1.引言
人生中充满选择,每次选择就是一次决策,我们正是从一次次决策中,把自己带领到人生的下一段旅程中。在回忆往事的时候,我们会对生命中某些时刻的决策印象深刻:“还好当时选择了读研,毕业后找到了一份自己喜欢的工作!” “如果当初接受那家公司的offer就好了,现在就可以有一个稳定的生活了。”通过这些反思,我们或许能够领悟到一些道理,变得更加睿智和成熟,以更加积极的精神来迎接未来的选择和成长。
2.强化学习介绍
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指:机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累计奖励的期望。
强化学习用智能体(agent)来表示做决策的机器,智能体和环境之间具体的交互方式如图所示。
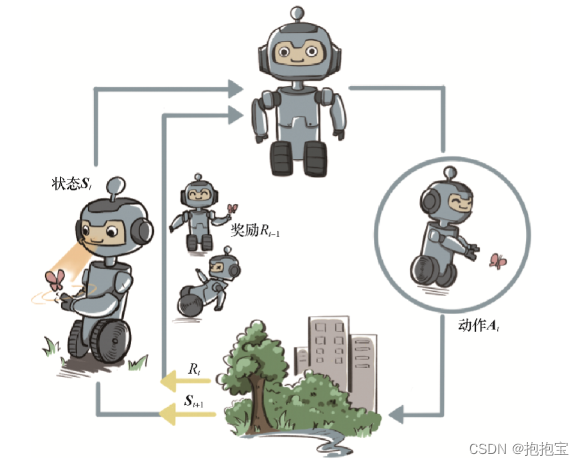
在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。
其中,智能体有3种关键要素,即感知、决策和奖励。
- 感知。智能体在某种程度上感知环境的状态,从而知道自己所处的现状。
- 决策。智能体根据当前的状态计算出达到目标需要采取的动作的过程叫做决策。
- 奖励。环境根据状态和智能体采取的动作,产生一个标量信号作为奖励反馈,这个标量信号衡量智能体这一轮动作的好坏。最大化累积奖励期望是智能体提升策略的目标,也是衡量智能体策略好坏的关键指标。
3.强化学习的环境
强化学习的智能体是在和一个动态环境的交互中完成序贯决策的。我们说一个环境是动态的,意思就是它会随着某些因素的变化而不断演变,这在数学和物理中往往用随机过程来刻画。对于一个随机过程,其最关键的要素就是状态以及状态转移的条件概率分布。
如果在环境这样一个自身演变的随机过程中加入一个外来的干扰因素,即智能体的动作,那么环境的下一刻状态的概率分布将由当前状态和智能体的动作来共同决定,用最简单的数学公式表示则是
![]()
根据上式可知,智能体决策的动作作用到环境中,使得环境发生相应的状态改变,而智能体接下来则需要在新的状态下进一步给出决策。
由此我们看到,与面向决策任务的智能体进行交互的环境是一个动态的随机过程,其未来状态的分布由当前状态和智能体决策的动作来共同决定,并且每一轮状态转移都伴随着两方面的随机性:一是智能体决策的动作的随机性,二是环境基于当前状态和智能体动作来采样下一刻状态的随机性。
4.强化学习的目标
智能体和环境每次进行交互时,环境会产生相应的奖励信号,其往往由实数标量来表示,这个奖励信号一般是诠释当前状态或动作的好坏的及时反馈信号。整个交互过程的每一轮获得的奖励信号可以进行累加,形成智能体的整体回报(return)。根据环境的动态性我们可以知道,即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。因此,在强化学习中,我们关注回报的期望,并将其定义为价值(value),这就是强化学习中智能体学习的优化目标。
5.强化学习中的数据
在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同,如图所示
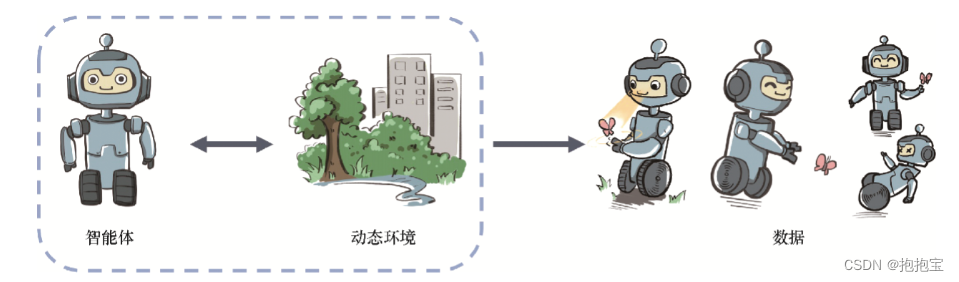
具体而言,强化学习中有一个关于数据分布的概念,叫作占用度量(occupancy measure),归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(state-action pair)的概率分布。
占用度量有一个很重要的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
根据占用度量这一重要的性质,我们可以领悟到强化学习本质的思维方式:
- 强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。
- 由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
6.强化学习和一般有监督学习的区别
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(generalization error),用简要的公式可以概括为:
![]()
相比之下,强化学习任务的最终优化目标是最大化智能体策略在和动态环境交互过程中的价值,而策略的价值又可以等价转换成奖励函数在策略的占用度量上的期望,即:
![]()
综上所述,一般有监督学习和强化学习之间的区别为:
- 二者优化的目标不同。一般的有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小;而强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
- 二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。