
{
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
}
else
{
//将/的位置向后移动一个位置,然后复制到logname中
//p - file_name + 1是文件所在路径文件夹的长度
//dirname相当于./
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
//后面的参数跟format有关
snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday;
m_fp = fopen(log_full_name, "a");
if (m_fp == NULL)
{
return false;
}
return true;
}
void Log::write_log(int level, const char *format, ...)
{
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
time_t t = now.tv_sec;
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
char s[16] = {0};
//日志分级
switch (level)
{
case 0:
strcpy(s, "[debug]:");
break;
case 1:
strcpy(s, "[info]:");
break;
case 2:
strcpy(s, "[warn]:");
break;
case 3:
strcpy(s, "[erro]:");
break;
default:
strcpy(s, "[info]:");
break;
}
m_mutex.lock();
//更新现有行数
m_count++;
//日志不是今天或写入的日志行数是最大行的倍数
//m_split_lines为最大行数
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0)
{
char new_log[256] = {0};
fflush(m_fp);
fclose(m_fp);
char tail[16] = {0};
//格式化日志名中的时间部分
snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
//如果是时间不是今天,则创建今天的日志,更新m_today和m_count
if (m_today != my_tm.tm_mday)
{
snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);
m_today = my_tm.tm_mday;
m_count = 0;
}
else
{
//超过了最大行,在之前的日志名基础上加后缀, m_count/m_split_lines
snprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail, log_name, m_count / m_split_lines);
}
m_fp = fopen(new_log, "a");
}
m_mutex.unlock();
va_list valst;
//将传入的format参数赋值给valst,便于格式化输出
va_start(valst, format);
string log_str;
m_mutex.lock();
//写入内容格式:时间 + 内容
//时间格式化,snprintf成功返回写字符的总数,其中不包括结尾的null字符
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);
//内容格式化,用于向字符串中打印数据、数据格式用户自定义,返回写入到字符数组str中的字符个数(不包含终止符)
int m = vsnprintf(m_buf + n, m_log_buf_size - 1, format, valst);
m_buf[n + m] = '\n';
m_buf[n + m + 1] = '\0';
log_str = m_buf;
m_mutex.unlock();
//若m_is_async为true表示异步,默认为同步
//若异步,则将日志信息加入阻塞队列,同步则加锁向文件中写
if (m_is_async && !m_log_queue->full())
{
m_log_queue->push(log_str);
}
else
{
m_mutex.lock();
fputs(log_str.c_str(), m_fp);
m_mutex.unlock();
}
va_end(valst);
}