大家好,我是微学AI,今天给大家介绍一下深度学习实战26-(Pytorch)搭建TextCNN实现多标签文本分类的任务,TextCNN是一种用于文本分类的深度学习模型,它基于卷积神经网络(Convolutional Neural Networks, CNN)实现。TextCNN的主要思想是使用卷积操作从文本中提取有用的特征,并使用这些特征来预测文本的类别。
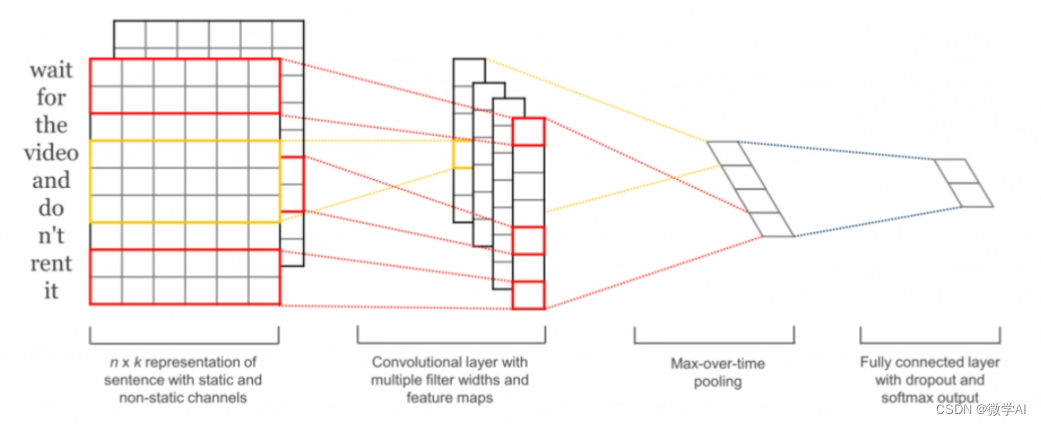
TextCNN将文本看作是一个一维的时序数据,将每个单词嵌入到一个向量空间中,形成一个词向量序列。然后,TextCNN通过堆叠一些卷积层和池化层来提取关键特征,并将其转换成一个固定大小的向量。最后,该向量将被送到一个全连接层进行分类。TextCNN的优点在于它可以非常有效地捕捉文本中的局部和全局特征,从而提高分类精度。此外,TextCNN的训练速度相对较快,具有较好的可扩展性.
TextCNN做多标签分类
1.库包导入
import os
import re
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, precision_score, recall_score
from collections import Counter2.定义参数
max_length = 20
batch_size = 32
embedding_dim = 100
num_filters = 100
filter_sizes = [2, 3, 4]
num_classes = 4
learning_rate = 0.001
num_epochs = 2000
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")3. 数据集处理函数
def load_data(file_path):
df = pd.read_csv(file_path,encoding='gbk')
texts = df['text'].tolist()
labels = df['label'].apply(lambda x: x.split("-")).tolist()
return texts, labels
def preprocess_text(text):
text = re.sub(r'[^\w\s]', '', text)
return text.strip().lower().split()
def build_vocab(texts, max_size=10000):
word_counts = Counter()
for text in texts:
word_counts.update(preprocess_text(text))
vocab = {"<PAD>": 0, "<UNK>": 1}
for i, (word, count) in enumerate(word_counts.most_common(max_size - 2)):
vocab[word] = i + 2
return vocab
def encode_text(text, vocab):
tokens = preprocess_text(text)
return [vocab.get(token, vocab["<UNK>"]) for token in tokens]
def pad_text(encoded_text, max_length):
return encoded_text[:max_length] + [0] * max(0, max_length - len(encoded_text))
def encode_label(labels, label_set):
encoded_labels = []
for label in labels:
encoded_label = [0] * len(label_set)
for l in label:
if l in label_set:
encoded_label[label_set.index(l)] = 1
encoded_labels.append(encoded_label)
return encoded_labels
class TextDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, index):
return torch.tensor(self.texts[index], dtype=torch.long), torch.tensor(self.labels[index], dtype=torch.float32)
texts, labels = load_data("data_qa.csv")
vocab = build_vocab(texts)
label_set = ["人工智能", "卷积神经网络", "大数据",'ChatGPT']
encoded_texts = [pad_text(encode_text(text, vocab), max_length) for text in texts]
encoded_labels = encode_label(labels, label_set)
X_train, X_test, y_train, y_test = train_test_split(encoded_texts, encoded_labels, test_size=0.2, random_state=42)
#print(X_train,y_train)
train_dataset = TextDataset(X_train, y_train)
test_dataset = TextDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
数据集样例:
| text | label |
| 人工智能如何影响进出口贸易——基于国家层面数据的实证检验 | 人工智能 |
| 生成式人工智能——ChatGPT的变革影响、风险挑战及应对策略 | 人工智能-ChatGPT |
| 人工智能与人的自由全面发展关系探究——基于马克思劳动解放思想 | 人工智能 |
| 中学生人工智能技术使用持续性行为意向影响因素研究 | 人工智能 |
| 人工智能技术在航天装备领域应用探讨 | 人工智能 |
| 人工智能赋能教育的伦理省思 | 人工智能 |
| 人工智能的神话:ChatGPT与超越的数字劳动“主体”之辨 | 人工智能-ChatGPT |
| 人工智能(ChatGPT)对社科类研究生教育的挑战与机遇 | 人工智能-ChatGPT |
| 人工智能助推教育变革的现实图景——教师对ChatGPT的应对策略分析 | 人工智能-ChatGPT |
| 智能入场与民主之殇:人工智能时代民主政治的风险与挑战 | 人工智能 |
| 国内人工智能写作的研究现状分析及启示 | 人工智能 |
| 人工智能监管:理论、模式与趋势 | 人工智能 |
| “新一代人工智能技术ChatGPT的应用与规制”笔谈 | 人工智能-ChatGPT |
| ChatGPT新一代人工智能技术发展的经济和社会影响 | 人工智能-ChatGPT |
| ChatGPT赋能劳动教育的图景展现及其实践策略 | 人工智能-ChatGPT |
| 人工智能聊天机器人—基于ChatGPT、Microsoft Bing视角分析 | 人工智能-ChatGPT |
| 拜登政府对华人工智能产业的打压与中国因应 | 人工智能 |
| 人工智能技术在现代农业机械中的应用研究 | 人工智能 |
| 人工智能对中国制造业创新的影响研究—来自工业机器人应用的证据 | 人工智能 |
| 人工智能技术在电子产品设计中的应用 | 人工智能 |
| ChatGPT等智能内容生成与新闻出版业面临的智能变革 | 人工智能-ChatGPT |
| 基于卷积神经网络的农作物智能图像识别分类研究 | 人工智能-卷积神经网络 |
| 基于卷积神经网络的图像分类改进方法研究 | 人工智能-卷积神经网络 |
这里设置多标签,用“-”符号隔开多个标签。
4.构建模型
class TextCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_filters, filter_sizes, num_classes, dropout=0.5):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([nn.Conv2d(1, num_filters, (fs, embedding_dim)) for fs in filter_sizes])
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(num_filters * len(filter_sizes), num_classes)
def forward(self, x):
x = self.embedding(x)
x= x.unsqueeze(1)
x = [torch.relu(conv(x)).squeeze(3) for conv in self.convs]
x = [torch.max_pool1d(i, i.size(2)).squeeze(2) for i in x]
x = torch.cat(x, 1)
x = self.dropout(x)
logits = self.fc(x)
return torch.sigmoid(logits)5.模型训练
def train_epoch(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct_preds = 0 # 记录正确预测的数量
total_preds = 0 # 记录总的预测数量
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算正确预测的数量
predicted_labels = torch.argmax(outputs, dim=1)
targets = torch.argmax(targets, dim=1)
correct_preds += (predicted_labels == targets).sum().item()
total_preds += len(targets)
accuracy = correct_preds / total_preds # 计算准确率
return running_loss / len(dataloader), accuracy # 返回平均损失和准确率
def evaluate(model, dataloader, device):
model.eval()
preds = []
targets = []
with torch.no_grad():
for inputs, target in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
preds.extend(outputs.cpu().numpy())
targets.extend(target.numpy())
return np.array(preds), np.array(targets)
def calculate_metrics(preds, targets, threshold=0.5):
preds = (preds > threshold).astype(int)
f1 = f1_score(targets, preds, average="micro")
precision = precision_score(targets, preds, average="micro")
recall = recall_score(targets, preds, average="micro")
return {"f1": f1, "precision": precision, "recall": recall}
model = TextCNN(len(vocab), embedding_dim, num_filters, filter_sizes, num_classes).to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
if epoch % 20==0:
train_loss,accuracy = train_epoch(model, train_loader, criterion, optimizer, device)
print(f"Epoch: {epoch + 1}, Train Loss: {train_loss:.4f}, Train Accuracy: {accuracy:.4f}")
preds, targets = evaluate(model, test_loader, device)
metrics = calculate_metrics(preds, targets)
print(f"Epoch: {epoch + 1}, F1: {metrics['f1']:.4f}, Precision: {metrics['precision']:.4f}, Recall: {metrics['recall']:.4f}")...
Epoch: 1821, Train Loss: 0.0055, Train Accuracy: 0.8837
Epoch: 1821, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1841, Train Loss: 0.0064, Train Accuracy: 0.9070
Epoch: 1841, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1861, Train Loss: 0.0047, Train Accuracy: 0.8837
Epoch: 1861, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1881, Train Loss: 0.0058, Train Accuracy: 0.8605
Epoch: 1881, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1901, Train Loss: 0.0064, Train Accuracy: 0.8488
Epoch: 1901, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1921, Train Loss: 0.0062, Train Accuracy: 0.8140
Epoch: 1921, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1941, Train Loss: 0.0059, Train Accuracy: 0.8953
Epoch: 1941, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1961, Train Loss: 0.0053, Train Accuracy: 0.8488
Epoch: 1961, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1981, Train Loss: 0.0055, Train Accuracy: 0.8488
Epoch: 1981, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
大家可以利用自己的数据集进行训练,按照格式修改即可